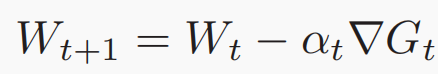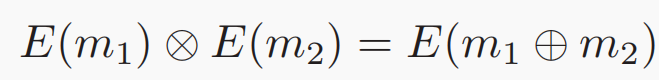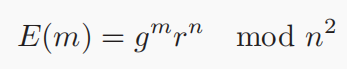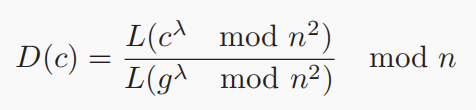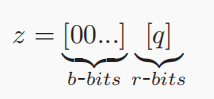联邦学习(Federated learning,FL)需要考虑到隐私问题和数据保护条例,已成为分布式训练全局机器学习模型的范例。FL中涉及大量的计算开销以及通信开销,现有的针对加速训练的研究只考虑单独加速计算或者加速通信,这限制了FL的整体加速能力;除此之外,现有的算法为特定的FL场景设计,通用性较差。因此,今天为大家带来ICDE 2023的论文《FLBooster: A Unified and Efficient Platform for Federated Learning Acceleration》,它提出了FLBooster,一个为联邦学习设计的框架和GPU加速系统,并且使用批处理压缩相关数据,成功解决了开销问题。
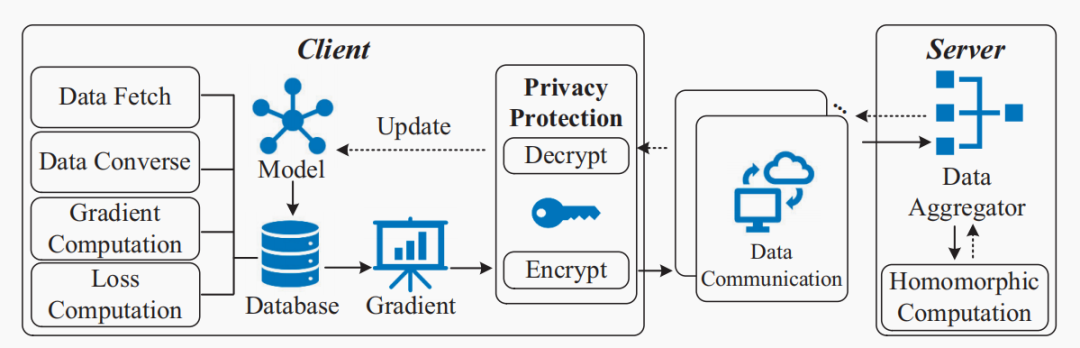
在大数据时代,互联网、金融、医学等广泛领域的数十亿物联网(IoT)设备和服务正在产生海量的训练数据。将这些训练实例上传到中心进行集中模型训练的传统方式可能会遇到隐私泄漏和网络拥塞问题,特别是对于受隐私政策约束的不同参与者⽽言。为了解决这些问题,联邦学习使用大量具有独立数据集的客户端,以一种分布式的方式学习一个共享的机器学习模型,而无需直接观察训练实例。经实验可知,现有的联邦学习框架FATE提供的训练效率无法满足工业应用的要求,归根结底是因为是联邦学习具有大量的同态加密(HE) 操作和昂贵的通信开销。为了避免隐私泄露,联邦进程中客户端和服务器之间不允许交换原始数据,同态加密的密钥大小必须足够大才能击败隐私破解,并且它通常为每个明文生成多个密文,这意味着密文的数量远远多于明文的数量。因此,在联邦学习过程中,每个客户端都需要上传冗余的密文,导致巨大的通信成本。 现有的方法要么只针对特定的机器学习模型在特定联邦学习框架下的加速,如逻辑回归模型或者神经网络模型在特定联邦学习框架下的加速,通用性不高;其次,现有的方法针对模型以及数据压缩,通常使用量化和压缩而不加密,不适合联邦学习框架。本论文提出FLBooster,一种联邦学习的加速框架,核心思想是利用GPU加速训练并且使用批处理压缩通信内容,两者结合成功提高联邦学习的性能。几乎所有的联邦学习都支持SGD,使用SGD的模型更新过程如下图:具体的基于SGD的FL模型训练如图1所示,每个客户端使用公钥加密本地梯度,并将加密的梯度上传到中央服务器;同时,服务器聚合加密的梯度,将聚合结果分发给每个客户端;然后客户端使用私钥解密结果并更新本地模型参数;重复上述操作至模型收敛。由于客户端仅上传加密梯度⽽不是原始值,因此在数据传输和数据聚合期间,服务器或外部各方无法获得任何个人信息,保证了数据的安全性。同态加密的使用是为了保证模型的准确性,对于客户端来说,加密梯度产生的训练结果应该与明文梯度产生的训练结果相同,基本思想如下图所示,其中⊗和⊕表示数学运算,m1和m2是消息,E是加密函数。在联邦学习中,加法同态加密可以有效地执行安全联邦平均,这允许对密文执行特定操作以对明文执行加法,其中Paillier因其简单的实现和可靠的安全性⽽成为最流行的一种。Paillier由以下四个部分组成。(1)密钥生成:选择两个大素数p和q,并计算n=p·q和λ=lcm(p-1,q-1),其中,lcm是最小公倍数函数。(2)选择一个随机的整数g∈Z∗n2满足gcd(n, L(gλmod n2))=1。其中gcd是最大公约数函数,L(x)=(x−1)/n。此时,成功生成公钥(g, n)和私钥(p, q)。(3)加密:对于每个消息m,选择一个随机整数r∈Z∗n2,并对m进行如下加密:根据以上步骤,可发现涉及模乘法,这里利用蒙哥马利乘法算法了解决模乘法的高复杂性,核心思想是用更高效的运算代替复杂的划分和模运算,具体实现如下图所示,这里不多加赘述:

图 2 Montgomery multiplication
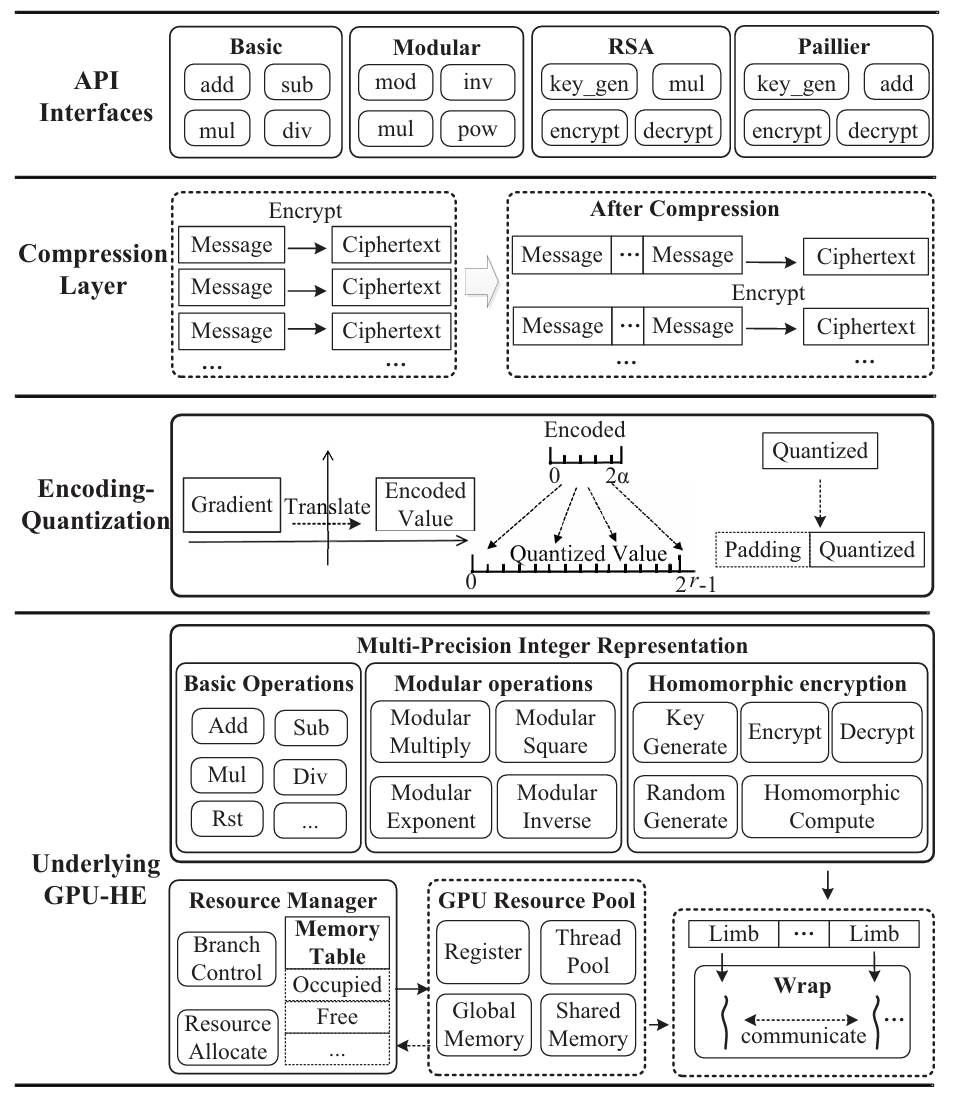
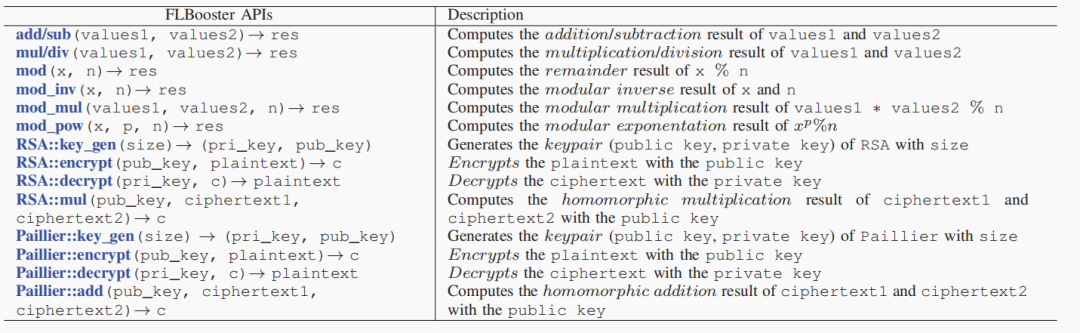
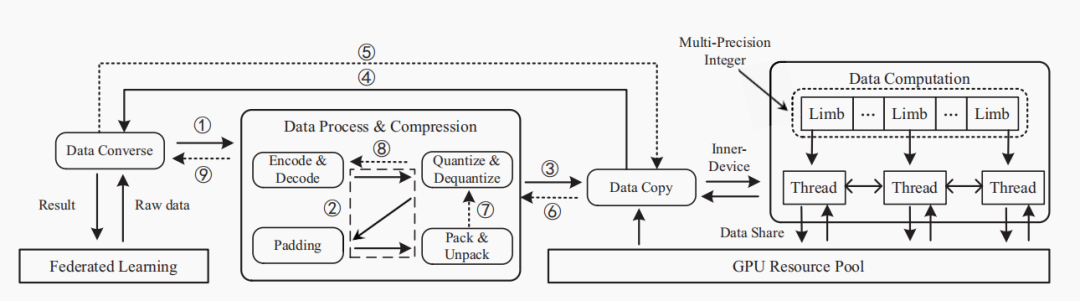
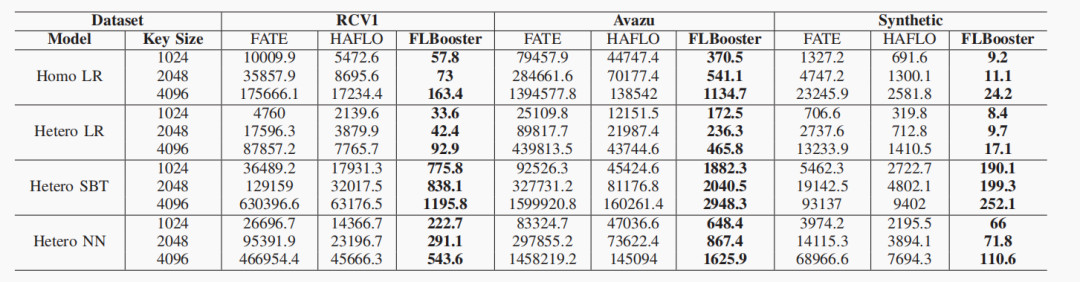
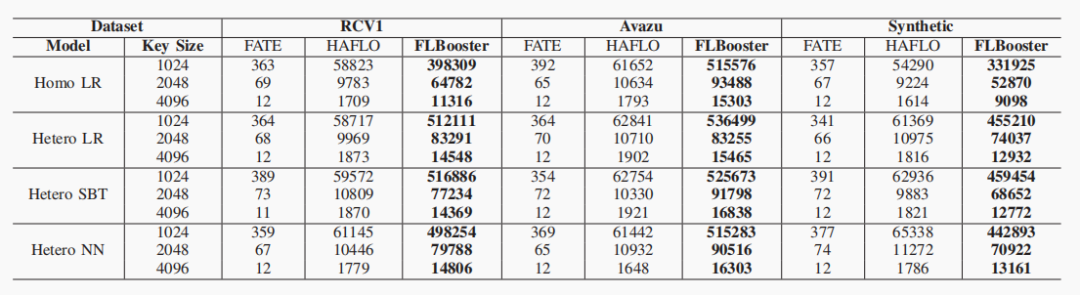
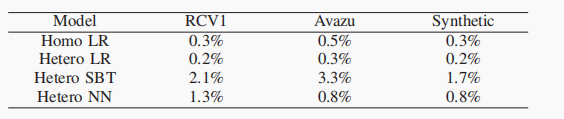
GPU的核心数远远多于CPU,可以实现高密度、高强度、独立数据的并行计算。FLBooster包括四层:GPU‑HE、编码量化、压缩和API接口,如下图所示:是FLBooster的底层计算层,提供并行同态加密能力(包括加密、解密、同态计算)。 具体实现包括自定义多精度整数并定义多精度整数的算术运算以及何最大化利用GPU资源,包括线程数量、寄存器数量、GPU显存大小等。实现了一个名为FRNS的基于基数的多精度数字系统,以在GPU上表示多精度整数。具体来说,将多精度整数拆分为多个分支,然后由多个线程并行处理。①两个多精度整数进行加减:将溢出结果局部存储在该线程中,然后通过线程间通信将溢出结果传播到其他线程中,进行进位(carry)和借位(borrow)。②两个多精度的整数执行乘法:将分支与其他线程中的分支逐个相乘,聚合并将结果传播到其他线程中;使用两个具有相同大小的多精度整数来分别表示最终结果中较重要的字和较不重要的字。③用多重减法和乘法运算替换复杂的除法和其他运算,商通过用更重要的字除以两个多精度整数而得到的,用分子数减去商数和分母的乘积。如果减法的结果溢出,那么通过加法来恢复它。重复这个过程,直到分子小于分母。使用以2w为基数的无符号数字来表示整数,w是一个字的大小。一个整数m用s=⌈k/w⌉个字表示,其中k=⌈log2m⌉是m的位数。对于具有d个线程的GPU程序,每个线程处理s/d个分支或字。借助GPU的强大功能,开发了GPU资源管理器来管理和平衡GPU资源,即线程数、寄存器的数量和内存的大小。开发了一种高效的基于GPU的并行同态加密,包括两个最重要的模运算,即模乘法和模幂运算。为了支持多精度模乘,本文在GPU上实现已知的CIOS方法来进行并行计算,具体算法如下图所示:图 4 The parallel Montgomery multiplication为了支持模幂,将蒙哥马利模乘的GPU实现与滑动窗口指数方法的扩展相结合,成功地将模幂的复杂性从e降低到log2be。除此之外,还开发大整数随机数生成器,方便大素数的生成。由于联邦学习使用的同态加密仅支持无符号整数,因此在加密之前必须将有符号梯度数据转换为无符号整数。现有的联邦学习解决方案倾向于使用不安全的方式通过对有效数字进行编码和加密来量化梯度值,将指数保留在明文中,即(加密(有效数字),指数)。它将数据和模型的近似间隔泄露给对手,这也造成数据冗余,增加通信成本。本文设计了新的安全量化方法,将梯度转换为无符号整数。 (1)根据梯度的分布,对于实数m∈[-α, α],首先通过线性平移将梯度映射到非负数:e=m+α,其中α表示梯度的界限,通常小于1。(2)使用r位来放大编码的梯度:q = e∗ (2r − 1)(3)为了避免梯度聚合中的溢出,保留参与者数量p的最小溢出位数b =⌈log2p⌉,并使用剩余的位数将梯度值量化为误差较小的整数。与现有方案相比,该编码量化更安全、存储成本更低、精度更高。基于编码量化方法,本文开发了批量压缩,将多个明文打包成一个多精度整数并一次性加密。它不仅可以减少通信中的密文数量,还可以减少复杂的加密、解密和同态计算。经过编码和量化后,梯度将被转换为固定位数的无符号整数。然后明文将被打包成一个大整数后加密传输。将常用算法运算封装成了对用户友好的API接口,如下图所示:如下图所示,是FLBooster的流水线过程示意图,主要分为以下三个步骤:1)加密(①-④);2)解密(⑤-⑨);3)同态计算(④-⑤)。使用三个公共数据集:RCV1、Avazu和Synthetic以及选择四个有代表性的联邦学习:同质逻辑回归(Homo LR)、异质逻辑回归(Hetero LR)、异质安全增强(Hetero SBT)和异质神经网络(Hetero NN);与世界上第一个工业级联邦学习框架FATE以及最先进的FL加速系统进行性能对比。主要使用计算消耗、通信消耗以及模型收敛偏差这三个方面来对性能进行评估。各数据集在各模型上的平均运行时间如下图所示,与FATE与HAFLO相比,FLBooster拥有更高的整体效率,总体性能更优。 各数据集在各模型上的吞吐量如下图所示,与FATE与HAFLO相比,FLBooster拥有更大的吞吐量,总体性能更优。如下图所示,FLBooster拥有更好的GPU硬件利用率。从下图可知,FLBooster引起的收敛偏差足够小(即远小于5%),因此可以在所有模型和数据集中都被忽略。 在本文中,提出了一个用于联邦学习的框架和gpu加速系统。为了最大化GPU的计算资源,并行化了加密、解密和同态计算,使计算开销扁平化。此外,为了减少密文扩展造成的通信开销,结合低量化,使用批处理压缩将多个明文打包到一个明文中。它最大化了明文的冗余空间,不仅减少了数据通信量,还减少了同态操作。实验结果表明,该系统在联邦学习方面取得了显著的性能提高。[1]Z. Zeng et al., "FLBooster: A Unified and Efficient Platform for Federated Learning Acceleration," 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 2023, pp. 3140-3153, doi: 10.1109/ICDE55515.2023.00241. 鲁茹芸
重庆大学计算机科学与技术专业本科在读学生,重庆大学START团队成员。主要研究方向:时序数据压缩。 |

|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!