





Oracle优化器根据数据库对象统计信息来评估访问特定数据的成本,这些信息主要分为三个维度:
- 表、索引等对象级统计信息,包含表行数、平均行长、索引页块数量等,
- 列、字段等统计信息,包含字段的唯一值数量、空值数量、字段最大值最小值等;
- 数据字典、固定对象以及系统级的统计信息。
大多数情况下这些信息是够用的,但是当列数据分布不均匀时,优化器对于某些列值的评估不够准确,导致SQL执行效率问题。这就是直方图的设计初衷。
直方图的作用
优化器默认数据分布是均匀的,没有更详细的信息时,其基于唯一值来(1/NDV -- Number of Distinct Values)评估数据的选择度。比如一张表有1000行数据,某个列的Num Distinct值为100,则其选择度为1/100,也就是说基于这个列的等值查询,优化器认为会返回10 (1000 * 1/100)行数据。
但现实世界往往没有这么简单,如果这张表是用来记录某个中学全年级学生考试成绩,现在需要分别统计分数为80分和30分的学生人数。按照实际的经验,0~50分的很少,95~100的可能也不多,大多数数据可能会位于70~90分之间。所以以下两条SQL的执行成本是相同的吗?

查询10分的学生人数可能是个位数,甚至为零,这个时候选择索引扫描是高效的;80分的学生人数则可能达到500人,占据这张表的80%数据量,这个时候使用全表扫描更加合理。
这个场景下,优化器如何来评估最优的执行计划呢?Oracle对这个问题的解决方案是直方图。
直方图是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况,一般横轴表示数据类型,纵轴表示该类型数据出现的频率。针对数据分布不均匀的场景,Oracle利用直方图来表示字段值的分布信息,以帮助优化器评估出更优的路径。
直方图的分类
为了更好的应对不同的场景,Oracle 11g及之前的版本定义了两种类型的直方图:Frequency Histograms和Height Balanced Histograms。
Frequency Histograms
Frequency直方图最多使用254个Bucket (也称为 END POINT) 来存储数据的分布,当一张表的唯一值跨度小于254时,每个唯一值都可以用一个独立的Bucket来表示。比如上面的学生成绩表,最多只有100个不同值,这种直方图称为Frequency Histograms,能够精确的呈现每个值的分布情况。
Height Balanced Histograms
如果唯一值大于254,没有足够的Bucket表示所有的值,则需要采用稀疏策略,将数据划分为不同的区间对应到相应的Bucket中。Height Balanced直方图的每个Bucket包含相同数量的唯一值,通过每个Bucket中最高值和最低值来计算数据的分布。
举个例子,帮助大家更好的理解这两个概念。
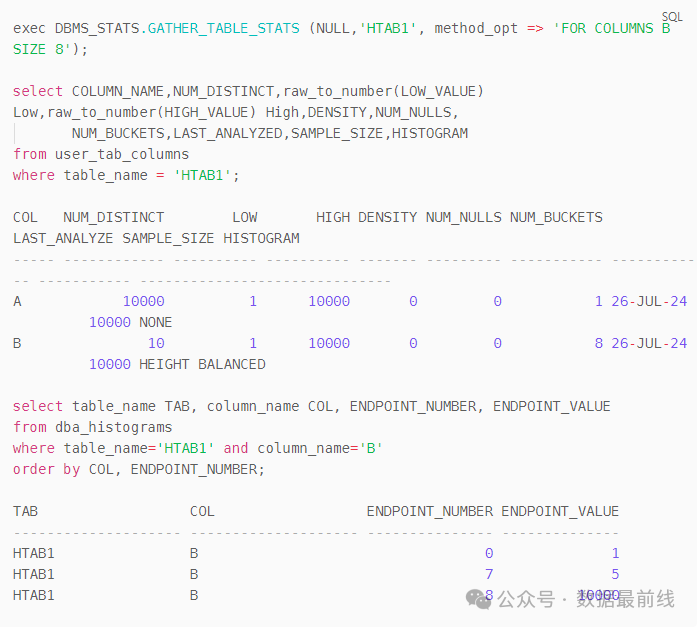
准备1张测试表,其中b=5的数据9991条,b=1..4和9996..10000的值各1条。

收集该表直方图,因为唯一值只有10个,所以生成了FREQUENCY直方图。

这里ENDPOINT_VALUE表示的是列的唯一值,ENDPOINT_NUMBER则代表的是累计的行数。
- 当ENDPOINT_VALUE=2时,ENDPOINT_NUMBER=2,在它之前的ENDPOINT_NUMBER=1,说明ENDPOINT_VALUE=2这个值只出现了一次;
- 当ENDPOINT_VALUE=5时,ENDPOINT_NUMBER=9995,在它之前的ENDPOINT_NUMBER=4,说明ENDPOINT_VALUE=5这个值出现了9995-4=9991次。
接下来我们设置B列的Bucket数量为8,模拟Bucket数量不够的情况。
这个时候创建出来的HEIGHT BALANCED直方图,HEIGHT BALANCED直方图的每个Bucket包含相同数量的值,也是为什么称为高度平衡直方图的原因。上面的例子中,一共10000个值,8个Bucket每个对应1250个值,Bucket 0包含了1-5的值;Bucket 1~7的ENDPOINT_VALUE相同都是5,为了节省存储空间,Oracle没有保存所有的行;Bucket 8包含了5~10000的值。
相信细心的同学已经看出来了,Bucket 0和Bucket 8中其实也包含了5的数据,并且5的次数还不少。为了区分这个这种情况,Oracle又引入了Non-popular values和Popular values的概念。
- Non-popular values是指某个ENDPOINT_VALUE仅在一个Bucket中出现,因此它的选择度是 1/所有Non-popular的数量;
- Popular values则是指这个ENDPOINT_VALUE在多个Bucket中出现,比如上面例子中的5。在计算选择度时,Popular values需要通过它在所有ENDPOINT中的占比来计算。
不过这种方案也并不是完美的,并不能覆盖到所有的场景。比如有些值出现的频率比较高,几乎占满了整个Bucket,但是又没有分布到两个Bucket,这种值不会被认为是Popular values,选择度按照Non-popular values的算法来进行,由此可能会对优化器评估产生错误的影响,为此12c之后引入了Hybird直方图。

数据最前线
身边的数据架构师
