






01
论文概述
多样化的问题类型:问题回答任务有多种不同的形式,包括事实性问题与观点问题、简单查找与多跳推理、单一答案与实体列表、直接回答与长形式回答等。现有的方法,尤其是依赖大型预训练语言模型(LLM)的方法,在处理信息需求的复杂性和证据频率方面存在局限性。
支撑证据的广度和深度:当前的基于检索增强生成(RAG)的架构在利用外部源方面存在限制,尤其是在结合不同模态的证据以推断正确和完整的答案方面。
长尾实体和复杂信息需求:大型语言模型在回忆不受欢迎或长尾实体的信息方面存在困难,且主要用于直接查找,而不是连接多片证据。
计算成本和能源消耗:现有的基于大型语言模型的方法在计算成本和能源消耗方面非常高。
问题理解:自动将用户问题转换为结构化的信息需求表示,以指导证据检索。
证据重排和过滤:在将证据输入答案生成之前,对检索到的证据进行重排和过滤。
答案生成:使用适度大小的语言模型从过滤后的证据中提取忠实的答案。
02
相关工作
检索增强生成 (RAG): RAG作为一种增强大型语言模型(LLM)事实性的方法,通过结合显式的检索步骤(如网页搜索或知识图谱查询)来提供给LLM top-ranked结果。
检索者-阅读架构:与RAG紧密相关的是检索器-阅读器架构,它使用神经网络作为“阅读器”来处理检索到的内容。
跨模态学习:涉及将知识图谱与文本源结合使用的研究,使用基于图的方法、神经学习和语言模型。
联合利用不同数据源:研究同时利用文本、知识图谱和表格(包括CSV和JSON文件)的工作,如UniK-Qa系统,Spaghetti/SUQL项目,Matter方法,STaRK基准测试
问题理解:研究自动将用户问题转换为结构化表示以指导证据检索的工作,如使用BART模型。
证据重排和过滤:研究使用图神经网络(GNNs)或交叉编码器(CEs)来迭代减少检索到的证据,以提高答案生成阶段的效率和准确性。
跨领域问题回答:研究在不同领域和类型的数据源上进行问题回答的系统,如CompMix基准和TimeQuestions基准。
03
核心内容
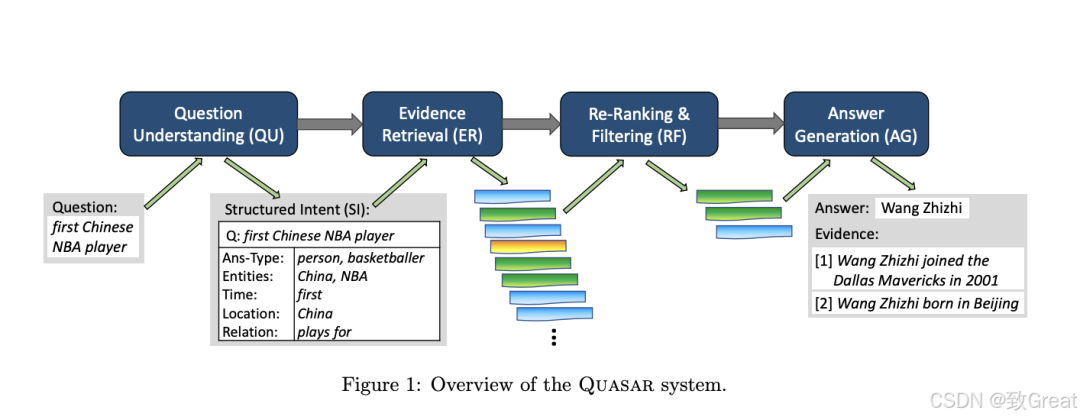
2. 证据检索(Evidence Retrieval, ER)
3. 重排和过滤(Re-Ranking & Filtering, RF)
4. 答案生成(Answer Generation, AG)
最后阶段使用一个适度大小的语言模型(如LlaMA-3.1模型),以检索增强的方式生成答案。具体来说,将问题的结构化意图和筛选后的顶部证据片段作为提示输入到语言模型中,生成最终答案。
总体而言,Quasar通过结合问题理解、跨源证据检索、证据的重排和过滤以及检索增强的答案生成,提供了一个高效且有效的解决方案,以应对跨多种数据源的问题回答挑战。
04
论文实验
1. 实验设置
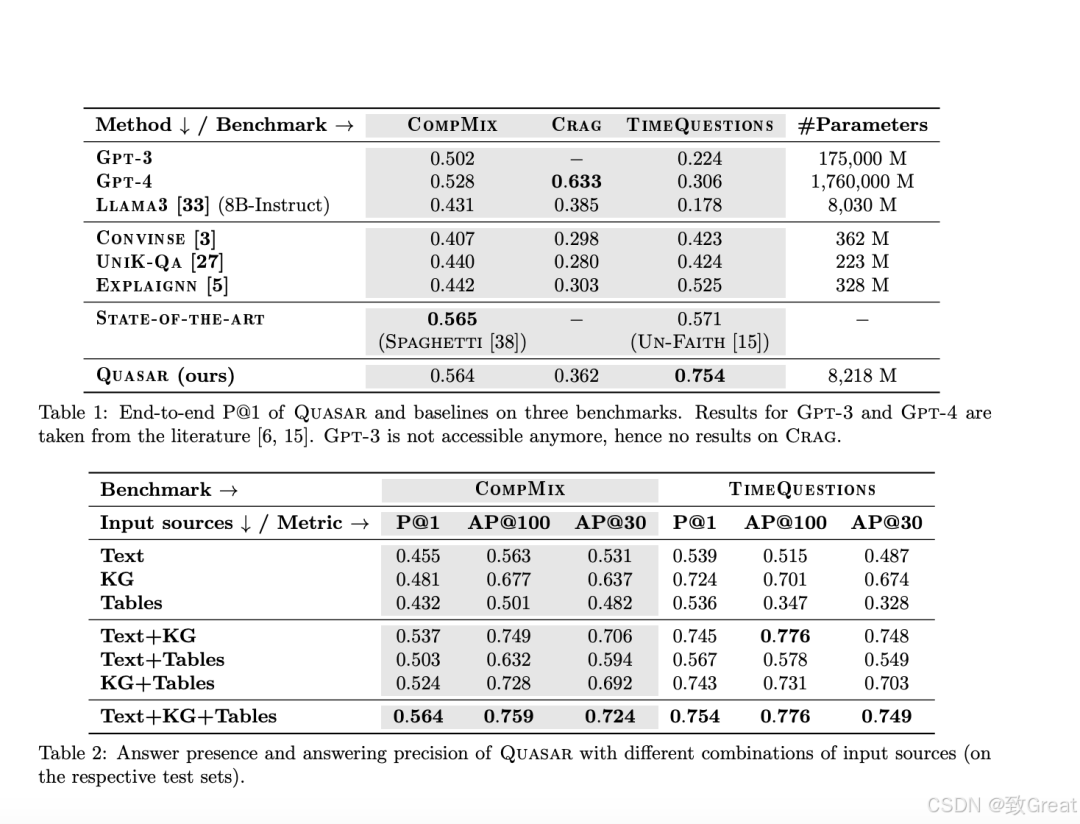
基准测试:实验使用了三个具有不同特性的问题基准测试,CompMix:专为评估跨异构源操作的QA系统设计的基准,包含9,410个问题,其中2,764个用于测试;Crag:最近发布的RAG基准测试集的子集,用于测试实体中心的问题,不依赖实时网络数据;TimeQuestions:一个时间问答基准,要求对时间有深入理解和推理,包含16,181个问题。
基线方法:与Quasar进行比较的其他方法包括直接使用的LLMs:Gpt-3, Gpt-4, Llama3;异构QA方法:Convinse, UniK-Qa, Explaignn;来自文献的最新方法:Spaghetti和Un-Faith。
评估指标:主要使用精确度@1(P@1)作为评估指标,并在Crag上手动注释答案正确性。同时,还计算了答案出现率(AP@k)和在顶部k个证据中的平均倒数排名(MRR@k)。
2. 主要结果
3. 结果分析
异构源集成的重要性:通过比较不同输入源组合的端到端回答性能,结果表明所有类型的源都有贡献,以Text+KG+Tables的组合表现最佳。
统一检索对性能的增强:通过比较不同源类型的顶部证据与全局排名的方法,发现默认的全局排名方法表现更好。
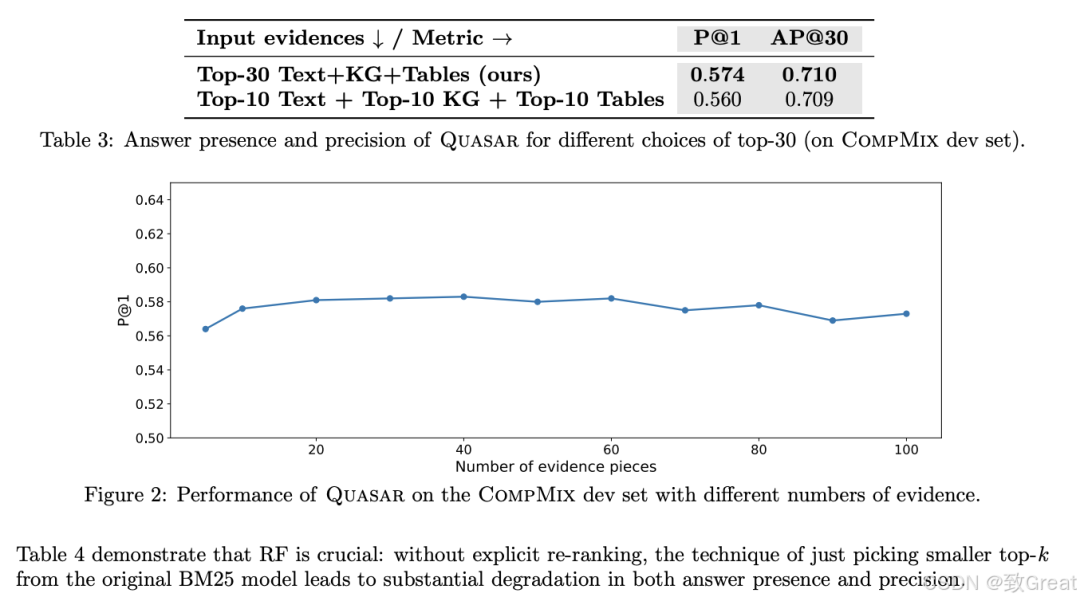
少量证据的效果:研究了输入到AG阶段的证据数量对性能的影响,发现存在一个最佳证据数量(例如30个),既能保证答案出现率,又不会因过多证据而降低性能。
重排研究:通过不同的RF策略进行消融研究,发现明确的重排步骤对于保持高答案出现率和精确度至关重要。
SI的质量:通过检查一些问题及其SI的例子,评估了SI的质量和鲁棒性,发现基于ICL的SI更为完整,而基于BART的SI更侧重于主要槽位。
4. 限制和挑战
这些实验全面评估了Quasar系统在处理跨异构数据源的问题回答任务时的有效性和效率,并与现有的一些先进方法进行了比较。通过这些实验,论文展示了Quasar在保持较低计算成本的同时,能够达到与大型GPT模型相当或更好的答案质量。
05
编者简介

