




大家好,我是 JiekeXu,江湖人称“强哥”,青学会 MOP 技术社区主席,荣获 Oracle ACE Pro 称号,墨天轮 MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及 PCA、PCTA、OBCA、OGCA、金仓KCA、KCP 等众多国产数据库认证证书,今天和大家一起来看看 遇到一个比较奇葩的 Oracle 小故障,欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!

前 言
昨天周末,闲来没事,也没有午休,下午刚好没有外出坐在电脑前回答微信群友的问题,突然好朋友在另一个群里发了一个 Oracle 启动失败的截图,说是主机断电重启了,Oracle 数据库启动不了,一看数据库版本是 19.3,也不是啥老掉牙的库,觉得问题不大。
故障现象
大概 16:30 左右,朋友便在群里发了个截图,我大概看了一眼,“ORA-01081: "cannot start already-running ORACLE - shut it down first”,问了下是不是断电没停干净,是不是还有残余进程,然后让清理一下信号量。
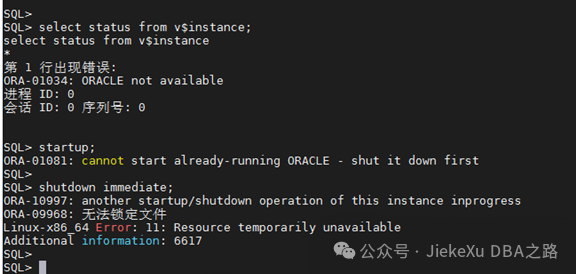
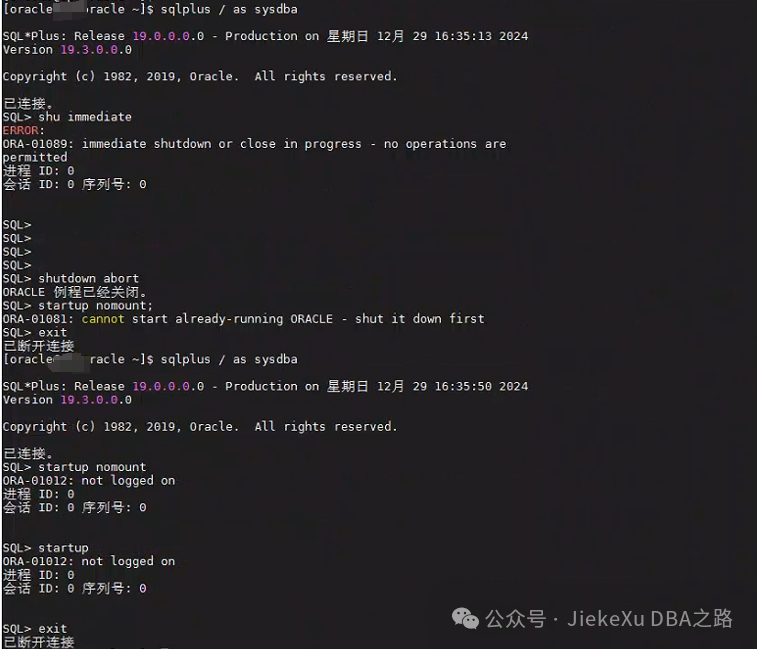
接着又发来一张图,问是不是和开启自启动有关系,我说有可能,还有 LOCAL=YES 的数据库进程存在,用总监刚写的清理信号量的命令:ipcrm -a 清理掉所有共享内存段和信号量。

ipcrm 是一个用于删除 System V IPC(进程间通信)对象的命令行工具。System V IPC 包括消息队列、信号量集和共享内存段。ipcrm 命令允许你删除这些对象,以释放系统资源。
[root@JiekeXu-Lix8 ~]# ipcrm --help
Usage: ipcrm [options] ipcrm shm|msg|sem <id>...
Remove certain IPC resources.
Options: -m, --shmem-id <id> remove shared memory segment by id -M, --shmem-key <key> remove shared memory segment by key -q, --queue-id <id> remove message queue by id -Q, --queue-key <key> remove message queue by key -s, --semaphore-id <id> remove semaphore by id -S, --semaphore-key <key> remove semaphore by key -a, --all[=shm|msg|sem] remove all (in the specified category) -v, --verbose explain what is being done
-h, --help display this help -V, --version display version
For more details see ipcrm(1).
[root@JiekeXu-Lix8 ~]# ipcs --查看当前 IPC 对象
--列出所有当前存在的消息队列、信号量集和共享内存段,并显示它们的标识符和其他相关信息
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 0 zabbix 600 632 6 dest
0x00000000 32769 zabbix 600 657056 6 dest
0xa133b8b4 65538 grid 600 45056 40
0x00000000 98307 oracle 600 14680064 442
0x00000000 131076 oracle 600 17045651456 442
0x00000000 163845 oracle 600 121634816 442
0x50dde820 196614 oracle 600 24576 442
------ Semaphore Arrays --------
key semid owner perms nsems
0x6904870c 163840 grid 600 250
0x6904870d 196609 grid 600 250
0x6904870e 229378 grid 600 250
0x6904870f 262147 grid 600 250
0x69048710 294916 grid 600 250
0x0fc16ed0 425989 oracle 600 250
0x0fc16ed1 458758 oracle 600 250
0x0fc16ed2 491527 oracle 600 250
0x0fc16ed3 524296 oracle 600 250
0x0fc16ed4 557065 oracle 600 250
0x0fc16ed5 589834 oracle 600 250
0x0fc16ed6 622603 oracle 600 250

如上图清理完之后,查看 Oracle 进程还有,当他去 kill 的时候发现又不存在了。后面好久不回复了我以为问题解决了就没有继续问了,也就在忙群友的问题了。大概快六点的时候,我就又问了一下说有大神在处理了,并发过来一张 alert 日志报错截图,从 alert 日志中看到此主机配置了大页内存,但是 memlock 配置的低于 30G,不够使用,那么就扩一下就 OK 呀,或者根据 SGA 大小降低大页内存配置也还是 OK 的。示例如下:
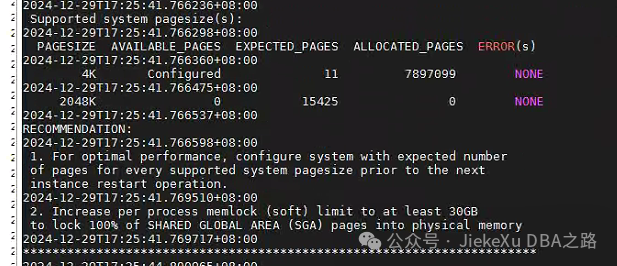
--设置内存大页vim /etc/sysctl.conf文件,增加如下行:
vm.nr_hugepages = 11266 --需要计算精确
--设置 memlock
vim /etc/security/limits.conf
oracle soft memlock 50000000
oracle hard memlock 50000000
这里设定 oracle 用户可以锁定内存的大小 ,以 KB 为单位,这个值一般设置为内存的 90% 左右,或者 memlock 的精确值一般为 vm.nr_hugepages*Hugepagesize,总之,比内存大页要大一些,当然为了省事,也会直接设置为 unlimited,不过记得设置 “vm.min_free_kbytes” 不然内存全被数据库占用完了,容易 OOM。内存大页这个我以前总结过了,也比较详细,这里不在介绍了,感兴趣的可以戳此看看《Linux 透明大页 THP 和标准大页 HP》。
然后大概晚上六点半左右,可以通过远程登录上去看看,所以我也就先上去看了下,这个时候已经把大页内存给禁用掉了,也注释了 rc.local 里的开机自启动,开机自启动我以前也用过并分享了 11g 和 19c 的不同之处,感兴趣的伙伴可以去看看《Oracle 单实例开机自启动》。他也将 memlock 设置成了 unlimited 并重启 OS 了。在这期间朋友他应该是发觉 unlimited 设置没有生效,有做了修改和尝试。
[root@JiekeXu limits.d]# cd /etc/rc.d/
[root@JiekeXu rc.d]# ll rc.local
-rwxr--r-- 1 root root 685 Oct 24 2023 rc.local
[root@JiekeXu rc.d]# more rc.local
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.
touch /var/lock/subsys/local
#su - oracle -lc /u01/app/oracle/product/19c/db_1/bin/dbstart
通过多次尝试,发现问题还是一样,数据库还是无法使用,大神给的意见是操作系统内存或者数据库库文件由于断电出现异常损坏,毕竟这是一台物理机出现这种情况的概率也是有的,而且内存损坏,操作系统故障,Oracle 数据库软件出问题都是很常见的,比较大神在这方面遇到的问题肯定是很多的,固定思维模式下也会想这方面的问题,建议异机迁移,毕竟数据量就几百G也不太大,但是这个就比较麻烦了,还得协调人员近机房重装系统,重新部署软件做恢复什么的,太折腾,所以我们就还想着折腾一下,看看有没有其他的突破。
解决问题
这个时候我也进行了简单的排查,CPU、/proc/meminfo、内存以及内核参数设置均没有问题,rc.local 文件中开机自启动也已经注释了,但是 alert 日志还在不停地刷着 Oracle 启动 关闭的过程,而且是一直刷,top 观察进程也是一会儿出现 Oracle 的相关进程,一会儿没有了,这就让我好奇了,难道有什么脚本一直在判断数据库状态?当出现宕机后就立马拉起来吗?当拉起后(出现内存问题)不能分配共享内存又宕掉了,这样一直循环,所以 alert 日志不停的刷新?所以就返回去查看开机自启动脚本是否真的有问题,发现确实是注释掉了,rc.local 也是调用 $ORACLE_HOME/bin/dbstart 脚本实现的自启动,这个也没有问题。
这个时候大概是 19:10 分左右了,他们自己人说是有设置了好几个开机自启动脚本,但都没有验证过是否正确。。。。。。我们也想到了 system 管理的开机自启动,然后去 mv /etc/systemd/system/oracle*.service 脚本,然后重启了主机。神奇的事情就发生了,sqlplus 可以正常登录查询状态了,隔了一会儿再查了一次也没有问题,业务前台验证也正常能查到数据了。那么说明还有一个开机自启动脚本生效了,当主机重启后数据库也被正常拉起了,这样就有三个开机自启动脚本了,可真是保障真多啊。。。。。。
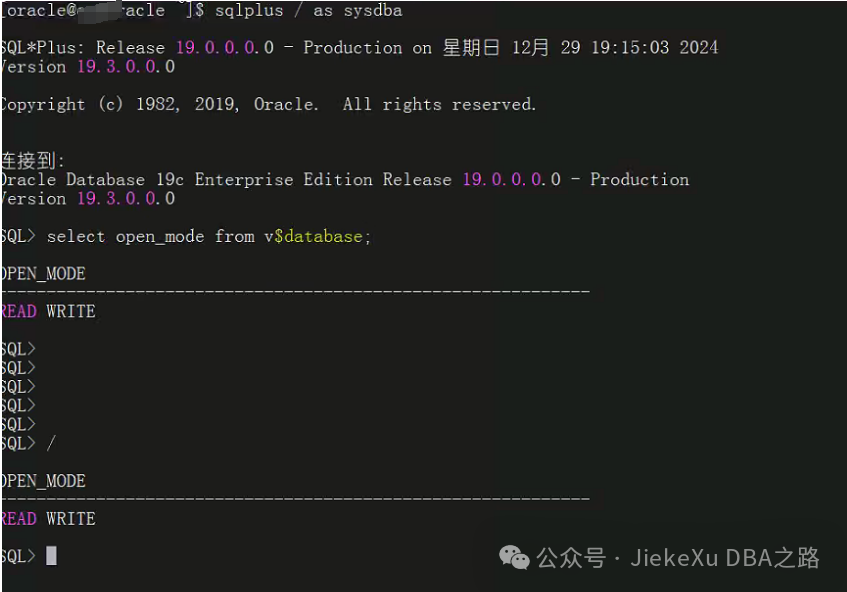
这样算是知道问题所在了,多个开机自启动脚本一直在运行,当主机断电重启后,几乎同时对数据库发起了开库命令,导致数据库内存无法分配。后面多次主机重启以及不断 alert 日志刷新很可能也是配置了类似 mysqld_safe 守护进程可以拉起 mysqld 进程。这里估计运维人员也是配置了类似于这样的 Oracle 服务,才会一直启动关闭,但由于时间关系,这里没有再去排查了,大家也都辛苦了一下午,就到这里结束了。
[root@JiekeXu ~]# ps -ef | grep mysqld
root 6488 3324 0 Sep03 pts/0 00:00:00 /bin/sh /app/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf --user=mysql
mysql 7327 6488 0 Sep03 pts/0 00:00:13 /app/mysql/bin/mysqld --defaults-file=/etc/my.cnf --basedir=/app/mysql --datadir=/mysqldata/data --plugin-dir=/app/mysql/lib/plugin --user=mysql --log-error=/mysqldata/log/mysql-error.log --open-files-limit=10240 --pid-file=/mysqldata/tmp/mysql.pid --socket=/tmp/mysql.sock
最后,通过直接执行 systemctl status oracle 是发现调用了 /etc/rc.d/init.d/oracle 来启动的数据库,通过其日志也证实了我的猜想,也就是这样了。
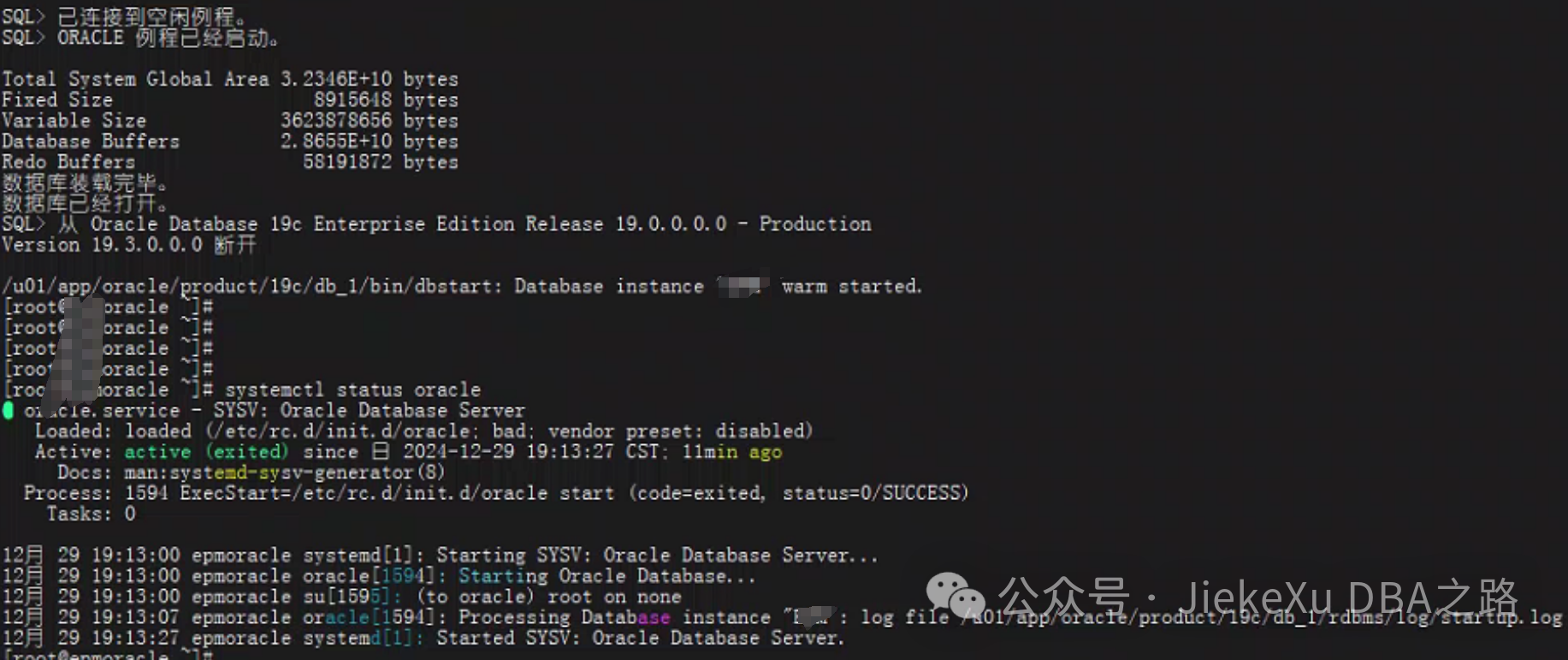
这里,简单记录一下这个排查过程,方便后续回忆或遇到类似的问题无从下手,好记性不如烂笔头,不算完整,但也简单记录下。
总 结
其实问题本身不是很复杂,主要是过于奇葩,没有人会想到会配置多个开机自启动脚本,也是第三方系统,都不熟悉,也没有人说起自启动这个事;另外还有一个就是思维误区,都在猜测可能断电导致主机、内存、Oracle 软件出现未知问题引发的,没人往开机自启动这方面考虑;最后,也是需要头脑风暴,朋友疑惑为啥分配不了内存,而我的疑惑是为啥一直不停的刷 alert 日志,开启关闭实例,当大家交流想法思路后,大神原有的思路才会打开,才能碰撞出火花来。可见,知识分享、思路分享交流多么重要,多交流分享才能擦出火花。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————
