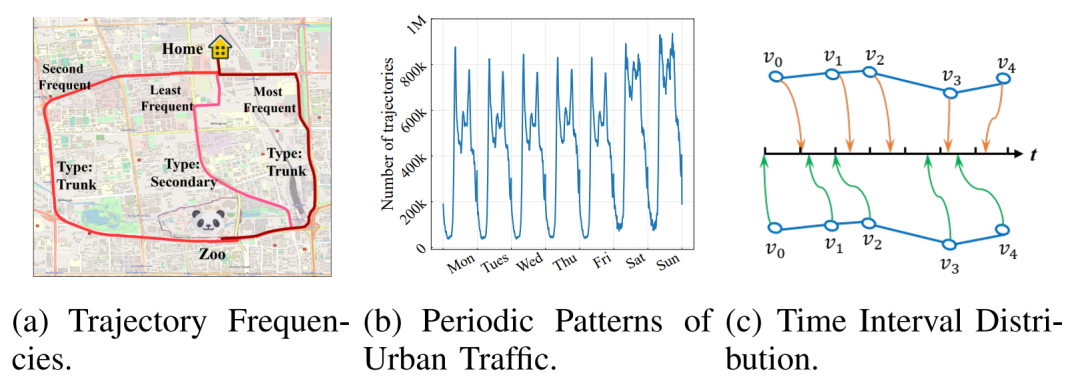
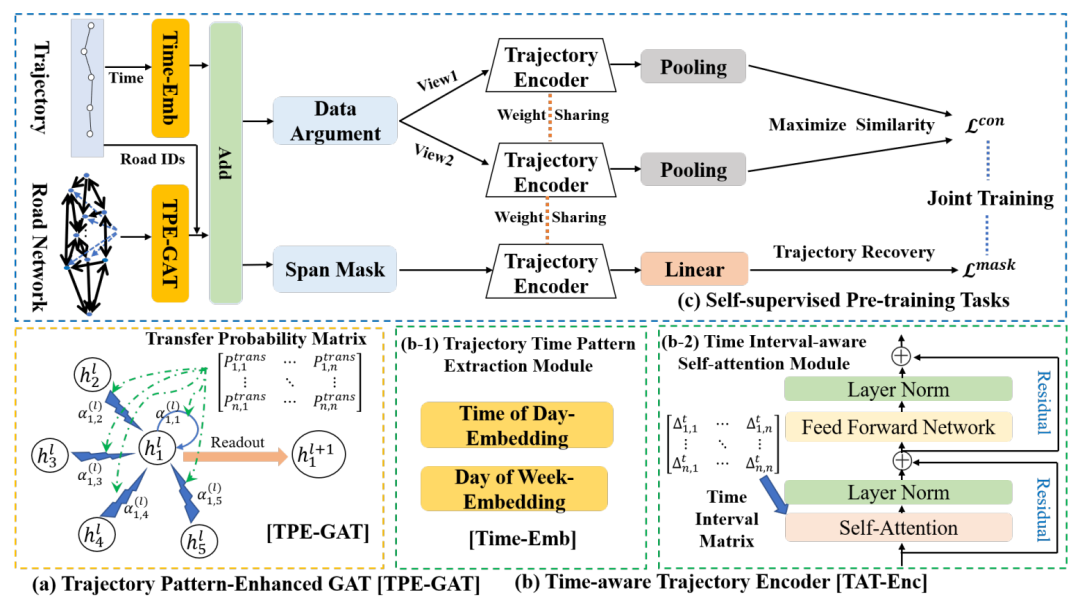
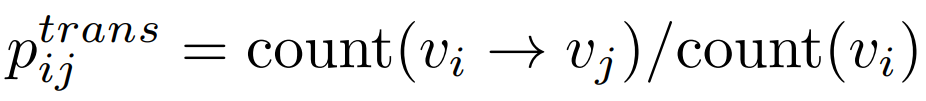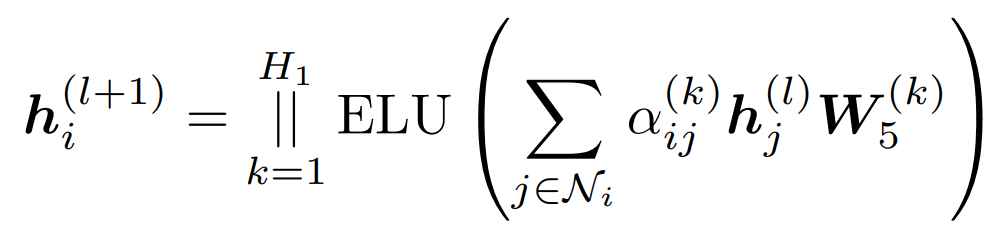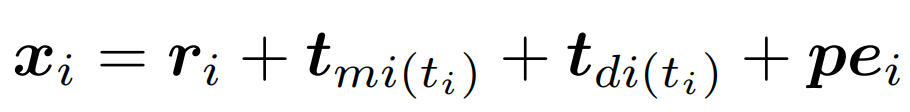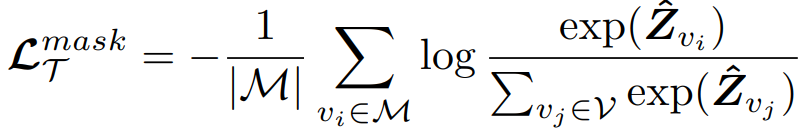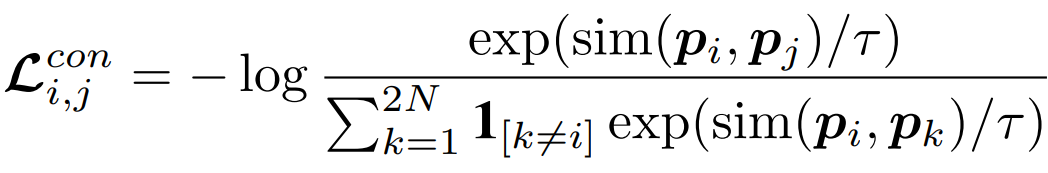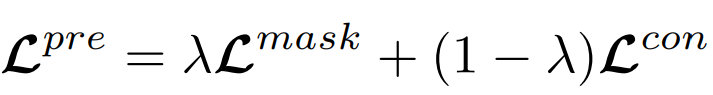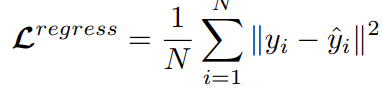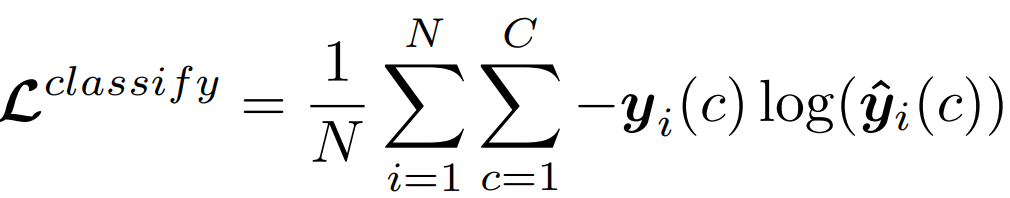轨迹表示学习(Trajectory Representation Learning, TRL)是一种强大的时空数据分析和管理工具,旨在将复杂的原始轨迹转换为低维表示向量,并将其应用于各种下游任务。现有的TRL工作通常将轨迹视为普通的序列数据,而一些重要的时空特征,如时间规律和出行语义,没有得到充分的利用。本次为大家带来数据库领域顶级会议ICDE的论文:《Self-supervised Trajectory Representation Learning with Temporal Regularities and Travel Semantics》。随着定位设备的快速发展,从城市中收集到的轨迹数据也飞速增长。轨迹数据分析与管理已成为数据挖掘领域研究的热点。传统的轨迹数据分析研究需要手工进行特征工程,并且针对特定的任务设计特定的模型,这使得它们难以迁移到不同的应用中。为了提高轨迹数据分析工具的通用性,研究者们提出轨迹表示学习(TRL),将原始轨迹转换为通用的低维表示向量,可以应用于各种下游任务。然而,轨迹数据包含了相当复杂的时空语义信息,许多重要的时空特征和语义信息对下游任务有帮助,但现有工作均没有考虑这些特征。因此,为了获取更完整的轨迹信息,TRL应该考虑两个重要特征。第一个特征是出行语义特征,如图1(a)所示,相同起点和终点的不同轨迹所经过的道路的类型和对应的访问频率不同,也就是指人群的流动模式;第二个应该考虑的特征是时间规律,如图1(b)所示,城市轨道的数量呈现出明显的周期性规律,即早高峰和晚高峰的轨迹数量比平时要多。此外,对于形状相同的两条轨迹,样本点即道路段在时间轴上的分布可能完全不同,如图1(c)所示。这是因为一个路段的行驶时间是动态的,它也可以反映道路的拥堵程度。 文章提出了一种新的具有时间规律和出行语义的自监督轨迹表示学习框架START。START将路网特征和出行语义转换为路段的表示向量,将道路表示序列转换为轨迹表示,并结合时间规则信息。此外,这篇文章还设计两个自监督任务来训练模型,充分考虑了轨迹的时空特征。路网:一个有向图G = (V, ε, Fv, A),V={v1,…,v|v|}是包含|V|个节点的路网,其中每个vi代表一个路段,Ni是vi的邻域,ε⊂ v×v是边集,ei,j=(vi,vj)代表路段vi与vj间有联系,Fv∈R|v|×din代表路段特征,A∈R|v|×|v|为0-1的邻接矩阵,代表对应路段间是否有有向连接;原始轨迹:即基于定位位置的轨迹Jraw是一个由来源于卫星定位终端的时空采样点组成的序列,时空采样点是由纬度、经度和时间戳组成的三元组sp=(lati, loni, ti); 路网限制下的轨迹:一个由用户产生的基本元素为路段的按时间排列的序列J;给定一个轨迹数据集D={Ji}|D|和路网G,要为D中的每一条轨迹J学习一个通用的低维表示向量pi∈Rd。本文构建一个自监督框架,把每个Ji都编码成d维表示向量Pi,然后将表示向量应用于多种下游任务,如出行时间预测、轨迹分类和轨迹相似度计算。如下图2所示,START包括一个轨迹模式增强图注意层(TPE-GAT)和一个时间感知轨迹编码器层(TAT-Enc)。然后,文章还提出了两个自监督任务来训练START。3.1 轨迹模式增强图注意力网络(TPE-GAT)轨迹模式增强图注意力网络(Trajectory Pattern-Enhanced Graph Attention Network, TPE-GAT)是START的第一个阶段,它将路网转换成道路表示向量并结合出行语义。轨迹中包含的路段具有一些重要的隐藏属性,而且它们受路网的邻接关系所限制。因此,START从道路特征和网络结构中学习道路表示向量。以前的工作通常使用基于随机行走的模型,但这种学习方法不能将道路特征和出行语义(如访问频率)加入轨迹中。因此,START使用图神经网络来捕获道路特征和网络结构。考虑到路网是一个有向图,本文选择图注意力网络(GAT),因为它可以通过计算节点对之间的注意力权值来动态地为相邻节点分配权重。为了解决标准GAT无法捕捉轨迹中的运动模式的问题,作者设计了一种轨迹模式增强图注意力网络(TPE-GAT),该网络通过将历史数据计算的道路间转移概率矩阵引入到道路访问频率模型中,扩展了GAT的注意力权重计算。
TPE-GAT共有L1层。首先,连接道路网络中的道路类型、道路长度、车道数量、最大行驶速度、入度和出度六种特征作为路段的初始表示,然后计算注意力权重αij:
其中hi, hj∈Rdl表示vi和vj的路段表示,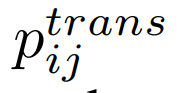 表示从vi到vj的转移概率,用频率来估计:其中count(vi→vj)和count(vi)分别为边(vi, vj)和道路vi在轨迹数据集D中出现的频率。然后,公式可以更新为:TPE-GAT层考虑了静态路网结构和人类流动性之间的关联。最后一层的输出为ri∈Rd,是包含了路网上下文信息和轨迹行驶语义的vi的表示(Representation)。此外,TPE-GAT层与下面描述的轨迹编码器层一起训练。
表示从vi到vj的转移概率,用频率来估计:其中count(vi→vj)和count(vi)分别为边(vi, vj)和道路vi在轨迹数据集D中出现的频率。然后,公式可以更新为:TPE-GAT层考虑了静态路网结构和人类流动性之间的关联。最后一层的输出为ri∈Rd,是包含了路网上下文信息和轨迹行驶语义的vi的表示(Representation)。此外,TPE-GAT层与下面描述的轨迹编码器层一起训练。在获得TPE-GAT层的道路表示后,接下来需要将道路表示序列转换为轨迹表示,并加入时间规律信息。START使用了Transformer Encoder建模轨迹中道路之间的协同关系并进一步扩展了Transformer Encoder,并提出了一个时间感知轨迹编码器层(TAT-Enc),以纳入城市轨迹的时间规律。该层由两个模块组成。第一个是轨迹时间模式提取模块,它使用两个时间嵌入来捕获城市交通的周期性模式。第二个模块是时间间隔感知自注意力模块,用于显式建模轨迹中道路之间的不规则时间间隔。
1) 轨迹时间模式提取模块:为了捕获城市交通的周期性模式,文章使用两个时间嵌入向量分别提取weeks和days的周期性。对于路段vi,其表示可以计算如下:其中ri为原道路表示,tmi(ti)和tdi(ti)为一天内所在分钟和一周内所在天对应的时间嵌入表示,pei表示Transformer中用于引入输入轨迹位置信息的位置编码。2) 时间间隔感知子注意力模块:显式建模组成轨迹的路段间的不规则时间段。文章使用时间间隔感知自注意力替换标准的自注意力:其中 是自适应时间间隔矩阵,其中的每个元素表示轨迹中道路段之间的影响。相邻路段访问时间越接近,即
是自适应时间间隔矩阵,其中的每个元素表示轨迹中道路段之间的影响。相邻路段访问时间越接近,即 越小,矩阵中其对应位置的值就越大。通过这种方式,不规则的时间间隔可以合并到Transformer编码器中。考虑到轨迹的时空特征,文章设计了两个不针对特定下游任务的自监督任务来学习通用表征。1)Span-Masked Trajectory Recovery: 传统的掩模语言建模(mask language modeling, MLM)任务并不完全适用于本任务,因为轨迹是一系列相邻的道路,如果每次单独对一条道路进行mask,模型可以很容易地根据路网中的上下游道路推断出被掩盖的道路。因此,文章在轨迹中选择几个连续子序列进行掩盖。在掩盖轨迹时,使用特殊的token[MASK]替换所选道路,然后使用被掩盖道路的真实值和预测值之间的交叉熵作为优化目标: 2) Trajectory Contrastive Learning: 对比学习的本质是使语义相似的正样本更接近,使负样本相距更远。因此其关键问题是如何在对比学习中构建不同的视图。本文设计了四种轨迹的数据增强策:i)轨迹裁剪,剪掉轨迹的几条连续路段,为保证轨迹的连续性,需要在轨迹的头部或尾部进行裁剪;ii)时间偏移,对几条路径中的时间加入扰动;iii)MASK,随机遮盖轨迹中的路段和对应的时间戳;iv)Dropout,从数据嵌入层中以一定概率随机丢弃一些token,并置其为零。最后采用归一化的带温度交叉熵(normalized temperature-scaled cross-entropy loss)作为损失函数:训练最终的损失函数为上文提到的两个损失函数的加权和:在通过自监督学习得到一个通用预训练模型之后,有必要根据特定任务用有标签的数据进行微调。1)Trajectory Travel Time Estimation:该任务的目的是在给定的道路序列和出发时间下,估计从起点到目的地的行驶时间。这里使用单个全连接层构建回归模型,得到预测值,然后以均方误差(MSE)作为优化目标: 2)Trajectory Classification:该任务的目的是根据特定的标签对轨迹进行分类,例如是否载客等。这里使用一个简单的使用softmax激活函数的全连接层来获得预测值,然后利用交叉熵损失对模型进行优化:2)Trajectory Similarity Computation and Search: 文章设计了两个子任务,最相似轨迹搜索和k-nearest轨迹搜索。这里直接使用预训练任务得到表示,而不需要进行微调,直接计算两条轨迹之间的欧式距离进行比较。所有的实验在Ubuntu 18.04
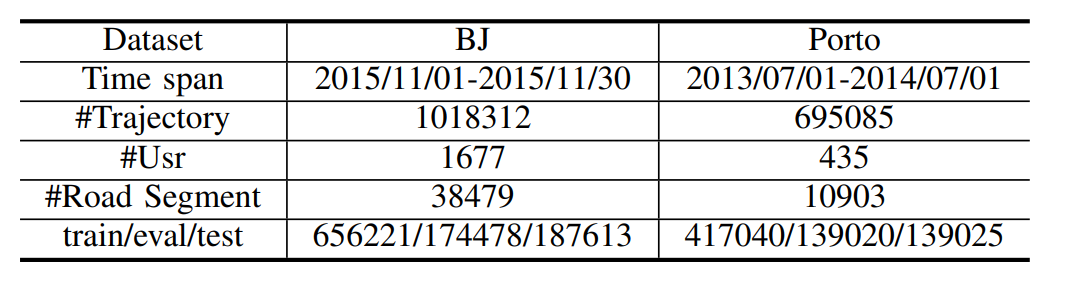
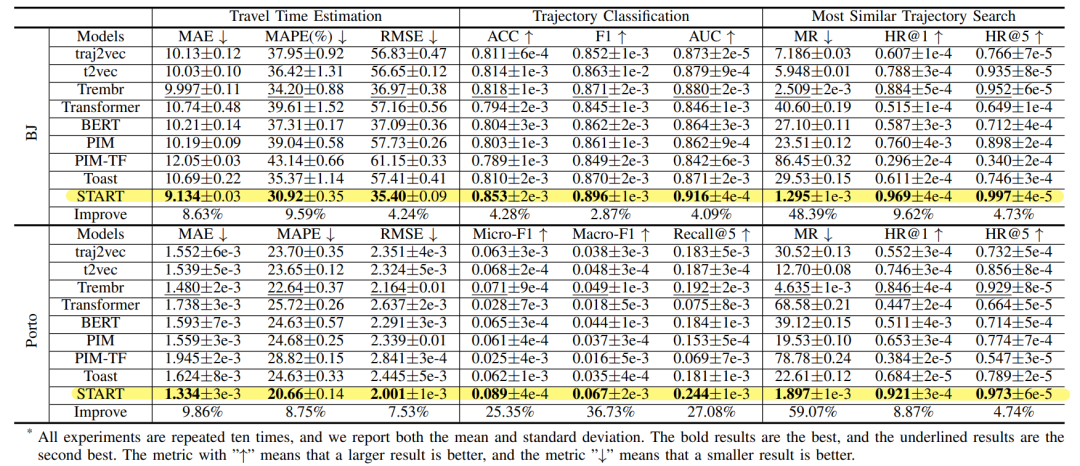
with an NVIDIA GeForce 3090 GPU上进行。使用的数据集如下表1所示。文章考虑了轨迹出行时间预测、轨迹分类、轨迹相似度计算和搜索三个下游任务,实验结果如下表2所示。从表中可以看出对于这两个真实世界的数据集,START在所有任务上都达到了最佳性能。通过在预训练阶段引入时间规则和行程语义,证实了START在学习轨迹表示方面具有更优越的性能。此外,使用重构的编码器-解码器模型优于序列表示模型(如Transformer, BERT)。这可能是因为这两种模型的预训练方法不适合轨迹数据,忽略了时空特征。相比之下PIM和Toast模型的性能不理想,主要是因为它们将轨迹视为普通的道路序列,而忽略了时间信息;其次,他们的道路表征学习方法没有充分考虑出行语义,如道路访问频率。文章使用了两种方式验证其设计的两个预训练任务的有效性:一个是探索是否可以通过预训练减少训练数据的大小;另一个是研究预训练模型是否可以迁移到其他小数据集上,以解决许多实际应用中训练数据不足的问题。下图3显示了模型在出行时间估计和轨迹分类任务上的性能。
越小,矩阵中其对应位置的值就越大。通过这种方式,不规则的时间间隔可以合并到Transformer编码器中。考虑到轨迹的时空特征,文章设计了两个不针对特定下游任务的自监督任务来学习通用表征。1)Span-Masked Trajectory Recovery: 传统的掩模语言建模(mask language modeling, MLM)任务并不完全适用于本任务,因为轨迹是一系列相邻的道路,如果每次单独对一条道路进行mask,模型可以很容易地根据路网中的上下游道路推断出被掩盖的道路。因此,文章在轨迹中选择几个连续子序列进行掩盖。在掩盖轨迹时,使用特殊的token[MASK]替换所选道路,然后使用被掩盖道路的真实值和预测值之间的交叉熵作为优化目标: 2) Trajectory Contrastive Learning: 对比学习的本质是使语义相似的正样本更接近,使负样本相距更远。因此其关键问题是如何在对比学习中构建不同的视图。本文设计了四种轨迹的数据增强策:i)轨迹裁剪,剪掉轨迹的几条连续路段,为保证轨迹的连续性,需要在轨迹的头部或尾部进行裁剪;ii)时间偏移,对几条路径中的时间加入扰动;iii)MASK,随机遮盖轨迹中的路段和对应的时间戳;iv)Dropout,从数据嵌入层中以一定概率随机丢弃一些token,并置其为零。最后采用归一化的带温度交叉熵(normalized temperature-scaled cross-entropy loss)作为损失函数:训练最终的损失函数为上文提到的两个损失函数的加权和:在通过自监督学习得到一个通用预训练模型之后,有必要根据特定任务用有标签的数据进行微调。1)Trajectory Travel Time Estimation:该任务的目的是在给定的道路序列和出发时间下,估计从起点到目的地的行驶时间。这里使用单个全连接层构建回归模型,得到预测值,然后以均方误差(MSE)作为优化目标: 2)Trajectory Classification:该任务的目的是根据特定的标签对轨迹进行分类,例如是否载客等。这里使用一个简单的使用softmax激活函数的全连接层来获得预测值,然后利用交叉熵损失对模型进行优化:2)Trajectory Similarity Computation and Search: 文章设计了两个子任务,最相似轨迹搜索和k-nearest轨迹搜索。这里直接使用预训练任务得到表示,而不需要进行微调,直接计算两条轨迹之间的欧式距离进行比较。所有的实验在Ubuntu 18.04
with an NVIDIA GeForce 3090 GPU上进行。使用的数据集如下表1所示。文章考虑了轨迹出行时间预测、轨迹分类、轨迹相似度计算和搜索三个下游任务,实验结果如下表2所示。从表中可以看出对于这两个真实世界的数据集,START在所有任务上都达到了最佳性能。通过在预训练阶段引入时间规则和行程语义,证实了START在学习轨迹表示方面具有更优越的性能。此外,使用重构的编码器-解码器模型优于序列表示模型(如Transformer, BERT)。这可能是因为这两种模型的预训练方法不适合轨迹数据,忽略了时空特征。相比之下PIM和Toast模型的性能不理想,主要是因为它们将轨迹视为普通的道路序列,而忽略了时间信息;其次,他们的道路表征学习方法没有充分考虑出行语义,如道路访问频率。文章使用了两种方式验证其设计的两个预训练任务的有效性:一个是探索是否可以通过预训练减少训练数据的大小;另一个是研究预训练模型是否可以迁移到其他小数据集上,以解决许多实际应用中训练数据不足的问题。下图3显示了模型在出行时间估计和轨迹分类任务上的性能。
从图中可以发现,随着标记数据的增加,两种模型的性能都有所提高, START的性能始终优于No Pre-train变体。此外,随着预训练数据的增加,模型的性能也得到了显著的提高。这些实验表明,预训练可以有效地减少训练数据的使用。在该部分,设置了用随机初始化的可学习表示,Node2vec替代TPE-GAT,去掉轨迹时间模式模块,去掉时间间隔感知自注意力模块中的自适应时间间隔矩阵等10种不同的消融类别。实验结果如下图4所示。从图中可以看到,首先,是否使用TPE-GAT会对性能产生显著影响,如果没有TPE-GAT,性能会明显下降。其次,忽略时间周期性特征后,性能显著下降(即w/o Time Emb)。它证实了引入周期性城市模式的必要性。此外,去除时间间隔矩阵会导致显著的性能下降。除此之外,两种自监督预训练任务(w/o Mask, w/o
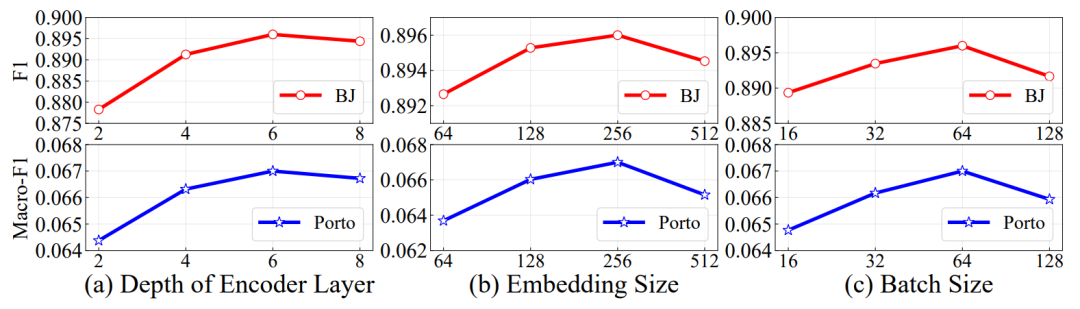
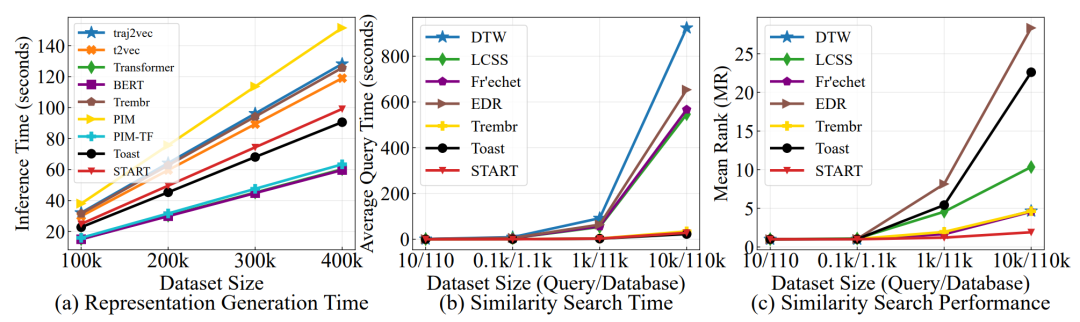
Contra)都会显著影响下游任务的性能。最后文章对比了四种数据增强方法的效果,实验结果如下图5所示,颜色越浅代表其效果越好。从图中可以看出,数据增强方案中Mask效果最好,其次是时间偏移和Dropout,最后是轨迹裁剪。文章对关键超参数(编码器层L2、嵌入尺寸d和批大小Ni)进行参数敏感性分析。从下图6可以看出,模型性能最初随着d和L2的增大而提高,但当d和L2过大时,由于过拟合导致性能下降。如图7所示,自注意力模型比RNN模型更高效,这是因为RNN模型需要O(L)的序列操作来处理轨迹(L是轨迹的长度),而自注意力模型只需要O(1)。此外,START比其他自注意力模型稍微慢一些,因为它引入了TPE-GAT层和时间间隔矩阵,这是性能和效率之间的权衡。即便如此,对100,000个轨迹进行编码只需要25.8秒。在进行相似度搜索时,可以看到深度模型比传统算法至少快一个数量级,因为计算相似度的传统算法的复杂度通常为O(L2),而深度模型计算表示之间的距离只需要O(d)复杂度(L是轨迹的长度,d是嵌入的大小)。START模型对应的时间随数据量线性增加,这意味着START可以扩展到大型数据集。文章介绍了一种两阶段的轨迹表示学习方法START,其将时间规律性和出行语义结合到通用轨迹表示编码中。此外,本文设计了两个自监督的任务来训练模型,它充分考虑了轨迹的时空特征。在三个下游任务的两个大规模数据集上,与先进的baseline进行的大量实验对比证实了START优越性能。
李佳俊 重庆大学计算机技术专业2023级硕士生,重庆大学START团队成员。主要研究方向:时空数据管理 | 
|
重庆大学时空实验室(Spatio-TemporalArt Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!