




作者:Digital Observer(施嘉伟)
Oracle ACE Pro: Database
PostgreSQL ACE Partner
11年数据库行业经验,现主要从事数据库服务工作
拥有Oracle OCM、DB2 10.1 Fundamentals、MySQL 8.0 OCP、WebLogic 12c OCA、KCP、PCTP、PCSD、PGCM、OCI、PolarDB技术专家、达梦师资认证、数据安全咨询高级等认证
ITPUB认证专家、PolarDB开源社区技术顾问、HaloDB技术顾问、TiDB社区技术布道师、青学会MOP技术社区专家顾问、国内某高校企业实践指导教师
现象描述
2024年3月12日凌晨接到客户通知数据库异常。01:59开始排查。节点一操作系统于0:38一直夯住,客户在1点40多手动重启服务器,数据库集群于01:51恢复正常。
问题详细诊断
查看集群日志,发现出现访问磁盘超时、磁盘检测hang的情况。初步诊断为节点一与磁盘组存储链路出现异常,后检查发现一块OCR磁盘采取NFS方式挂载,系统日志显示出现NFS服务端未响应,尝试重连。
数据库层面排查
00:10分集群CSSD日志出现磁盘超时告警:

磁盘无响应时间增大并持续至0:38 ,节点一被驱逐,01 :51 分时重新启动:
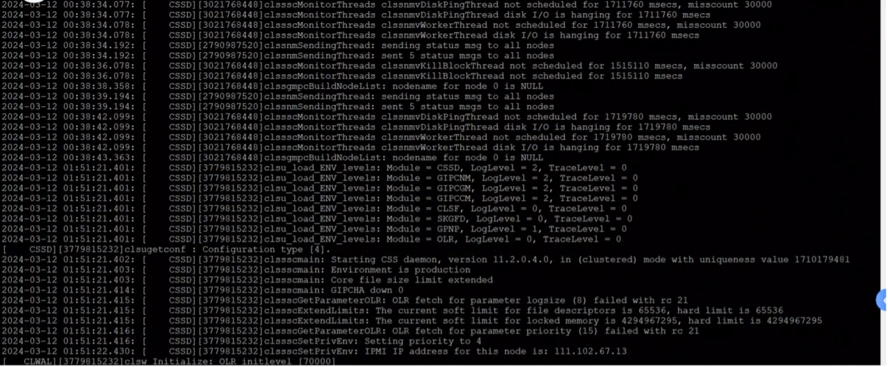
判断为节点一无法访问OCR 磁盘组导致发起驱逐节点以一的动作,但是当时操作系统负载已经非常高,已经无法自动重启。
节点二日志显示,节点一由于无磁盘心跳在00:39 分被重启,但是事实上节点一此时已经假死:

事发时节点一数据库负载情况:
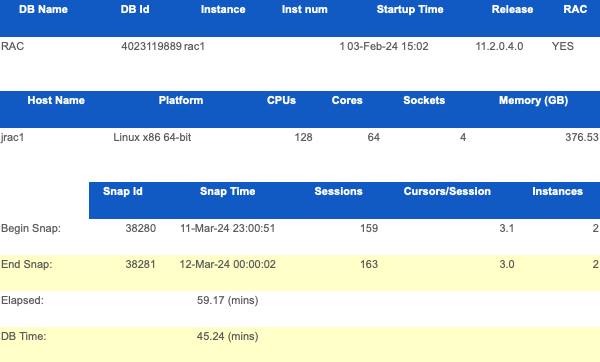
数据库分析:
我们收集了节点一数据库在事发前一个小时的数据库性能报告。
节点一平均会话数:161
系统实际共有 128 个 CPU (其中 4 个物理 CPU )。在不考虑 session 的情况下,系统在 59.19 分钟内,数据库实际消耗时间为:45.24 钟,CPU 在数据库上消耗的时间(DB Time) 占运行总时间的(0.6% ),CPU 系统压力非常轻。
二节点也是如此,负载非常轻:

总结:数据库本身不存在性能问题。
主机系统层面排查
主机日志在0:10 之前到0:39 存在一些cpu 问题的信息 INFO: rcu_sched self-detected stall on CPU
检查操作系统日志发现NFS 服务出现无响应:

OSW 记录操作系统CPU 的队列很高且不断增长,但使用率很低:

故障原因
经上述日志判断,本次故障是由于高负载,导致操作系统假死,节点一数据库实例无法对外提供服务。整体过程如下:0:10 之前主机开始存在cpu 报错, INFO: rcu_sched self-detected stall on CPU ,持续一段时间后,cpu 队列一直堆积。0:13 主机报错 kernel: nfs: server
而主机cpu load average 过高,并且当前cpu 使用偏低。获取load average 是观察系统性能的一种方式,但它并不能提供问题出在哪里的详细信息。例如,高负载可能是由CPU 密集型进程导致,也可能是由于磁盘I/O 、网络I/O 或其他资源争用造成的。。
另外 INFO: rcu_sched self-detected stall on CPU 报错:
通常情况下,RCU 调度器在CPU 上检测到停顿是由于以下几种原因造成的:
1) 高系统负载:当系统负载过高时,CPU 可能会无法及时完成任务,导致RCU 调度器检测到停顿,这个可以理解,事发当时系统负载非常高,显然是负载过高导致的。
2) 硬件问题:可能存在硬件故障或不良硬件,例如内存故障或CPU 故障,导致CPU 无法正常工作,硬件事发当时已经排查,不存在错误。
3) 内核错误:可能存在内核中的错误或漏洞,导致CPU 陷入死锁或长时间无响应。
4) 软件问题:可能是由于应用程序或进程造成的异常情况,例如死锁或无限循环,导致CPU 无法继续正常工作。
建议
(1)主机工程师排查节点一cpu 低使用率,高等待队列(load average )的原因。可以部署相应的队列检测脚本,便于后续排查,例如:
#!/bin/bash
LANG=C
PATH=/sbin:/usr/sbin:/bin:/usr/bin
interval=1
length=86400
for i in $(seq 1 $(expr ${length} / ${interval}));do
date
LANG=C ps -eTo stat,pid,tid,ppid,comm --no-header | sed -e 's/^ \*//' | perl -nE 'chomp;say if (m!^\S*[RD]+\s*!)'
date
cat /proc/loadavg
echo -e "\n"
sleep ${interval}
done
(2 ) 启用kdump ,用来搜集故障现场信息,方便后续再次出现类似事情。
(3 ) 日常关注top load average 项以及stat 为D 的深度睡眠进程、网络流量信息、内存使用信息、cpu 资源等信息。
(4 ) 主机层面部署有效的进程监控,出现异样时及时告警,另外也可以根据告警情况进行合理调整优化,进行告警降噪。
(5 ) 本次故障的原因是cpu 高load average 导致操作系统一系列进程无响应最后操作系统僵死的现象。其中也影响了nfs 进程,引发另外一个问题,如果其他生产的rac 数据库也碰到nfs 服务无响应并且主机其他服务都正常的情况,数据库层面可以采取将nfs 共享文件夹所在的ocr vote 迁移至第三台共享存储来规避由于nfs 不稳定导致的数据库集群问题。
(6 ) 部署有效的数据监控软件,数据库服务出现异常第一时间通过短信告警,也利于事后变更溯源。并且定期检查osw 运行情况,避免因为osw 不运行导致日志没有收集的情况发生。
 # 一级标题
# 一级标题
