




1、羲和(halo)数据库简介
羲和(Halo)数据库采用世界领先的数据库技术,并且结合实际核心生产业务系统实践,通过自主研发而精心打造的一款数据库产品。羲和(Halo)数据库拥有先进的多模数据库技术,可以针对国外主流数据库如 Oracle、MySQL、PostgreSQL、SQL Server、Db2 等实现在大幅减少应用代码的修改量甚至不修改应用代码的基础上完成迁移。
目前已迁移测试的项目覆盖了金融、军工、自动化办公、国税等相关行业,几百例的迁移测试案例都无需客户修改业务代码。很多网友朋友想了解下具体的迁移过程,因为很多客户的项目有保密要求,所以今天借助gitee的开源平台,选着一个开源业务,为大家详细介绍一下羲和(halo)数据库的迁移流程。
2、部署源码应用
2.1 首先下载源码
下载开源业务源码,从https://gitee.com/java73-group-7/jsh_erp下载源码,这个应用采用的数据库是mysql,所以这次文档以介绍mysql迁移羲和(halo)数据库为主。
2.2安装mysql数据库
mysql安装步骤忽略,为方便测试,网友朋友可以下载二进制mysql包进行快速安装即可。暂时使用默认端口3306即可。
安装好mysql之后,登录mysql数据库,创建用户名、密码、database、导入数据。
create user jsh_erp@'%' identified by '123456';
grant all on *.* to jsh_erp@'%' ;
create database jsh_erp;
use jsh_erp;
source jsh_erp.sql
2.3 使用idea导入项目
使用idea导入项目并进行依赖包更新下载,之后为方便迁移,打成了java包形式,方便启动测试。已打好的java名为jshERP2.0。
设置好数据源后即可启动java进行验证。

启动java包,验证服务正常。
nohup java -Xms512m -Xmx1024m -jar jshERP2.0.jar > nohup.out 2>&1 &

3、安装羲和(halo)数据库
3.1安装依赖
yum install -y iproute bind iptables which sudo sysstat make cmake gcc gcc-c++
yum install -y uuid uuid-devel bison flex perl perl-devel perl-ExtUtils-Embed
yum install -y readline readline-devel libxml2 libxml2-devel iotop tcpdump
yum install -y strace gdb systemtap net-tools xdpyinfo smartmontools ksh bc
yum install -y libaio libaio-devel libX11 libXau libXi libXtst libicu libicu-devel
yum install -y libXrender libXrender-devel libxcb libgcc libstdc++ libstdc++-devel
yum install -y libcurl libcurl-devel zlib-devel tcl glibc glibc-devel ftp
yum install -y openssl openssl-devel binutils nfs-utils python-devel
yum install -y zstd zstd-devel lz4
3.2配置内核参数
vi /etc/sysctl.conf
添加
kernel.sem = 4096 4194304 32768 1024
执行生效
sysctl -p
3.3修改资源限制
在/etc/security/limits.conf 文件添加如下参数:
vi /etc/security/limits.conf
添加
halo soft nproc unlimited
halo hard nproc unlimited
halo soft nofile 1024000
halo hard nofile 1024000
halo soft stack unlimited
halo hard stack unlimited
halo soft memlock unlimited
halo hard memlock unlimited
halo soft core unlimited
halo hard core unlimited
3.4防火墙设置
关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
3.5关闭 selinux
方法一:临时修改
setenforce 0
方法二:永久修改
vi /etc/selinux/config
将修改如下项
SELINUX=disabled
3.5 Halo 数据库单实例部署
下述操作以演示的目的呈现给大家,请大家操作时根据实际情况进行修改。
演示操作时$PGDATA 代表 Halo 数据库的数据目录,而使用的用户,如未注明则为
root 用户下,如已注明的操作用户则需要切换到注明用户下进行操作。
3.5.1 创建用户和组
为防止 halo 用户 ID/用户组 ID 与已存在的用户 ID/用户组 ID 冲突,我们默认设置为 3000,可根据需要执行修改,建议按按照 X000 方式(X 是数字)。
groupadd -g 3000 halo
useradd -u 3000 -g halo halo
3.5.2创建安装目录
Halo14 数据库建议的安装目录为/u01/app/halo,可根据需要自定义安装目录。如果不存在,您需要使用 root 用户先创建该目录,并赋予 halo 用户对该目录的读写权限。
mkdir -p /u01/app/halo
chown -R halo:halo /u01/app/halo
解压安装包到安装目录
tar -zxvf halo_14.el7.x86_64.build240925.tar.gz -C /u01/app/halo/
解压安装包后得到 product 目录,product 目录有三个子目录 dbms,instantclient_xx_x, shield。
3.5.3 授权文件
移动或拷贝 license 到 halo14 应用程序目录
cp license.lic /u01/app/halo/product/dbms/14
3.5.4 创建进程目录
进程目录默认路径/var/run/halo,如不存在需要手工创建。
mkdir /var/run/halo
chown halo:halo /var/run/halo
注意:在/var/run 目录下的用户内容在操作系统重启后会被系统自动清理,为防止因为系统重启 导致的路径丢失错误,可以在/etc/rc.local 中配置系统重启后自动重建路径。
在/etc/rc.local 和/etc/rc.d/rc.local 文件添加自动重建
vi /etc/rc.d/rc.local
添加
/usr/bin/mkdir /var/run/halo
/usr/bin/chown halo:halo /var/run/halo
授权
chmod +x /etc/rc.d/rc.local
3.5.5创建数据目录
数据目录是 Halo14 数据库中存放数据文件的目录,我们建议的数据目录为/data/halo/, 也可以根据需要自定义设置。您可以根据业务系统数据量来单独设置数据目录路径,例如
将数据目录初始化在本机硬盘或者挂载在盘阵上。需要注意的是 Halo 数据库数据目录的
拥有者必须为 halo 用户,且目录权限应该为 0700 或者 0750。
您可以运行如下命令创建数据目录:
mkdir -p /data/halo
chown -R halo:halo /data/halo
chmod -R 0700 /data/halo
3.5.6配置用户环境变量
用户环境变量只对当前用户生效,当用户登录时执行,每个用户都可以使用该文件来 配置专属于自己的环境变量。
--halo 用户下操作
vi /home/halo/.bash_profile
添加
#Halo 数据库应用程序的安装目录
export HALO_HOME=/u01/app/halo/product/dbms/14
#指定可执行程序在运行时查找共享库的路径
export LD_LIBRARY_PATH=$HALO_HOME/lib
# 进程目录的路径
export PGHOST=/var/run/halo
#数据目录路径
export PGDATA=/data/halo
export PATH=$HALO_HOME/bin:$PATH
export PATH
加载修改后的环境变量配置
--halo 用户下操作
source /home/halo/.bash_profile
3.5.7 初始化数据库
初始化的过程会创建数据库集群包括数据目录及其子目录和子文件、生成系统表以及 创建 template1 和 halo0root 数据库。当创建新数据库时,将会复制 template1 数据库中的 所有内容,halo0root 数据库是供用户、实例程序和第三方应用程序使用的默认数据库。
初始化必须以 halo 用户(运行数据库服务器进程)身份运行它,不能以 root 用户运行初
始化操作。
--halo 用户下操作
pg_ctl init -D /data/halo
或者
--halo 用户下操作
initdb -D /data/halo
3.5.8 启动数据库
在 halo 用户下进行启动数据库操作
--halo 用户下操作
pg_ctl start
验证安装版本
--halo 用户下操作
pg_ctl -V
psql -c "select version()"

3.6 配置数据库
3.6.1访问配置
通过修改数据目录下的 pg_hba.conf 文件实现对 Halo14 数据库的访问认证配置。
vi $PGDATA/pg_hba.conf
添加
# 注释掉本地免密登录
#TYPE DATABASE USER ADDRESS METHOD
host all all 0/0 md5
# 0/0 表示任意 IP 地址的任意用户 无需密码验证可直接连接访问该主机的数据库
# local all all md5
# 表示本地登录的任意用户 需要通过 MD5 方式加密的密码验证才可访问该主机的数据库
host all all 0/0 trust
# 0/0 表示任意 IP 地址的任意用户 无需密码验证可直接连接访问该主机的数据库
host test test 10.10.10.17/24 md5
# 表示允许地址为 10.10.10.17 的用户 test 通过 MD5 方式加密的密码方式连接主机上的 test 数据库
3.6.2 数据库参数配置
修改 postgresql.conf 数据库参数文件
vi $PGDATA/postgresql.conf
#监听地址
#listen_addresses = 'localhost' --> listen_addresses = '*'Halo14 数据库安装手册
#端口号
#port = 1921 --> port = 1921
#最大连接数
max_connections = 100 --> max_connections = 1000
#指定在写入临时文件之前内部排序操作和散列表使用的内存量
#work_mem = 4MB --> work_mem = 16MB
#预写日志(wal)缓冲区
#wal_buffers = -1 --> wal_buffers = 16MB
#设置检查点完成的目标时间为 0.9,表示在 90% 的时间内完成检查点。
#checkpoint_completion_target = 0.9 --> checkpoint_completion_target = 0.9
#在自动 WAL 检查点之间允许 WAL 增长到的最大尺寸。这是一个软限制, 在特殊的情况下 WAL 尺寸可能会 超过
max_wal_size = 1GB --> max_wal_size = 8GB
#只要 WAL 磁盘用量保持在这个设置之下,在检查点时旧的 WAL 文件总是 被回收以便未来使用,而不是直接 被删除。
min_wal_size = 80MB --> min_wal_size = 2GB
#为没有通过 ALTER TABLE SET STATISTICS 设置列相关目标的表列设置默认统计目标。
#default_statistics_target = 100 --> default_statistics_target = 100
#多种记录服务器日志的方法,包括 stderr,csvlog 和 syslog。
#log_destination = 'stderr' --> log_destination = 'csvlog'
#日志收集器。
#logging_collector = off --> logging_collector = on
#设置规划器对一次非顺序获取磁盘页面的代价估计。
#random_page_cost = 4.0 --> random_page_cost = 1.1
#用于维护工作的 effective_io_concurrency 变体,与 effective_io_concurrency 类似,但用于代 表许多客户端会话完成的维护工作。
#maintenance_io_concurrency = 10 --> maintenance_io_concurrency = 200
#当这个参数设置为 ON 时,Halo 数据库服务器在一个检查点之后第一次页面更改过程(即使是对提示位进行非 关键性的修改)中,将每个磁盘页的全部内容写入到 WAL 中。
#wal_log_hints = off --> wal_log_hints = on
# 以下参数,测试配置不高的时候可以不配置
#数据库服务器将使用的共享内存缓冲区量。
shared_buffers = 128MB --> shared_buffers = (内存的 25%-40%)
#设置规划器对一个单一查询可用的有效磁盘缓冲区尺寸的假设。
#effective_cache_size = 4GB --> effective_cache_size = (内存的 50%)
#后台进程的最大数量
#max_worker_processes = 8 --> max_worker_processes = (CPU 数)
#并行操作所支持的工作者的最大数量。
#max_parallel_workers = 8 --> max_parallel_workers = (CPU 数)
3.6.3开启 MySQL 模式
因为本次迁移的是mysql数据库,所以需要配置羲和(halo)数据库为mysql兼容模式。
修改配置文件
vi $PGDATA/postgresql.conf
#数据库模式改为 mysql
#database_compat_mode = 'postgresql' --> database_compat_mode = 'mysql'
#开启第二监听
#second_listener_on = false --> second_listener_on = 1
#修改第二端口
#second_port = 3307 --> second_port = 3307
# 根据版本修改日志体现版本
#mysql.halo_mysql_version = '5.7.32-log' --> mysql.halo_mysql_version =
'8.0.21-log'
# 字符序不区分大小写
#mysql.ci_collation = true --> mysql.ci_collation = true
3.6.4 重启数据库并创建扩展
--halo 用户下操作
pg_ctl restart
psql -c "create extension aux_mysql; "
3.6.5创建 所需的迁移用户
一般建议创建和生产环境一样的用户名/密码/库名。
--halo 用户下操作
psql
halo0root=# set password_encryption='mysql_native_password';
halo0root=# CREATE USER jsh_erp SUPERUSER PASSWORD '123456';
halo0root=# CREATE schema jsh_erp;
注意:采用 mysql 模式情况下,mysql 的数据库即 schema,只需要在 halo0root 库下创建
schema 就可以。
4、安装数据迁移工具
Halo Migration Tool为我们易景科技自研数据库迁移系统,可以稳定快速的进行元数据和数据迁移,并支持增量数据迁移功能。
4.1 迁移工具安装步骤
4.1.1环境需求
Java1.8

需要root用户下可以执行 psql 命令

4.1.2创建安装目录、并解压
mkdir /soft
unzip datax_web迁移工具_241009.zip
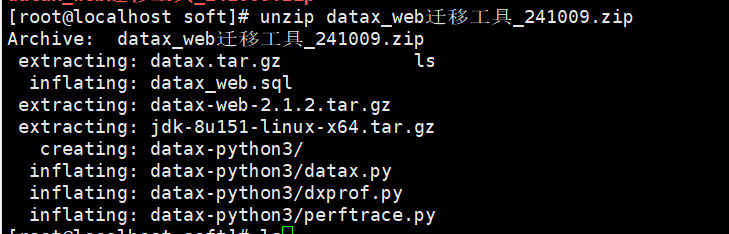
4.1.3迁移工具工具使用的数据库为 postgresql 模式的 Halo
为方便管理,可以单独初始化一个实例做迁移工具的库使用:
mkdir /data/halo_dx
pg_ctl init -D /data/halo_dx
database_compat_mode = 'postgresql'
port = 1922

pg_ctl start -D /data/halo_dx
在数据库中创建相应的用户并导入迁移工具所需要的表和数据
su - halo -c "psql -c \"CREATE USER datax_web SUPERUSER PASSWORD '123456'; \" "
su - halo -c "psql -c \"CREATE DATABASE datax; \" "
su - halo -c "psql -U datax_web -d datax -c \"CREATE SCHEMA datax_web;\" "
su - halo -c "psql -U datax_web -d datax -f /opt/datax_web.sql"
4.1.4迁移工具安装
tar -xvf datax.tar.gz
cd datax
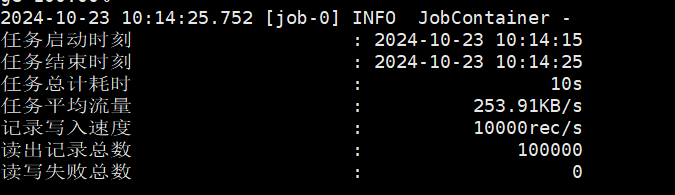
python bin/datax.py job/job.json
如果最后输出如下,则 datax 部署成功
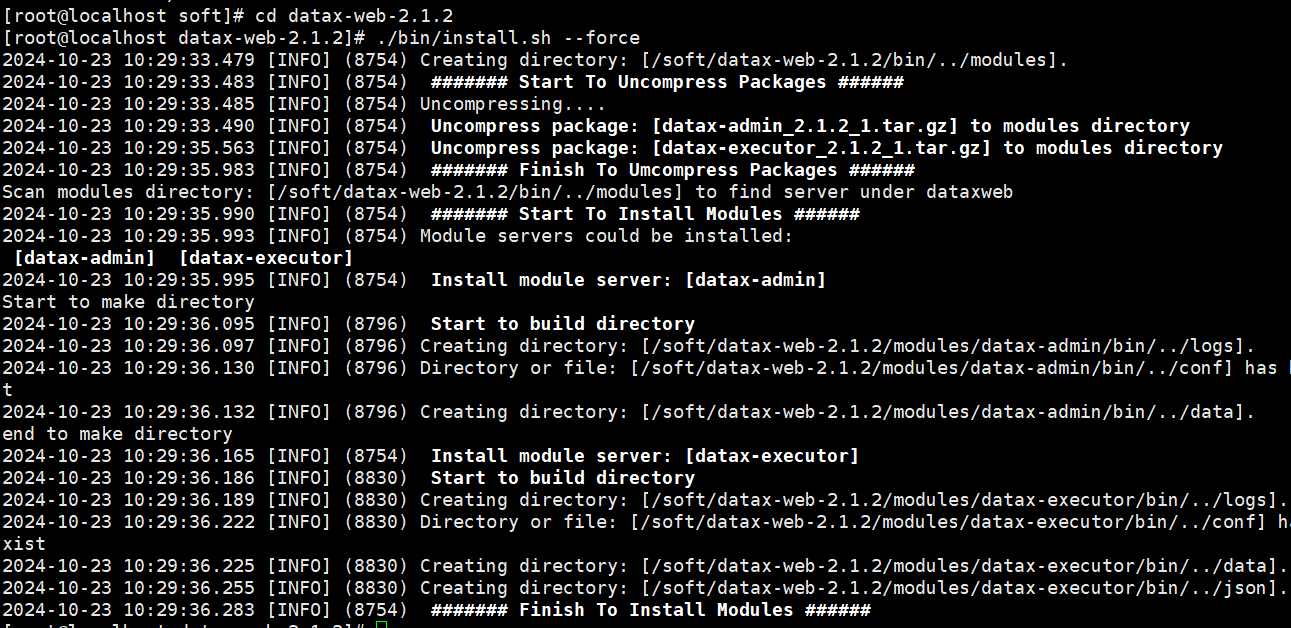
tar -zxvf datax-web-2.1.2.tar.gz
cd datax-web-2.1.2
./bin/install.sh --force
配置文件修改
/soft/datax-web-2.1.2/modules/datax-admin/conf 目录的application.yml
注意修改 spring.datasource.url 的 ip 地址改为实际 halo 的 ip 地址,端口号、 实例名如有变动也需要更改。
修改 spring.datasource.username 以及 password,改为实际的账号密码。

/soft/datax-web-2.1.2/modules/datax-executor/bin 目录下的 env.properties 文 件要修改 PYTHON_PATH 地址,改为实际 datax 脚本路径。
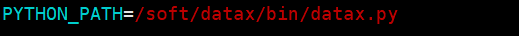
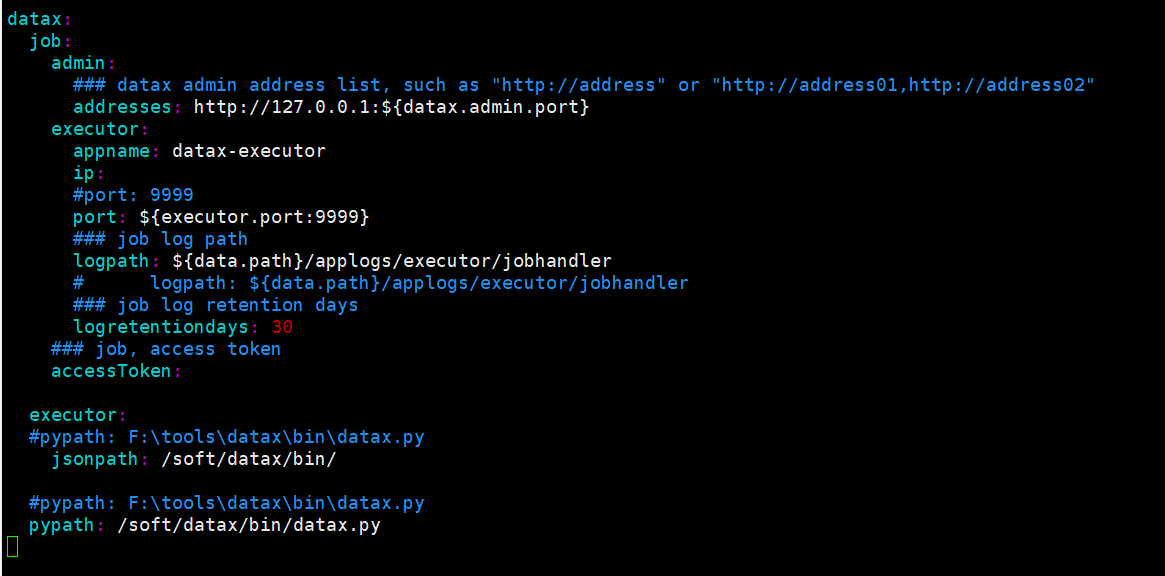
/soft/datax-web-2.1.2/modules/datax-executor/conf 目录下的application.yml,
注意修改 datax.job.admin.addresses 的 ip 地址,datax.executor.jsonpath
和 datax.pypath
目前都是在同一台服务器上安装,所以连接ip可以使用127.0.0.1
4.1.5 启动服务
cd /soft/datax-web-2.1.2
./bin/start-all.sh

运行 jps 命令,如果出现 DataXExecutorApplication,DataXAdminApplication
任务,则表示启动成功。
在浏览器输入 http://ip:9527/index.html,默认管理员账号是 admin 密码
123456
5、迁移步骤
5.1操作流程
1.添加数据源,2.添加项目,3.添加 datax 任务模板,4.任务构建,5. 批量任务构建。
5.2添加需要迁移源mysql和目标端halo的数据源


5.3添加项目
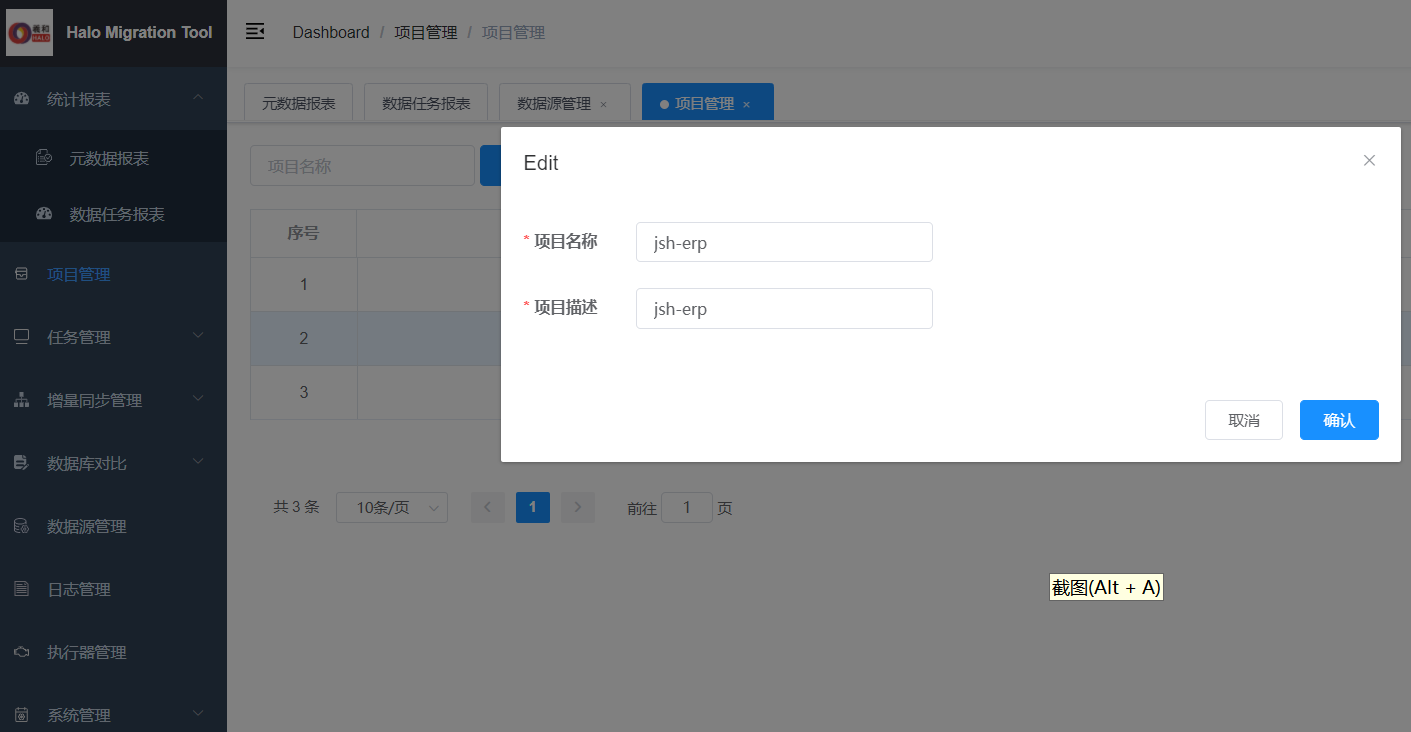
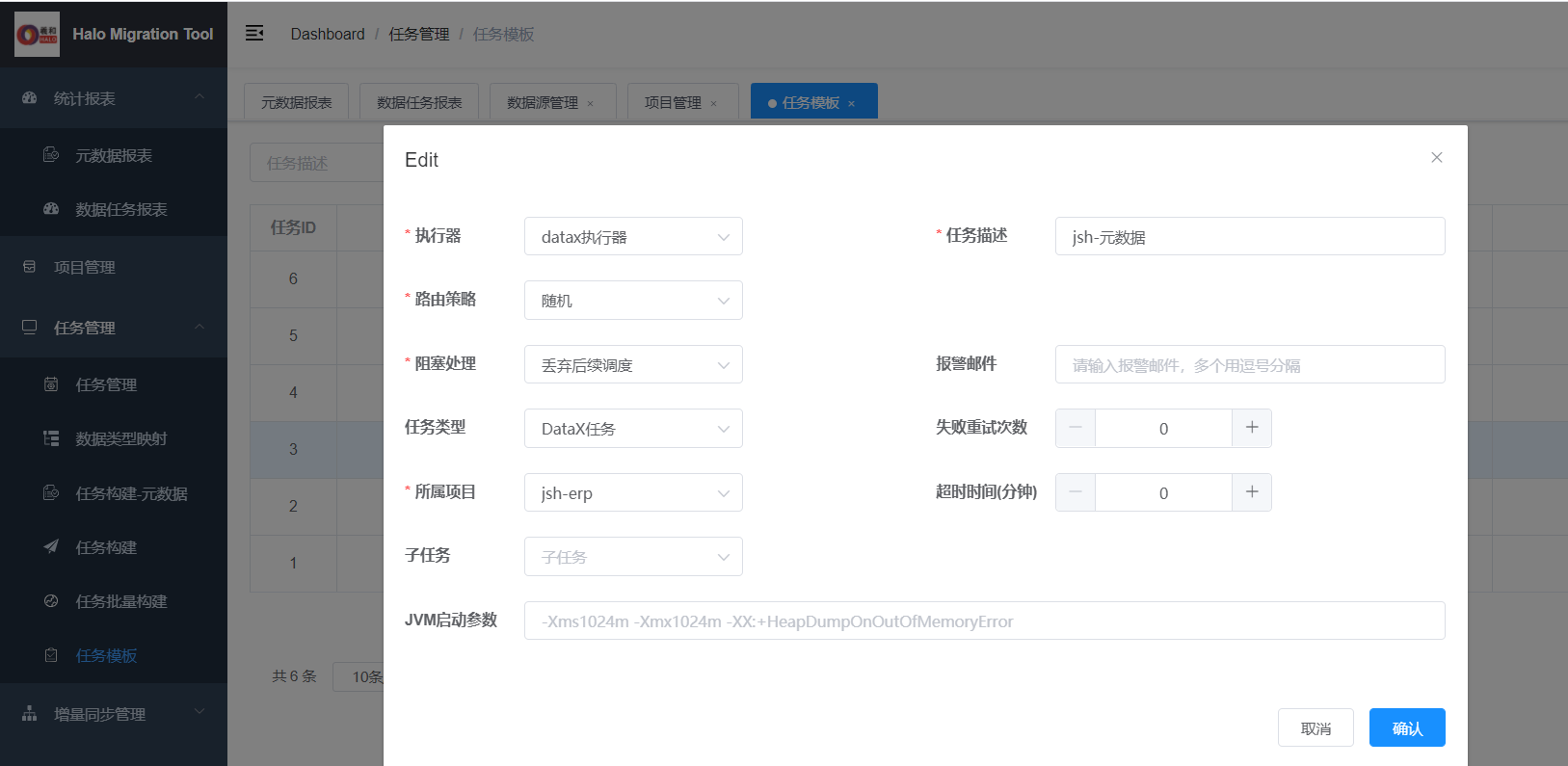
5.4添加 datax 任务模板
为方便管理迁移任务,可以添加元数据和数据2个模板。

5.5任务构建-元数据
一般执行顺序表结构、索引、约束后再执行其他对象。如果数据量比较大,建议是先执行表结构,迁移数据后,再执行索引和约束,可以缩短迁移时间。

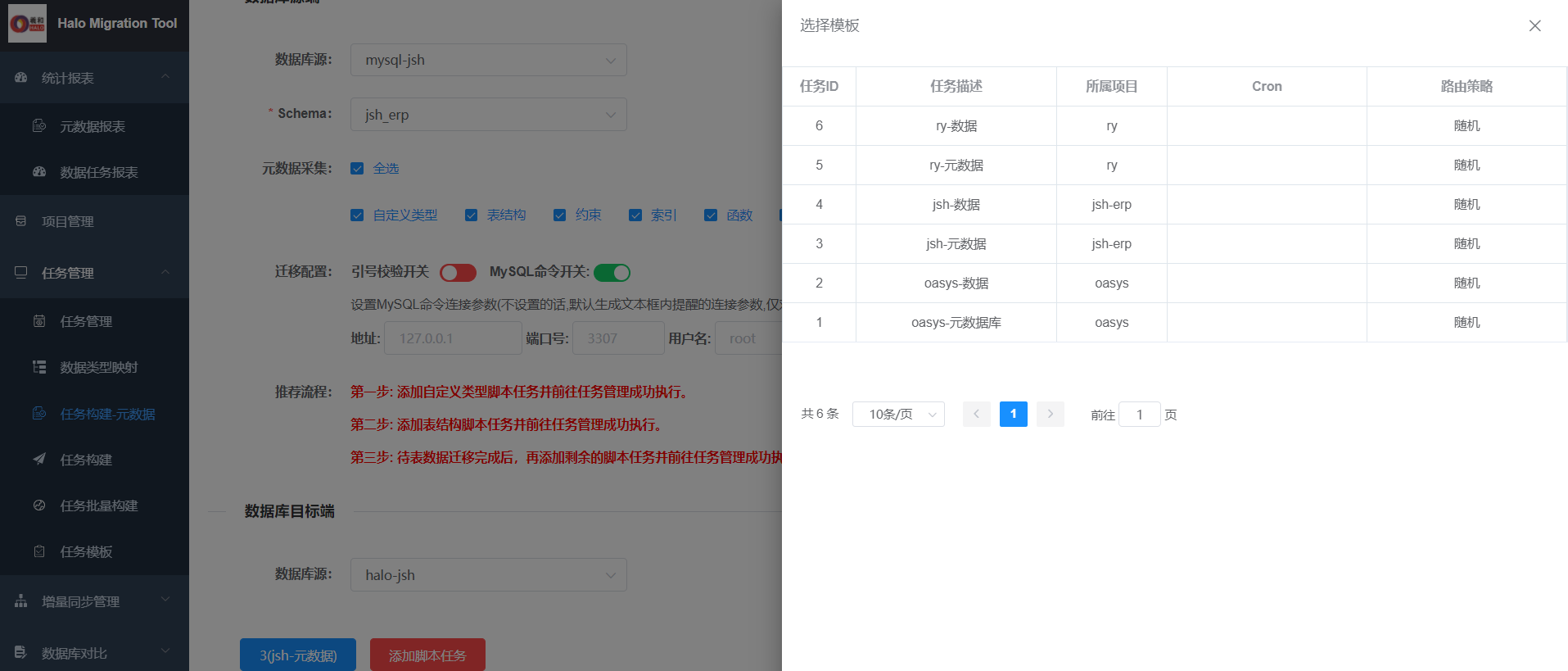
选择好模板后,点添加任务脚本即可。
5.6任务管理
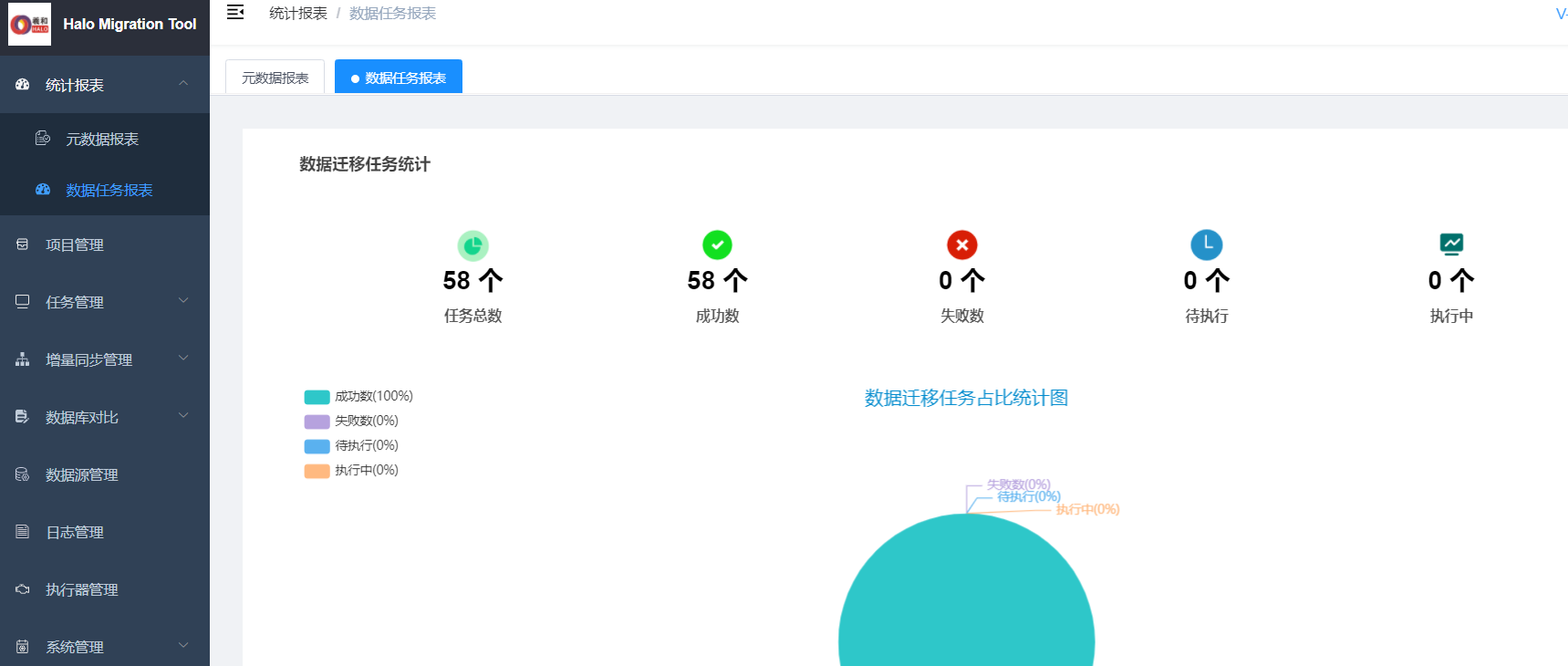
下图为生成的任务脚本
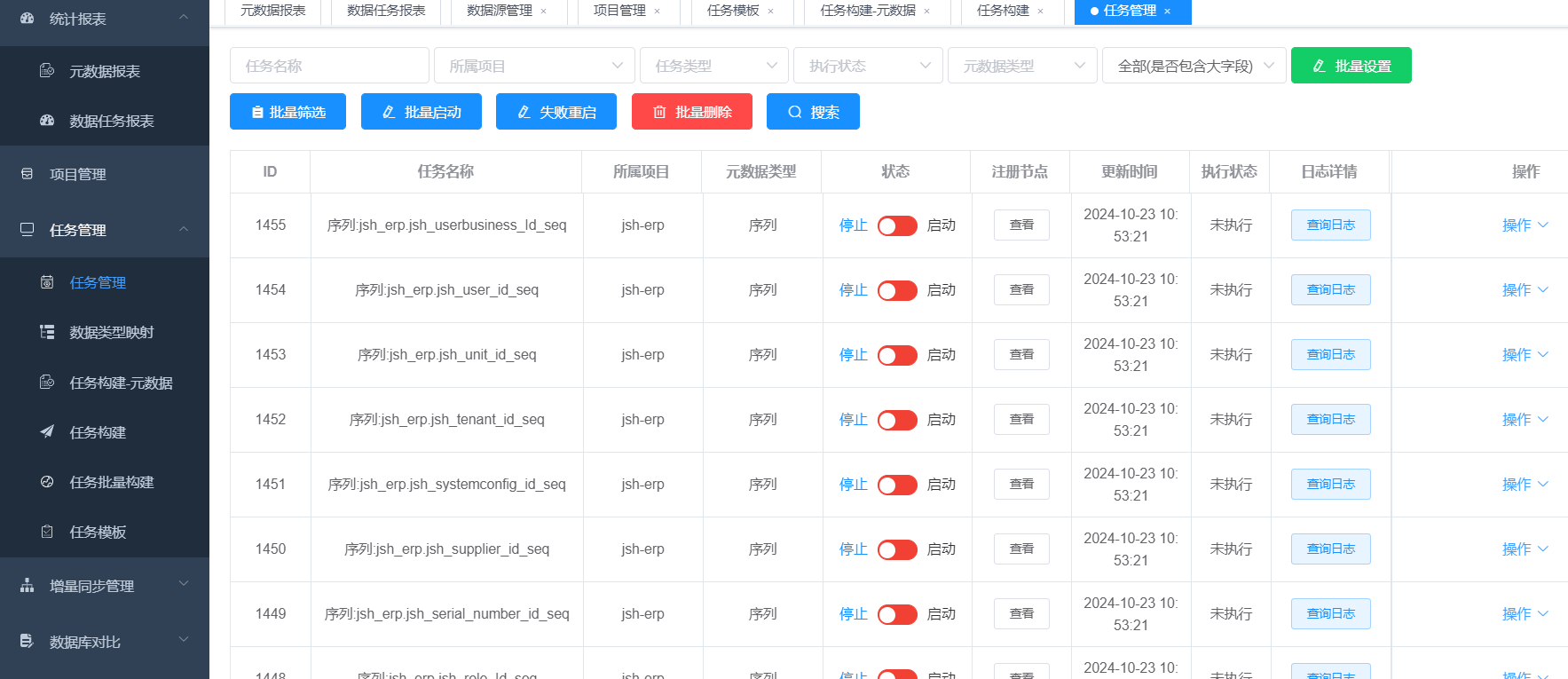
执行的时候可以安装选着框,选着需要执行的对象,执行元数据后的状态
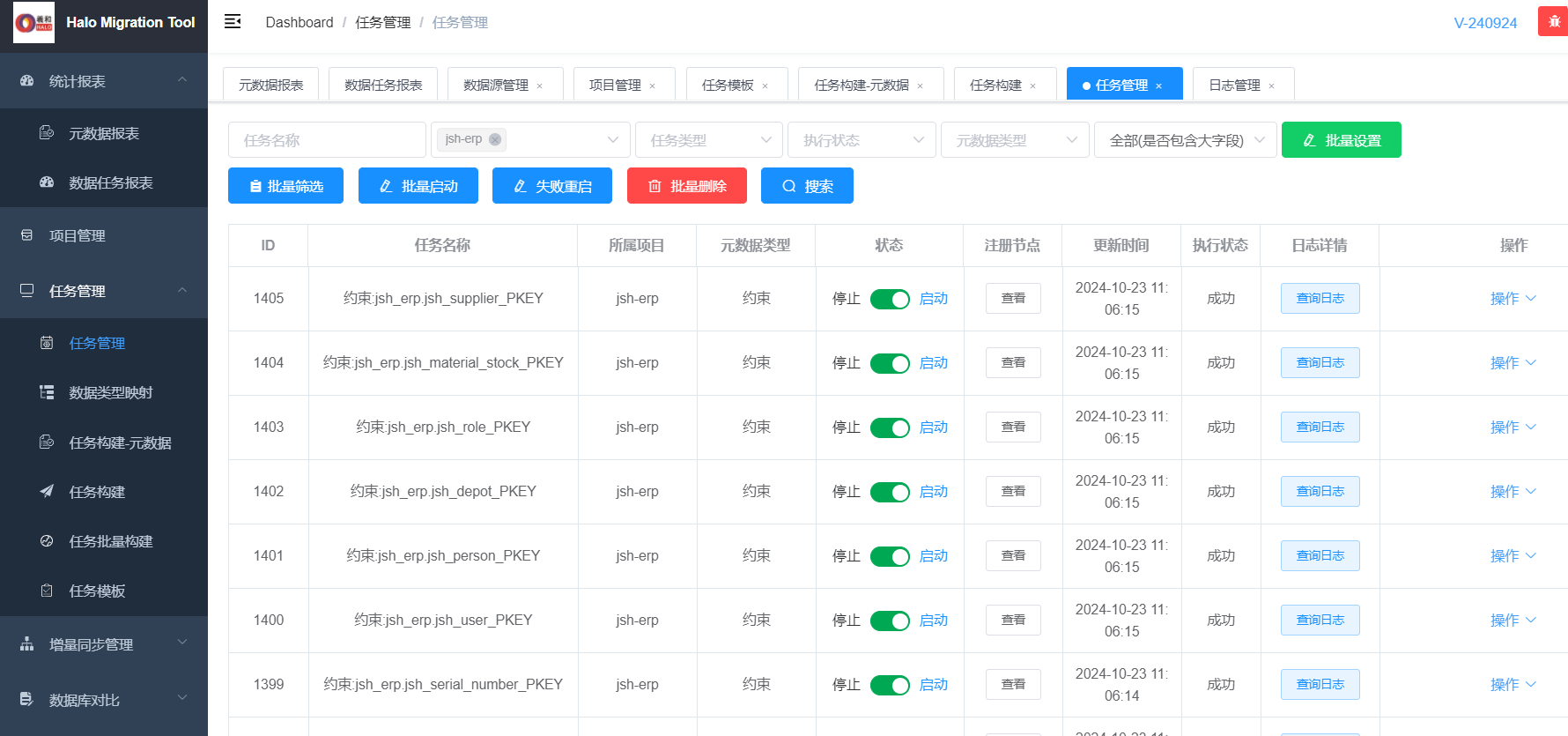
查询迁移项目中失败状态为无,就表示元数据迁移无误,即可以进行数据迁移

5.7创建数据迁移任务
创建数据迁移任务,可以全表,也可以选着某些表。
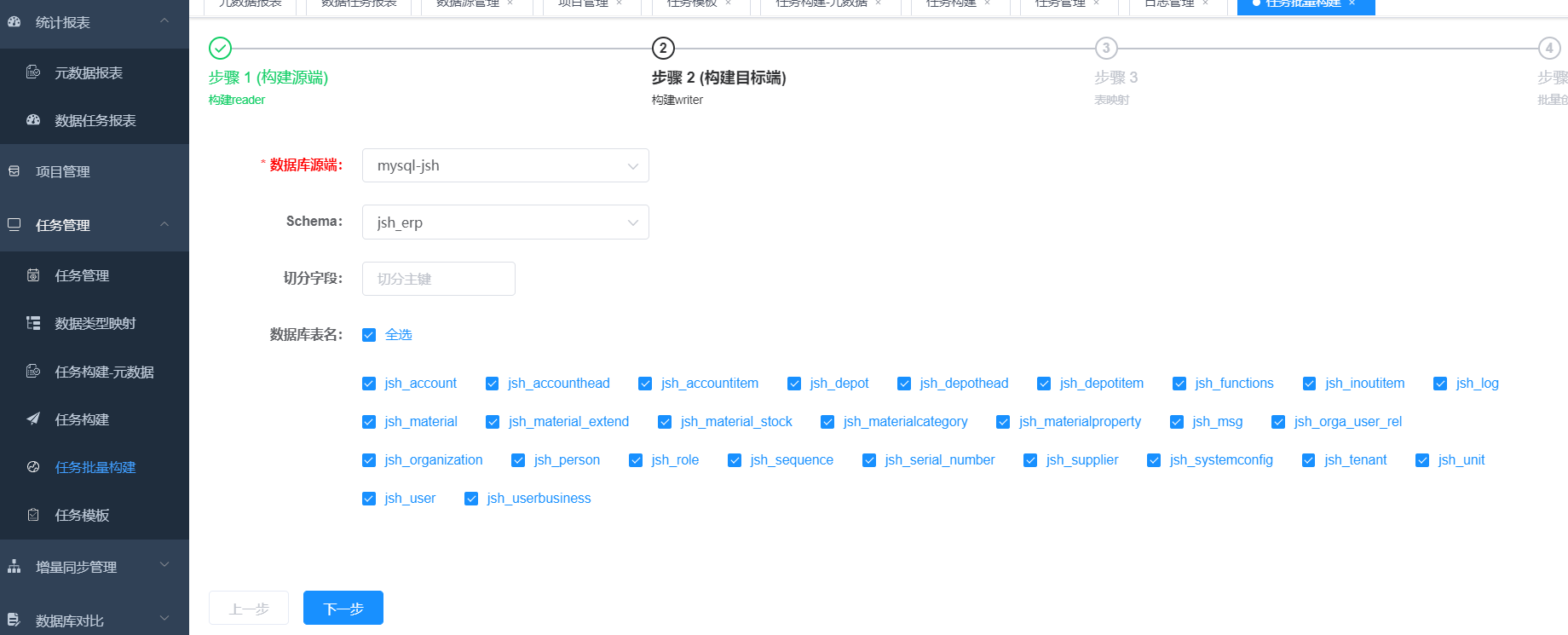

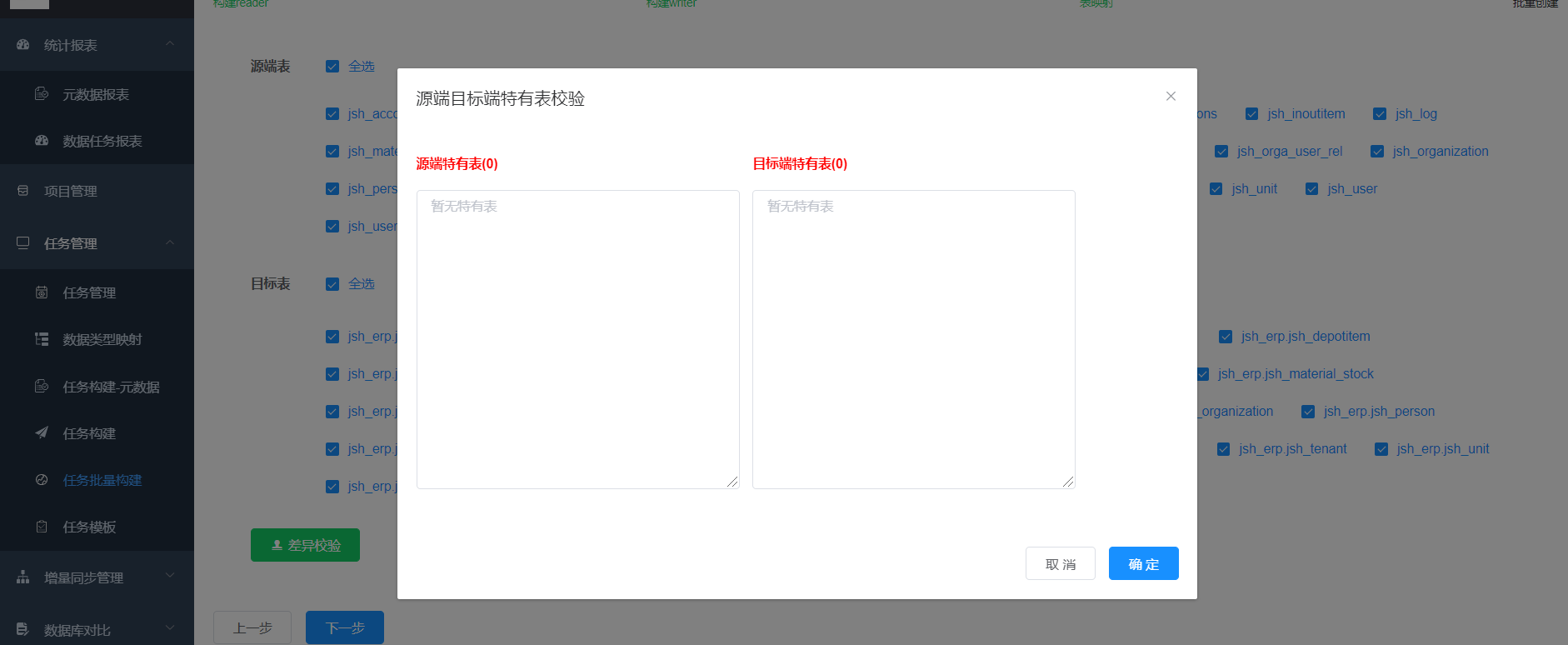

点击批量创建任务
在任务管理查询未执行任务

点击批量启动即可
收索失败任务为空,即表示迁移数据完成。
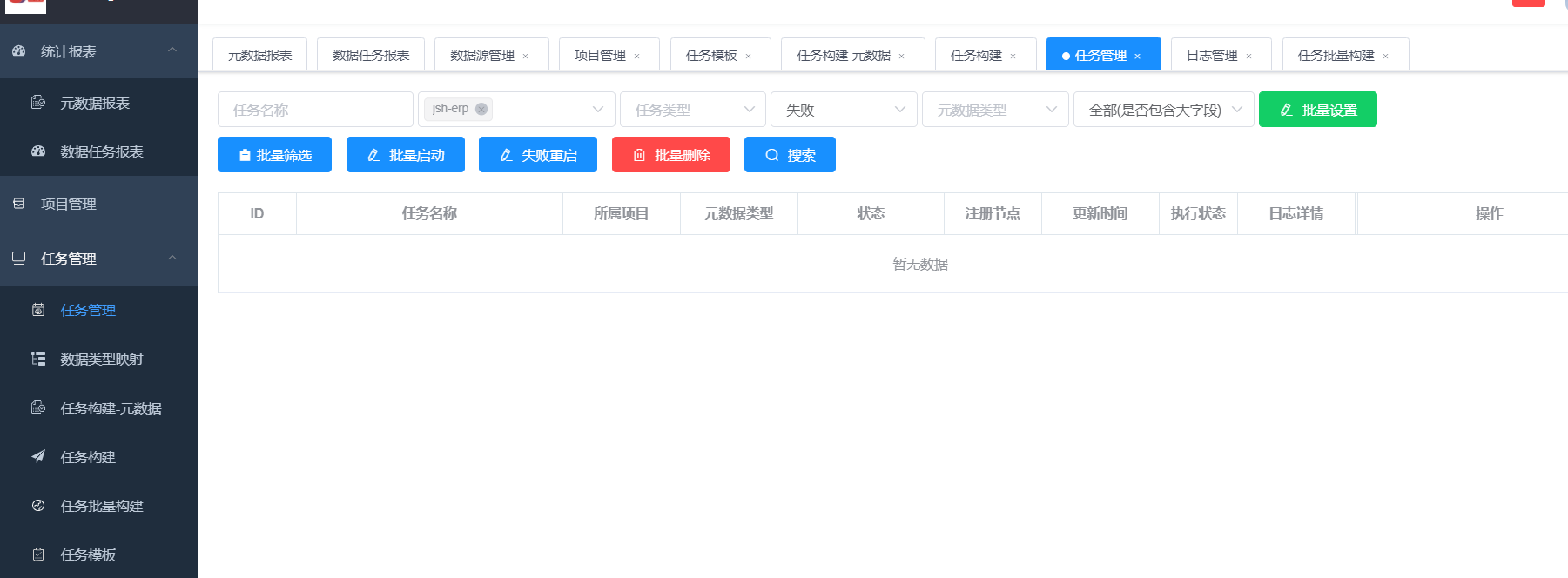
5.8启动应用进行验证
在halo库创建的用户名、密码、database都和生产环境一致,因为mysql和halo在同一台服务区,应用java包只需要修改下端口后即可。

启动jaba包
nohup java -Xms512m -Xmx1024m -jar jshERP2.0.jar > nohup.out 2>&1 &
验证业务的流程都无问题

迁移总结
以上描述可以证明羲和(halo)数据库,可以完美的将后台数据库为mysql的应用完美的迁移至halo数据库,并且应用代码不需要进行任何修改,实现了现有系统快速完成迁移、低成本大规模替换、开发人员可以保留原有开发习惯,快速适应。
有感兴趣的朋友可以联系我们进行迁移测试,共同为国家的信创事业的飞速发展贡献力量。
