




迁移需求
随着信创政策的落地,越来越多的项目要求将Oracle库数据迁移到DM数据库,往常都是以达梦数据库自带的DTS迁移工具实现迁移,由于当前项目数据量高达7T多,和厂商专家请教交流后,推荐使用SQLark百灵连接实现迁移,比DTS迁移工具更快。现以一个迁移案例来整理总结下使用SQLark百灵连接迁移数据库的过程、遇到的问题及处理办法。
库类型 | 库架构 | 实例 | 端口 | 用户名密码 | 数据量 | ||
源库 | 192.168.3.191 | Oracle11.2.0.4 | 单点 | xjtopicis | 1521 | topicis/oracle | 13.65G |
目标库 | 192.168.3.175 | DM8 | 单点 | topicis | 9999 | topicis/Topnet@123 |
迁移前准备
源库
统计oracle数据库信息
统计基本信息
--统计页大小 select name,value from v$parameter where name ='db_block_size'; 输出: name value db_block_size 8192 --查询编码格式 select * from v$nls_parameters a where a.PARAMETER='NLS_CHARACTERSET'; 输出: PARAMETER VALUE NLS_CHARACTERSET AL32UTF8复制
统计要迁移用户的数据量
统计数据库中对象及表数量
统计各类对象数量
--统计要迁移用户的数据量 select round(sum(bytes) / 1024 / 1024 / 1024, 2) || 'G' from dba_segments where owner in ('TOPICIS') ; 输出: ROUND(SUM(BYTES)/1024/1024/1024,2)||'G' 13.65G复制
统计表中记录数
--根据指定用户统计用户下的各对象类型和数目 select object_type,count(*) from all_objects where owner='TOPICIS' group by object_type order by 1;复制
方式一:借助系统表
select table_name, num_rows from dba_tables t where t.owner = upper('TOPICIS') order by 1;复制
方式二:借助移植辅助表
--创建移植辅助表,统计指定用户下所有的对象并插入到辅助表中 create table oracle_objects(obj_owner varchar(100),obj_name varchar(100),obj_type varchar(50)); insert into oracle_objects select owner,object_name,object_type from all_objects where owner='TOPICIS'; select * from oracle_objects; --创建移植辅助表,统计每个表的数据量并插入到移植辅助表中 CREATE TABLE oracle_tables ( tab_owner VARCHAR ( 100 ), tab_name VARCHAR ( 100 ), tab_count int ); BEGIN FOR rec IN ( SELECT owner, object_name FROM all_objects WHERE owner = 'ITPUX' AND object_type = 'TABLE' ) loop BEGIN execute IMMEDIATE 'insert into oracle_tables select ''' || rec.owner || ''',''' || rec.object_name || ''',count(*) from ' || rec.owner || '.' || rec.object_name; EXCEPTION WHEN others THEN dbms_output.put_line ( rec.owner || '.' || rec.object_name || 'get count error' ); END; END loop; END; select * from oracle_tables;复制
目标库
初始化实例时注意事项
数据库参数检查:
- 字符集需要注意默认采用GB18030,如果源端是UTF8注意初始化实例时字符集为UTF8
- 大小写需要敏感(Oracle是大小写敏感的)
- 修改达梦数据库兼容ORACLE参数(初始化实例后更改参数即可)
- 需要使用单独的业务表空间,创建用户和表空间
- 生产环境建议创建30G一个数据文件,关闭自动扩展(这点执行把控,我采用的是开启自动扩展,数据文件最大30G)
- 区大小建议16页,页大小建议32k(避免源库字段内容长目标端容纳不下插入报错)

检查基本参数
初始化实例时,字符集和大小写敏感参数一定要选对,不然得重新初始化,慎重慎重慎重。
目的库达梦空闲连接数,测试环境建议设置为 300 或以上,建议和源库一样或比源库多,否则可能导致后续迁移失败;
--登录数据库,注意端口 disql sysdba/SYSDBA:9999 --检查基本参数 set pagesize 999 select '实例名称' 数据库选项,INSTANCE_NAME 数据库集群相关参数值 FROM v$instance union all select '数据库版本',substr(svr_version,instr(svr_version,'(')) FROM v$instance union all SELECT '字符集',CASE SF_GET_UNICODE_FLAG() WHEN '0' THEN 'GBK18030' WHEN '1' then 'UTF-8' when '2' then 'EUC-KR' end union all SELECT '字符数据类型' NAME, CASE VALUE WHEN 0 THEN 'BYTE' WHEN 1 THEN 'CHAR' end FROM v$parameter WHERE name like '%LENGTH_IN_CHAR%' union all SELECT '页大小',cast(PAGE()/1024 as varchar) union all SELECT '簇大小',cast(SF_GET_EXTENT_SIZE() as varchar) union all SELECT '大小写敏感',cast(SF_GET_CASE_SENSITIVE_FLAG() as varchar) union all select '空格填充模式',cast(BLANK_PAD_MODE as varchar) union all select '最大连接数',cast(SF_GET_PARA_VALUE(1,'MAX_SESSIONS')as varchar) union all select '数据库模式',MODE$ from v$instance union all select '数据库兼容模式',cast(SF_GET_PARA_VALUE(2,'COMPATIBLE_MODE') as varchar) union all select '唯一魔数',cast(permanent_magic as varchar) union all select 'LSN',cast(cur_lsn as varchar) from v$rlog ;复制
输出如下:
LINEID 数据库选项 数据库集群相关参数值 ---------- ------------------ ------------------------------ 1 实例名称 TOPICIS 2 数据库版本 DM Database Server x64 V8 3 字符集 UTF-8 4 字符数据类型 BYTE 5 字符数据类型 CHAR 6 页大小 32 7 簇大小 32 8 大小写敏感 1 9 空格填充模式 1 10 最大连接数 1500 11 数据库模式 NORMAL 12 数据库兼容模式 2 13 唯一魔数 2003516224 14 LSN 41319复制
检查兼容ORACLE参数
如果已经修改过了可以忽略,如果未修改按该步骤修改
--检查兼容ORACLE参数,若未设置成兼容Oracle参数按以下命令修改 SELECT * FROM V$DM_INI WHERE para_name='COMPATIBLE_MODE'; --更改兼容Oracle参数 alter system set 'COMPATIBLE_MODE' = 2 spfile; 或者 sp_set_para_value(2,'COMPATIBLE_MODE',2); --重启数据库 systemctl restart DmServicetopicis.service --查看参数 PARA_VALUE要等于2 2即Oracle模式 SELECT * FROM V$DM_INI WHERE para_name='COMPATIBLE_MODE'; --参数说明 COMPATIBLE_MODE数据库兼容模式:默认值0,0:none, 1:SQL92, 2:Oracle, 3:MS SQL Server, 4:MySQL, 5:DM6, 6:Teradata, 7:PG复制
创建用户及表空间
检查数据文件位置
SQL> select path from v$datafile; 行号 PATH ---------- --------------------------- 1 /dmdb8/dmdbms/data/topicis8888/topicis/ROLL.DBF 2 /dmdb8/dmdbms/data/topicis8888/topicis/TEMP.DBF 3 /dmdb8/dmdbms/data/topicis8888/topicis/SYSTEM.DBF 4 /dmdb8/dmdbms/data/topicis8888/topicis/MAIN.DBF 已用时间: 31.840(毫秒). 执行号:36500.复制
创建表空间
SQLark百灵工具建议:
- 新建表空间: 建议根据【源库画像】中的【表空间信息】,创建【同名表空间】,数据文件大小和源数据库保持一致,自动扩充设置为打开状态。
- 临时表空间: SQLark 默认开启并发迁移,迁移大数据量表的索引和约束将占用较多临时表空间,请按照实际需求适当增加临时表空间大小。
以下是2种场景,自行选择
场景1:表空间自动扩展
生产环境建议创建能自动扩展的数据文件,大小上限为32G
create tablespace topicis datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis01.dbf' size 1024 autoextend on next 1024 maxsize 32768; --生产环境配置好,可以一次性创建32g大小一个 alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis01.dbf' size 1024 autoextend on next 1024 maxsize 32768; alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis02.dbf' size 1024 autoextend on next 1024 maxsize 32768; alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis03.dbf' size 1024 autoextend on next 1024 maxsize 32768; alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis04.dbf' size 1024 autoextend on next 1024 maxsize 32768; alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis05.dbf' size 1024 autoextend on next 1024 maxsize 32768; alter tablespace topicis add datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis06.dbf' size 1024 autoextend on next 1024 maxsize 32768; --创建索引表空间 create tablespace topicis_idx datafile '/dmdb8/dmdbms/data/topicis8888/topicis/topicis_idx01.dbf' size 1024 autoextend on next 1024 maxsize 32768;复制
场景2:表空间不自动扩展
create tablespace itpux datafile '/dm/dmdata/erpdb/itpux01.dbf' size 30g autoextend off; alter tablespace ITPUX datafile '/dm/dmdata/erpdb/itpux01.dbf' autoextend off; --生产环境配置好,可以一次性创建20g大小一个 alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux02.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux03.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux04.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux05.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux06.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux07.DBF' size 1024 autoextend on next 1024 maxsize 30720; --创建索引表空间 create tablespace itpux_idx datafile '/dm/dmdata/erpdb/itpux_idx01.dbf' size 1000 autoextend off;复制
创建用户并授权
SQLark百灵工具建议:
- 新建用户: 建议与源数据库用户同名。
- 用户授权: 为新建的用户赋予【RESOURCE】 权限,授权后可创建数据库对象。
create user "topicis" identified by "Topnet@123" default tablespace topicis default index tablespace topicis_idx; grant dba to topicis; exit disql 'topicis/"Topnet@123"':9999复制
SQLark百灵工具
目前 SQLark里创建一个迁移任务,单个任务限制数据量30GB,如果项目数据规模超过 30GB,可以将数据分多次、多个任务迁移。期待后面能像OGG那样支持的数据量大一些吧。
SQLark百灵工具介绍
SQLark 是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统,现已支持达梦、Oracle 和 MySQL 数据库。
SQLark 提供了对多种数据库的连接支持,实现跨平台数据库管理的无缝切换;通过直观的可视化界面,轻松实现对模式、表、视图、物化视图、函数、存储过程、触发器、包等多种对象类型的增删改查。SQLark 内置的 SQL 编辑器,基于语法解析,集成智能提示、实时语法检查及语法高亮等功能,提升编写 SQL 语句的效率与准确性;其直观的数据查看与编辑器,使用户能够直观地浏览数据内容并进行即时编辑。此外,SQLark 还集成了数据生成、数据迁移及 ER 图生成等特色功能,助力开发人员更加高效、安全地完成数据管理任务。
支持的数据库:DM 7.0 及以上、Oracle 11g 及以上、MySQL 5.7、8.0
支持的部署模式:本地客户端部署
系统功能
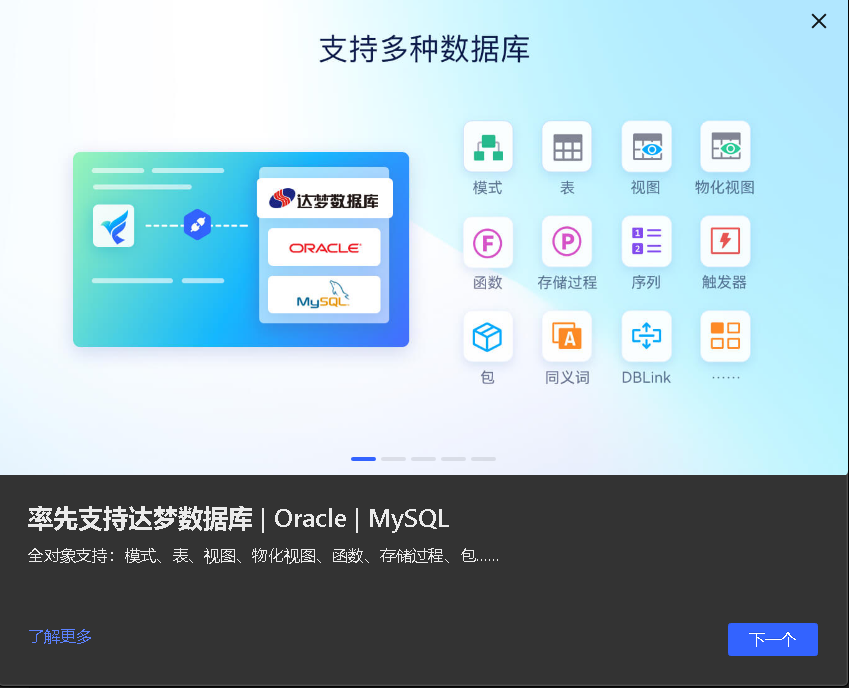
支持多种数据库
丰富的数据库对象支持达梦数据库、Oracle 、MySQL以下对象:
模式、表、视图、物化视图、函数、存储过程、序列、触发器、包、同义词、DBLink、自定义类型
SQL 智能编辑器
SQL 智能编辑器:基于语法语义解析实现代码补全能力,提供精准的 SQL 编码提示。
代码提示和补全:
- 基于 SQL 语法实现对关键字、对象名、别名、 代码块的智能提示和代码补全
- 通过外键关系自动补全整个 JOIN 联表查询语句
- 快速生成 DDL/DML 语句
- 代码内快速查看对象 DDL
- 支持对系统函数的语法和示例查询
辅助开发
SQL格式化 | 快速注释 | 大小写转换
PL/SQL 对象支持
支持函数、存储过程、包等PL/SQL对象的实时语法结构解析,快速定位代码。
丰富的应用场景
不断更新的应用市场,助力你将信创应用开发工作化繁为简
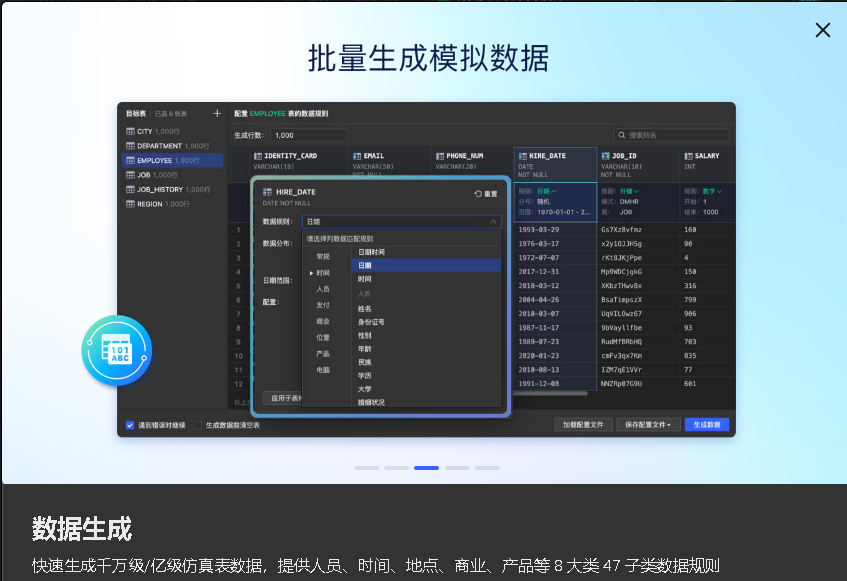
数据生成
快速生成千万级/亿级仿真表数据,助力大型项目 POC 测试
数据导入
从外部文件快速导入数据到目标表
执行计划分析器
辅助分析复杂的执行计划,快速定位慢 SQL 问题
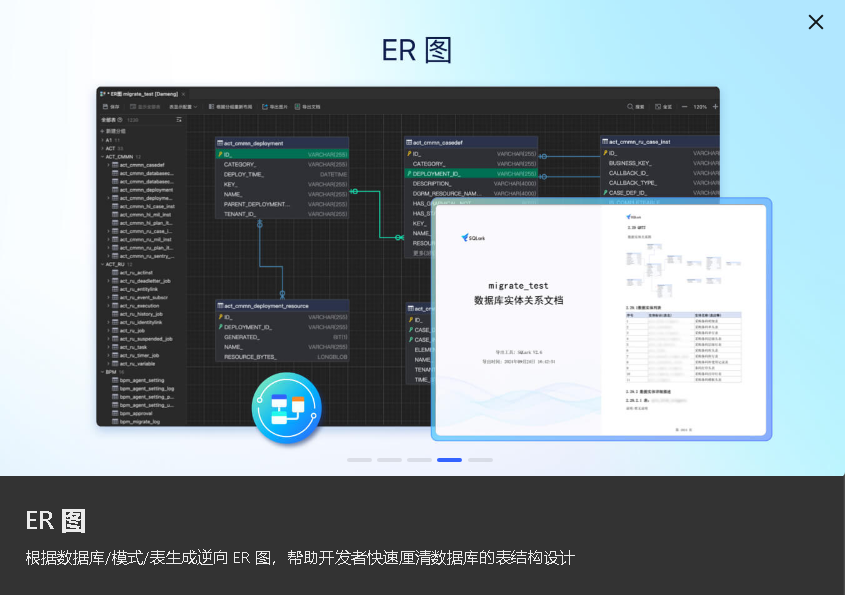
ER 图
根据数据库/模式/表生成逆向 ER 图,帮助开发者快速厘清数据库的表结构设计
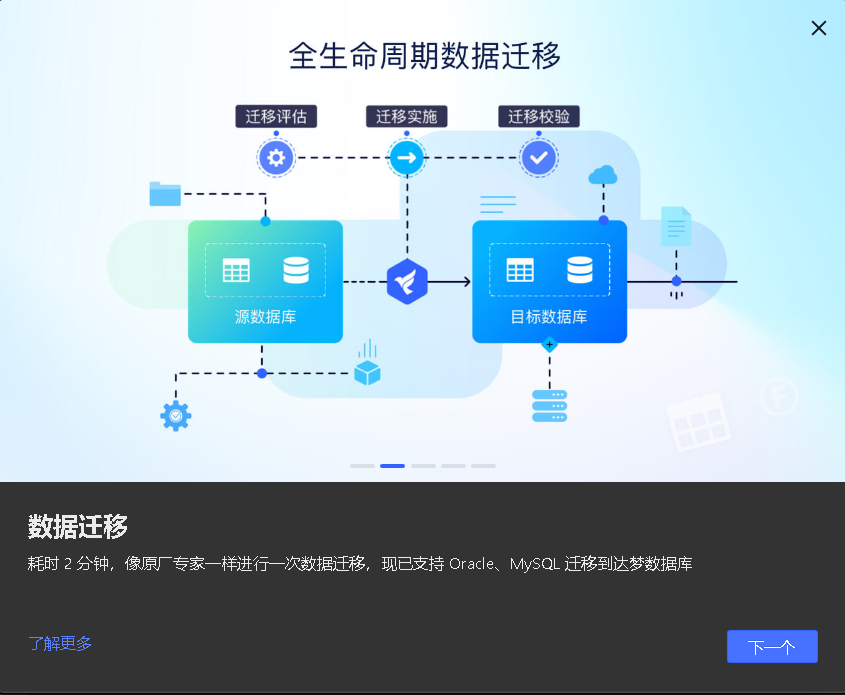
全生命周期数据迁移
SQLark企业版本支持TB级别、集群多节点并发迁移,速度更快、支持的数据规模更大。
提供全生命周期的数据迁移解决方案,一次迁移成功率 90% 以上
1、迁移评估
2、迁移实施
基于迁移策略对数据库对象和表数据开展自动化迁移和语法转换,为迁移异常提供错误分析和修改建议,以任务管理的方式保障迁移工作完成。
- 数据库对象迁移
- 表数据迁移
- 对象改写建议
3、迁移校验
更多功能移步官网。
支持的迁移类型
源数据库版本 | 目标数据库版本 |
Oracle 11g 及以上 | DM 8 系列 |
MySQL 5.7、8.0 | DM 8 系列 |
版本说明
SQLark百灵工具分公测版、企业版,均注册即享客户端永久免费,一年后对数据迁移、ER图等增值服务收取适当费用。
企业版优势如下:
SQLark企业版本支持TB级别、集群多节点并发迁移,速度更快、支持的数据规模更大,但需要联系 SQLark 官方客服 获取企业版序列号,然后去激活。
参考手册
地址:https://www.sqlark.com/docs/zh/v1/data-migration/overview.html

SQLark百灵工具下载并安装
官网免费获取 SQLark:www.sqlark.com ,官网是官方提供的唯一下载路径。
请通过 PC 端访问 SQLark 官网 www.sqlark.comopen in new window,下载安装 SQLark 最新客户端。
解压SQLark_V3.0_win_x86_64.zip并在解压后生成的SQLark_V3.0_win_x86_64目录中运行SQLark_V3.0_win_x86_64.exe。这个地方需要PK下DTS:
支持操作系统 | 支持免安装运行 | |
DTS迁移工具 | Windows、Linux | 支持 |
SQLark百灵迁移工具 | Windows7、macOs 客户端支持 (macOs 12及以上)、 暂不支持Linux | 不支持 |
环境需求 | 最低配置 | 推荐配置 |
操作系统 | Microsoft Windows 7 | Microsoft Windows 10 64位 |
处理器 | 1.6 GHz 处理器 | 2.5 GHz 处理器及以上 |
内存 | 4 GB RAM | 16 GB RAM |
显卡 | 1 GB GPU | 4 GB GPU |
显示器分辨率 | 1024 * 768 显示屏 | 1920 * 1080 显示屏,或更高分辨率显示屏 |
可用磁盘空间 | 不少于 500 MB ,用于安装和数据库驱动扩展 | |
SQLark百灵迁移工具的Logo比DTS迁移工具的Logo好看不少,不过和钉钉的Logo太像,不晓得灵感来自于迅雷还是来自于钉钉,纯属个人唠叨哈。
以下是安装过程:
- 双击打开 .exe 文件。
- 点击 SQLark 许可协议与服务条款,阅读协议,勾选 阅读并同意,点击 自定义安装。

也可以点击“自定义安装“,自行选择安装位置

- 等待安装界面显示 安装完成,点击 立即体验。

SQLark百灵工具中创建数据库连接
目前支持的数据源只局限Oracle Dm MySQL,期待后面支持更丰富的数据库类型。
创建源端数据库连接
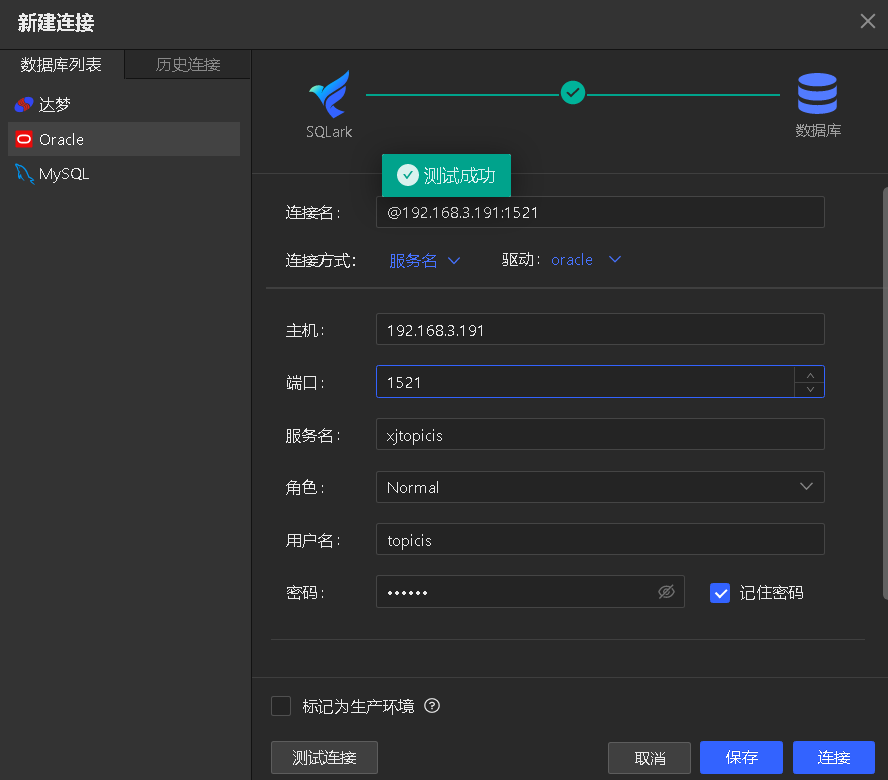
新建源库Oracle数据库连接
创建目标端数据库连接

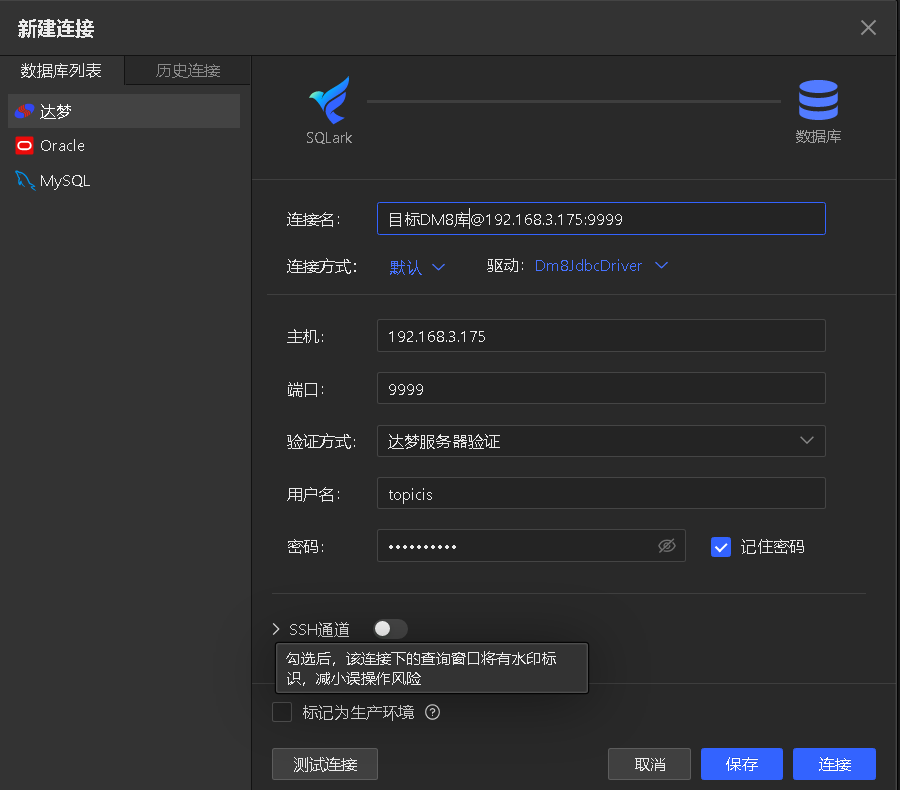
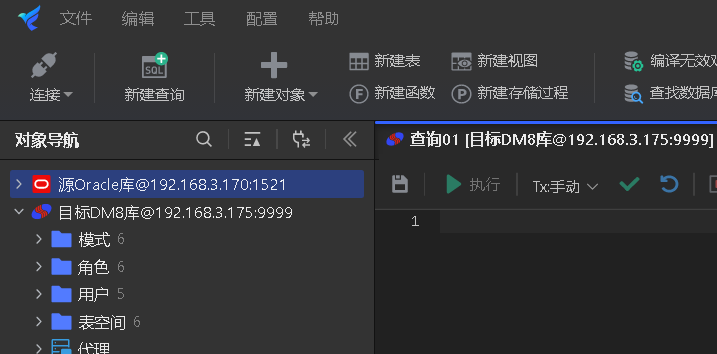
跳转至SQLark百灵工具的迁移WEB界面

或
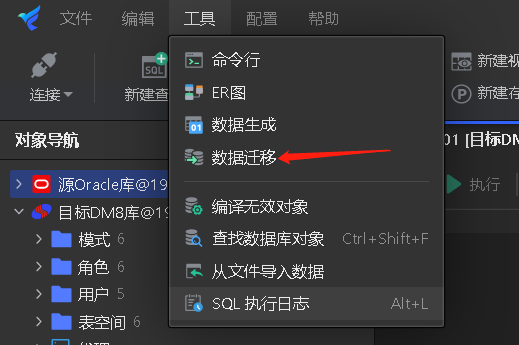
工具--数据迁移 后会跳转至一个WEB界面,如下图:
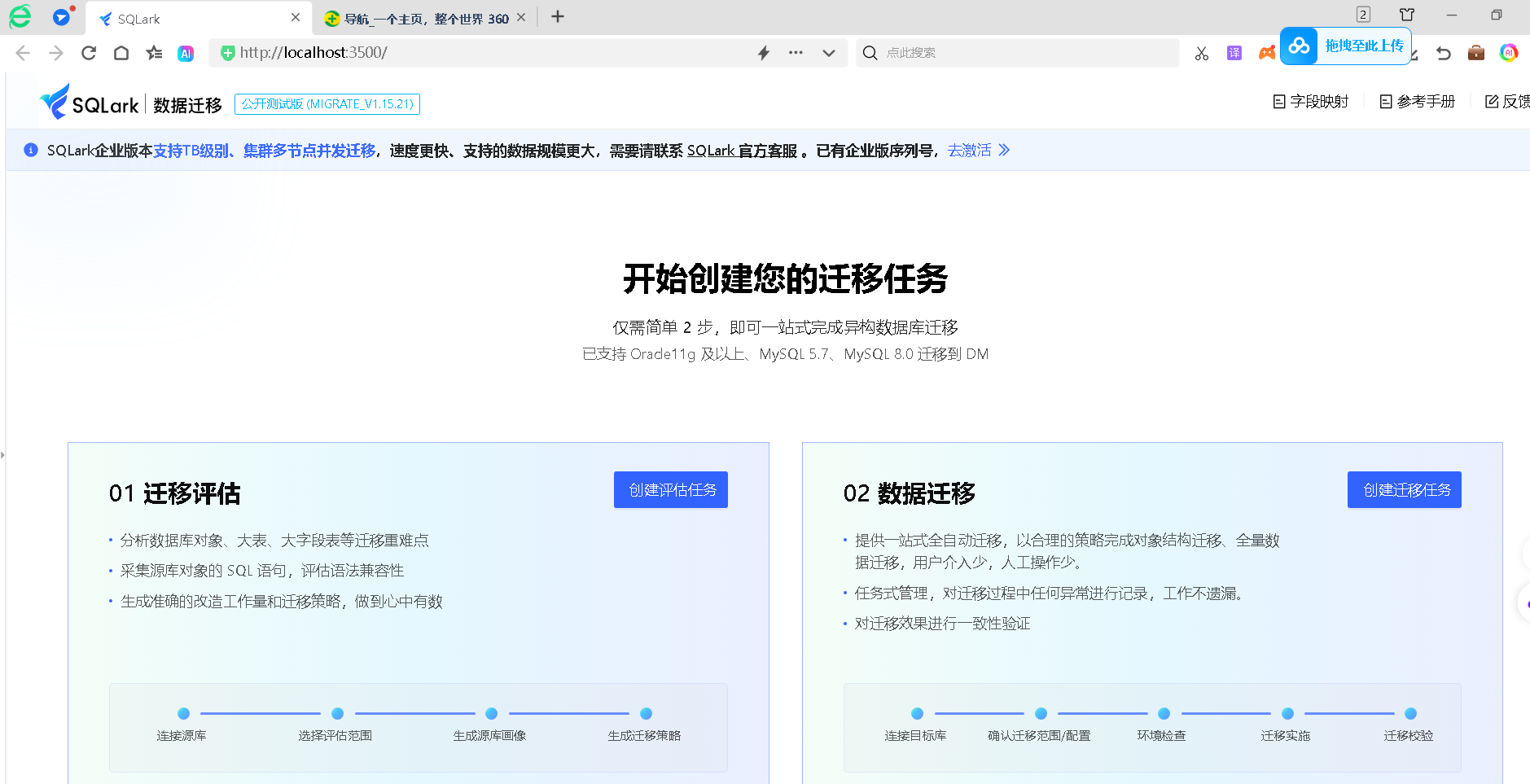
这个地方感觉像是借鉴OGG21C微服务架构开发的WEB图形化界面,个人猜测哈。
配置快速装载(可选)
数据量大于30G开启配置快速装载功能
快速装载可提升迁移性能,选择该方法迁移前请进行如下环境配置,否则会导致大量迁移失败。
前提:若想启用快速装载,SQLark工作所在的服务器上必须安装达梦数据库
打开环境变量配置界面
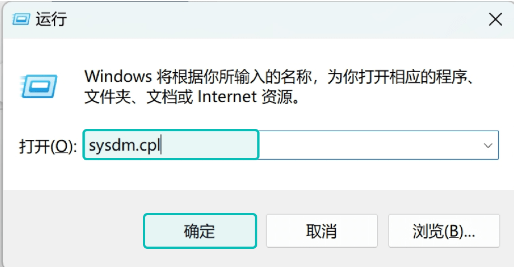
1. 按下 Win+R 快捷键,打开 运行 对话框,输入 sysdm.cpl 指令,打开 系统属性 窗口。
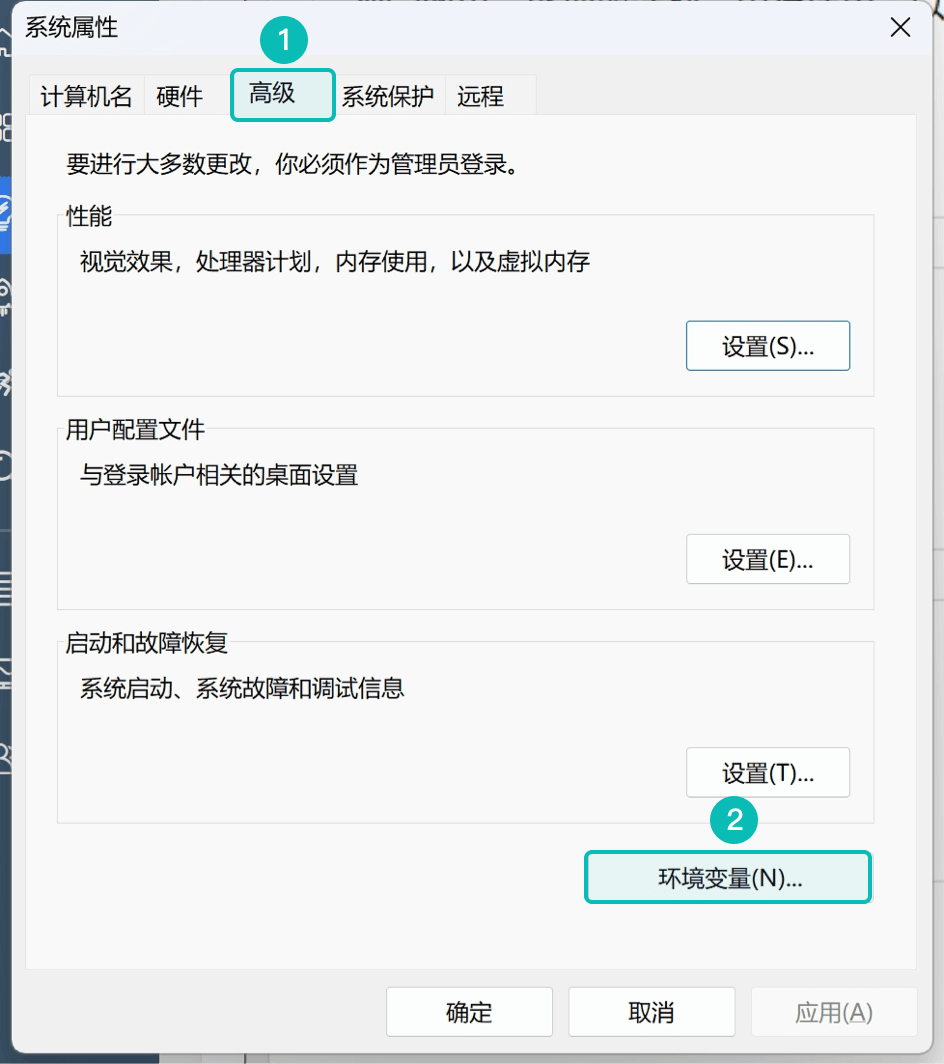
2. 依次点击 高级 | 环境变量 ,如下图:
配置环境变量
新建系统变量
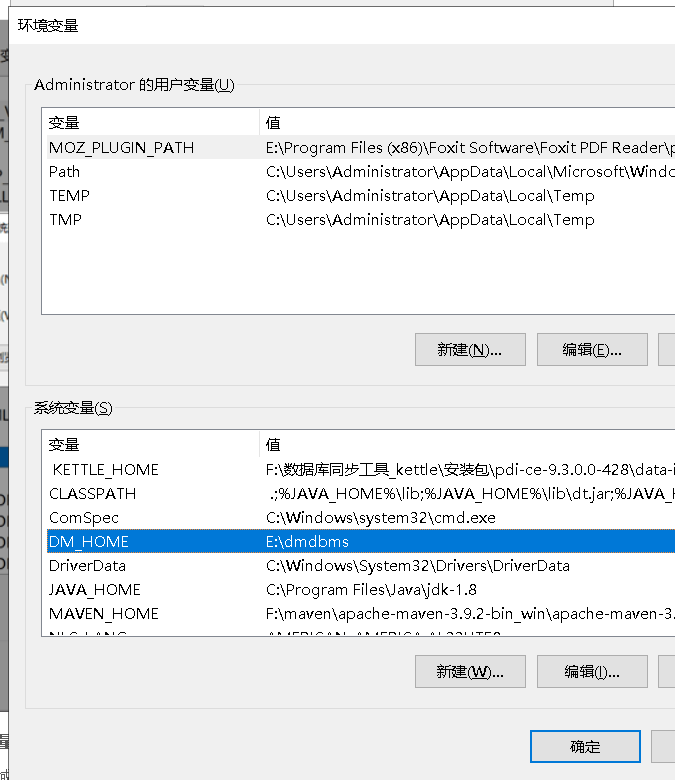
在系统变量区域点击 新建,在 编辑系统变量 弹框中输入下列值后点击 确定:
变量名:DM_HOME
变量值:SQLark 当前部署服务器的 DM8 安装路径,下图示例中为 E:\dmdbms
编辑系统变量 Path
在系统变量区域,找到变量 Path,双击或者点击 编辑 打开 编辑环境变量 窗口。
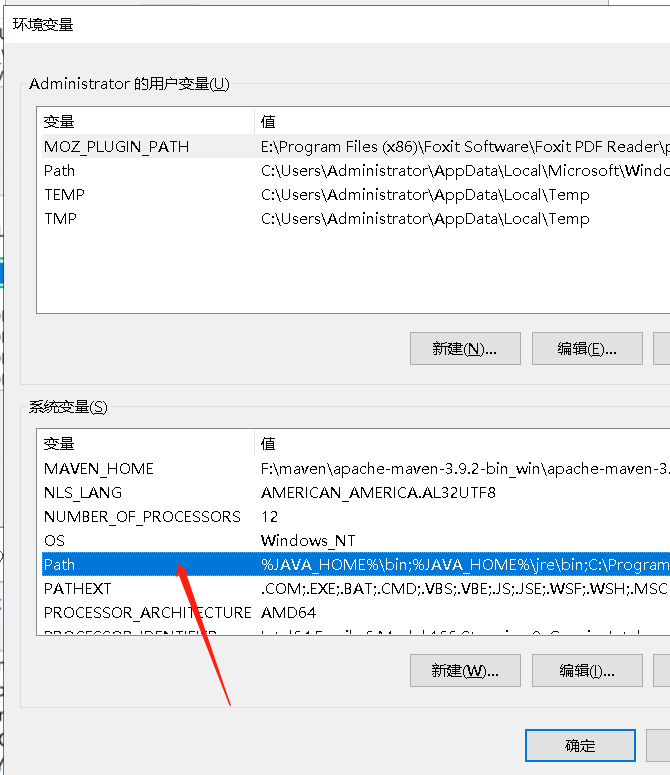
点击 新建,输入 %DM_HOME%\bin或者编辑Path在最后增加 ;%DM_HOME%\bin
检验环境变量
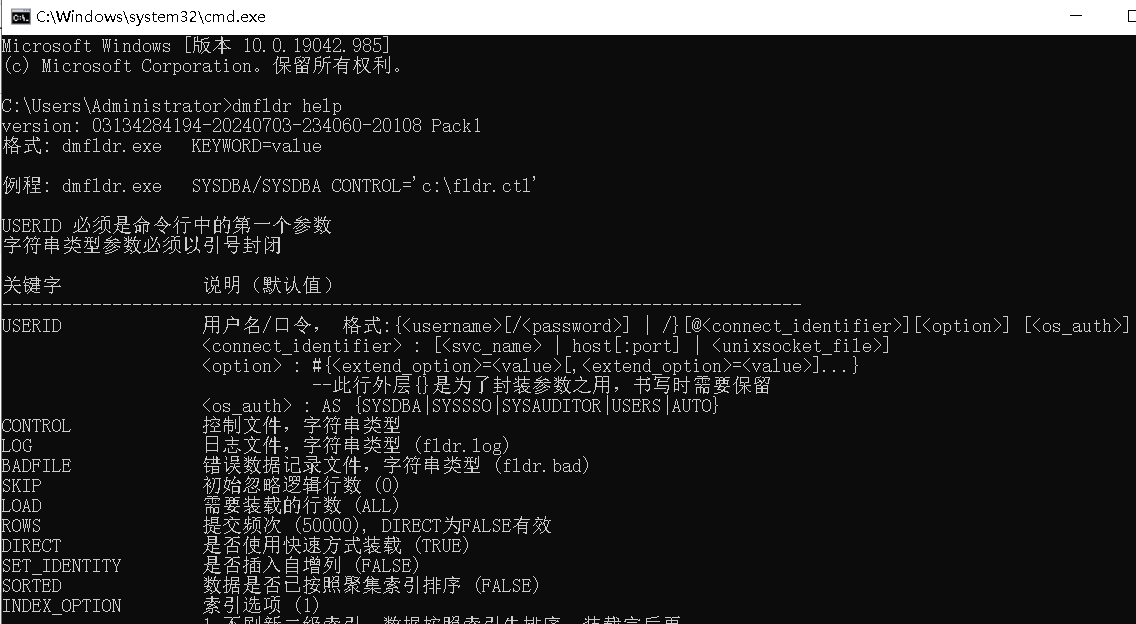
- 按下
win+R快捷键,打开 运行 对话框,输入cmd指令,打开命令提示符窗口。 - 在命令提示符窗口输入
dmfldr help命令,系统返回 dmfldr 版本号及相关帮助信息,即表示环境变量配置成功。
重启 SQLark 客户端
退出并重新启动 SQLark 客户端,再次勾选 启用快速装载,即可成功启用
迁移过程
SQLark 数据迁移,专注于提供全流程的异构数据库迁移服务,通过迁移评估和数据迁移两个环节和自动化语法解析,提前识别可能存在的改造工作,生成最佳迁移策略,一键迁移到目标数据库,最大化降低用户的数据库迁移成本。
一次完整的数据库迁移流程,包括迁移评估和数据迁移两部分。SQLark 同时支持仅迁移评估,或跳过评估直接开始数据迁移环节,满足不同迁移场景需求。
迁移评估
迁移评估环节通过分析数据库对象、大表、大字段表等迁移重难点情况,采集源库对象的 SQL 语句,评估语法兼容性,生成准确的改造工作量和迁移策略。详细流程如下图所示:

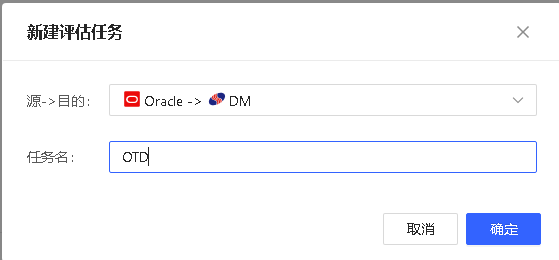
新建评估任务
- SQLark 支持同时创建多个迁移评估任务。
- 若关闭数据迁移页面所在浏览器,评估任务将正常进行。
- 如因网络中断、所在终端导致 SQLarkService 服务中止,则评估任务将会异常中断。
- 评估任务列表包含任务名、源数据库、目标数据库信息、评估范围、状态、当前进度、创建时间和其他操作等信息。
弹出如下界面:
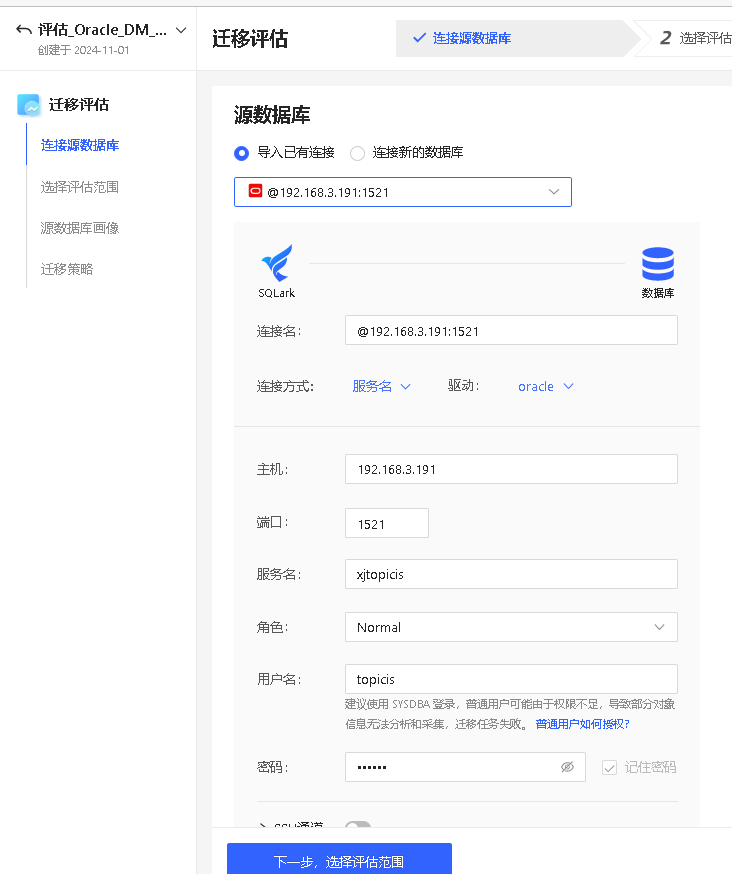
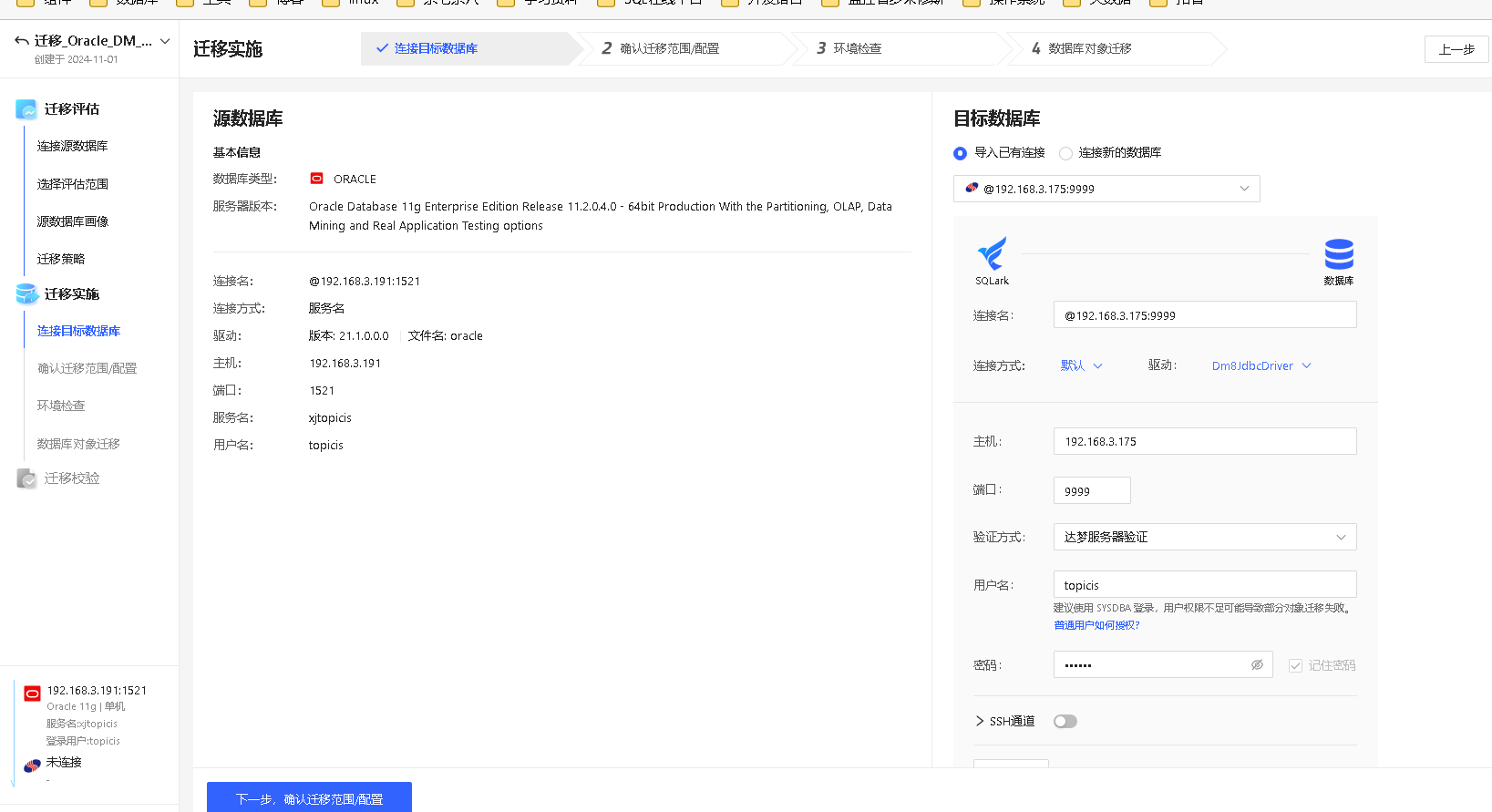
连接源数据库
SQLark 默认使用 JDBC 驱动程序连接到不同数据库,不同的数据库类型需要配置不同的连接参数,包括数据库所在地址、访问数据库的用户名等。
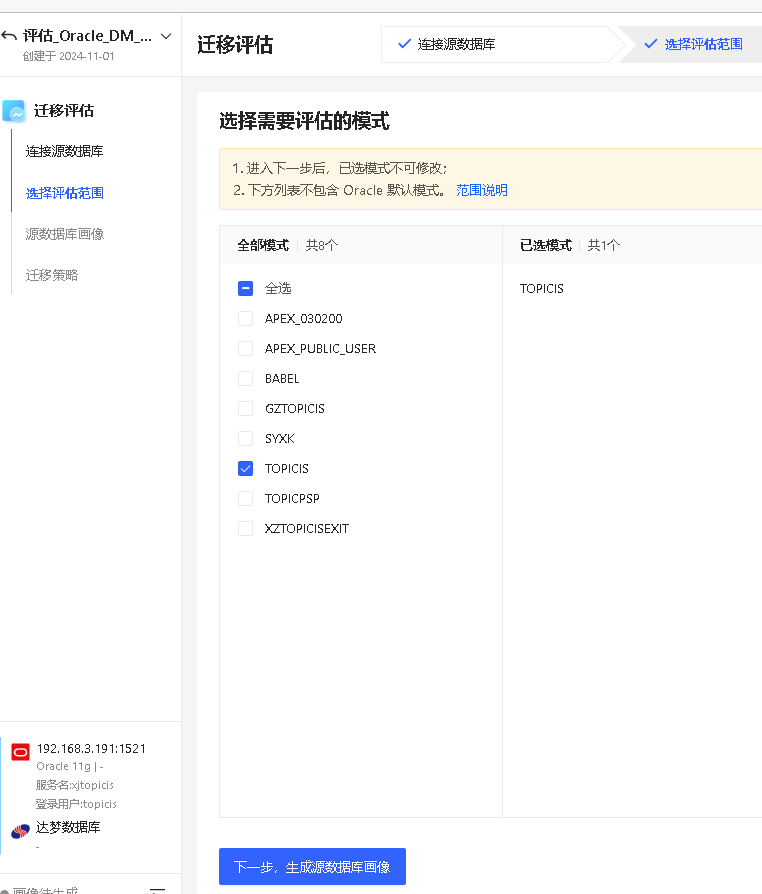
选择评估范围
- SQLark 不支持Oracle、MySQL中默认模式的迁移。
- SQLark 支持在授予只读权限或非 SYSDBA 用户权限的情况下,正常开展迁移评估和实施工作。
源数据库画像
将对指定用户下全部对象信息进行分析和采集,生成源数据库画像,提前识别可能存在的改造风险及工作量。
SQLark 会采集数据库基本信息、表空间信息、表数据信息、对象信息等生成画像,等待进度加载至 100% 即可。
说明:
- 画像加载耗时,取决于源库的对象复杂程度、数据量、源库和 SQLark 所在服务器的实际情况。
- 在源库画像生成过程中,SQLark 支持暂停评估任务,并允许在任务内重新开启评估。
- 生成源库画像时,如遇到源库对象数量显示为 0 的情况,请参考官网:FAQ-为什么源库画像中该模式下对象数量为 0 ?
- 为保障画像生成成功,请确保部署环境稳定,避免出现网络中断、服务器重启、所在终端故障等问题,否则可能会导致任务异常中断。
- 含大字段表:含有 LOB、LONG 等类型字段的表,容易造成内存溢出、迁移缓慢等问题(含有大字段的分区表、大数量表,在 SQLark 中均视为大字段表)
- 大数据量表(未分区):表行数超过 1000 万行、无分区子表且不含大字段的表,存在迁移耗时长的风险
- 分区表:分区表常用于解决单表数据量过大导致的查询、检索慢问题,存在迁移耗时长的风险
源库概览
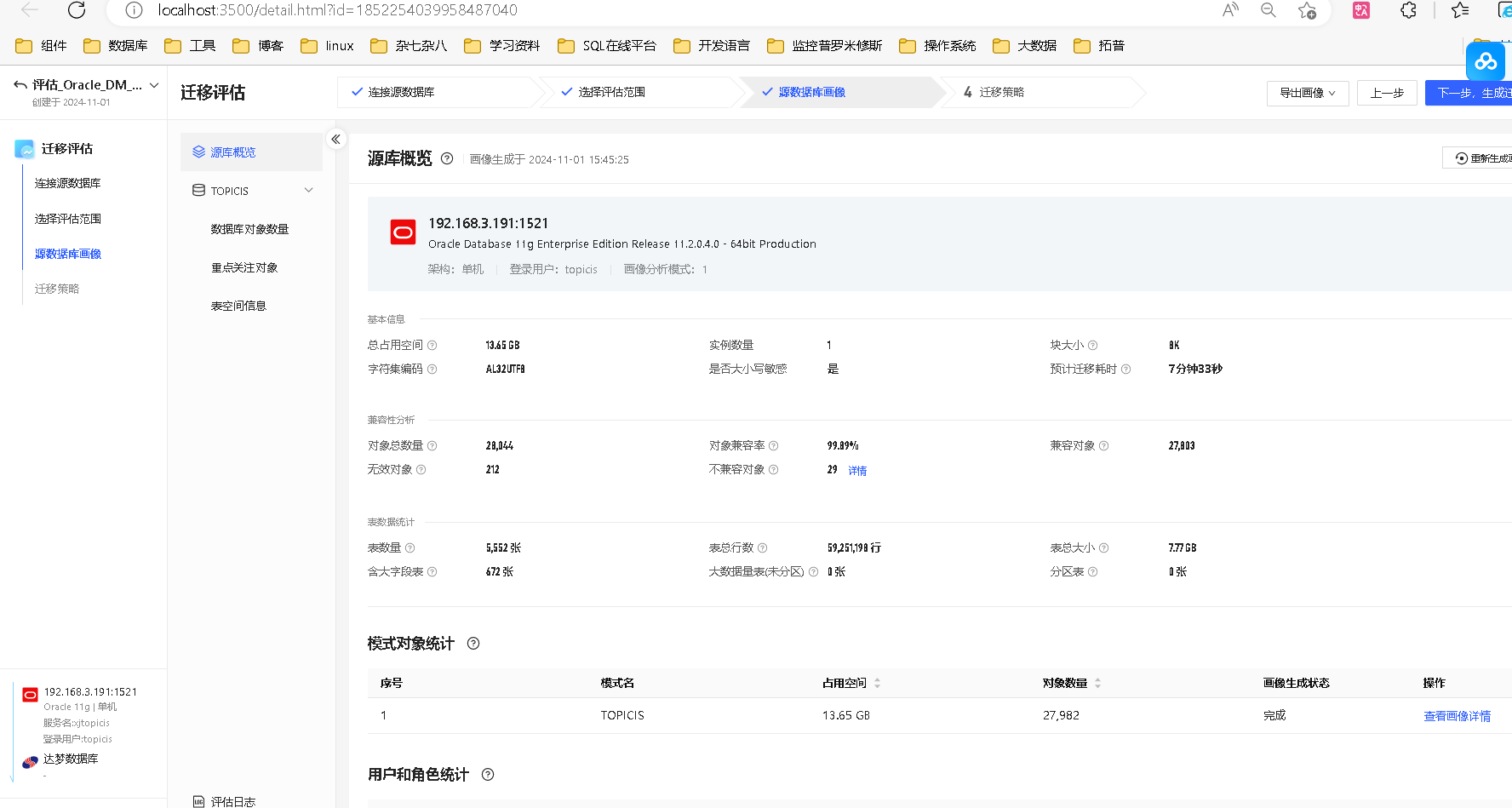

数据对象数量
展示该模式下的全部数据库对象类型和对象数量,点击 查看详情,可查看该类型对象的详细对象列表和 DDL 语句。
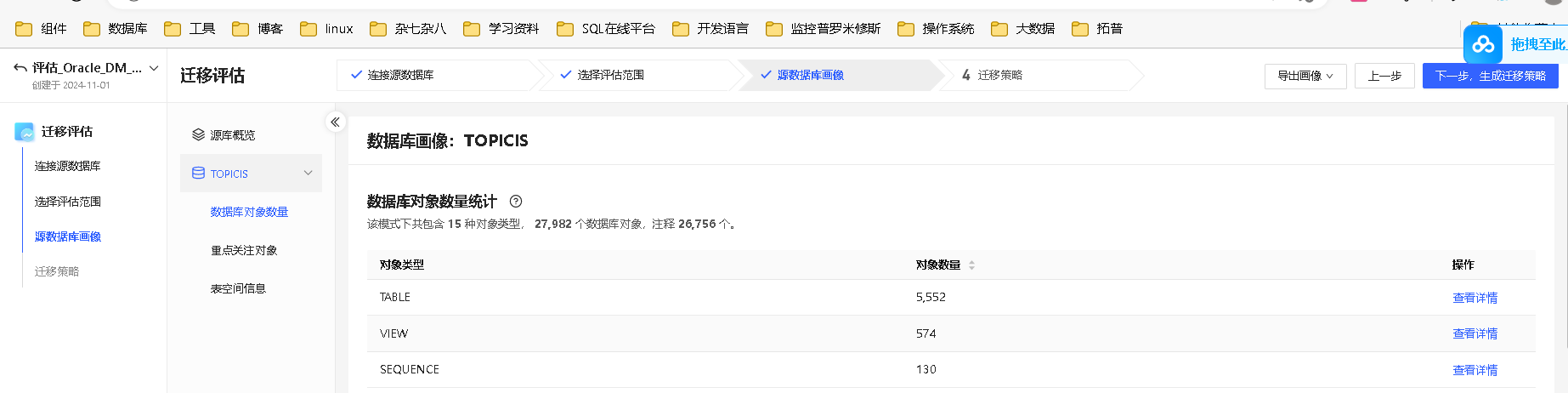
点击”查看详情“--》再单击表右侧的详情,显示表的DDL语句
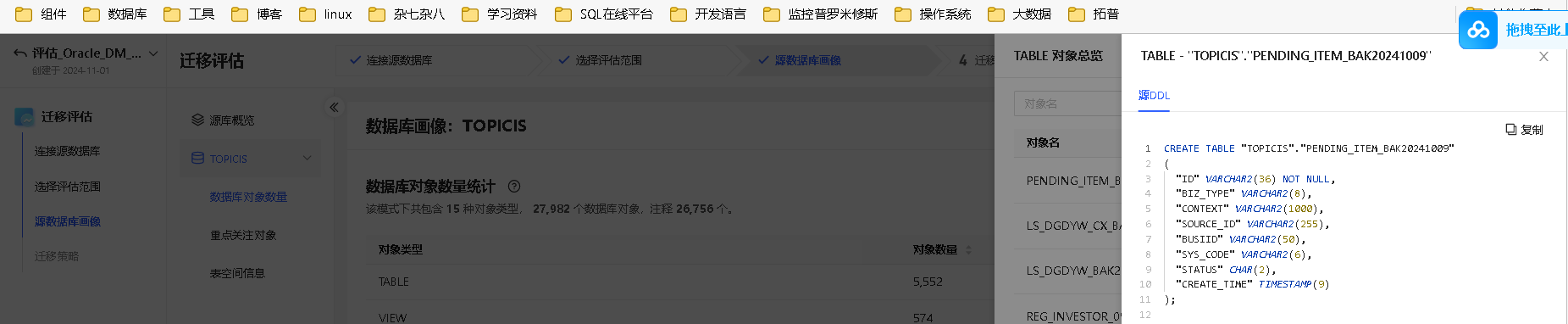
重点关注对象
展示该用户从源库迁移到目标库的风险点,主要包含 5 个维度,分别为含大字段表、大数据量表(未分区)、分区表、不兼容对象及无效对象。
含大字段表
- 对象定义:指含有 LOB、LONG 等类型字段的表,容易造成内存溢出、迁移缓慢等问题。
- 基本信息:包括表名、含大字段列数量、表行数及占用空间等。
- 详情信息:点击 查看详情 可查看该大字段表的列名、类型和源 DDL 语句等。
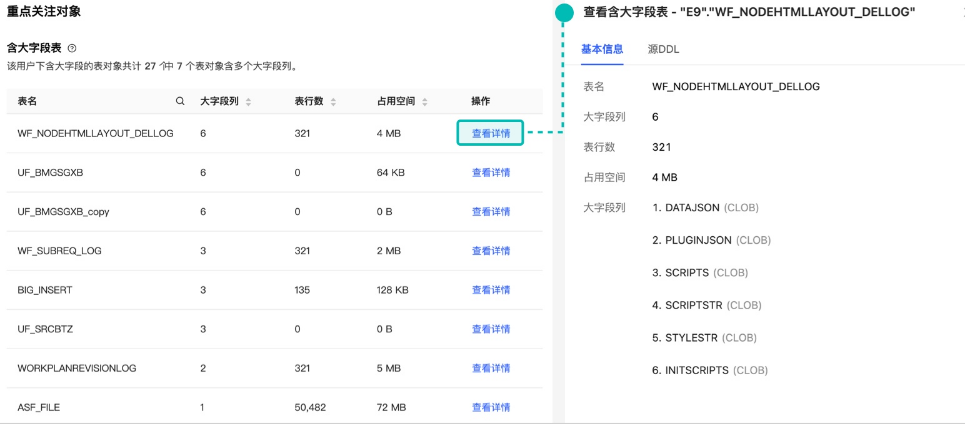
- 含有大字段的分区表、大数量表,均统计至含大字段表中。
大数据量表(未分区)
- 对象定义:指表行数超过 1000 万行、无分区子表且不含大字段的表,存在迁移耗时长的风险。
- 基本信息:包括表名、表行数以及占用空间。
- 详情信息:点击 查看详情 可查看该大数据量表的基本信息和源 DDL 语句。
分区表
- 对象定义:分区表常用于解决单表数据量过大导致的查询、检索慢问题,存在迁移耗时长的风险。
- 基本信息:包括表名、表行数、占用空间、分区表的一级分区数量以及是否包含二级子分区。
- 详情信息:点击 查看详情 可查看该分区表的分区类型、分区列和源 DDL 语句等。
不兼容对象
- 对象定义:不兼容对象是指 SQLark 针对所有对象进行语法解析后,源库 DDL 或 DML 语句在目的库没有对应的语句,或语句的含义不完全相同的对象。
- 基本信息:包括对象类型、对象名以及不兼容详情说明信息。
- 详情信息:点击 查看详情 可查看该对象的不兼容详情原因 、源 DDL 和目的 DDL 语句。
无效对象
- 对象定义:指源库状态为
Invalid的对象,默认不予迁移。 - 基本信息:包括对象类型和对象名信息。
- 详情信息:点击 查看详情 可查看无效对象的基本信息和源 DDL 语句。
表空间信息
- 基本信息:展示该用户所在表空间的基本信息,包括表空间名、占用空间等信息。
- 详情信息:点击 查看详情 可查看该表空间的数据文件大小、自动扩充策略等详细信息。
查看用户和角色统计
点击用户和角色统计页面 查看详情,可获取 Oracle 数据库中用户和角色的详细信息。
导出画像报告(可选)
点击页面右上方 导出画像,即可生成源数据库画像报告
查看评估日志
若源库画像出现评估结果缺失、异常等问题,可点击页面左下方 评估日志,查看迁移评估过程中的全部日志和异常日志。SQLark 支持通过关键词搜索快速定位所需日志。
迁移策略
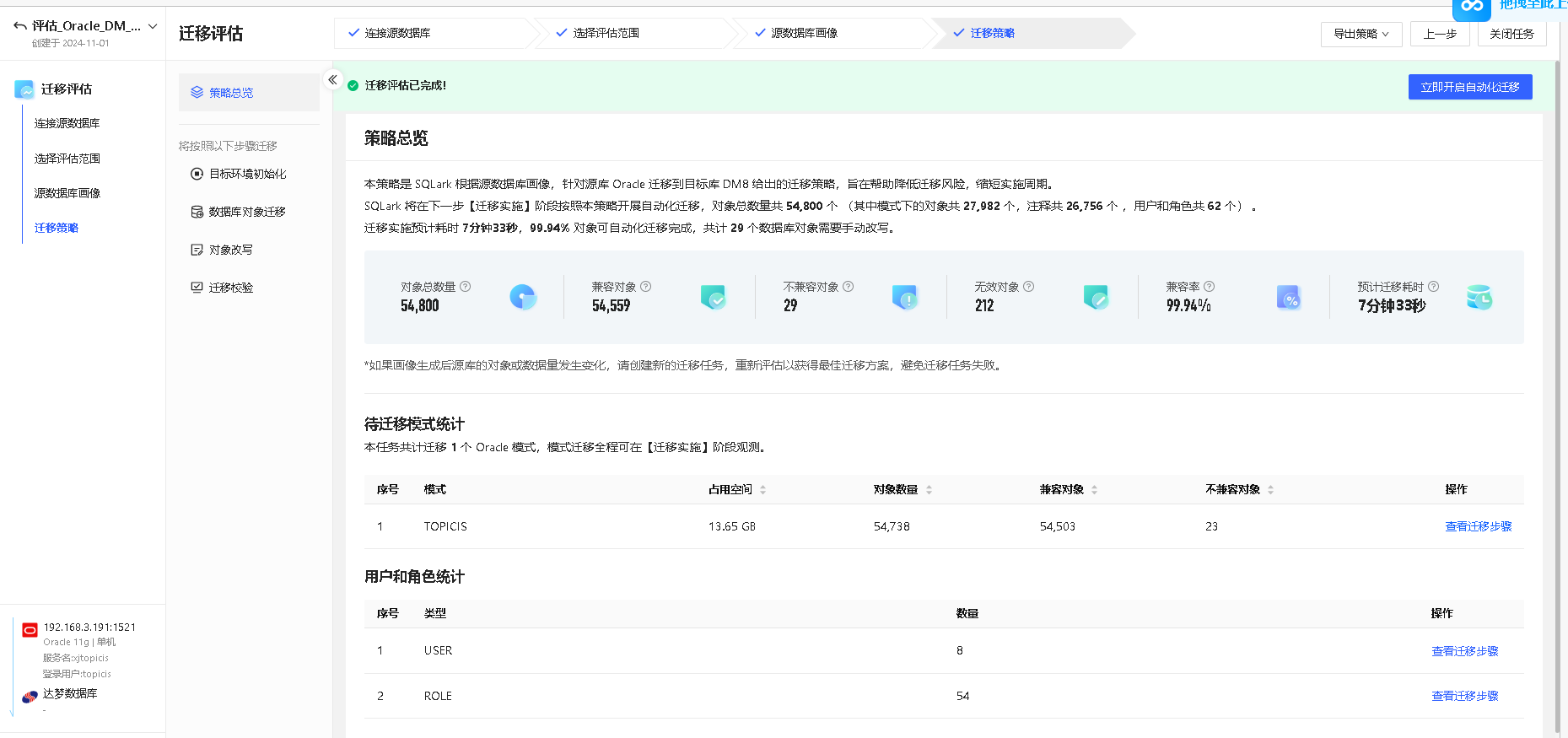
查看策略总览
获取当前迁移任务的待迁移对象数量、兼容情况,改写工作量及预计迁移耗时等基本信息。
数据迁移
数据迁移环节提供一站式全自动迁移,以合理的策略完成对象结构迁移、全量数据迁移,并对迁移效果进行一致性验证,采取任务式管理方式保障迁移工作完成。详细流程如下图所示:

立即开启自动化迁移


连接目标库
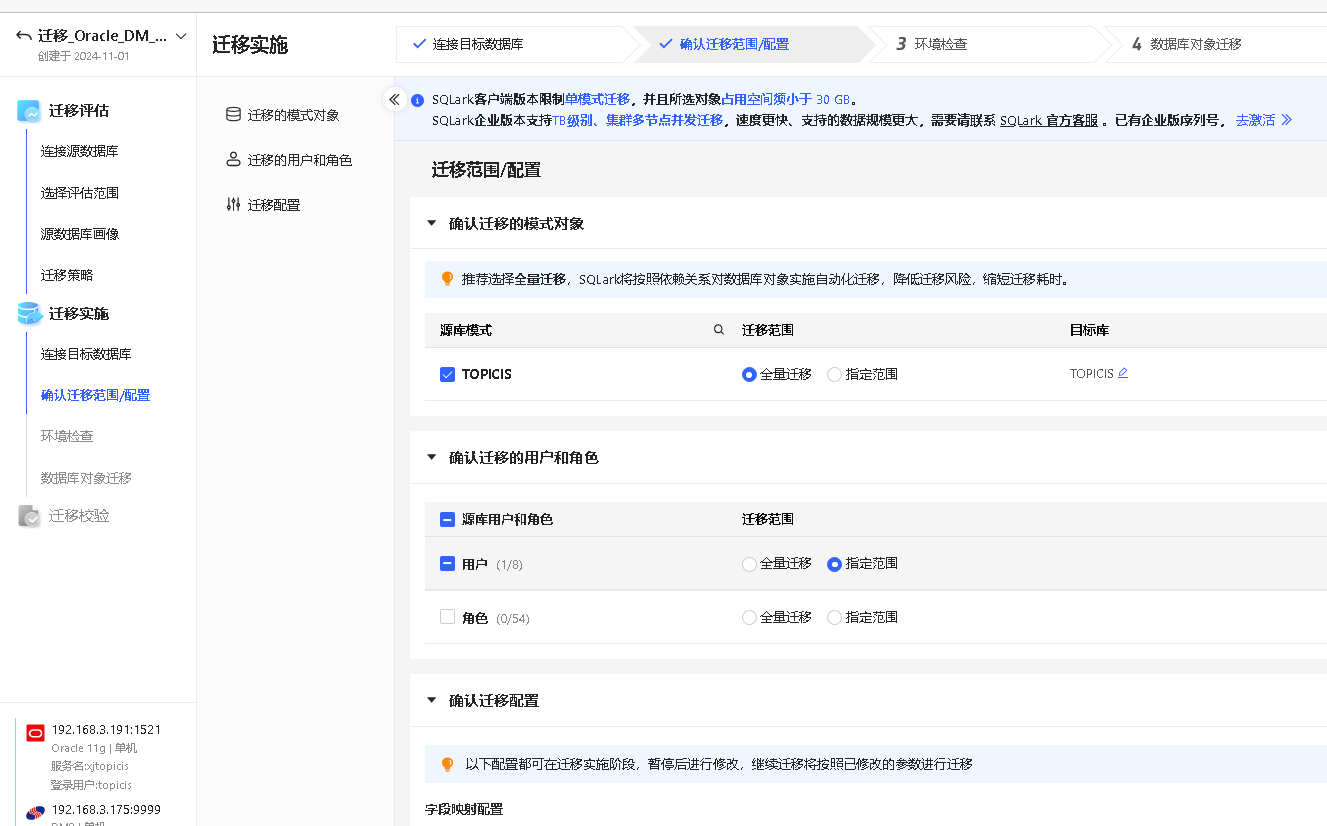
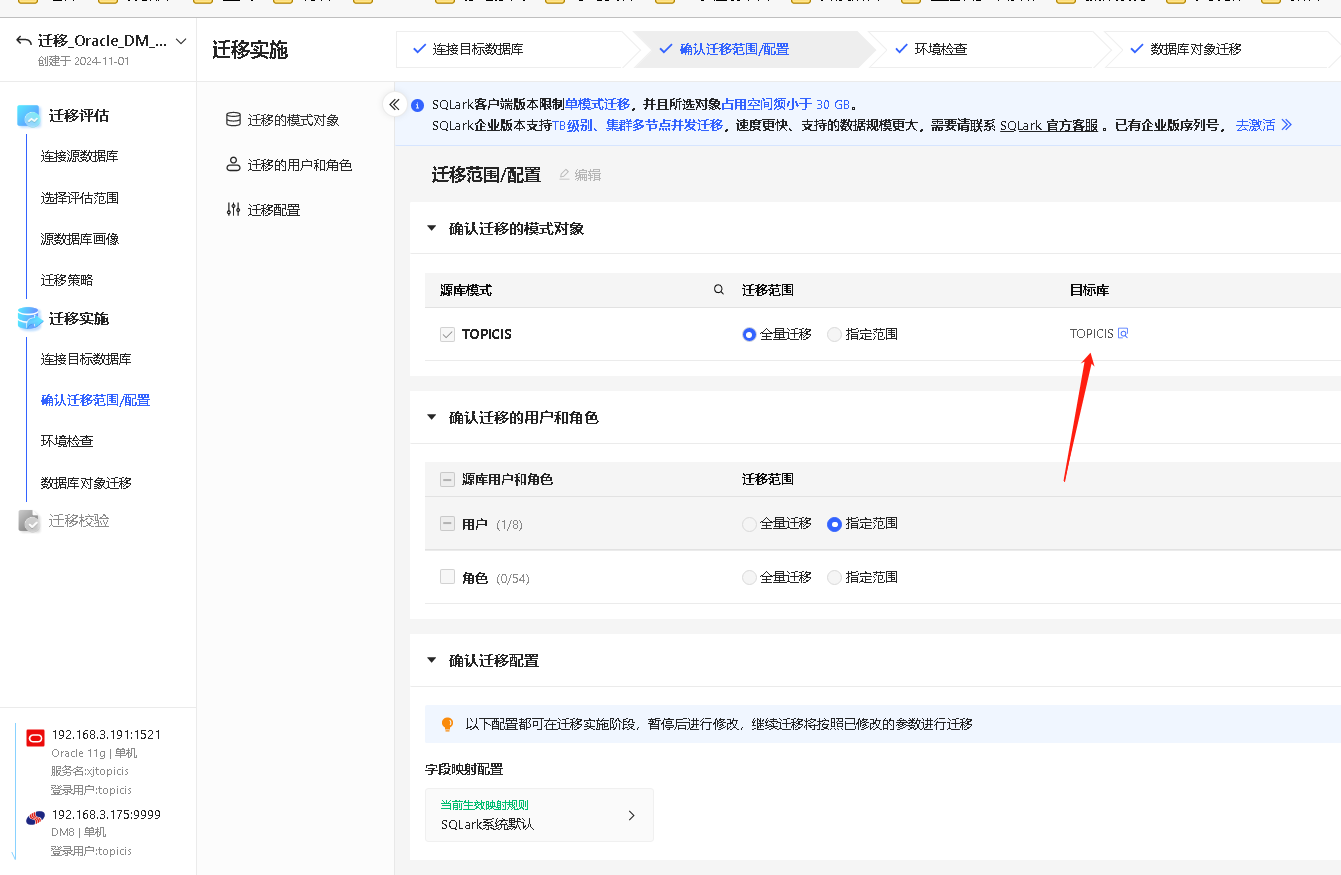
选择迁移范围/配置
确认迁移的模式对象
选择源库模式和迁移
为提升迁移效率,防止因配置参数设置过大导致迁移中断、批量报错等,SQLark 将根据当前部署机器所在服务器的内存和逻辑 CPU 生成最佳迁移参数,避免迁移过程中出现内存溢出、监听报错等问题。
数据迁移对计算机资源消耗较高,如希望提升迁移速度,请在调大下列并发参数之后,检查源端、目的端、SQLark 部署端所在服务器分配的内存和逻辑 CPU,咨询专业 DBA 或 SQLark 客服后完成配置。
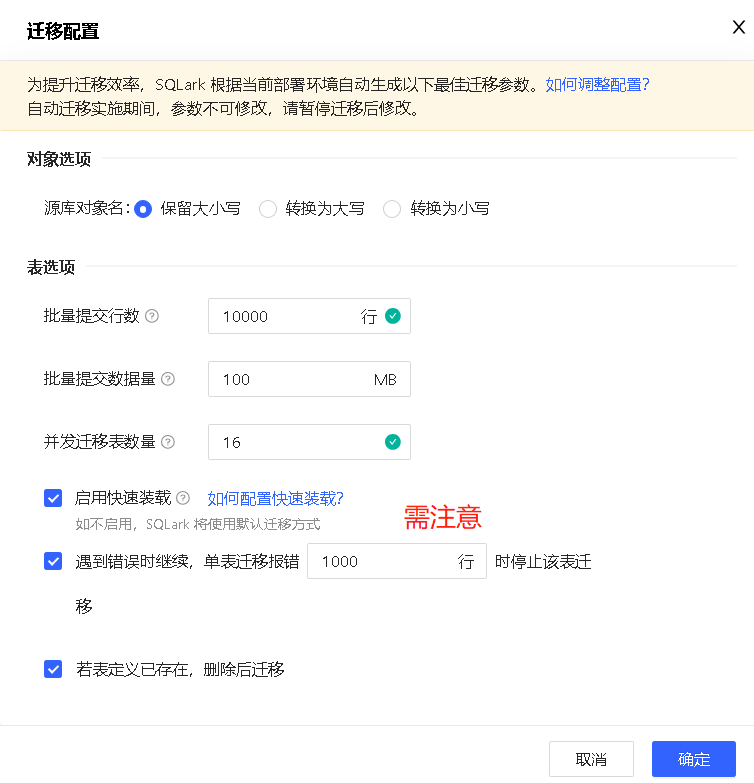
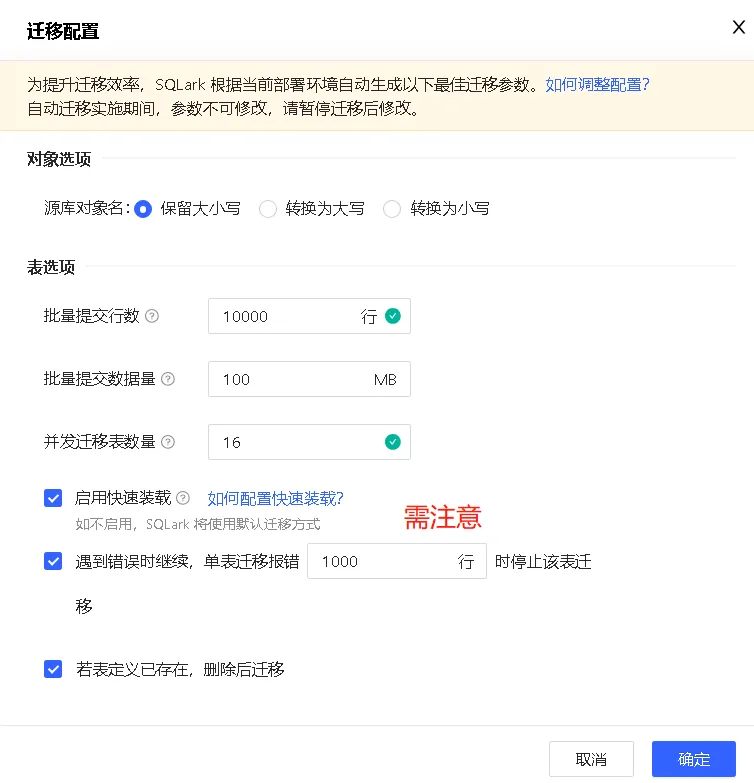
迁移配置
选择目标模式
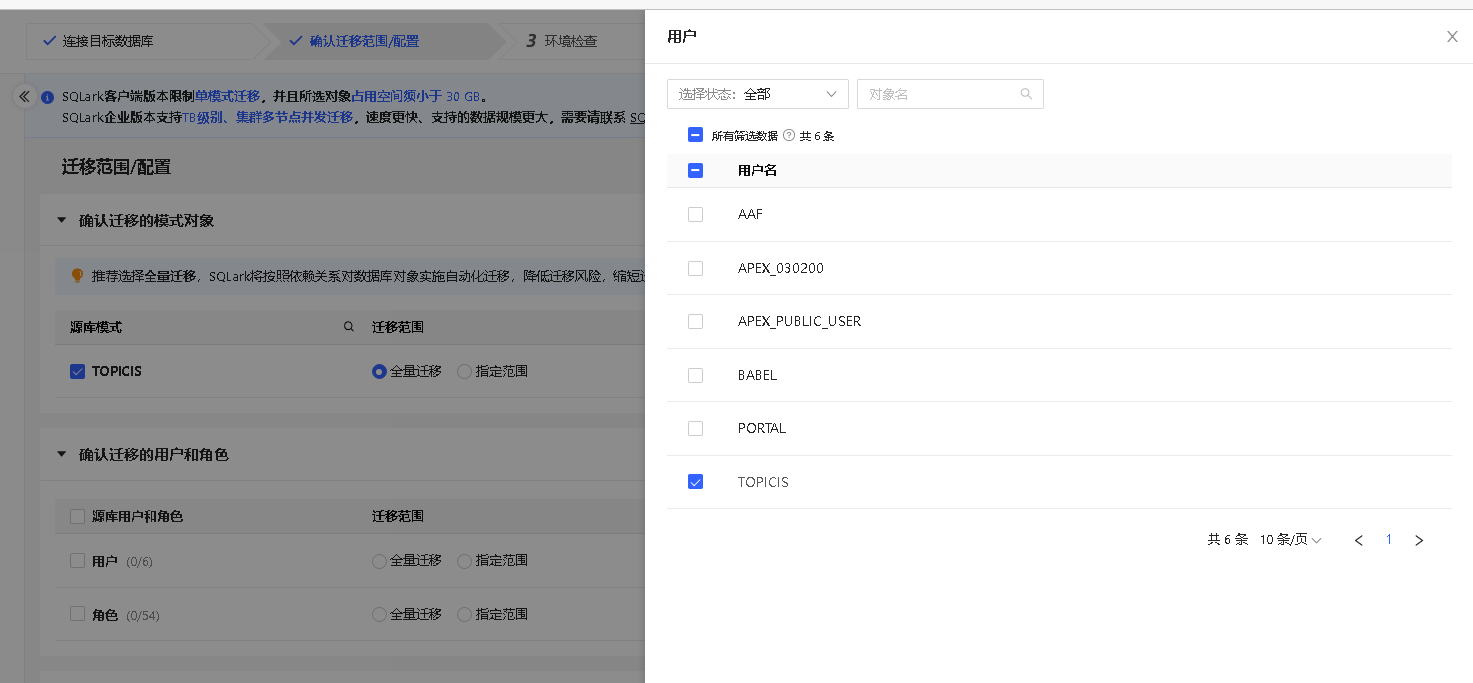
确认迁移的用户和角色
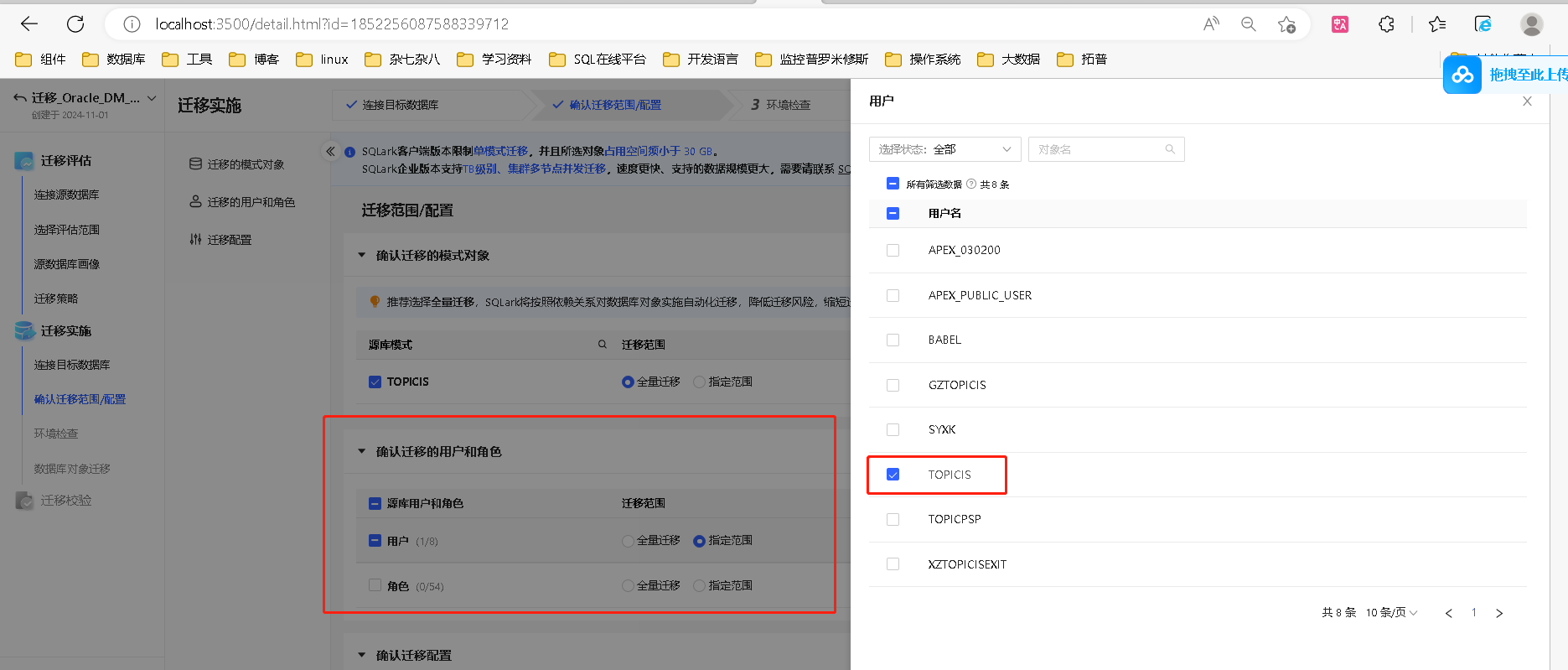
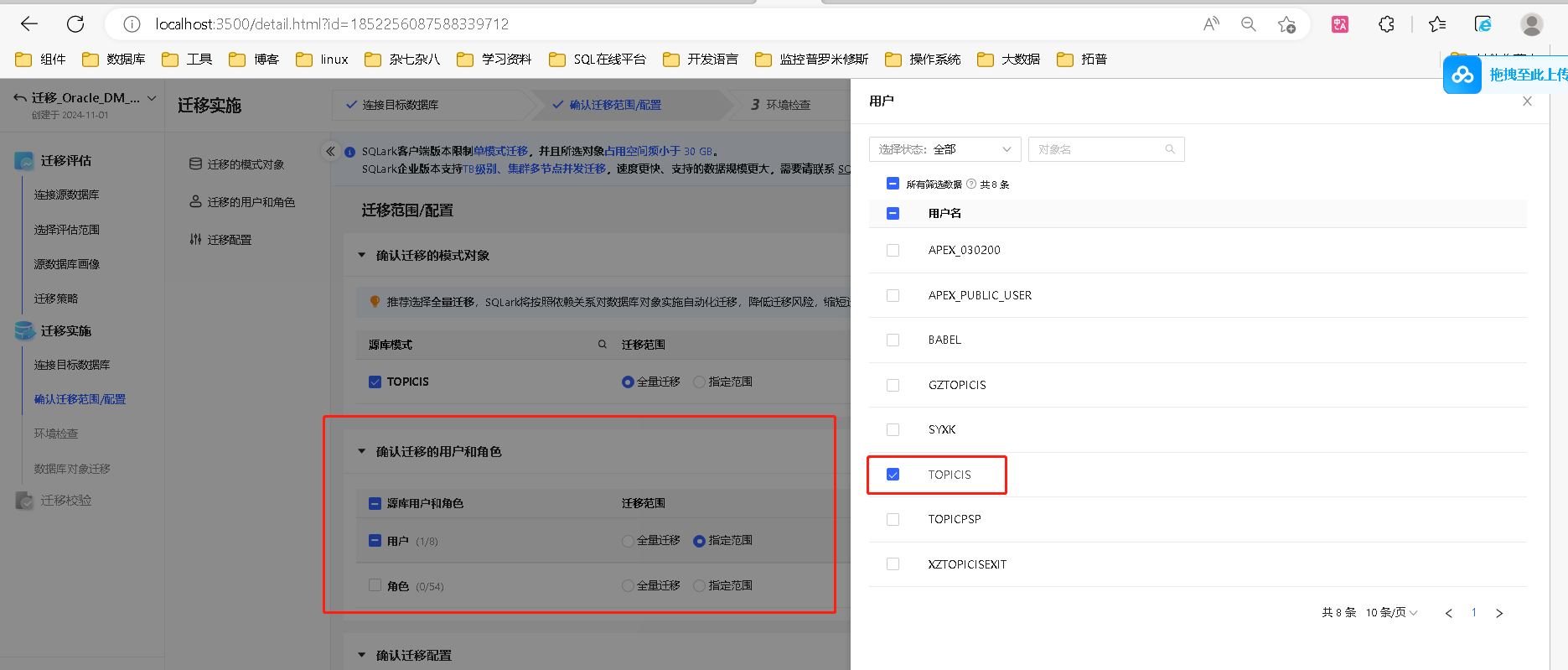
SQLark 支持迁移 Oracle 数据库的用户、角色、授权信息,简化迁移流程。
在本环节选择需要迁移的源库用户和角色,并确认其迁移范围,SQLark 提供全量迁移、指定范围迁移两种选项。
配置字段映射规则
- 功能入口
- 查看系统默认规则
- 编辑字段映射规则
- 查看系统默认规则
- 编辑字段映射规则
- 管理字段映射规则
可参照官方文档介绍
配置迁移参数
为提升迁移效率,SQLark 根据当前部署环境自动生成以下最佳迁移参数,参数确认无误后,点击 确认 按钮。
勾选启用快速装载后将启用 FastLoader 以提升迁移效率;如不启用,SQLark 将使用默认迁移方式
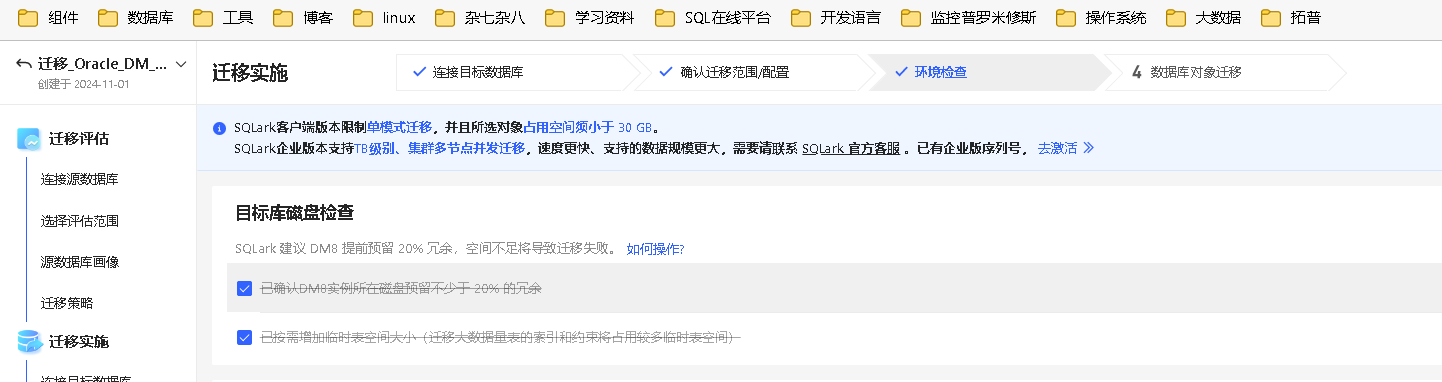
环境检查
确认迁移范围/配置后,在本步骤将进行环境检查,核查目标库环境检查项,避免迁移失败。
在进行环境检查时,SQLark 采取任务管理制度,全部检查项通过后,才可进入下一步,避免遗漏任何关键环节造成迁移失败。具体操作步骤如下
目标库磁盘检查
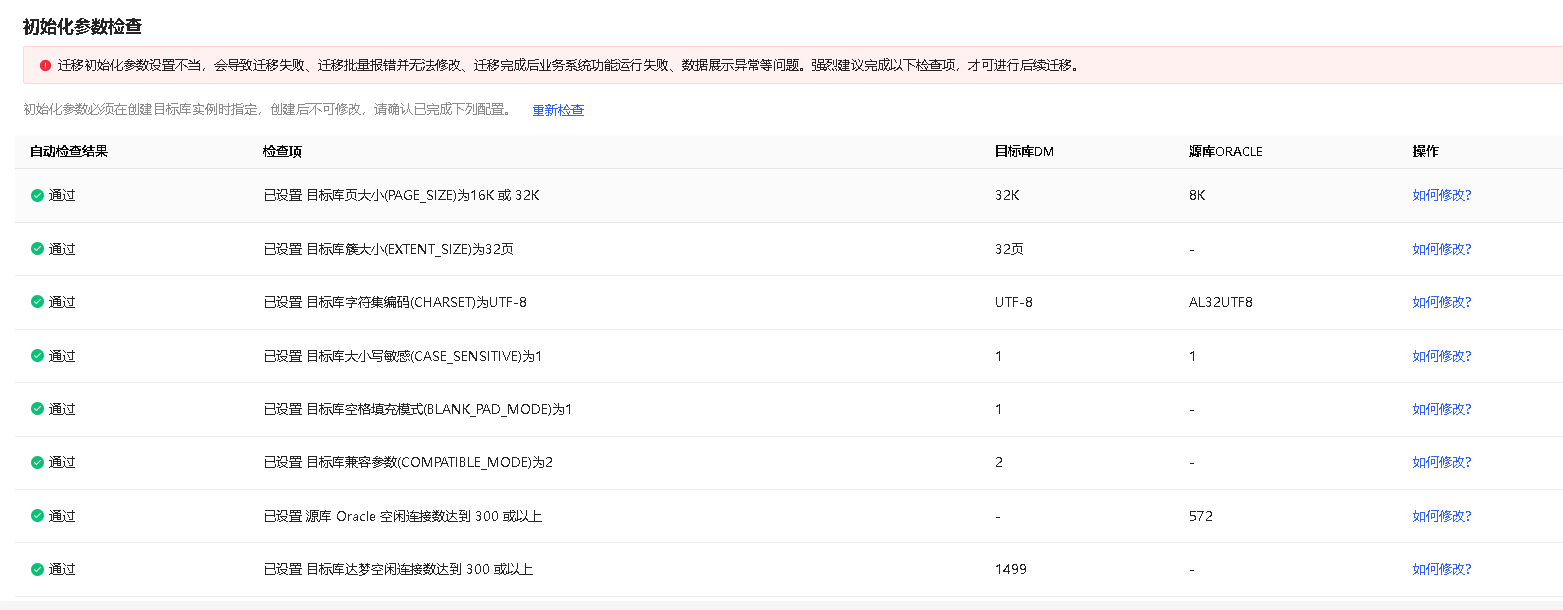
初始化参数检查
在本环节将显示各检查项的检查结果,初始化参数项的全部检查结果为 通过 ,即可单击 下一步,开启数据迁移。
若存在失败或告警项,可点击 如何操作,按照操作引导修改初始化参数,修改完成后可点击 重新检查,确保所有检查项通过。
迁移初始化参数设置不当,会导致迁移失败、迁移批量报错并无法修改、迁移完成后业务系统功能运行失败、数据展示异常等问题。强烈建议完成上述检查项后,再进行后续迁移。
数据库对象迁移
环境检查完成后,SQLark 将基于迁移策略对数据库对象和表数据开展自动化迁移和语法转换,为迁移异常提供错误分析和修改建议,以任务管理的方式保障迁移工作完成。
查看迁移任务进度
在迁移概览页面,可查看当前迁移任务的总进度、模式迁移进度、用户和角色迁移进度和待处理清单。迁移总进度将以进度条和百分比形式显示迁移任务的整体进度和执行耗时,便于及时了解任务进展。
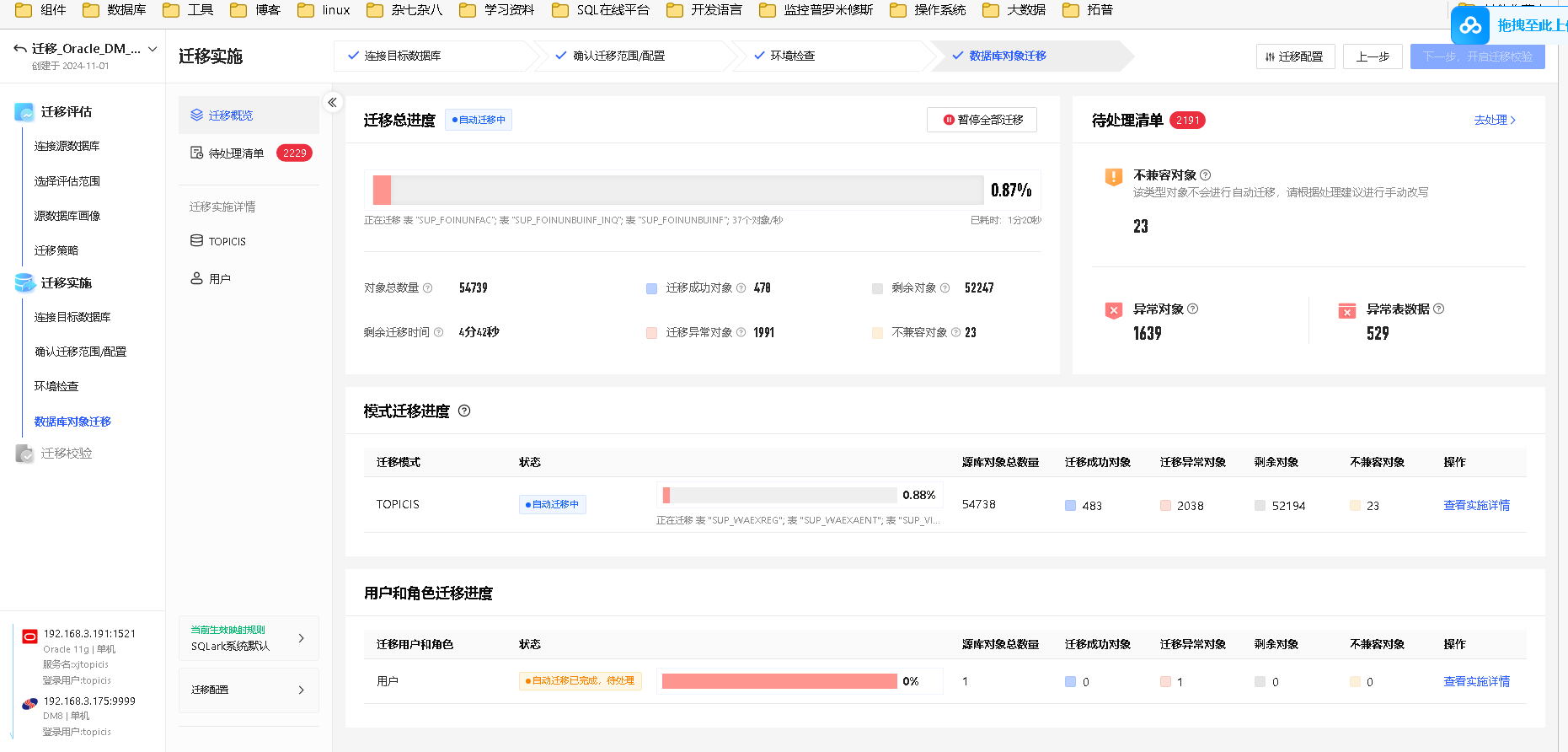
可查看以下信息:
说明项 | 描述 |
对象总数量 | 待迁移的全部对象数量(含注释数量) |
迁移成功对象 | 已成功迁移至目标库的对象 |
剩余对象 | 正在迁移中、或者正在等待迁移的对象 |
剩余迁移时间 | 预计剩余迁移时间 |
迁移异常对象 | 由于 DDL 或 DML 语句执行报错等原因导致无法迁移到目标库的对象 |
不兼容对象 | 源库 DDL 或 DML 语句在目的库没有对应的语句,或语句的含义不完全相同 |
查看实施详情
在模式迁移进度页面,点击 查看实施详情,可进入迁移实施详情页面,通过可视化界面展示具体迁移情况。

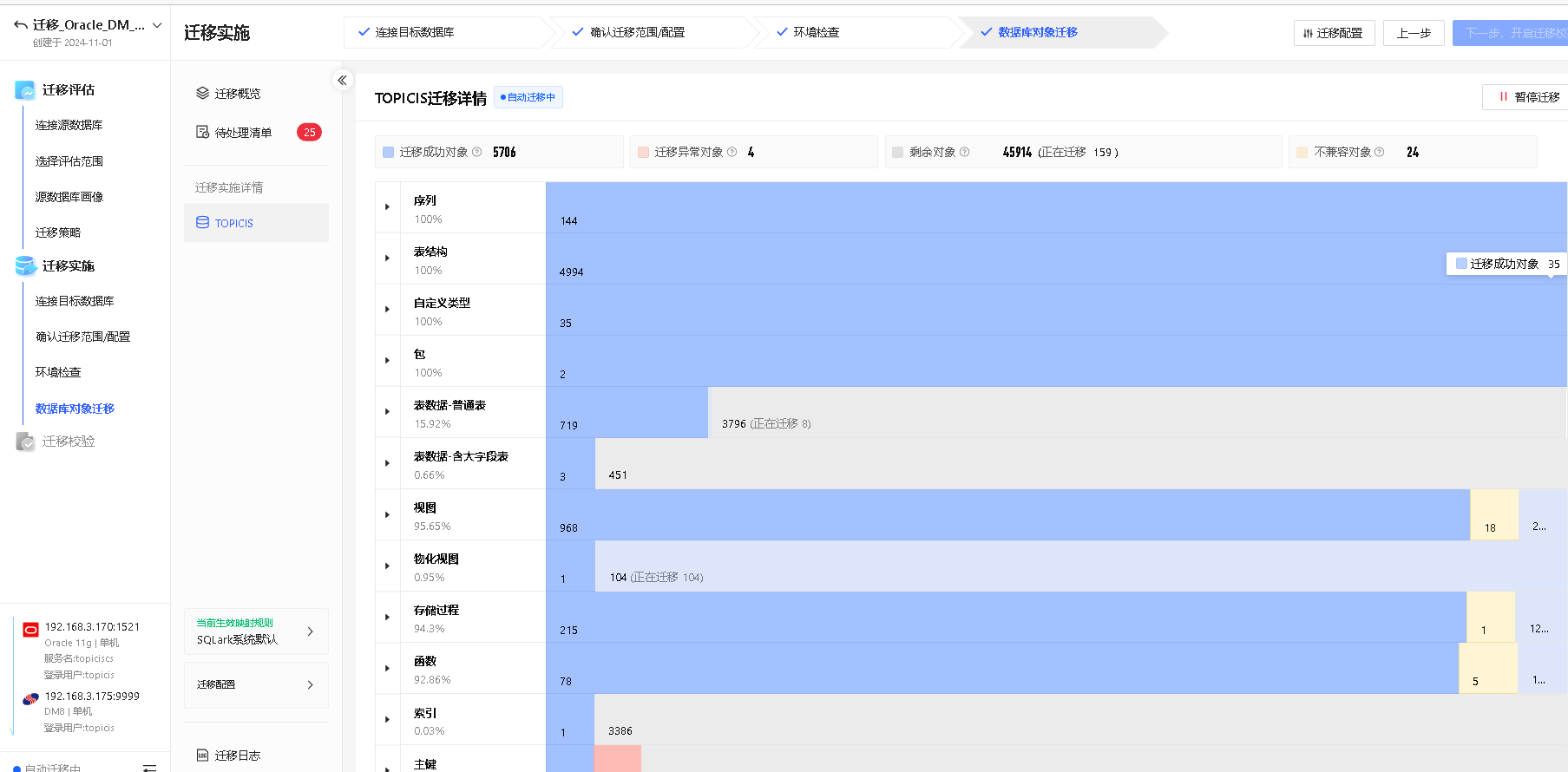
主要分为以下三个部分:
(1) 自动化迁移顺序:页面左侧从上至下展示自动化迁移顺序,依次为序列、表结构、同义词等。
(2) 每类对象的迁移进度:页面右侧展示各类对象的迁移进度。
(3) 对象迁移的状态:迁移对象有以下四种状态,不同色块代表不同迁移状态,点击色块可查看相应对象的详情。
- 蓝色:迁移成功对象
- 红色:迁移异常对象
- 灰色:剩余对象(包括正在迁移和排队迁移的对象)
- 黄色:不兼容对象
查看用户和角色迁移详情
在用户和角色迁移进度页面,点击 查看实施详情,可进入用户/角色迁移详情页面,查看具体迁移进度。
查看并处理异常对象和表数据
整个迁移任务中,未迁移成功的对象和表数据,均集中在待处理清单中解决。点击待处理清单模块的 去处理,主要包括以下三类对象:不兼容对象、异常对象和异常表数据。
不兼容对象
SQLark 默认不迁移该类对象,建议在迁移实施过程中优先进行手动改写,避免后续相关对象因依赖问题而报错。
评论

 0 点赞
0 点赞 0 点赞
0 点赞