




在异构存储库之间迁移数据(即源数据库和目标数据库来自不同供应商的不同数据库管理系统)会遇到一些挑战。在某些情况下,可以同时连接两个数据库。但有时根本无法实现。面对这样的困境,数据库从业者别无选择,只能从转储文件填充表。在这个过程中,Navicat 可以提供很大的帮助。导入向导允许你从各种源导入数据到表/集合,包括 CSV、TXT、XML、DBF 等。此外,你还可以将设置保存为配置文件,以便将来使用或设置自动化任务。在今天的博客,我们将使用免费的 Navicat Premium Lite 17 ,使用 Navicat 导入向导从 PostgreSQL "dvdrental" database 迁移数据到 MySQL 8 实例。
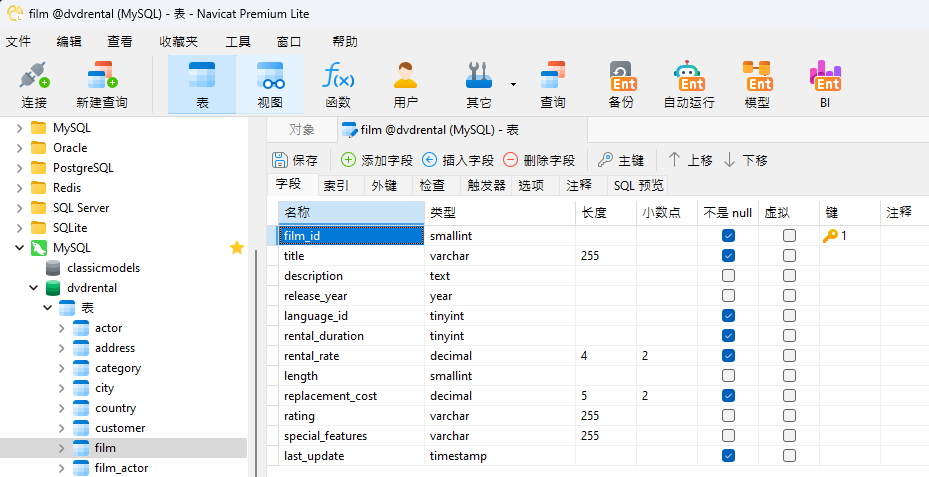
在本教程中,我们将使用 PostgreSQL DAT 文件填充 MySQL 8 中的 film 表。下面是表设计器中的表定义:
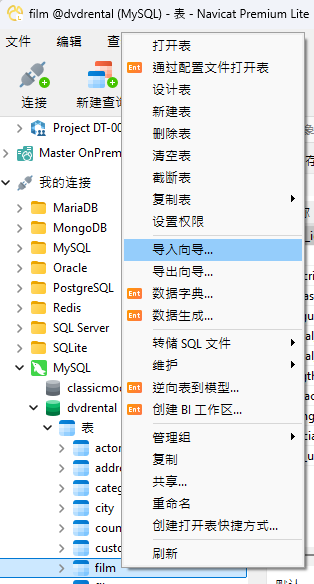
要启动导入向导,请右键单击 Navicat 导航窗格中的目标表(或在 macOS 中按住 Ctrl-Click),然后从弹出的菜单中选择“导入向导...”:
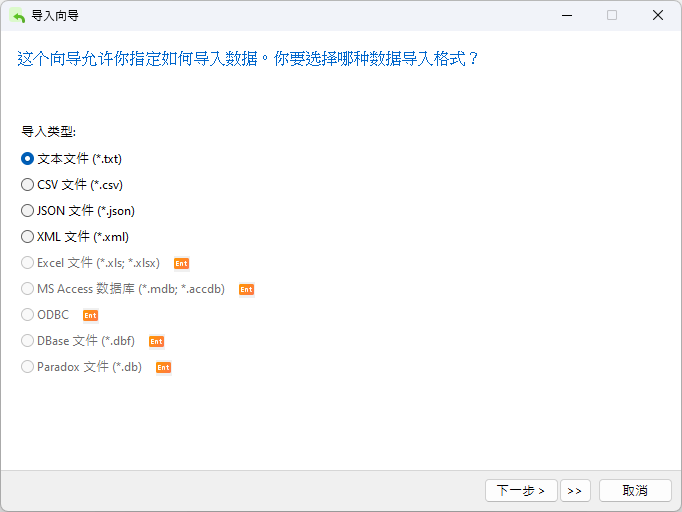
向导的第一个屏幕是我们选择源文件的地方。请注意,精简版只支持基于文本的文件,如 TXT、CSV、XML 和 JSON。虽然我们有一个 .dat 文件,但我们可以选择文本文件选项,其中包括 .txt、.csv 和 .dat 格式:
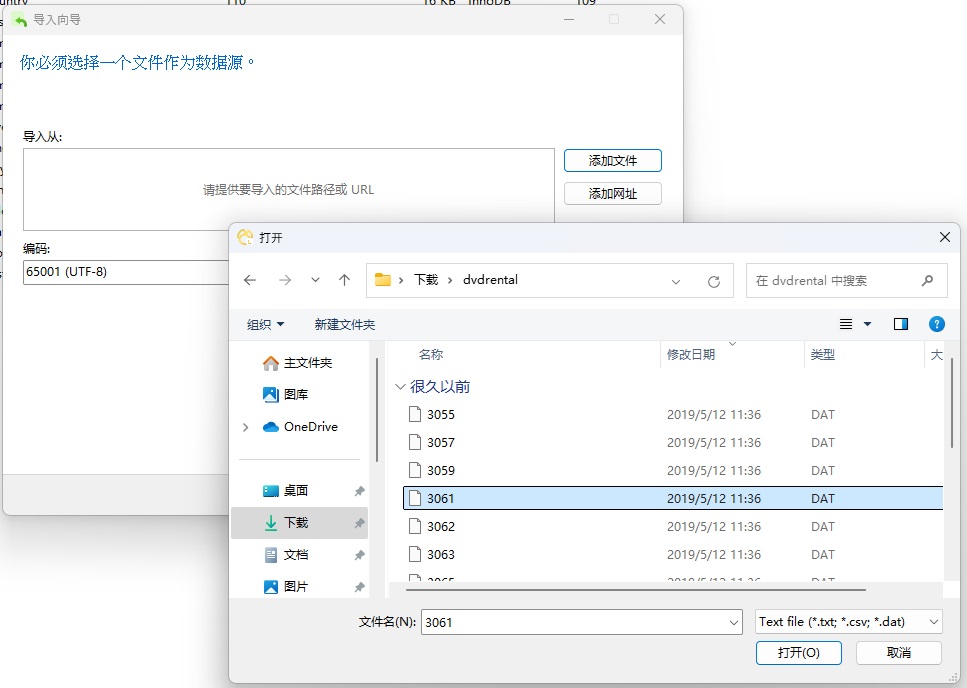
在下一个屏幕中,我们将选择 DAT 文件。每个表都有一个文件。电影表的文件名为“3061.dat”:
接下来是设置分隔符。记录使用换行(LF)字符分隔,而列则使用制表符(TAB)分隔。文本值周围没有引号,因此一定要移除“文本识别符号”文本框中的双引号(")字符:
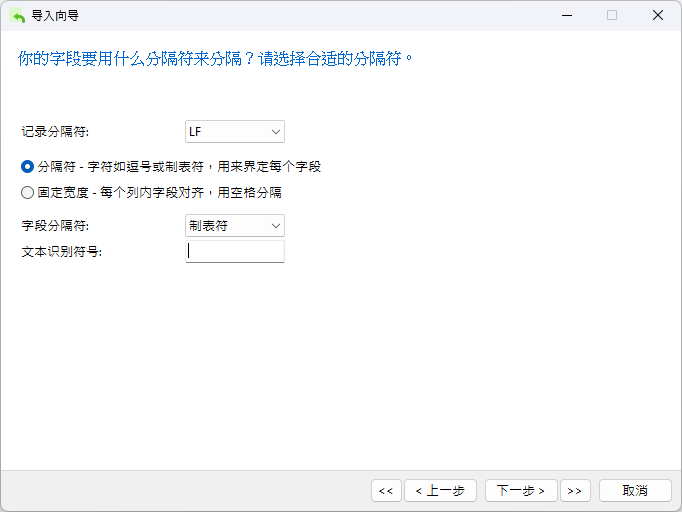
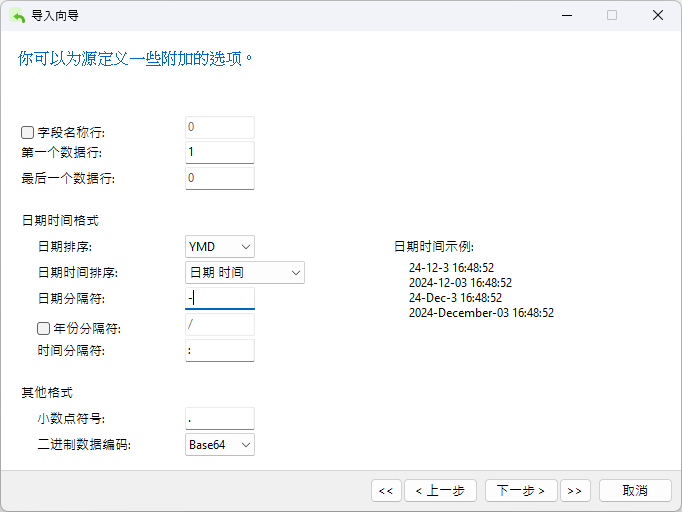
在下一个屏幕中,你会看到一些额外的选项。在这里,我们必须取消选中“字段名称行”框,因为 DAT 文件不包含字段名。我们还需要将“日期顺序”改为“年/月/日”("YMD"),并用破折号 (-) 替换正斜线 (/) 分隔符,因为我们要导入的日期是 YYYY-MM-DD hh:mm:ss.ms,即2013-05-26 14:50:58.951 的格式:
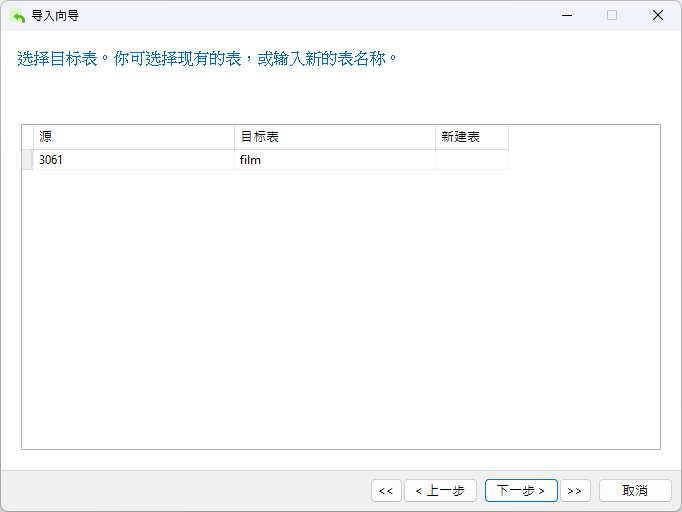
我们可以选择现有表格或创建新表格。由于我们在启动导入向导时选择了目标表,因此它应该显示在这里:
下一步是将源字段映射到目标表中的字段。在这里,我们不能假定它们会一致。快速查看 DAT 文件中的一个条目就会发现,last_update 和 special_features 列是相反的:
5 African Egg A Fast-Paced Documentary of a Pastry Chef And a Dentist who must Pursue a Forensic Psychologist in The Gulf of Mexico 2006 1 6 2.99 130 22.99 G 2013-05-26 14:50:58.951 {"Deleted Scenes"} 'african':1 'chef':11 'dentist':14 'documentari':7 'egg':2 'fast':5 'fast-pac':4 'forens':19 'gulf':23 'mexico':25 'must':16 'pace':6 'pastri':10 'psychologist':20 'pursu':17
我们可以右键单击(或在 macOS 中按住 Ctrl-Click)对话框中的任意位置,然后从上下文菜单中选择“直接匹配全部”,将字段快速映射到目标表中的字段。不过,一旦这样做了,我们就必须从目标字段下拉菜单中手动选择 last_update 和 special_features 列来更改它们的顺序:
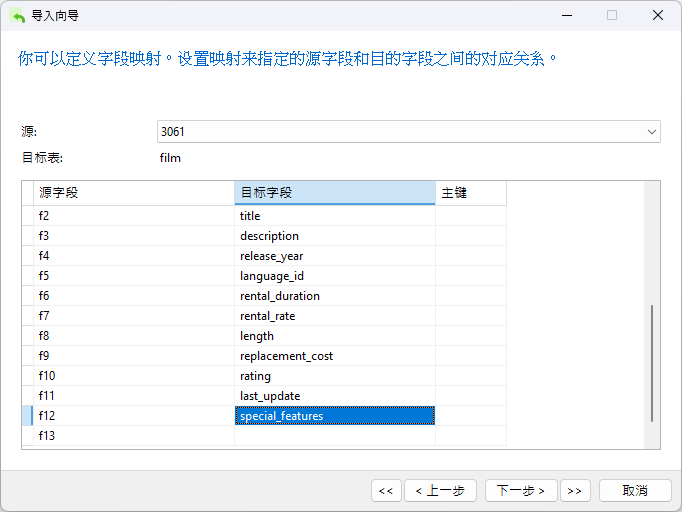
请注意,字段 13 (f13) 可以安全忽略。
对于导入模式,我们可以“追加”或“复制”记录,因为表应该是空的:
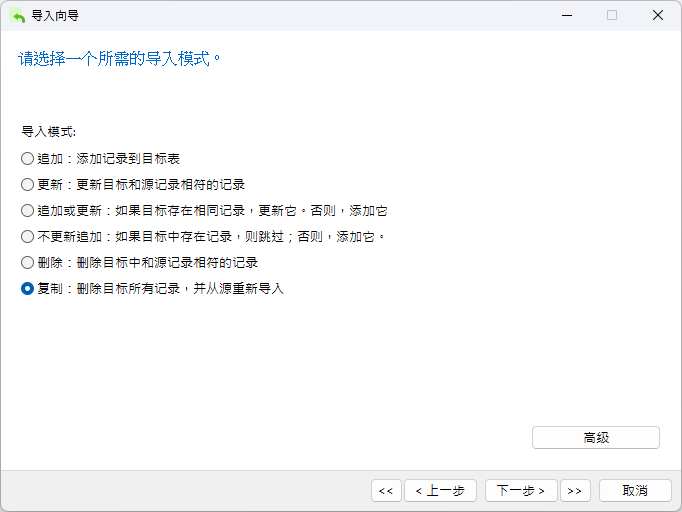
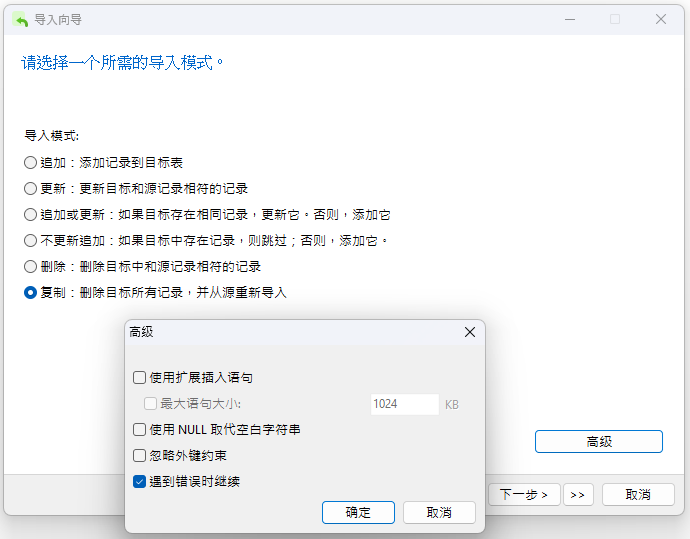
从一种数据库类型迁移到另一种数据库类型时,很有可能会遇到数据转换错误。因此,取消选择 “高级”中的“使用扩展插入语句”复选框是个不错的做法。这样做会使 Navicat 为每条记录发出单独的 INSERT 语句,而不是使用以下语法合并多条记录:
INSERT INTO `film` VALUES (1, 'African Egg', 'A Fast-Paced...'), (2, 'Rumble Royale', 'A historical drama...'), (3, 'Catherine the Great', 'A new take on...'), etc...复制
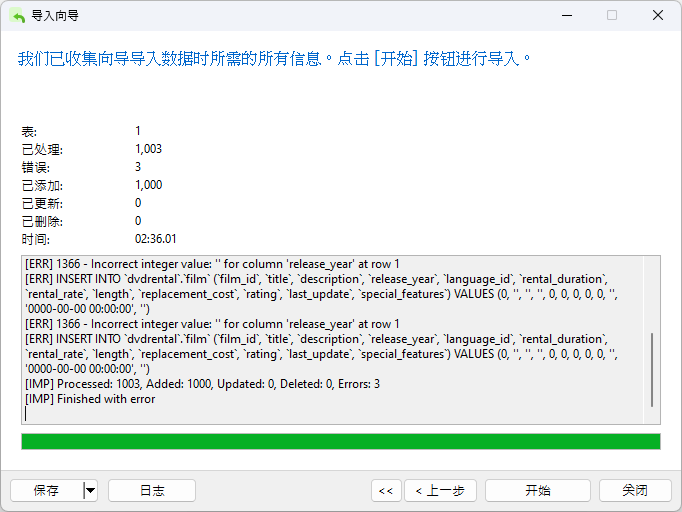
现在,点击“开始”按钮启动导入程序。
不出所料,虽然出现了几个错误(确切地说是 3 个),但 1003 行中的 1000 行已经添加到了目标表中!
结语
Navicat 的导入向导可以大大减少在异构资源库之间迁移数据所花费的时间。它支持多种输入,包括 CSV、TXT、XML、DBF、ODBC 数据源等。
有兴趣试试 Navicat Premium Lite 17 吗?你可以在 这里 免费下载。它适用于 Windows、macOS 和 Linux 操作系统。
