




问题反馈、代码提交、文章投稿与社区贡献请移步 Github issue。
Github issue #66 登记企业或组织生产使用,可邀请至企业支持群,获取团队技术支持与其他企业用户的经验分享。
 GitHub 地址
GitHub 地址 一、Docker 快速部署 Dinky
h2数据库无需安装,开箱即用,仅适合快速体验,重启后数据消失,如要正式使用,请切换为mysql。
docker run --restart=always -p 8888:8888 \-v opt/lib:/opt/dinky/customJar/ \--name dinky \dinkydocker/dinky-standalone-server:1.1.0-flink1.19
二、准备依赖
hadoop的shaded包:flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
Paimon flink 1.19的依赖包,如果你不是1.19,请自行替换:paimon-flink-1.19-0.9.0.jar
三、初始化 Paimon 表
如果你已经有 Paimon 库了,可以略过此步骤。
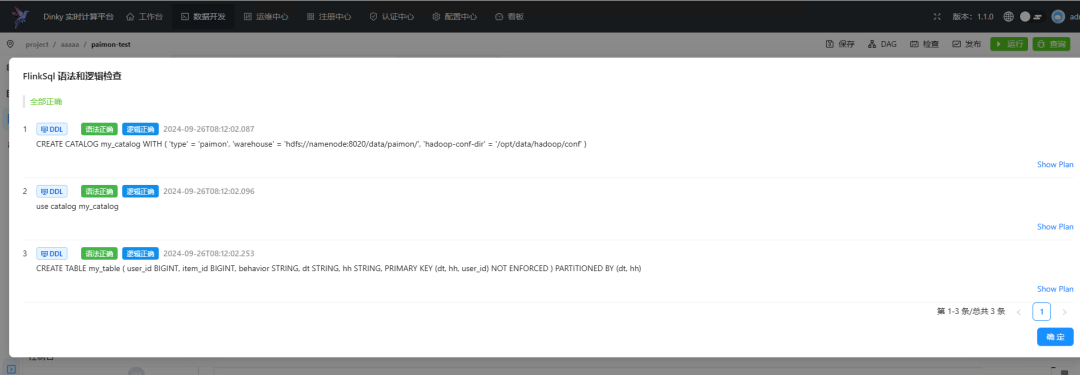
CREATE CATALOG my_catalog WITH ('type' = 'paimon',-- 这里更改为你的hdfs地址'warehouse' = 'hdfs://namenode:8020/data/paimon/',-- 这里更改为你的hadoop配置路径'hadoop-conf-dir' = '/opt/data/hadoop/conf');use catalog my_catalog;CREATE TABLE my_table_1 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED) PARTITIONED BY (dt, hh);
点击检查。(虽然是检查,但是Dinky在检查过程中会执行DDL语句)
hdfs dfs -ls data/paimon/default.db/drwxr-xr-x - root supergroup 0 2024-09-26 16:12 data/paimon/default.db/my_tabledrwxr-xr-x - root supergroup 0 2024-09-26 14:49 data/paimon/default.db/my_table_1opt/data/hive/conf
四、注册 Paimon 数据源
前往注册中心-->数据源,新建数据源,选择 Paimon。
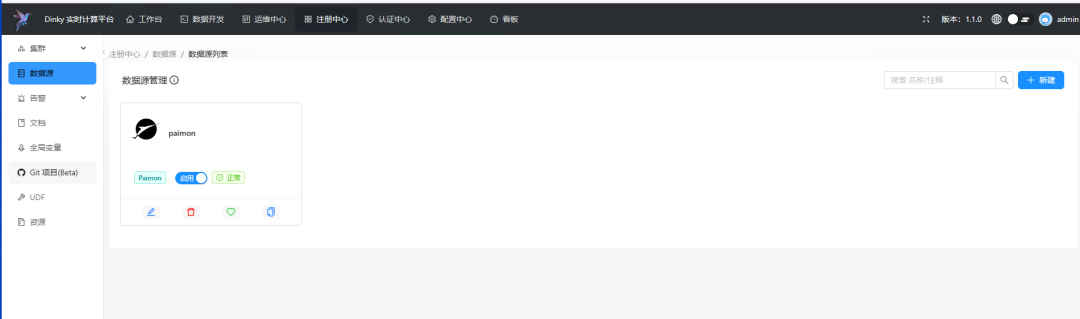

warehouse 参数:表示数据在HDFS上面的存储路径,和我们上面sql里设置的一样即可。
hive-conf-dir 参数:本地hadoop配置路径。
五、查看 Paimon 元数据
在数据开发页面左侧点击数据源,下拉列表选择我们刚刚建立的paimon数据源。
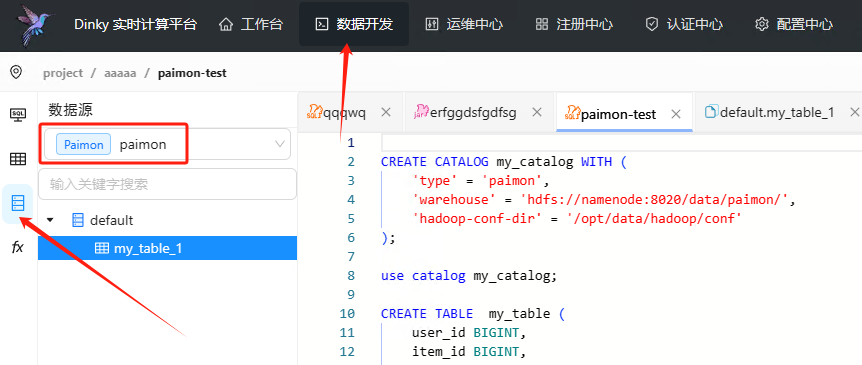
选择对应的表,即可看见元数据啦!
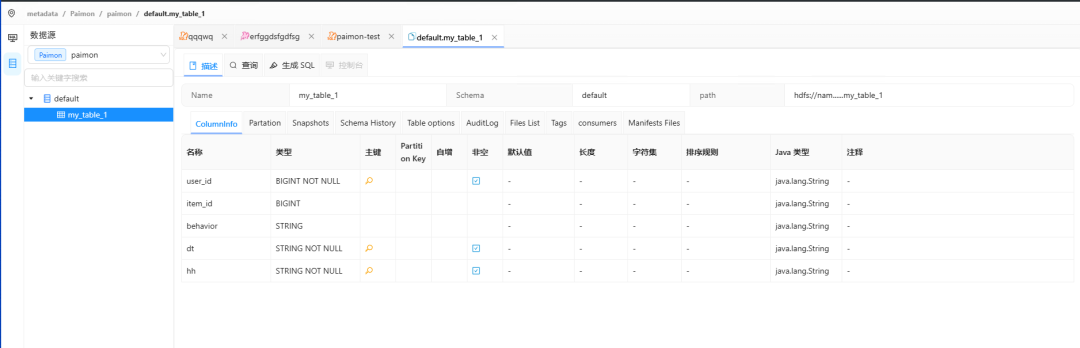
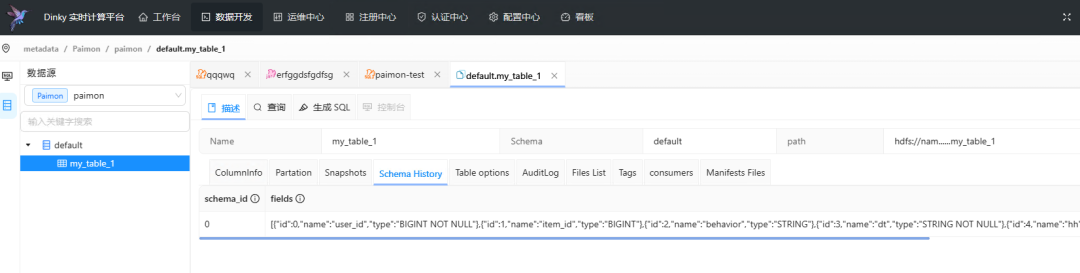
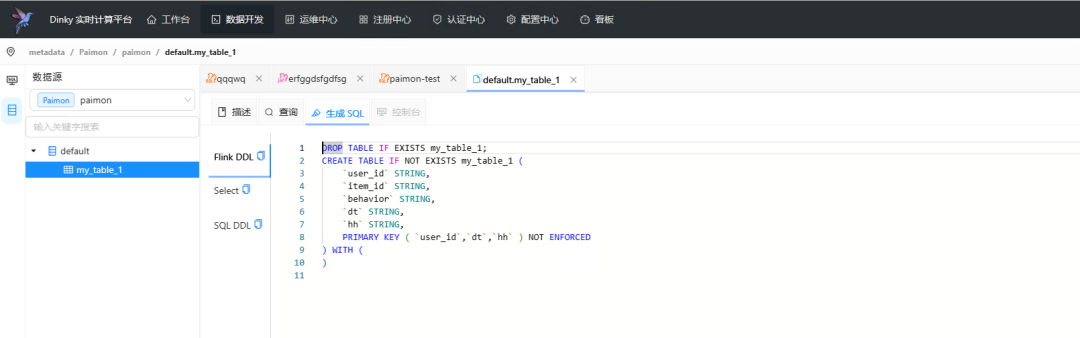
能看到非常多的内容,再也不用在sql cli内敲命令了!╰(°▽°)╯
六、S3/OSS/COS/OBS 的 Paimon
首先 S3/OSS/COS/OBS 都是兼容S3协议的,所以我们只需要创建时候选择S3类型就可以啦。
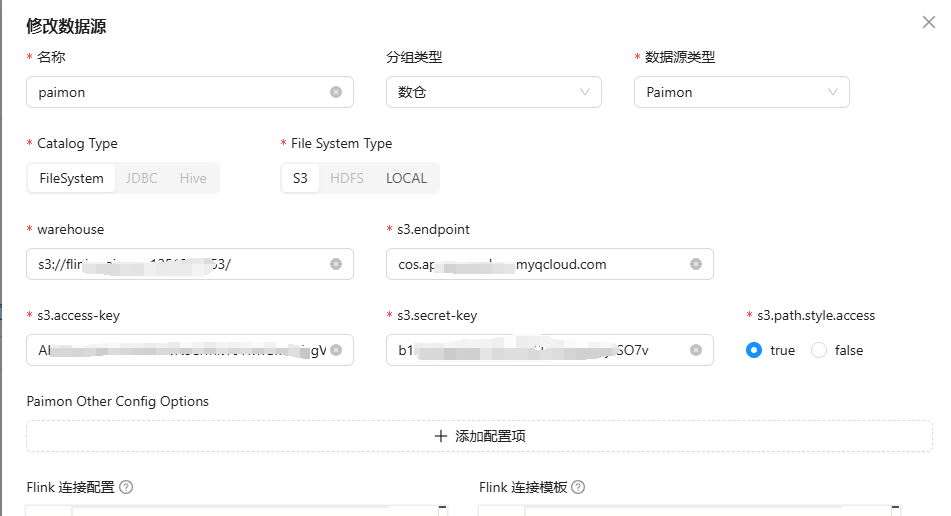
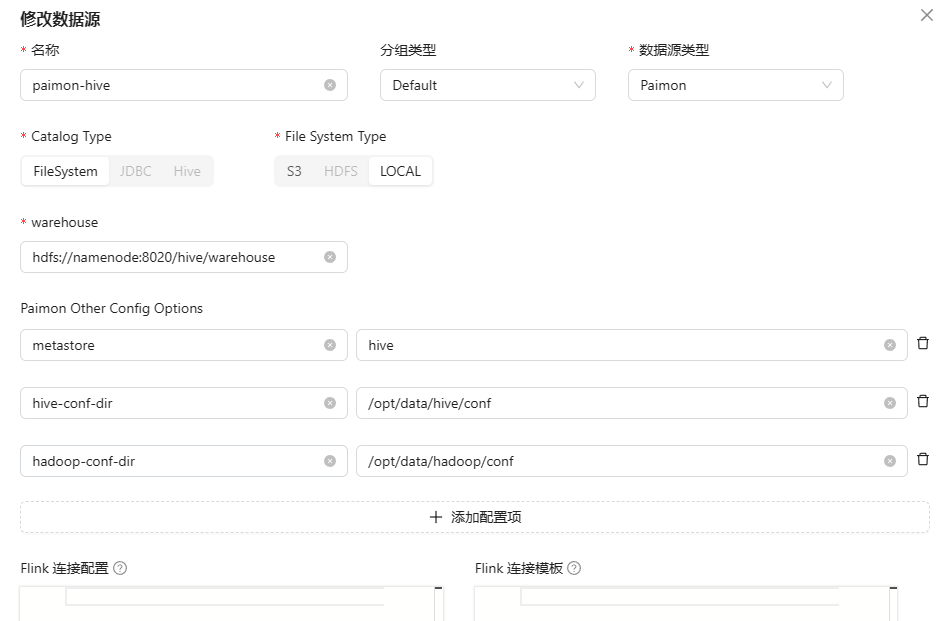
七、读取 Paimon on Hive
其余操作都一样,数据源需要做如下修改:
| 参数 | 说明 | 示例 |
| warehouse | hive的存储路径 | hdfs://namenode:8020/hive/warehouse |
| metastore | 指定元数据为 hive | hive |
| hive-conf-dir | Hive 配置文件路径 | /opt/data/hive/conf |
| hadoop-conf-dir | Hadoop 配置文件路径 | /opt/data/hadoop/conf |
交流
欢迎加入 Dinky 社区交流问题与分享经验。
QQ社区群:543709668,申请备注 “ Dinky+企业名+职位”,不写不批。
微信官方群:添加 wenmo_ai ,申请备注“ Dinky+企业名+职位”,不写不批谢谢。


扫描二维码获取
更多精彩
Dinky开源

