




在开发一个系统时,数据库是必不可少的组件。那时候关系型数据库只了解Mysql,做缓存就用Redis,文档类的选Mongodb存储,而对数据库内部是如何工作的,知之甚少。然而,当我开始接触Oracle时,才真正感受到它复杂而精妙的架构设计。Oracle不仅仅是一个存储数据的工具,更是一个经过多年优化、具备高度可靠性与可扩展性的企业级软件架构。很多知识和我开发时的知识高度重合:比如集群架构:负载均衡集群-Oracle RAC、并发控制:Oralce锁机制与一致性读- 分布式锁与一致性控制、缓存机制、日志、异步处理等。
不得不承认Oracle是一款很出色软件,但不能只把它当作一个软件,数据库作为数据存储的最后一个防线,是一个企业的核心不可马虎,这么优秀的架构值得学习一下。我发现一个事务的流程中有很多疑问和不明白的东西,它可以把我这半年学的大部分知识串联起。我在学习中一般是全表扫的学习方式,先建立知识框架,再逐个击破,所以我打算写一个Oracle筑基系列,从一个事务流程开始为切入点,带着自己的一些思考和疑问深入学习一下Oracle系统的底层机制,重新建了一个知识网络,探索一下Oracle背后的运作逻辑,今天这篇算是开头,大家多多三连支持,理解的透彻、反馈的好评多的话,会考虑出视频系列。
什么是数据库,一个数据库我认为需要满足以下两点:
- 第一,数据不能出错 ,要保证存储数据的一致性、完整性,任何时候,数据不能出错。
- 第二,高效查询,数据库除了存数据,还有就是查询,对于OLTP系统要保证数据库查询效率,这也是我们日常打交道的地方,如何优化一个SQL的访问效率。当然还有增删改。
而在数据库中“事务”是保障数据一致性和完整性的关键机制。事务不仅是我们操作数据库的基本单位,也是理解数据库内部运作的切入点。首先梳理一下整个事务流程,
最先入门Oracle是在天津实习时同事给的姜老师23届校招生的培训课,下面这张图当时研究了老半天,如今也仍然很多疑问的地方,学明白这一个流程难度很大,我尽量表达的清楚一些。
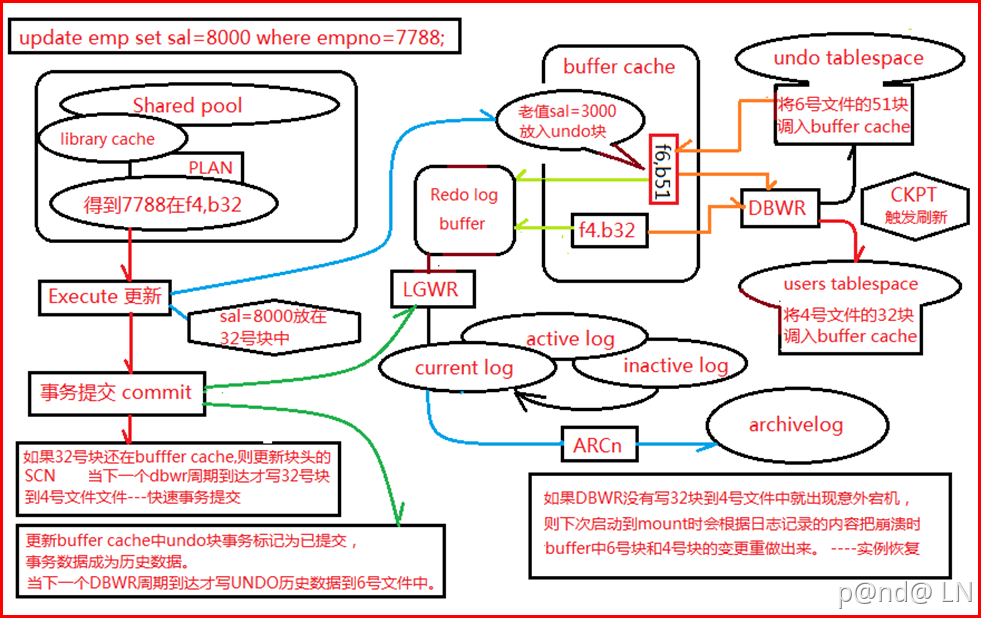
SQL语句执行流程大致分为解析、执行、获取数据三个阶段,而事务的流程包括其中各个SQL语句的执行阶段,对于一条更新语句 update emp set sal=8000 where empno=7788;他的事务流程生命周期如下:
1、客户端到服务器进程
小王表现良好,下个月要工资给涨到8000,管理者登录ERP系统,一般用户界面会有一个分页列表和按条件查询展示的功能(CRUD一般一个表必备的操作),先查出对应的7788号员工,接着点击修改员工共工资按钮(update emp set sal=8000 where empno=7788;),输入要修改的工资8000,最后点击“确定”按钮。浏览器会弹出状态信息,是否修改成功。这个过程一般是ms级的,很快,整个过程用户在前台是无感知的,请求从客户端通过网络传到数据库,被Oracle实例的服务器进程(server process)接收。开始sql语句的生命之旅。
2、SQL语句解析与执行计划生成
到了Oracle的sql语句的执行阶段,Oracle需要将sql语句解析成执行计划才能执行,这阶段主要包括:
- 语法检查:
sql书写是否符合sql规范,关键字单词from等拼对了吗?是否是一条sql,不能把C语言拿过来执行。
- 语义检查:
sql语句中涉及的对象(表、视图、用户等)是否存在,输入sql的用户有没有权限访问这些信息。
- 共享池检查:
在Shared pool检查是否有之前解析相同的SOL语句后所存储的SOL文本、解析树和执行计划。
- 软解析: 如果共享池中已有对应的解析树和执行计划,则直接复用,无需重新解析,直接跳过步骤4、5硬解析阶段。
- 硬解析: 如果没有相同的SQL语句,Oracle会创建新的解析树和执行计划。
- 选择执行计划:
判断sql语句到底该怎么执行(访问很多对象数据的统计信息),一条sql的可行性方案有N种,需要找到最优的执行方案。Oracle的优化器(Optimizer)会根据统计信息,分析SQL语句访问的对象和路径,生成一个最优的执行计划:
- 选择访问路径: 确定是全表扫描、索引扫描,还是其他方式。
- 表连接方式: 确定是嵌套循环(Nested Loops)、哈希连接(Hash Join),还是排序合并连接(Sort Merge Join)。
- 统计信息: 评估表和索引的大小、分布等。
- 生成最终的执行计划:
server process根据上面的执行计划的资源消耗,主要是CPU资源+IO资源(其他的比如内存转换成这两资源的消耗),选择资源消耗最少的执行计划。
- 执行sql语句
ps:
上面步骤看起来很少,但这里有很多需要重点了解的地方,
- 硬解析、软解析、软软解析、 如何避免频繁硬解析等。
- shared pool内存结构, 包括Library Cache和Data Dictionary Cache,用于存储解析后的SQL语句、执行计划及数据字典信息,怎么查看具体信息有哪些相关视图,4031怎么解决。
- 执行计划是如何产生的,如何修改执行计划,10053事件。
- Oracle优化器、SQL语句的访问路径、表的连接方式、统计信息的管理等。
3、数据访问与修改
1)数据块的读取
可以执行sql了,需要修改emp表员工号7788的薪水为8000,首先去database buffer cache缓存里读有没有emp表对应的记录:
- 如果有server process直接访问buffer cache。
- 如果没有,server process去磁盘dbf数据文件去找它需要的数据,找到7788在4号文件32号块(此时sal=3000,将老值放到undo块),取出来不直接返给我们的用户,取出来以后放到buffer cache里面去(sql分为增删改查,都要读到内存里去),然后再从buffer cache中返给我们的用户。读数据是server process读,但最后由dbwrite即DBWn进程****这个进程负责把serverprocess修改的数据写回磁盘。
2)buffer cache中 数据块修改
Server Process修改内存buffer cache中的数据块f4,b32,
- 数据块被Pin住(锁定),此时数据处于“连接”状态,内存中的操作很快。
- 修改数据后,数据块状态从干净变为脏数据。
2)日志的生成与归档
修改buffer cache中的数据块f4,b32的时候会产生日志,日志记录到redo log buffer里去。这个不是前台进程来干了,影响前台响应速度,这个由logwrite即LGWR进程,负责将redolog buffer里面的日志写到redolog日志文件(current log)。
redo log有不同的状态,生成的redo日志会被ARCn进程写到archivelog归档日志文件,被标记为inactive log才可以被重用,因为redo已经归档,可以在归档日志找到系统当时的操作日志。
- Oracle每次读dbf到database buffer cache为什么是一块一块读,不是一行一行读?
- 物理读和逻辑读的区别是什么?
- 缓冲区里面的数据块的分类?
- 为什么server porcess只负责读不负责写入磁盘呢?
- Lock和内存锁Latch的应用?
- SGA的结构,共享池、buffer cache的数据结构?
- DBWn、LGWR、CKPT的触发时间?如何手工触发?
- 这是对一个数据块的操作,并发操作的流程如何?
- Mysql日志落盘由实时、延时等和Oracle的区别?
4、commit与rollback
1)commit
用户提交,完成一个事务流程,因为是一个update操作,在f4,b32块的7788数据行上会有锁标记,这个什么时候清除呢?后面出篇文章细说。
事务信息被记录在不同的块上,这个Oracle出了一个快速提交,在事务涉及的块修改操作很多时,有时块上的事务信息(Xid,Uba)包括锁信息是不全的,需要去对应的回滚段上去找,事务提交后这些信息也不会修改,由后面访问的数据进行修改、清除这些记录。这也是有时候为什么select语句会产生redo的原因,只要对数据块进程修改都会记录到redo中。
2)rollback
我们要知道事务开始,必须首先在data block中分配ITL,ITL中记录了事务ID(XID),在Undo segment header中有一个事务表,记录该回滚段上的事务信息,每个事务都会占据了一个回滚槽,XID对应一个UBA(undo block address),表示该事务回滚信息的开始位置。update emp set sal=8000 where empno=7788;这个sql中,更新了一个block中的数据,data block中存在一个ITL,指向undo segment header中的事务表。undo信息存放在undo block中。
undo信息是一个链表结构,而undo segment header中的uba则指向了最后一个undo block(指向事务最后一个操作,回滚起始位置)。如果事务需要回滚,只需要在undo segment header中的事务表中找到事务回滚的起始位置,然后通过undo链表,就可以依次回滚整个事务。
3)一致性读
除了commit和rollback,事务期间可能还有锁争用和一致性读,简单说一下一致性读,其实在每个data block的ITL中也有一个UBA,这个UBA是指向了该block对应的undo信息的起始位置,这个UBA主要的作用是提供一致性读,因为一致性读需要通过undo信息来构造一个CR block,通过这个UBA就可以直接定位block的回滚信息的起始位置f6,b51,而不再需要通过undo segment header中的事务表。
- 用户提交之后脏数据才从buffer cache写会数据文件吗?或者说脏数据需要等到用户提交吗?
- 数据块、回滚段、回滚块详解、对应关系,有什么作用?
- 并发带来的锁争用问题?
5、todo
这篇文章仅仅是一个开头。未来,我计划通过以下几个方向,逐步深入Oracle的核心模块:
- Oracle体系结构
- Oracle存储结构
- 深入Redo与Undo机制
- SGA(共享池和buffer cache)和PGA的内存结构与管理
- 事务与锁
- 日志与恢复
。。。。。。
数据库的学习是一场漫长但充满乐趣的旅程,每一块模块都能带来新的启发和视角。希望通过这个系列,既能梳理自己的理解,也能为更多学习Oracle数据库的朋友提供一些帮助,欢迎大佬们多多批评指正,也欢迎刚入门的小伙伴一起学习。
