





关注我们丨文末赠书

▼点击下方,即可购书
01基础原理
这部分首先介绍了数据库的历史和发展,探讨了云计算对数据库的挑战以及云原生数据库的特点。
然后深入介绍了分布式数据库的基础理论和架构,包括经典的 CAP 理论、一致性算法和典型的分布式数据库技术(OLTP/OLAP/HTAP)。
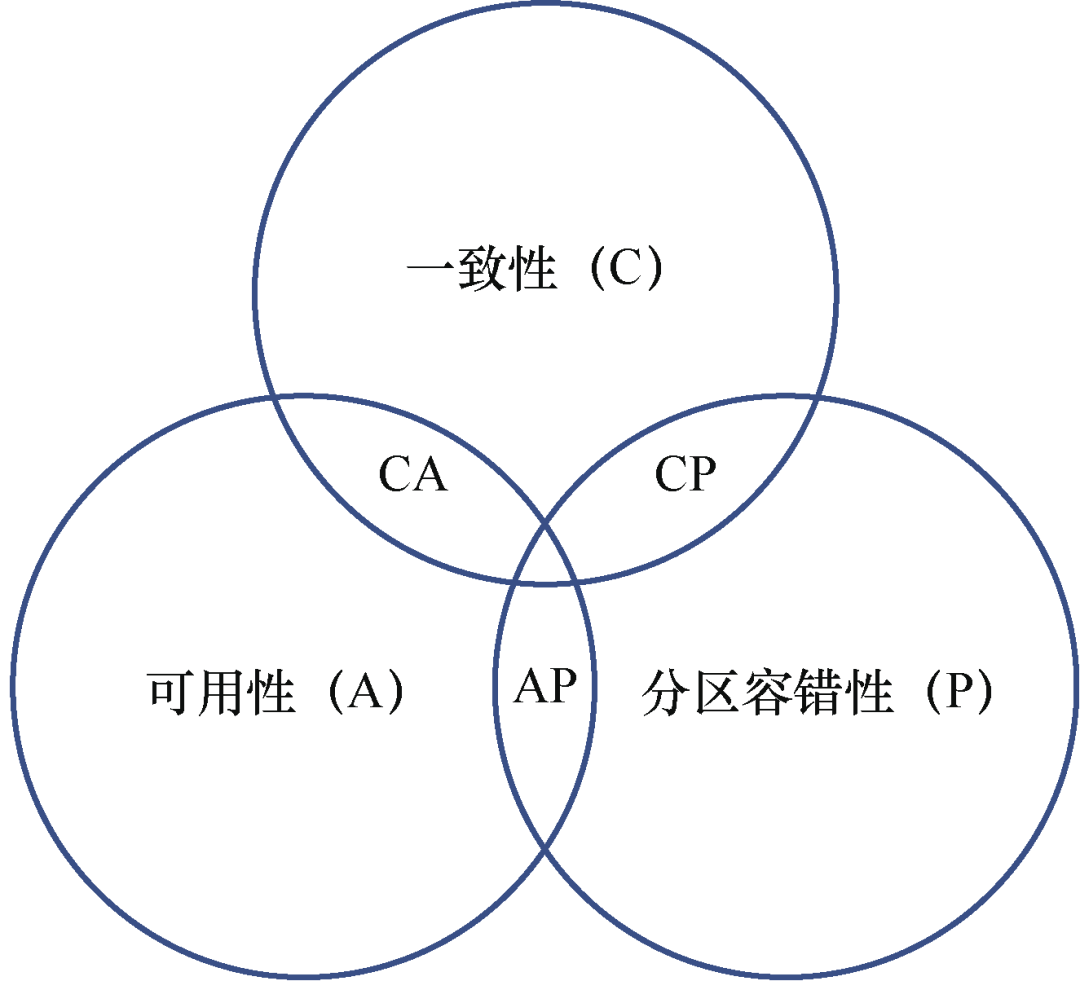
CAP 理论
对于并发控制,详细介绍了基于锁的并发控制、基于时间戳的并发控制、基于验证法的乐观并发控制、MVCC 技术以及快照隔离技术等关键概念。
02深入剖析Greenplum
这部分先是概述了 Greenplum 的总体架构,包括数据库通信协议和核心引擎。接着详细讨论了分布式事务的实现,包括事务隔离、两阶段提交,对 PostSQL 事务处理和状态机进行了细致说明。
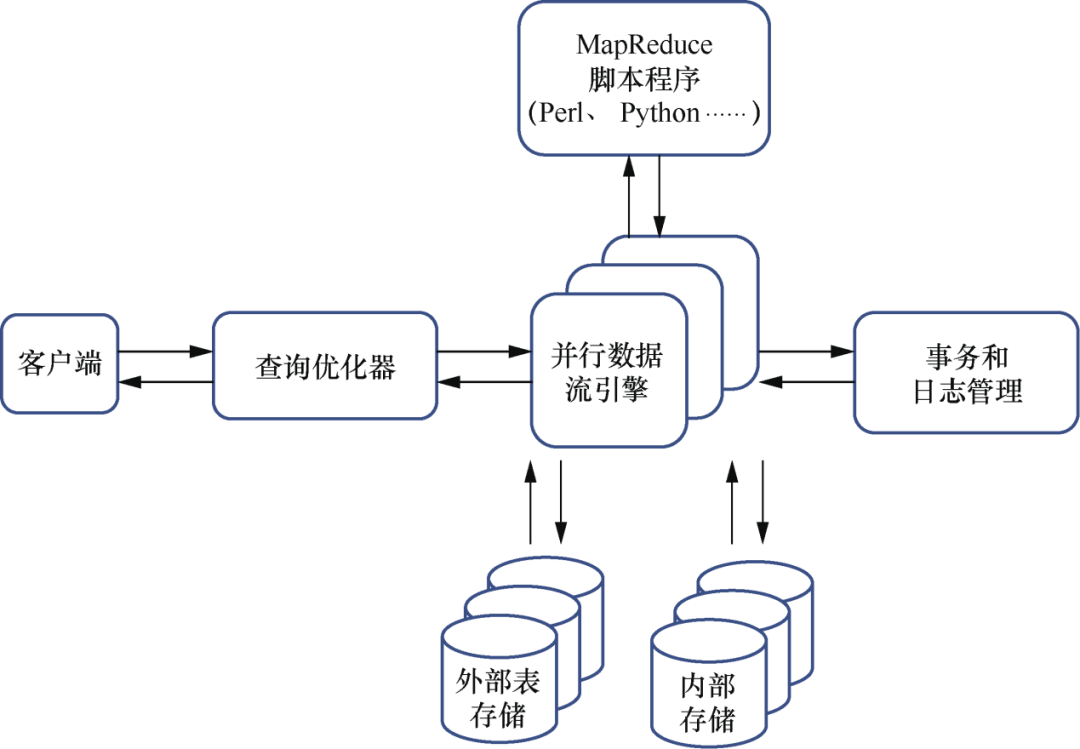
Greenplum 内部逻辑
03数据库和新技术
这部分先介绍了 Greenplum 在云原生数据库方面的尝试,以及 VMware 多云战略对 Greenplum 的影响。探索了 NVM 存储技术、虚拟化技术和容器等新技术给数据库带来的机遇。
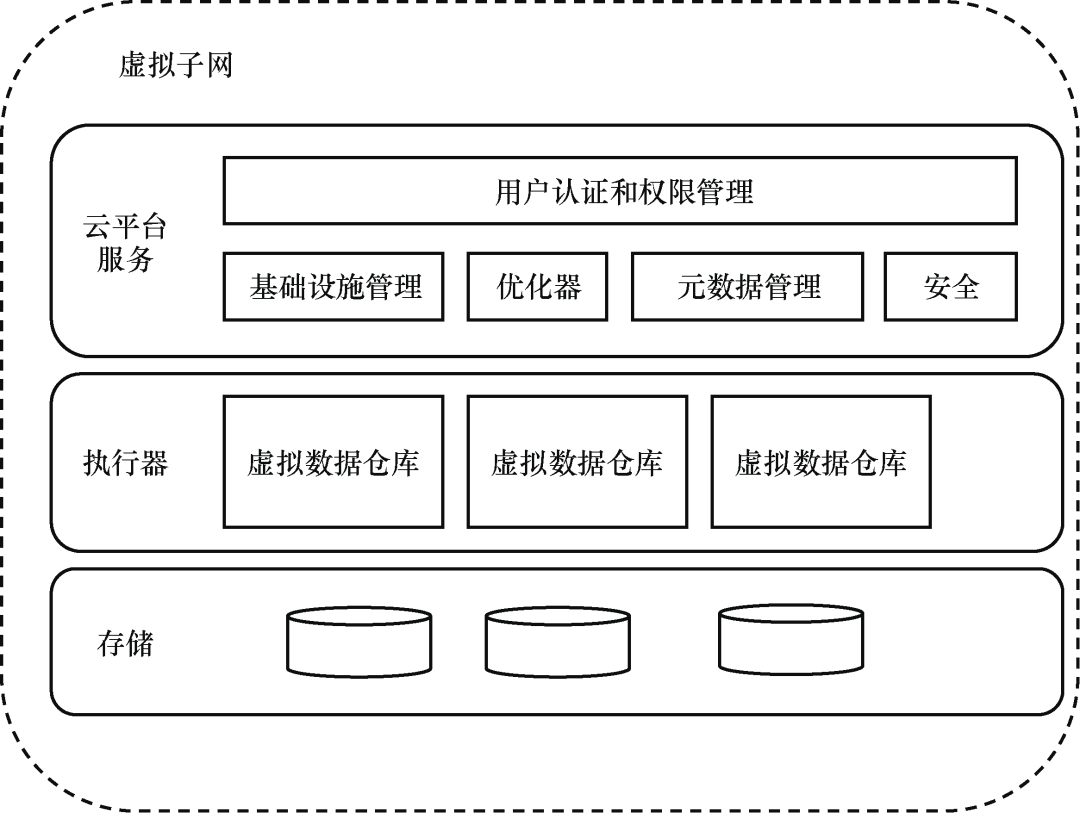
Snowflake 的软件架构
这部分内容使读者能够把握数据库技术的最新发展趋势,并思考如何在新技术的推动下优化和发展数据库系统。
吃透了强悍的 Greenplum,你对云数据库的未来已经有了强大的把握。那么,在云计算及大数据领域,还有不少彪悍的数据库相关产品,而且我国的开源数据库系统表现也非常抢眼,我们来继续深入探索它们吧。

▼点击下方,即可购书
第一部分以 Beam 模型为核心,深入探讨了批处理与流处理数据模型,包括奠定流处理的基本概念,定义专业术语,评估流系统的功能,区分处理时间和事件时间,以及研究常见的数据处理模式等。
还阐释了处理乱序数据的核心概念,利用动画展示时间维度。探讨时间进度的度量、方法及其在流水线中的传递方式,并剖析实际案例中的水位线应用,延续对高级窗口技术和触发器的讨论。
第二部分深化了概念讨论,专注于 “流与表” 的流处理思维模式。阐释流和表的基本概念,构建普适的流表理论。探讨引入持久状态的动因,考察关系代数和 SQL 中的流式含义,对比 Beam 模型与经典 SQL 在表和流设计上的倾向,提出将流式语义整合入 SQL 的途径。
研究多样的连接类型及其在流式上下文中的行为,关注时间有效性窗口这一场景。最后纵览 MapReduce 数据处理系统家族的重大历史,探讨推进流式系统发展的重要贡献。

▼点击下方,即可购书
第一部分先是说明了数据库管理系统(DBMS)在现代生产环境中面临的挑战,以及数据库开发人员角色的演变。通过深入探讨 DBMS 的未来发展方向,读者可以了解到 ShardingSphere 生态及其核心概念。
书中还详细介绍了 ShardingSphere 的架构,包括其分布式数据库架构、Database Plus 理念、部署架构和插件平台,为读者提供了坚实的理论基础。
第二部分专注于 ShardingSphere 的安装与配置。该部分详细介绍了 ShardingSphere-JDBC 和ShardingSphere-Proxy 的安装步骤,以及如何配置它们以满足不同的应用场景。
无论是通过二进制包、Docker,还是通过 YAML 配置,读者都可以获得清晰的指导,确保能够顺利地在现有基础设施中部署和配置ShardingSphere。
第三部分重点介绍 ShardingSphere 的应用与测试。书中介绍了利用 ShardingSphere 进行分布式数据库解决方案的构建、数据库安全加固、全链路监控和数据库网关配置,还提供了丰富的测试场景,包括分布式数据库、读写分离、影子库等。

▼点击下方,即可购书

▼点击下方,即可购书
第一部分是基础知识,对于零基础小白来说,要在这一步掌握时序数据的基础知识,知道 TDengine 的核心特性,包括数据模型、数据写入、数据查询、数据订阅和流计算等。
第二部分是运维管理,主要是TDengine 的功能使用与配置。书中详细介绍了 TDengine 的日常运维管理,包括安装部署、资源规划、图形化管理、数据安全等关键内容。
第三部分深入讲解如何利用 TDengine 进行应用开发,介绍了包括 Java 在内的多种编程语言的连接器使用、订阅数据方法,以及使用 C 语言与 Python 开发自定义函数等高级功能,并说明 TDengine 与 Grafana、Power BI 等第三方工具的集成方法。
第四部分是透彻理解核心技术原理,这是全书的关键内容,书中揭示了 TDengine 的内核设计,详细介绍了从分布式架构到存储引擎、查询引擎、数据订阅,再到流计算引擎的知识。
第五部分是实践案例,书中精心挑选了一系列典型应用场景案例,包括车联网、新能源、智慧油田、智能制造、金融等领域,展示了 TDengine 在实际业务中的具体应用。

分享你对分布式数据库的理解
在留言区参与互动,并点击在看和转发活动到朋友圈,我们将选1名读者获得e读版电子书1本,截止时间12月30日。
