




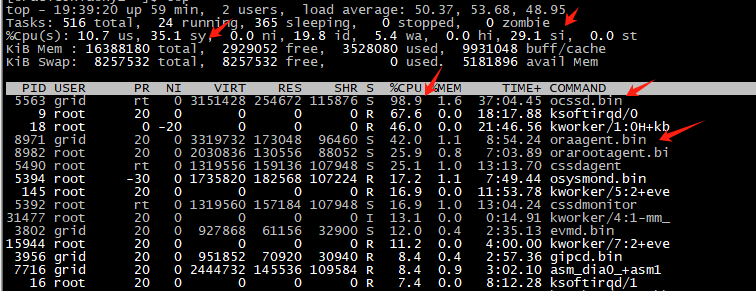
在自己的测试环境升级oracle RAC 19.19到19.25,升级完以后,发现开机很慢,进入操作系统执行任何操作都很慢,很多软中断。ocssd 进程cpu 使用率也很高。
幸好做了快照,闪回到升级前,操作很丝滑:
因为是升级后才有问题,所以首先就怀疑这个补丁是否有问题,没找到相关的文章。随后用排除法,一个个的关闭类似ahf之类的资源,发现只有在所有进程都停下的情况下,主机才正常。
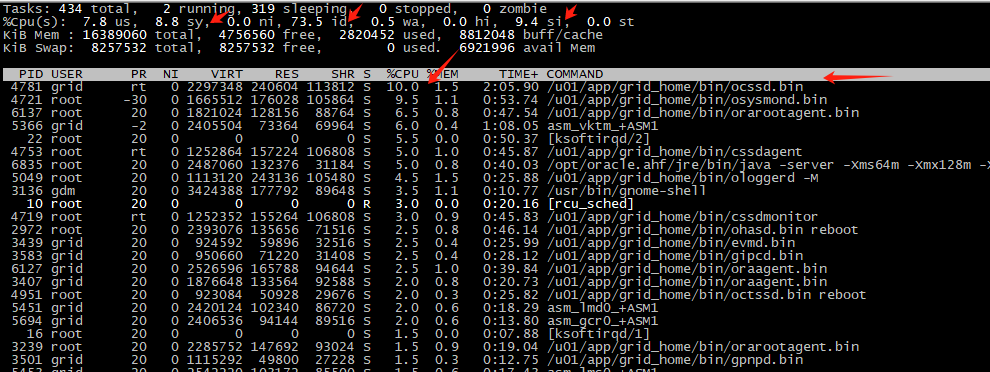
然后想到自己在升级前做了一次根目录的扩容,加了磁盘。闪回,然后升级,升级完以后cpu使用率正常。开机也快了起来。
所以我想第一个坑就是根目录不能随意扩容,没有专业指导的话。也许还需要再验证验证,可能是我电脑本身虚拟机的问题。
做第二次升级的时候,发现VirtualBox 是没有闪回共享盘的。
在第二次升级过程中,还遇到两个问题:
2024-12-29 00:56:37: Executing cmd: /u01/app/grid_home/bin/crsctl stop rollingpatch
2024-12-29 00:56:45: Command output:
> ORA-15138: cluster rolling patch incomplete
> ORA-15139: patch level of ASM instances differ in cluster
> CRS-4698: Error code 2 in retrieving the patch levelCRS-1164: There was an error resetting Oracle ASM rolling patch mode.
> CRS-4000: Command Stop failed, or completed with errors.所以在升级过程中遇到了以下错误,CRS起不来:
CRS-4000: Command Start failed, or completed with errors.
2024/12/29 02:45:23 CLSRSC-117: (Bad argc for has:clsrsc-117)
After fixing the cause of failure Run opatchauto resume
]
OPATCHAUTO-68061: The orchestration engine failed.
OPATCHAUTO-68061: The orchestration engine failed with return code 1
OPATCHAUTO-68061: Check the log for more details.
OPatchAuto failed.2024-12-29 02:28:56.678 : OCRMAS:3485456128: th_hub_verify_master_pubdata: Shutdown CacheLocal. Patch Levels don't match. Local Patch Level [526767740] != Cache Writer Patch Level [760403972]
2024-12-29 02:28:56.678 : OCRMAS:3485456128: th_master: Failed to check master pubdata. Retval:[53]
2024-12-29 02:28:56.678 : OCRAPI:3485456128: procr_ctx_set_invalid: ctx is in state [6].
2024-12-29 02:28:56.678 : OCRAPI:3485456128: procr_ctx_set_invalid: ctx set to invalid根据文档描述,在RAC 中打补丁的时候,当有一个节点打上了补丁,那么集群就会进入 rolling patch 的状态。发生这种错误的时候,是因为集群没有进入rolling patch 的状态,而是进入了normal 的状态。
这就是为什么crs 会在启动的时候报错说,patch level 不一致。
可以通过以下命令查看集群的状态。
<GI_HOME>/bin/crsctl query crs activeversion -f
<GI_HOME>/bin/crsctl query crs softwarepatch
<GI_HOME>/bin/crsctl query crs softwareversion
<GI_HOME>/bin/crsctl query crs releaseversion
如:
[root@xiaoxy2 trace]# crsctl query crs activeversion -f
Oracle Clusterware active version on the cluster is [19.0.0.0.0]. The cluster upgrade state is [NORMAL].解决办法:
1. 在另外一个CRS正常运行的节点执行start rollingpatch 命令
<GI_HOME>/bin/crsctl start rolling patch2. 然后尝试在CRS启动失败的节点重启CRS,正常应该能起起来。
<GI_HOME>/bin/crsctl stop crs -f
<GI_HOME>/bin/crsctl start crs -wait3. 把数据库切回到之前CRS 启动失败的节点,把mgmtdb 要切过来。
<DB_HOME>/bin/srvctl relocate database -db db_unique_name [-node target_node]4. 打补丁。
5. 打完补丁后,检查一下CRS的状态,如果是在NORMAL 状态,那么不用理,如果还是在ROLLING PATCH 的状态,则需要停掉。
<GI_HOME>/bin/clscfg -patch
<GI_HOME>/bin/crsctl stop rolling patch6. 在所有节点上检查软件版本
<GI_HOME>/bin/crsctl query crs activeversion -f
<GI_HOME>/bin/crsctl query crs softwarepatch
<GI_HOME>/bin/crsctl query crs softwareversion
<GI_HOME>/bin/crsctl query crs releaseversion7. 也可以在所有节点用sysasm 登陆asm 查看。
SELECT SYS_CONTEXT('SYS_CLUSTER_PROPERTIES', 'CLUSTER_STATE') FROM DUAL;
SELECT SYS_CONTEXT('SYS_CLUSTER_PROPERTIES', 'CURRENT_PATCHLVL') FROM DUAL;
另外一个问题是:
# crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
尝试手动起:
[grid@xiaoxy2 ~]$ srvctl start cha -n xiaoxy2
PRCR-1013 : Failed to start resource ora.chad
PRCR-1064 : Failed to start resource ora.chad on node xiaoxy2
CRS-2549: Resource 'ora.chad' cannot be placed on 'xiaoxy2' as it is not a valid candidate as per the placement policy
[grid@xiaoxy2 ~]$ srvctl start listener -l LISTENER -n xiaoxy2
PRCR-1013 : Failed to start resource ora.LISTENER.lsnr
PRCR-1064 : Failed to start resource ora.LISTENER.lsnr on node xiaoxy2
CRS-2549: Resource 'ora.LISTENER.lsnr' cannot be placed on 'xiaoxy2' as it is not a valid candidate as per the placement policy原因是因为,在打季度补丁的过程中,rootcrs.pl -prepatch 会把当前节点的RESOURCE_USE_ENABLED 设置为0,以防止ASM以及其他资源启动。
解决办法直接贴:
1. 检查RESOURCE_USE_ENABLED 的值
root@node_1:# <GI_HOME>/bin/crsctl stat server -f
NAME=<node_1>
MEMORY_SIZE=1547613
CPU_COUNT=88
CPU_CLOCK_RATE=2911
CPU_HYPERTHREADING=1
CPU_EQUIVALENCY=1000
DEPLOYMENT=other
CONFIGURED_CSS_ROLE=hub
RESOURCE_USE_ENABLED=1 <<<<<<<<<<<<<<<<<<<<<< Node where ASM is up and running
SERVER_LABEL=
PHYSICAL_HOSTNAME=
CSS_CRITICAL=no
CSS_CRITICAL_TOTAL=0
RESOURCE_TOTAL=0
NAME=<node_2>
MEMORY_SIZE=1547613
CPU_COUNT=88
CPU_CLOCK_RATE=2707
CPU_HYPERTHREADING=1
CPU_EQUIVALENCY=1000
DEPLOYMENT=other
CONFIGURED_CSS_ROLE=hub
RESOURCE_USE_ENABLED=0 <<<<<<<<<<<<<<<<<<<<<< Node where ASM is down.
PHYSICAL_HOSTNAME=
CSS_CRITICAL=no
CSS_CRITICAL_TOTAL=0
RESOURCE_TOTAL=02. 连接到无法启动资源的节点执行以下命令,并重启CRS:
root@node_2:# <GI_HOME>/bin/crsctl set resource use 1
CRS-4416: Server attribute 'RESOURCE_USE_ENABLED' successfully changed. Restart Oracle High Availability Services for new value to take effect.
root@node_2:#3. 检查是否修改成功
# crsctl stat server -f
NAME=<node_2>
MEMORY_SIZE=1547613
CPU_COUNT=88
CPU_CLOCK_RATE=2707
CPU_HYPERTHREADING=1
CPU_EQUIVALENCY=1000
DEPLOYMENT=other
CONFIGURED_CSS_ROLE=hub
RESOURCE_USE_ENABLED=1 <<<<<<<<<<<<<<<<<<<<<<Here.
PHYSICAL_HOSTNAME=
CSS_CRITICAL=no
CSS_CRITICAL_TOTAL=0
RESOURCE_TOTAL=0记录一下,以备忘。
