




在当前的大数据时代,流处理技术变得越来越普遍。然而,随着数据流规模的不断增加,流处理系统面临着存储和传输两方面的巨大压力。为了解决存储和传输的压力,最新的论文提出了一种基于压缩的流处理引擎CompressStreamDB,可以直接在压缩流上进行自适应细粒度流处理,实现高吞吐量低延迟。本次为大家带来数据库领域顶级会议ICDE 2023的论文:《CompressStreamDB: Fine-Grained Adaptive Stream Processing without Decompression》。

一.背景
在大数据时代的今天,数据源源不断地产生,对大量连续到达的数据进行低延迟实时的处理使得流处理技术越来越普遍。由于数据量的庞大,流处理面临着传输带宽和内存空间的压力。因此,在流处理中使用压缩非常重要,这有助于提高流系统的性能,减少数据冗余,提高传输效率。然而,设计压缩流直接处理系统面临三大挑战。首先,流处理需要低延迟,但压缩算法通常需要时间进行编码,从而导致严重的延迟。其次,对于不同的输入工作负载,需要权衡压缩算法在压缩率与时间开销的利弊,自适应选择以实现更好的性能。第三,在执行SQL查询之前,可能需要进行解压,这会带来额外的时间和空间开销,从而降低性能。
作者开发了一个基于压缩的流处理引擎,称为CompressStreamDB,它可以通过系统的特殊设计来解决上述三个挑战。首先,为了保证流处理的低延迟和实时性要求,选择轻量级和快速的压缩算法。其次,针对不同特性的输入流,作者设计了一个细粒度的自适应压缩算法选择器,可以动态选择能够带来最大性能提升的压缩算法。第三,为了处理解压缩开销,作者提出了一种可以避免解压的解决方案。
论文的主要贡献如下:
开发了压缩流处理引擎,其中包括多种轻量级压缩方法,适用于不同的场景。
提出系统成本模型指导压缩流处理,并基于成本模型设计自适应压缩算法选择器。
设计了一种直接对压缩流执行 SQL 查询的处理方法,可以避免解压带来的开销。
二.问题定义与基本思想
问题定义
输入数据流是从数据源生成的元组的无限序列。要在流中处理的数据块称为窗口 w,其中包含预设大小的元组序列。本文使用 SQL 查询来处理这些流。每个查询都包含不同的运算符,包括投影、聚合等。给定所选的压缩算法 τ,流在源处压缩,压缩流表示为 R′。最后,压缩的流和查询被传输到处理器。压缩流处理的结果由一系列查询后的流中的元组组成。本文的优化旨在最大限度地减少延迟,同时提高吞吐量。
基本思想
为了解决这个问题,基本思想是压缩流直接处理。作者开发了一个细粒度的自适应模型来选择合适的压缩方案,并在压缩数据和运算符之间执行映射。对于每个流式 SQL 运算符,本文修改它读取的字节数并压缩它使用的值。这样,无需解压即可查询数据,从而节省时间和空间。
此外,采用的压缩算法为轻量级压缩算法。轻量级压缩的编码方法相对简单。与重量级压缩算法相比,它们以较低的压缩率换取更快的压缩和解压缩时间。再将轻量级压缩算法分为两类:预先压缩(eager compression)和延迟压缩(lazy compression)。表一中总结了两类常见的轻量级压缩算法。预先压缩算法在输入元组的子集到达时便进行压缩,可以及时处理每个元组无需等待。延迟压缩需要等待整个数据批次进入后再进行压缩,可以更好地利用大量数据的冗余以实现更高压缩率。
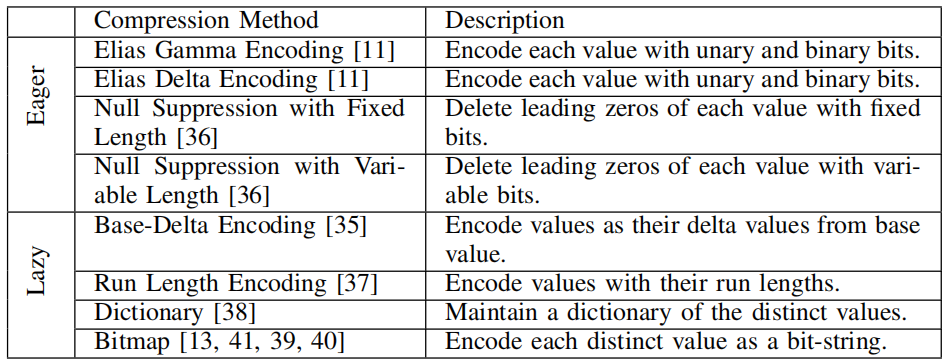
表一
三.CompressStreamDB框架
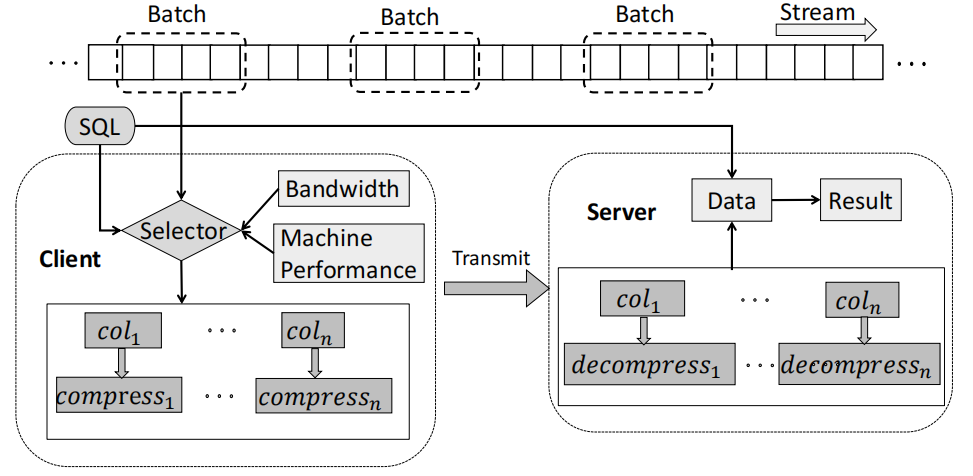
图一
如图一所示,CompressStreamDB 框架由两部分组成:客户端和服务器。客户端具有基于成本模型的压缩算法选择器,选择器负责收集要处理的数据并选择最佳压缩算法。服务器负责压缩数据流数据的查询处理,包含了查询的内核函数。以批处理粒度处理输入数据,并对每列数据使用不同的压缩算法,如表一所述。压缩的数据被传输到服务器,服务器通过相应的SQL查询处理压缩的数据。
四.压缩流处理
动态工作负载的自适应处理
流处理是通过由这些运算符(如投影,选择,聚合,分组,连接)组成的查询语句执行的,这些运算符具有给定的滑动窗口大小。在预设的批次数之后,使用系统成本模型重新选择数据列的压缩算法。然后 CompressStreamDB 扫描接下来的五批来预测后续流的数据属性,使用系统成本模型计算具有属性的延迟,最终确定总处理时间最短的新处理方法。考虑到使用的压缩算法都是轻量级的,动态重新选择的开销可以忽略不计。
无需解压即可查询
CompressStreamDB 尽可能避免解压,从而减少解压时间和内存访问开销,加快查询过程。在作者的设计中,当压缩流满足以下三个条件时,可以直接查询压缩数据:
1. 压缩后的数据与压缩前的数据相似,并且仍然是结构化的。
2. 对齐压缩流数据。
3. 压缩不影响流的顺序和内核操作的过程。
例如,假设流数据包含三列:col1为 8 个字节,col2为 4 个字节,col3为 4 个字节。压缩后,col1’为 2 字节,col2’为 1 字节,col3’为 1 字节。 “select col1, avg(col2) from data group by col3”这样的查询可以映射到“select col1’, avg(col2’) from data group by col3’ ”。这样,我们只需要更新运算符中每个对应列要读取的字节数。原始流处理算子根据压缩映射到相应的压缩流处理算子。
五.系统成本模型
为了指导系统在运行时自动选择合适的压缩算法,作者提出了一个压缩流处理系统的成本模型,考虑了机器指标、网络状况和其他广泛因素。CompressStreamDB 的流程主要包括压缩、传输、解压和查询处理四个阶段,对应的时间分别为tcompress, ttrans, tdecom, tquery,则系统总成本为t = tcompress + ttrans+ tdecom + tquery。
系统成本模型中的主要参数如表二所示。
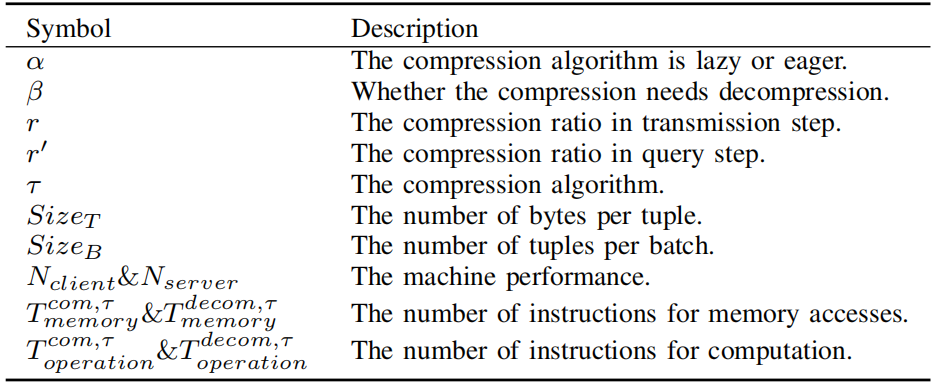
表二
压缩时间
压缩时间计算方法为:
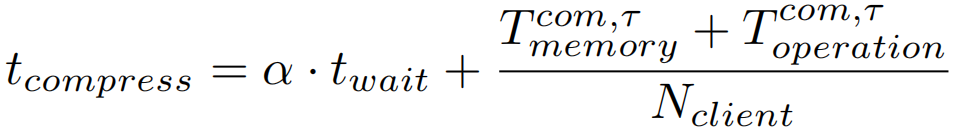
预先算法会立即压缩数据,而延迟压缩算法需要等到整个数据批次达到;用twait表示等待数据批次所花费的时间,则
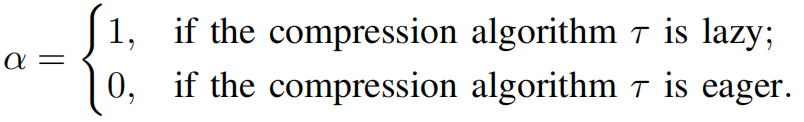
传输时间
对于压缩的单元批处理,需要传输的字节大小为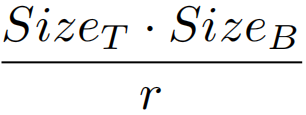 。当网络带宽足够且不需要考虑排队延迟时,传输时间为
。当网络带宽足够且不需要考虑排队延迟时,传输时间为
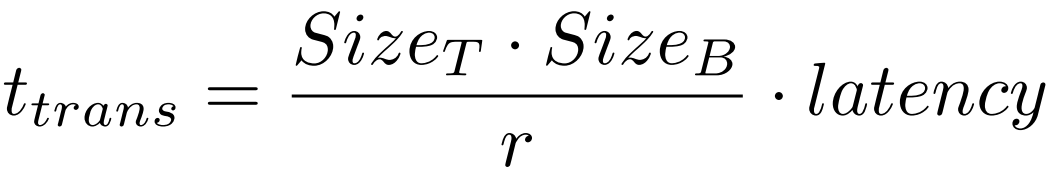
网络带宽被完全占用时,传输时间为
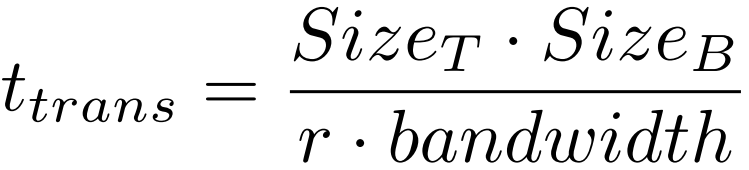
解压时间
同理压缩时间,解压时间为
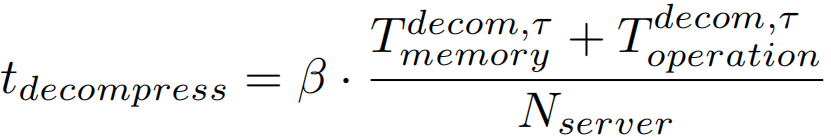
其中

查询时间
由于 CompressStreamDB 以字节为单位进行读写,因此内存读写时间与内存中占用的字节数成正比。用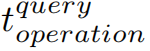 表示查询的计算时间,
表示查询的计算时间,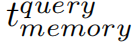 表示在内存上读取和写入花费的查询时间;则查询时间为
表示在内存上读取和写入花费的查询时间;则查询时间为
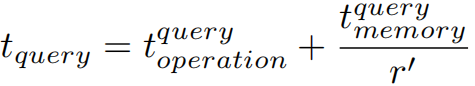
其中

六.选定压缩算法
CompressStreamDB 涉及八种轻量级压缩算法,如表一所述。CompressStreamDB 可以在运行时基于系统成本模型自适应地选择这些替代方案。
1.预先压缩
预先压缩算法会立即压缩到达的元素,不需要等待整个批次。因此,在系统成本模型中的α为0。
Elias Gamma encoding (EG)
压缩率为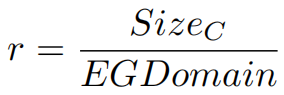 ,其中SizeC表示列中每个元素的大小,EGDomain表示此列中采用该编码所需的最大字节数。
,其中SizeC表示列中每个元素的大小,EGDomain表示此列中采用该编码所需的最大字节数。
其存储格式对齐,以便编码结果具有相同的字节数,压缩数据仍然是结构化的。CompressStreamDB可以避免使用该格式进行解压,故有参数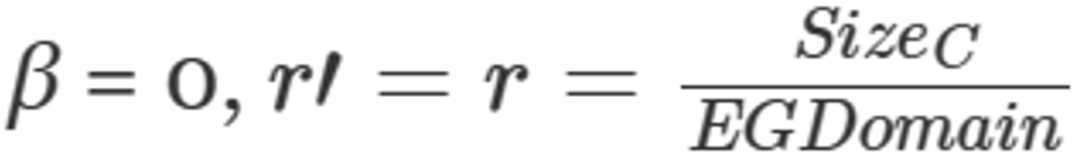 。
。
Elias Delta encoding (ED)
同理EG,有参数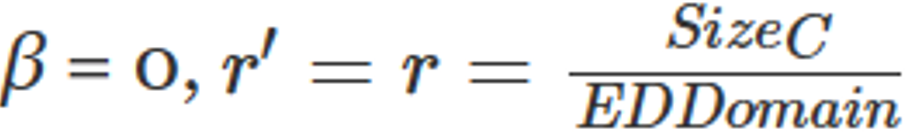 。
。
Null suppression with fixed length (NS)
相关参数为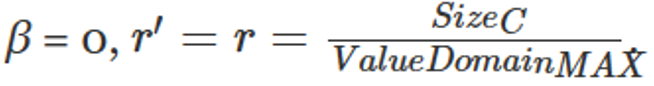 ,其中ValueDomainMAX表示元素在NS压缩后的字节数。
,其中ValueDomainMAX表示元素在NS压缩后的字节数。
Null suppression with variable length (NSV)
压缩率为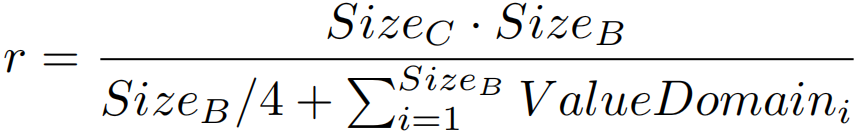 。由于压缩原始不是字节对齐的,因此必须在处理之前解压,故参数为
。由于压缩原始不是字节对齐的,因此必须在处理之前解压,故参数为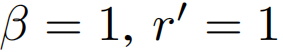 。
。
2.延迟压缩
延迟压缩算法等到整个输入批处理到达,然后压缩整个批处理。因此,在系统成本模型中的α为1。
Base-Delta encoding (BD)
压缩率为 。它可以避免在CompressStreamDB中解压,故参数有
。它可以避免在CompressStreamDB中解压,故参数有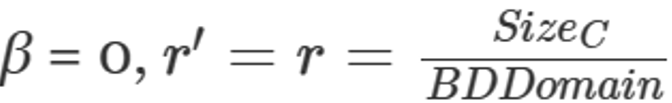 。
。
Run length encoding (RLE)
用AverageRunLength表示数据批次列的平均长度,由于运行长度需要一个额外的int变量(4字节)表示,故压缩率为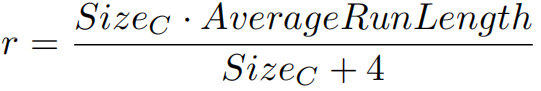 。
。
RLE不是字节对齐的,破坏了原始数据结构,故在处理之前需要减压,则相关参数为。
Dictionary (DICT)
压缩率为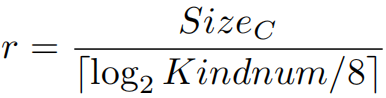 ,其中Kindnum为数据类型的数量。
,其中Kindnum为数据类型的数量。
由于采用DICT时字节对齐且结构化的,可以避免解压,故相关参数为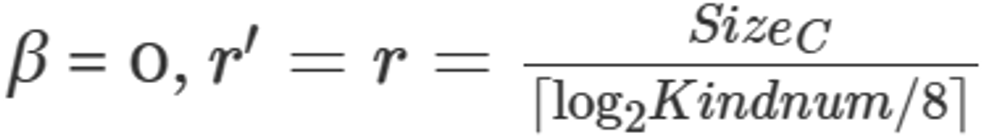 。
。
Bitmap
压缩率为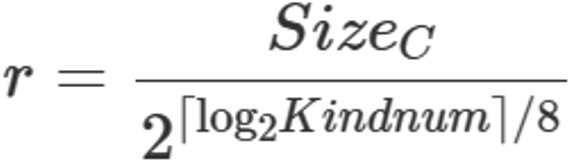 。由于破坏了原始数据的数据结构,相关参数为。
。由于破坏了原始数据的数据结构,相关参数为。
七.实验
实验设置
实验在阿里云中进行,平台可以在服务器和客户端之间提供从0到1Gbps的网络带宽,服务器和客户端都配备了Intel Xeon Platinum 8269CY 2.5 GHz CPU和16GB内存,运行Ubuntu 20.04.3 LTS和Java 8。
实验使用了三个真实世界的数据集:1.智能电网中的能耗测量(Smart Grid),来自智能电网中的不同设备,侧重于能源消耗中的负荷预测和实时需求管理;2. 计算集群监控(Cluster Monitoring),来自 Google 的集群,模拟集群管理场景;3. 线性道路基准(Linear Road Benchmark),表示车辆的位置,并对收费公路网络进行建模。
使用六个查询来评估 CompressStreamDB 中自适应压缩的性能,如表三所示。本文对每个数据集使用两个查询来获取性能指标,并评估不同处理方法的性能,包括Baseline、Base-Delta、八种轻量级压缩算法和 CompressStreamDB。

表三
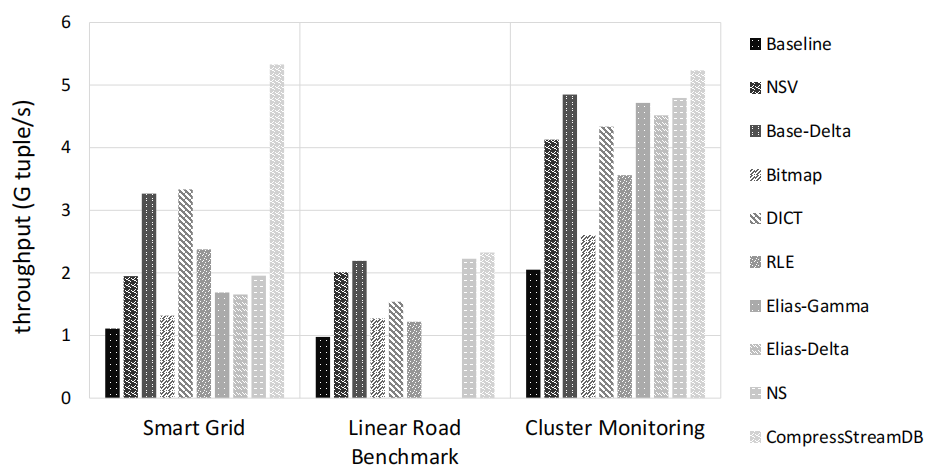
吞吐量
如图二所示,平均而言,CompressStreamDB 实现了 3.24× 的吞吐量提升,与各种方法相比均有更优的吞吐量。其中可以得出,压缩可以明显提高流处理系统的吞吐量,尽管 Base-Delta 通常在大多数情况下可以提供良好的系统性能,但 CompressStreamDB 中使用的自适应压缩仍然可以实现更好的性能。此外,压缩在流处理中的效果受数据集属性的显著影响。例如,如果数据集的平均运行长度较低,则 RLE 无法提供足够的性能;因此,算法的选择是提高性能的重要因素。最后,CompressStreamDB可以结合不同算法的优势,适应各种情况。无论数据集是什么,CompressStreamDB 都可以实现与任何单一压缩算法相似或更好的性能。
图二
延迟
如图三所示,平均而言,CompressStreamDB 的延迟降低了 66.0%;与实验中任何单一压缩算法相比,CompressStreamDB有更低的延迟。

图三
八.总结
流处理技术在大数据领域很普遍。随着流数据规模的不断扩大,流处理系统面临着巨大的时间和空间压力。本文提出了 CompressStreamDB,它在流处理中应用压缩算法来提高系统性能。具体来说,本文在 CompressStreamDB 中涉及八种轻量级压缩算法,可以获得比没有压缩时更好的性能。实验表明,在三个真实数据集上,CompressStreamDB 可以实现 3.24×吞吐量提升和 66.0% 的延迟降低,同时节省 66.8% 的空间。
本文作者 |  |
