






论文地址:https://arxiv.org/pdf/2411.19951

01
摘要

02
核心内容
具体步骤如下:
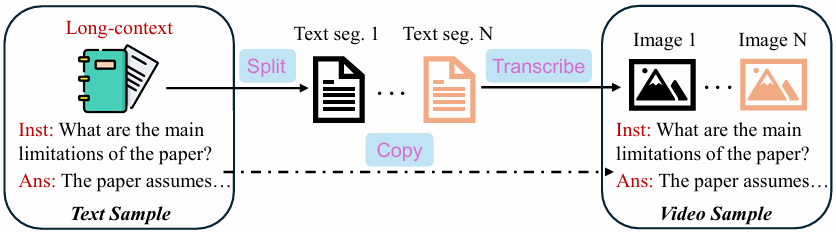
选择包含 (long-context, instruction, answer) 三元组的文本数据集。
long-context 是一个长文本段落,例如书籍章节或学术论文片段。
instruction 是一个针对 long-context 的指令,例如“总结这段文字”。
answer 是 instruction 对应的答案。
将 long-context 分割成多个段,每个段包含一定数量的句子。 段落数量可以根据需要进行调整,以模拟不同长度的视频。
使用文本到图像生成模型(例如 Stable Diffusion 或 DALL-E)将每个文本段转换为图像。 可以根据需要调整图像的风格和分辨率。
将生成的图像序列、instruction 和 answer 按照视频指令数据的格式进行组织。 例如,可以使用 (image_sequence, instruction, answer) 三元组的形式。
将生成的视频样本与现有的视频指令数据集进行混合,作为微调训练的语料库。
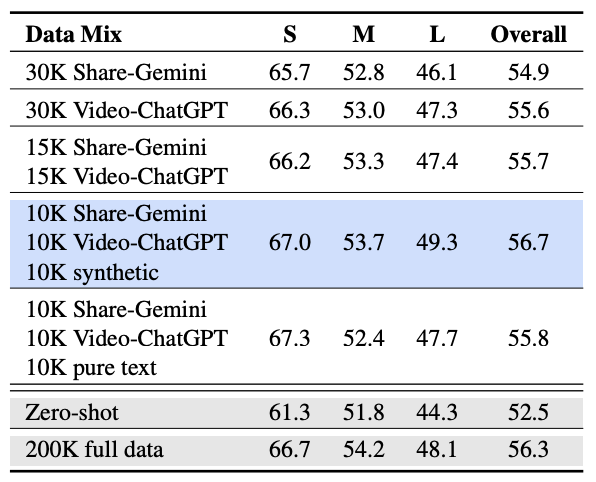
实验:
Image-LLM,如 MiniCPM-8B、Idefics3-8B 等。
Video-MME:包含各种场景的视频数据集。 MVBench:评估视觉感知任务。 TempCompass:测量时态上下文理解。
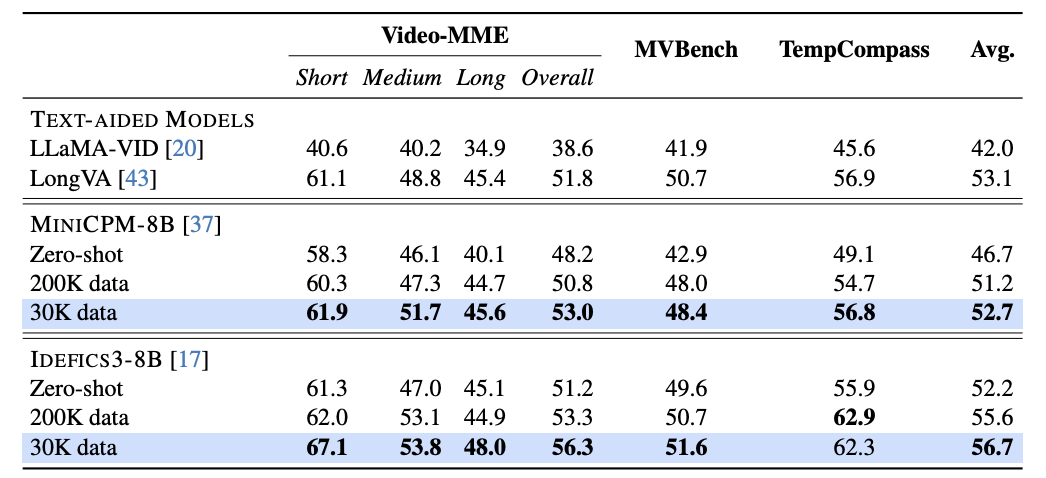
作者提出的方法在 Video-MME 基准测试中,无论在数据量为 30K 还是 200K 的情况下,都展现出了比其他方法更高的准确性。
不同模型/设置在三个视频基准测试上的表现。作者提出的方法仅使用总样本量的15%(与完整的视频集(200K)相比)进行微调,即可实现相似甚至更优的性能。
03
总结
1. T2Vid 的优势:
指令多样性:文本数据包含丰富的指令类型,可以有效提高模型的学习效率。 时间结构模拟:文本段之间存在相关性,可以模拟视频帧的时间结构,帮助模型学习时间理解能力。 经济高效:文本数据更容易收集,且生成图像的成本较低。
2. T2Vid 的局限性:
图像质量:文本到图像生成模型的输出质量可能不如真实视频图像。 时间结构:文本段之间的时间结构可能与真实视频帧之间的时间结构存在差异。 数据平衡:生成的视频样本可能与真实视频样本在数据分布上存在差异。
3. 未来改进方向:
改进图像生成模型:使用更先进的文本到图像生成模型,以提高图像质量。 优化文本分割:研究更有效的文本分割方法,以更好地模拟视频帧的时间结构。 数据增强:使用数据增强技术,例如随机裁剪、旋转和缩放,以提高模型鲁棒性。
文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
