




地图匹配(Map Matching,MM)是将位置信息与地图对齐的问题。将车辆记录的GPS数据映射到路网路径这一问题已被广泛研究,而基站轨迹地图匹配(Cellular Trajectory Map-Matching,CTMM)主要针对于基站收集到的定位数据,有着更低的数据精度和更高的定位误差。传统的隐马尔可夫模型(Hidden Markov Model,HMM)并不能直接应用于CTMM问题。面对上述挑战,文章提出了一种学习增强式的HMM模型LHMM。本次为大家带来的是数据库领域顶级会议ICDE于2023年收录的文章《LHMM:A Learning Enhanced HMM Model for Cellular Trajectory Map Matching》。

一. 背景
移动电话的广泛使用产生了大规模的基站轨迹数据,其中每条轨迹都是一系列带时间戳的位置序列。这些数据记录了人们历史移动的位置,可用于安全跟踪、交通管理、用户行为分析等方面。CTMM的目的是将这些轨迹与路网对齐来得到实际的移动路径。
利用现有的地图匹配方法来完成CTMM任务存在以下几个问题:(1)收集的轨迹基于基站位置,与用户的实际距离偏差远远大于GPS定位误差;(2)目前针对CTMM任务的seq2seq方法面临误差传播(error propagation)、曝光偏差(exposure bias)和幻觉问题(hallucination problem)。这些问题导致HMM和seq2seq方法在解决CTMM任务方面表现不佳。
为了解决上述问题,文章提出了一种用于CTMM任务的学习增强式模型LHMM,它将深度神经网络的数据知识整合到HMM框架中进行道路和路径的评估,保留了HMM在通过物理约束的稳定性和seq2seq在识别噪声点方面的优势。
二. 方法介绍
2.1 总体框架
LHMM包括三个模块:多关系表征学习(Multi-relational Representation Learning)、观测/转移概率学习器(Observation/Transition Probability Estimator)和HMM路径查找框架(HMM Path-finding Framework)。
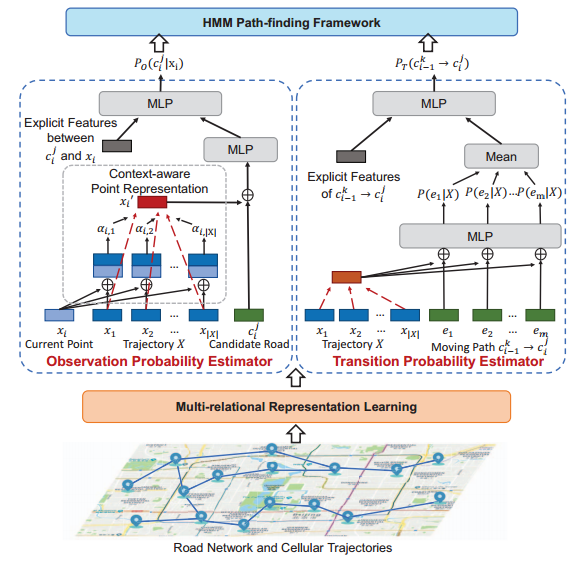
图1 LHMM框架结构
Multi-relational Representation Learning:用低维嵌入(embedding)方法储存多关系语义信息。
Observation/Transition Probability Estimator:观测概率学习器通过学习显式和隐式特征获取知识,以计算观测概率;转移概率学习器获取真实路径和轨迹之间的相关性,以计算转移概率。
HMM Path-finding Framework:基于维特比(Viterbi)算法,利用学习到的两种概率在HMM框架下得到最终的匹配路径。
2.2 Multi-relational Representation Learning
该模块的目的是表示地图匹配任务中的所有对象以及对象之间的关系。通过建立多关系图实现。
2.2.1 多关系图的边
图中的每一条边代表一种关系,图中存在三种关系:
(1)共现关系(Co-occurrence):对于轨迹点xi及其在真实路径下对应路段ej,构造关系边(xi, CO, ej),关系边具有权重,大小为轨迹点和对应路段共同出现的次数。
(2)顺序关系(Sequentiality):对于相邻轨迹点xi和xi+1,构造关系边(xi, SQ, xi+1),代表轨迹的移动模式。
(3)拓扑结构(Topological Structure):对于路段ei和ej,构造关系边(ei,TP, ej),代表路段是邻接的。
建立好关系后,可以在上述三种基本关系上挖掘结点之间的高阶关系以支持地图匹配任务。
2.2.2 多关系图的结点
多关系图的结点通过使用Het-Graph编码器嵌入表示,该编码器可以充分保留多关系语义信息。该编码器包括以下三个步骤:
(1)初始化嵌入(initialize the embedding):对于关系图的结点vi∈v,使用其one-hot编码vi∈R|v|,随后与可学习矩阵Winit∈R|v|×d相乘得到嵌入向量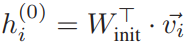 代表
代表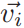 在第0层的嵌入表示。
在第0层的嵌入表示。
(2)消息传递(message passing):每个结点接收来自相邻节点的消息,并根据不同的关系类型分别进行处理。结点vi接受到属于某种关系的邻居的所有消息为:

(3)消息整合(aggregate the message):整合所有邻居传递的消息以及自身的嵌入信息,结点vi的嵌入表示通过下式更新:
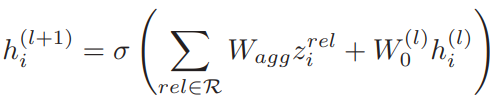
通过编码器设置的嵌入表示,随后的概率计算过程可以依据上述信息识别轨迹和真实路径的相关性。
2.3 Observation Probability Learning
基于HMM的方法通常使用显式特征(如距离)计算观测概率,这种方式在高定位误差下不适用于CTMM任务。文章考虑从点-道路的隐含关系以及一些显式特征得到可学习的观测概率。
同样的轨迹点在不同的轨迹上时,匹配到的位置也可能不同,因此轨迹点需要感知其所在轨迹的上下文。使用注意力机制层将权重自适应的分配到各个历史轨迹点中,并得到具有上下文信息的当前轨迹点的嵌入表示:
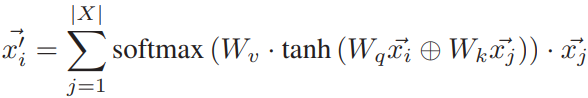
接下来,结合距离这一显式的物理特征,得到最终的观测概率,记为Po(.):

2.4 Transition Probability Learning
转移概率评估的是给定候选路段,两个相邻的轨迹点之间的路径遵循候选路段间最短路径的可能性。文章首先使用注意力机制对轨迹进行了嵌入表示,然后计算每一条边与轨迹的相似性,最后计算两条候选路段组成的最短路径中,所有在最短路径中边的平均概率,相关公式如下:
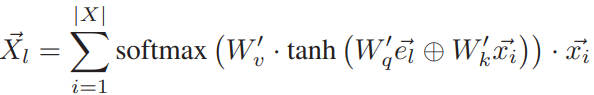
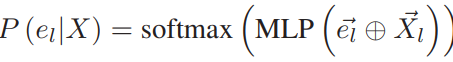
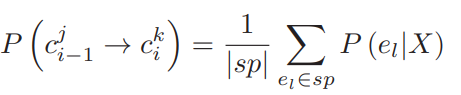
同观测概率,结合距离这一显式的物理特征,可得到最终的转移概率,记为PT(·):

2.5 HMM Path-finding Framework
寻路过程大致与传统的HMM框架相同,文章将其归纳成三个部分:
(1)候选路段准备(Candidate Preparation):对于每个轨迹点的候选路段,选取其前k个观测概率最高的路段作为其候选路段。
(2)候选图构建(Candidate Graph Construction):给定所有候选路段集合,生成一个候选图来描述寻路空间。图的每一个结点代表候选路段集合,集合内部的元素为某一个轨迹点的候选路段,元素与元素之间的边代表相邻候选路段组成最短路径的边集合。一个可能的候选图如图2所示。
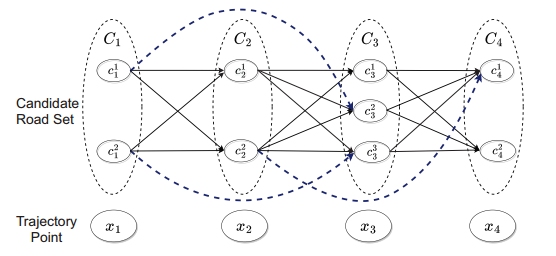
图2 候选图的结构,蓝色虚线代表捷径
相邻候选路段的移动可以通过得分进行评估:
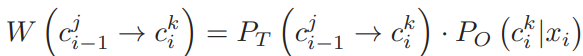
候选路径的总得分即为路径中所有路段转移时的得分之和:
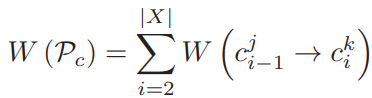
(3)基于维特比的路径查找(Viterbi-based Path-finding):在维特比算法中,会使用一个得分数组f[cik]记录当前最高得分的候选路段,以及一个前驱数组pre[cik]记录当前最高得分候选路段的前驱节点。这样在搜索到最后一个结点后,就可以通过前驱数组向前遍历得到完整的路径。详细的算法步骤见算法1。

文章还对传统的路径查找框架进行了改进,主要针对绕路问题(detour)进行了优化,如图3所示,轨迹点x3由于定位误差较大,其候选路段集合都不在真实路径中,而匹配结果中为了包含该点导致了绕行。为了解决这个问题,文章引入了捷径(shortcut),即向前多考虑一步,考虑绕过轨迹点x3。

图3 使用捷径的例子
为了找到最佳的捷径前驱,可以多考虑一步转移得分:
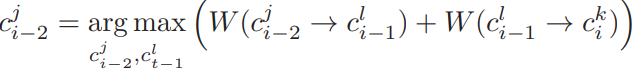
相应的得分数组也要进行变化:
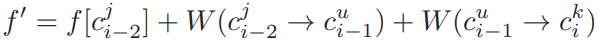
加入捷径后的寻路算法如算法2所示:

三. 实验结果与讨论
3.1 实验设置
数据集:来自移动运营商的两个真实轨迹数据集,分别位于中国杭州与中国厦门。真实路径由GPS采样序列通过经典HMM算法生成。
参数设置:嵌入向量和潜向量的维度设置为128。使用Adam算法优化所有可学习的参数,初始学习率为10-3,权重衰减率为10-4,交叉熵损失的标签平滑为0.1。Het-Encoder的迭代次数q=2。每个点的候选点数k,对于CTMM设置为30,对于其它基线方法设置为45。
评价指标:准确率、召回率、RMF(错误匹配路段总长度/真实路径总长度)、CMF(未被廊道覆盖的总长度/真实路径总长度)、命中率(候选道路集覆盖走过路径的比例)和运行时间。
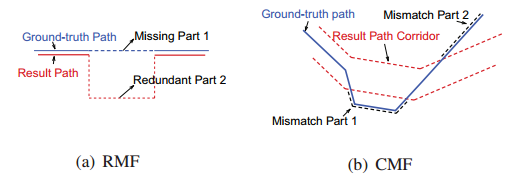
图4 RMF和CMF的图示
基线方法:
匹配GPS轨迹的算法:STM、IVMM、IFM、DeepMM、MCM、TransformerMM。
匹配基站轨迹的算法:CLSTERS、SNet、THMM、DMM。
3.2 总体结果
总体结果如图5所示,主要结论如下:
(1)为CTMM设计的方法总体上由于为GPS轨迹设计的方法;
(2)基于学习的方法比基于HMM的方法在RMF上取得了更好的效果,因为隐式知识提供了更准确的信息来定位轨迹点所在的道路。
(3)在粗粒度的廊道水平上,基于HMM的THMM和MCM方法在CMF50上的精度分别与DMM和TransformerMM相似,这是由于HMM具有较高的稳定性。
(4)LHMM在所有指标上都达到了最佳精度。兼具了最佳的匹配精度和效率。
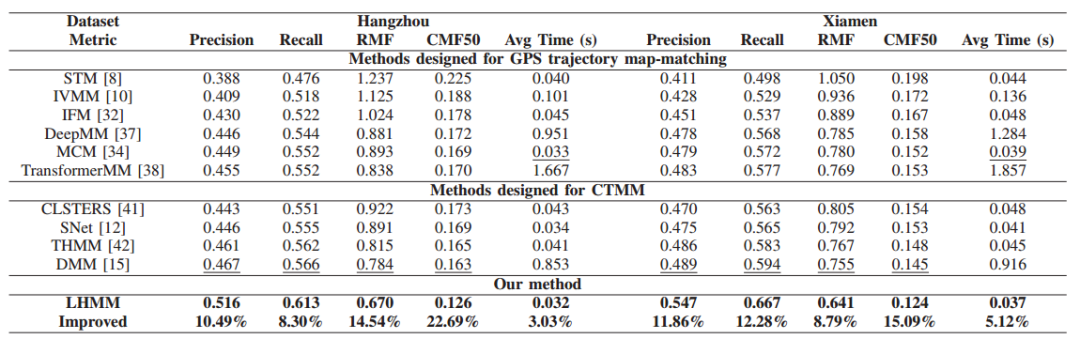
图5 总体结果
3.3 消融实验
消融实验探究了如下几个方面的影响,结果如图6所示:
(1)Het-Encoder的作用:
lLHMM-E:用MLP嵌入层代替基于图的编码器层;
lLHMM-H:用同质图神经网络代替异构图神经网络;
(2)可学习的观测与转移概率:
lLHMM-O:移除了观测概率中点-路之间的隐含关系;
lLHMM-T:移除了转移概率中轨迹-路径的隐含关系;
(3)引入捷径的作用:
lLHMM-S:移除了LHMM中的捷径;
lSTM, STM+S:在其它HMM方法中加入了捷径。
主要结论如下:基于图的编码器能够捕获更丰富的语义信息,多关系需要以平衡的方式嵌入来提取异质性。集成隐式特征可以显著提高匹配性能。捷径可以避免不合格候选道路集的影响。
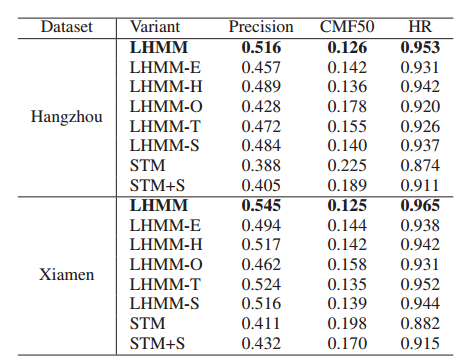
图6 消融实验结果
3.4 稳定性分析
在稳定性分析中,文章比较了不同地区下基站轨迹对地图匹配产生的影响,如基站数量稀疏的农村和分布密度高的城市,结果显示LHMM可以利用物理特征在轨迹密度较低时得到不错的匹配结果。然后,还比较了不同采样率下对匹配效果的影响,结果显示LHMM受依赖轨迹上下文和显式特征的采样率降低的影响最小。
3.5 参数分析
限于篇幅,这里直接给出结论,详细的讨论可参照原文:
(1)候选路段数的选取应该适中,避免过多的路段带来噪声干扰;
(2)1条捷径就足以弥补大部分不合格候选路段集合的影响;
(3)历史轨迹的数据规模可以直接影响神经网络的性能,带来一定的性能提升。
四.总结
文章描述了一种用于基站轨迹地图匹配的学习增强式HMM模型。多关系表征学习模块可以用于捕获为CTMM任务量身定制的多关系信息。学习到的观察概率捕获了轨迹点和道路之间隐含的上下文感知相关性,以便更好地进行定位去噪;学习到的转移概率建模了移动路径和轨迹之间的隐藏相关性。最后,这两个概率在改进的候选图上进行寻路过程。在两个大型真实数据集上的大量实验表明,该方法对CTMM任务具有较高的准确性和鲁棒性。
论文地址:https://ieeexplore.ieee.org/document/10184797
本文作者 黄天羽 重庆大学计算机科学与技术专业2024级硕士生,重庆大学Start Lab团队成员。 主要研究方向:流式轨迹数据管理,时空轨迹管理 |
|

重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|黄天羽
编辑|李佳俊
审核|李瑞远
审核|杨广超
