




一、前言
Elasticsearch是目前使用最广泛的开源搜索引擎之一,它具有分布式、高可用、快速、可扩展等优点。在中文搜索领域,Elasticsearch同样表现出色,其中最重要的一个因素就是中文分词器的支持。本文将介绍部分Elasticsearch中文分词器的使用方法。
二、什么是分词器?
分词器(Analyzer),顾名思义就是一种用于将文本转换为单词或词条 (term/token) 的工具,在ES中分词(Analysis)过程是通过分词器来实现的。
比如,举个简单的例子,用户输入Chinese Dictionary, 分词器会将这个词语拆分成两个单独的单词,分别是 chinese 和 dictionary,同时在此过程中也会将其转换成小写。
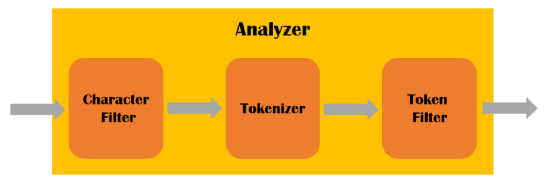
ES的分词器主要是由三个部分组成的:
Tokenizer(分词器):将文本拆分为单词或词条的组件。Elasticsearch提供了许多内置的分词器,例如标准分词器、简单分词器、正则表达式分词器等。
Token Filter(分词过滤器):在分词器生成的单词或词条基础上进行处理的组件。例如,停用词过滤器可以删除常用单词(例如"a"、"an"、"the")、大写转小写、增加同义语,以便将精力集中于更重要的单词。
Character Filter(字符过滤器):在文本被分析之前,对其进行预处理的组件。例如,HTML字符过滤器可以从HTML文本中删除标记,以便只留下纯文本。
分词器三个部分的执行顺序如下图所示:
内置分词器
Standard Analyzer - ES的默认分词器,按照单词分类并进行小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Pattern Analyzer - 正则表达式,默认 \W+
Language - 提供了 30 多种常见语言的分词器
Customer Analyzer 自定义分词器
这些内置分词器擅长处理单词和字母,但是对于处理中文的话,就显得有些捉襟见肘了,难以满足我们的要求。




