




kube-scheduler架构设计
最优解
调度阶段
kube-scheduler启动流程
内置算法调度注册
命令行参数解析
实例化Scheduler对象
运行事件管理器
运行HTTP或HTTPS服务
运行informer同步资源
领导者选举实例化
运行sched.Run调度器
优先级和抢占机制
亲和性调度
领导者选举
kube-scheduler架构设计
kube-scheduler是Kubernetes的默认调度器,其架构设计本身并不复杂,但后期引入了优先级和抢占机制及亲和性调度等功能,使得kube-scheduler调度器的整体设计略微复杂。
最优解
最优解是数学中的基本概念之一。
实际生产中,kubernetes集群中用于运行Pod资源对象的node节点并不是1台、2台,对于中大型公司的kubernetes集群可能有几百台、几千台,kubernetes也会很快选择出一个node节点用于运行Pod资源对象,这就是因为kube-scheduler使用两种最优解中的局部最优解实现的。
在具体说两种最优解前,先说下调度周期。一个调度周期就是kube-scheduler为一个 Pod资源对象寻找合适的节点的过程。
全局最优解 每个调度周期都会遍历Kubernetes集群中的所有节点,以便找出全局最优的节点 局部最优解 每个调度周期只会遍历部分Kubernetes集群中的节点,找出局部最优的节点
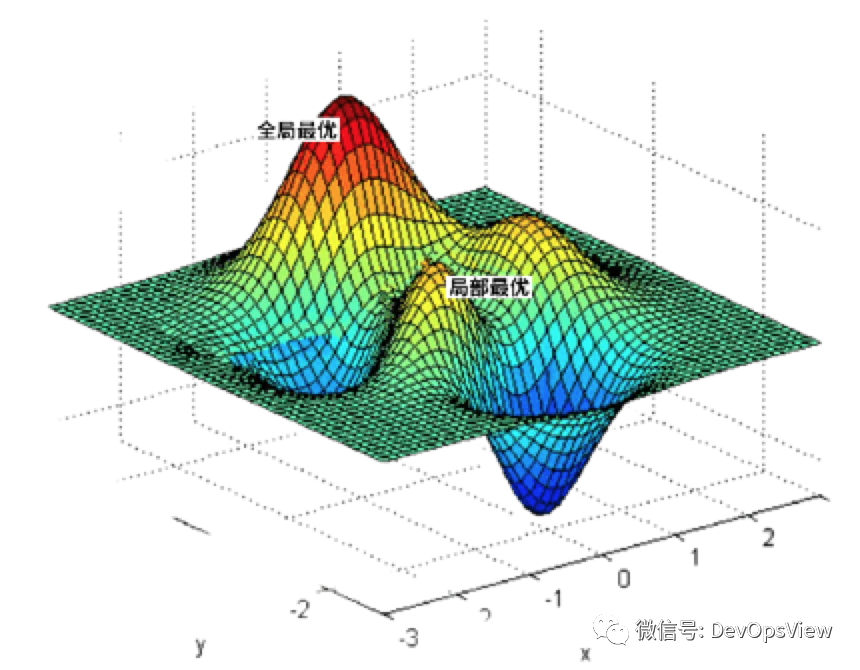
图片来自于网络
调度阶段
调度可分为三个阶段:预选、优选、选定。
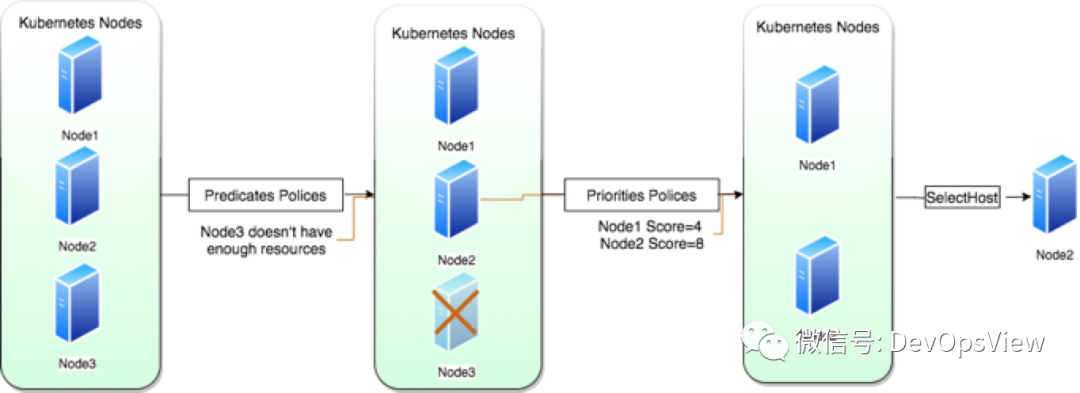
预选阶段是使用内置预选算法对节点进行筛选,比如CPU、内存、GPU等资源是否符合要求,节点上的Pod是否达到上限,等等。该阶段默认使用16个goroutine来执行。
优选阶段主要是对预选阶段筛选出来的节点进行打分,得分最高的节点就会成为这次调度最终最佳节点。如果有多个,会使用round-robin轮询方式选择一个。该阶段默认使用16个goroutine来执行。
选定阶段也可以称为bind阶段,是将Pod运行到最佳节点上。该步是一个异步的过程,先修改本地缓存,然后异步通过api server修改etcd。
kube-scheduler启动流程
内置算法调度注册
启动后第一件事是将kubernetes内置的调度算法注册到注册表中。内置算法有预选算法和优选算法两种。算法的注册是通过Go语言的导入和初始化机制触发。
命令行参数解析
在Kubernetes系统中,Cobra是作为统一的命令行参数解析库使用的,kube-scheduler组件通过Cobra解析配置参数。首先是初始化各个模块,比如HTTP或HTTPS服务等,然后验证配置参数的合法性和可用性,最后将配置参数传递给kube-scheduler组件启动的逻辑。
实例化Scheduler对象
Scheduler对象实例化可分为3个步骤:实例化所有的informer、实例化调度算法函数、为所有的informer对象添加对资源事件的监控。
实例化所有的informer
kube-scheduler组件依赖于资源的informer对象,用于监控资源对象的事件,比如PodInformer监控Pod资源的Add、Update、Delete事件。
实例化调度算法函数
前面只是注册了调度算法,在这一步是将已经注册的调度算法实例化成对应的调度算法函数。
为所有的informer添加对资源事件的监控
主要是为所有的informer对象添加对资源事件的监控并设置回调函数。比如PodInformer对象监控Pod资源对象,当该资源对象触发Add、Update、Delete事件时,触发对应的回调函数。比如触发Add事件后,PodInformer将其放入调度队列中,等待为该Pod资源对象分配节点
运行事件管理器
在kubernetes系统中,Event是一种资源对象,用于展示集群内发生的情况。kube-scheduler会向apiserver上报这些事件。比如为什么Pod资源对象调度不成功、为什么从节点驱逐某个或某些Pod资源对象等。
运行HTTP或HTTPS服务
kubernetes是直接使用Go语言提供的HTTP标准库,并没有过多的封装。HTTPS只是增加了TSLConfig配置。
kube-scheduler提供三个重要的接口:
/healthz:用于健康检查 /metrics:用于监控指标,一般用于Prometheus指标采集 /debug/pprof:用于pprof性能分析
运行informer同步资源
在正式启动调度器之前,需要等待所有运行中的Informer的数据同步,使本地缓存数据与Etcd集群中的数据保持一致。
领导者选举实例化
领导者选举机制的目的是实现kube-scheduler组件的高可用。
主要是实例化了两个回调函数:OnStartedLeading函数和OnStoppedLeading。
OnStartedLeading是当前节点领导者选举成功的回调函数,该函数定义了kube-scheduler组件的主逻辑。OnStoppedLeading当前节点领导者被抢占后,会退出当前kube-scheduler组件的主逻辑。
leaderelection.NewLeaderElector函数会一直尝试使节点成为领导者。
运行sched.Run调度器
在运行之前,会再次确认所有运行中的informer的数据是否已同步到本地。
主逻辑是一个定时器,对定时调用组件的主逻辑。
优先级和抢占机制
在kube-scheduler组件中,会有一个调度队列:activeQ,是一个优先级队列。可以看如下三种场景。
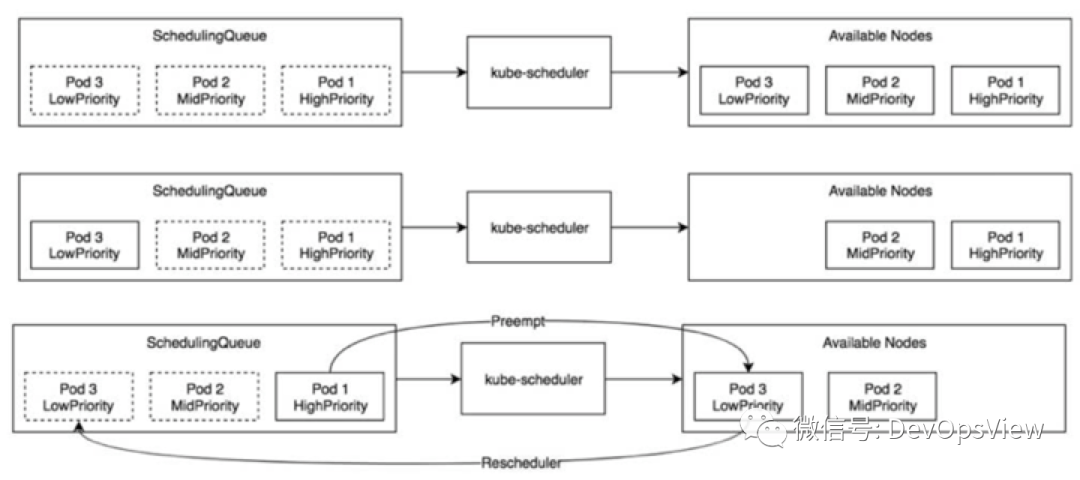
图片来自于《Kubernetes原码剖析》
场景一中,在资源足够的情况下,同时创建三个不同优先级的pod,pod会按照优先级依次调度到3个节点上。
场景二中,在资源不足的情况下,同时创建三个不同优先级的pod,高优先级和中优先级的Pod会依次调度到节点上。
场景三中,在资源不足的情况下,中优先级和低优先级的Pod先被创建,调度到节点上,再创建高优先级的Pod时,高优先级的Pod会抢占低优先级的Pod,低优先级的Pod会重新被调度。
可以知道,抢占是发生在调度失败的时候,也就是说,优先级和抢占机制解决的是Pod调度失败时该怎么办的问题。
要想使用优先级,必须创建一个PriorityClass对象。定义如下:
apiVersion: scheduling.k8s.io.v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This should be used for web service pod only"
这里需要注意的有两个点,一个点是value的值。在kubernetes中,优先级的值是一个32bit的整数,最大值不能超过10亿(超过10亿的是为系统Pod预留的),数字越大优先级越高。
另外一个点是 globalDefault,是设置这个PriorityClass是否要被全局使用。在kubernetes集群中,默认只能有一个用于全局的PriorityClass资源。
定义好PriorityClass后,就可以用于Pod了。示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: AllWays
priorityClassName: high-priority
亲和性调度
在生产中,一般都会干预、控制Pod资源对象的调度。比如有些业务对于网络方面要求高,让Pod调度到网卡是万兆万卡的节点上,两个业务Pod之间有比较紧密的联系,希望部署到同一个节点上,等等需求。
上面的需求,只需要在这些节点上打上响应的标签,即label,在调度的时候可以使用标签来对Pod进行调度。这种调度机制被称为亲和性和反亲和性调度,或者亲密性和反亲密性调度。
亲和性分为NodeAffinity和PodAffinity,反亲和性只有PodAntiAffinity。
NodeAffinity是将Pod资源对象调度到特定的节点上。比如调度到有万兆网卡的节点上。
NodeAffinity支持两种调度策略:
RequiredDuringSchedulingIgnoredDuringExecution:Pod资源对象必须调度到满足条件的节点上,否则Pod资源对象会调度失败并不断尝试。该策略被称为硬策略。 PreferredDuringSchedulingIgnoredDuringExecution:Pod资源优先被部署到满足条件的节点上,否则从其它节点中选择较优的节点。该策略被称为软策略。
PreferredDuringSchedulingIgnoredDuringExecution该策略在1.14版本中被官方注释了,不建议使用
PodAffinity将Pod资源对象调度到和另外一个Pod资源对象相近的位置,比如调度到同一节点上或同一机房。PodAffinity也支持和NodeAffinity一样的两种策略,不再赘述。
PodAntiAffinity多用于容灾,比如某一业务的Pod不部署到同一节点上。PodAntiAffinity也支持和NodeAffinity一样的两种策略,不再赘述。
领导者选举
领导者选举是分布式锁实现的一种,kube-scheduler组件通过etcd来实现分布式锁。当多个节点中的一个节点成功在etcd创建key并将自身节点信息写入到etcd中后,该节点就会成为领导者,并定时更新该key的信息。成为领导者的节点会执行kube-scheduler调度器的核心逻辑。剩余的节点会处于阻塞状态但并定时尝试获取锁。
如下图,A、B、C三个部署kube-scheduler组件的节点,当A成为领导者后,由A执行调度器核心逻辑,B、C成为候选者,处于阻塞状态不会执行调度器核心逻辑。
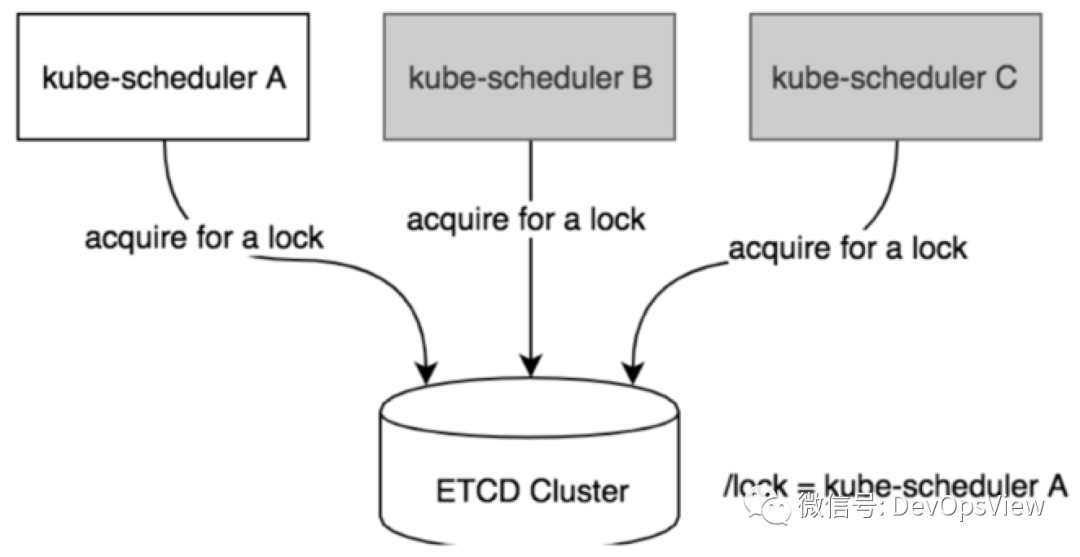
图片来自于《Kubernetes原码剖析》
kube-scheduler组件会创建两个回调函数:OnStartedLeading和OnStopedLeading。kube-scheduler的acquire函数会尝试获取锁,获取到资源锁后,会执行kube-scheduler的核心逻辑即OnStartedLeading回调函数,并通过renew函数默认每隔2秒进行续约。候选者并不会退出,默认每隔2秒定时尝试获取锁。当由于某种原因,领导者被抢占,会执行OnStopedLeading回调函数退出当前主逻辑。
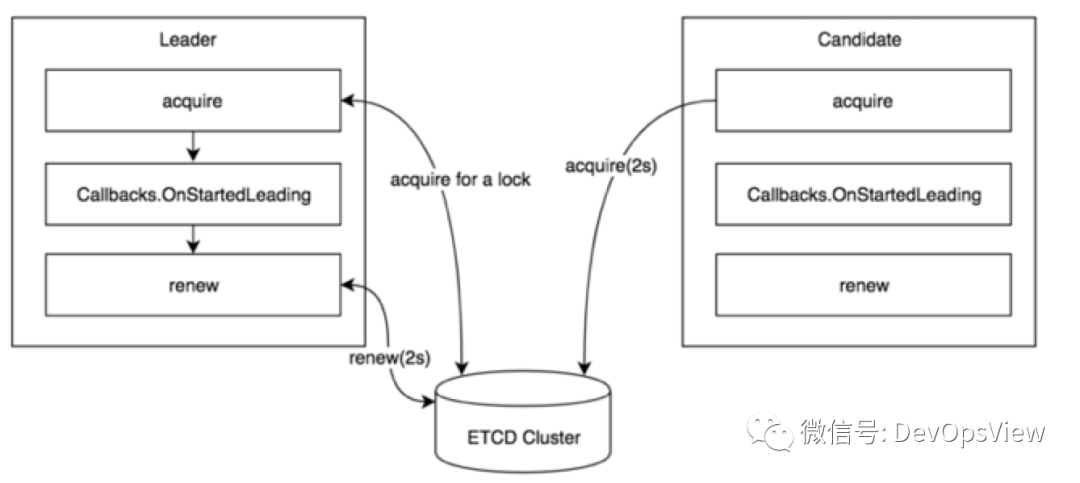
图片来自于《Kubernetes原码剖析》
kube-scheduler实现领导选举的分布式锁(即资源锁),基于etcd集群的key依赖于kubernetes的某种资源,在早期的版本(比如从1.14<=version<=1.19)支持三种锁:Endpoints、ConfigMaps、Leases。默认是使用Endpoints作为资源锁。从1.18.10新增了endpointsleases和configmapsleases两种锁,但是从1.20版本才开始将默认的资源锁修改为Leases。如果不想使用默认的资源锁,可通过--leader-elect-resource-lock参数指定想要使用的资源锁。
由于kube-scheduler组件内容比较多,未展开太多,更多内容大家阅读参考部分的内容,如有问题,请斧正。此外是个人维护公众号,产出比较慢,还望大家多包涵。
参考:
《Kubernetes原码剖析》
Kubernetes Documentation
