






数据准备

--Create DatabaseCREATE DATABASE test_access;--Create TableUSE test_access;CREATE TABLE access_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3)) Engine=InnoDB CHARSET=utf8;--Create ProcedureDELIMITER ;;CREATE PROCEDURE accessdata()BEGIN DECLARE i INT; SET i=0; WHILE i<10000 DO INSERT INTO access_table(key1,key2,key3,key_part1,key_part2,key_part3,common_field) VALUES(SUBSTRING(MD5(RAND()),1,2),i+1,SUBSTRING(MD5(RAND()),1,3),SUBSTRING(MD5(RAND()),1,4),SUBSTRING(MD5(RAND()),1,5),SUBSTRING(MD5(RAND()),1,6),SUBSTRING(MD5(RAND()),1,7)); SET i=i+1; END WHILE;END;;DELIMITER ;--Call ProcedureCALL accessdata();复制
access_table表一共创建了1个聚簇(主键)索引和4个辅助索引:
为id列创建的聚簇索引;
为key1列创建的二级索引;
为key2列创建的唯一二级索引;
为key3列创建的二级索引;
为key_part1、key_part2、key_part3列创建的复合(联合)二级索引。
单表的访问方式
访问方法介绍
大家上小学时都有过查字典的经历,当我们词汇量还没有达到一定程度时,如果我们想知道某个没见过字的释义,就需要查字典。一般情况下,我们都会先去字典目录找对应的拼音或者汉字部首、定位所在字的页码,然后直接翻到对应页码查看对应释义即可。还有一种情况,闲的厉害,上百页的字典,可以从首页翻到尾页一页一页去查找,最终也能找到。两种方式,都可以得到我们想要的结果,但是花费的时间和精力却是天差地别。MySQL也一样,为了加快查询数据的速度,提出了B+树索引的概念。但是有的时候,我们要查询所有的数据,那么就不得不一行一行,一页一页的去遍历所有的数据页去获取结果。
对于单个表的查询,MySQL查询的执行方式大致分为下边两种:
使用全表扫描进行查询
这种方式就是上面说的,一行一行记录,一页一页记录去遍历,把符合搜索条件的记录加入到结果集就完了。这种方式虽然可以满足我们的需求,但效率无疑是最低的。还是查字典的例子,我们从头到尾翻一遍字典、再定位到我们要找的字,这得翻到猴年马月啊。
使用索引进行查询
直接使用全表扫描的方式执行查询要遍历好多记录,代价可能非常大。就像我们通过字典目录查找汉字一样,如果MySQL查询语句中的搜索条件可以使用到某个索引,那直接使用索引来执行查询可能会加快查询执行的时间。使用索引来执行查询的方式可以细分为许多种类:
通过主键或唯一二级索引的等值查询
通过普通二级索引的等值查询
通过索引列的范围查询
通过直接扫描整个索引
const
SELECT * FROM access_table WHERE id=9999;复制

还记得MySQL之B+树索引中聚簇索引B+树的结构吗,叶子(Leaf)节点存储的是完整的记录,B+树叶子(Leaf)节点中的记录是按照主键id列的值从小到大排序的。B+树本来就是一个矮胖子,加上唯一、有序、非空的属性,根据主键值定位一条记录的速度非常快。同样,根据唯一二级索引列来定位一条记录的速度也是非常快的:
SELECT * FROM access_table WHERE key2=8888;复制
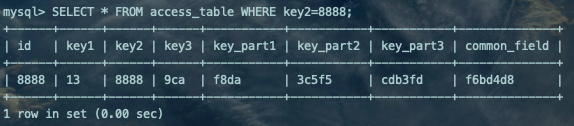
根据之前文章的知识铺垫,这个查询的执行分两步,第一步先从idx_key2对应的B+树索引中根据key2列与常数的等值比较条件定位到一条二级索引记录,然后再根据该记录的id值到聚簇索引中获取到完整的用户记录。
MySQL通过主键或者唯一二级索引列与常数的等值比较来定位一条记录是非常非常快的,所以把这种通过主键或者唯一二级索引列来定位一条记录的访问方法定义为:const,意思是常数级别,代价可以忽略不计。不过这种const访问方法只能在主键列或者唯一二级索引列和一个常数进行等值比较时才有效,如果主键或者唯一二级索引是由多个列构成的话,索引中的每一个列都需要与常数进行等值比较,这个const访问方法才有效(这是因为只有该索引中全部列都采用等值比较才可以定位唯一的一条记录)。
SELECT * FROM access_table WHERE key2 IS NULL;复制
ref
普通的二级索引列与常数进行等值比较:
SELECT * FROM access_table WHERE key1='ef';复制

二级索引列值为NULL的情况:不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含NULL值的数量并不限制,所以我们采用key IS NULL这种形式的搜索条件最多只能使用ref的访问方法,而不是const的访问方法。 包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数的等值比较就可能采用ref的访问方法。
SELECT * FROM access_table WHERE key_part1 = '76bf';SELECT * FROM access_table WHERE key_part1 = '76bf' AND key_part2 = '95f8a';SELECT * FROM access_table WHERE key_part1 = '76bf' AND key_part2 = '95f8a' AND key_part3 = '817fd8';复制
SELECT * FROM access_table WHERE key_part1 = '76bf' AND key_part2 > '95f8a';复制
ref_or_null
找出某个二级索引列的值等于某个常数的记录,还想把该列的值为NULL的记录也找出来:
SELECT * FROM access_table WHERE key1 = 'ef' OR key1 IS NULL;复制
range
之前介绍的几种访问方法都是在对索引列与某一个常数进行等值比较的时候才可能使用到(ref_or_null比较奇特,还计算了值为NULL的情况),有时候我们面对的搜索条件更复杂:
SELECT * FROM access_table WHERE key2 IN (5555, 6666) OR (key2 >= 1234 AND key2 <= 1240);复制
可以使用全表扫描的方式来执行这个查询,不过也可以使用二级索引 + 回表的方式执行,如果采用二级索引 + 回表的方式来执行的话,那么此时的搜索条件就不只是要求索引列与常数的等值匹配了,而是索引列需要匹配某个或某些范围的值,MySQL把这种利用索引进行范围匹配的访问方法称之为:range。
index
SELECT key_part1, key_part2, key_part3 FROM access_table WHERE key_part1 = 'e837';复制
它的查询列表只有3个列: key_part1
,key_part2
,key_part3
,而索引idx_key_part
又包含这三个列。搜索条件中只有key_part2列。这个列也包含在索引idx_key_part中。
all
SELECT * FROM access_table;复制
就像这个SQL语句,查询所有数据。这种查询执行方式就是全表扫描,对于InnoDB表来说也就是直接扫描聚簇索引,把这种使用全表扫描执行查询的方式称之为:all。
注意事项
二级索引+回表
SELECT * FROM access_table WHERE key1 = '0e' AND key2 > 9988;复制
idx_key1索引进行查询时只会用到与
key1列有关的搜索条件,其余条件,比如
key2 > 9988这个条件在步骤1中是用不到的,只有在步骤2完成回表操作后才能继续针对完整的用户记录中继续过滤。(注意,这里我们所说的是一般情况,一般情况下执行一个查询只会用到单个二级索引)
range访问方法使用的范围区间
对于B+树索引来说,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以写成<>)或者LIKE操作符连接起来,就可以产生一个所谓的区间。
SELECT * FROM access_table WHERE key2 IN (1222, 1333);SELECT * FROM access_table WHERE key2 = 1222 OR key2 = 1333;复制
一个查询的WHERE子句可能有很多个小的搜索条件,这些搜索条件需要使用AND或者OR操作符连接起来:A AND B,A和B都为TRUE,整个表达式才为TRUE;A OR B,A或B任意一个为TRUE,整个表达式就为TRUE。
当我们想使用range访问方法来执行一个查询语句时,重点就是找出该查询可用的索引以及这些索引对应的范围区间。下边分两种情况看一下怎么从由AND或OR组成的复杂搜索条件中提取出正确的范围区间。
01
所有搜索条件都可以使用某个索引的情况
SELECT * FROM access_table WHERE key2 > 2222 AND key2 > 3333;复制
SELECT * FROM access_table WHERE key2 > 2222 OR key2 > 3333;复制
02
部分搜索条件无法使用索引的情况
SELECT * FROM access_table WHERE key2 > 2222 AND common_field = '039cb00';复制
这个查询语句中能利用的索引只有idx_key2一个,而idx_key2这个二级索引的记录中又不包含common_field这个字段,所以在使用二级索引idx_key2定位记录的阶段用不到common_field = '039cb00'这个条件,这个条件是在回表获取了完整的用户记录后才使用的,而范围区间是为了到索引中取记录中提出的概念,所以在确定范围区间的时候不需要考虑common_field = '039cb00'这个条件,我们在为某个索引确定范围区间的时候只需要把用不到相关索引的搜索条件替换为TRUE(把用不到索引的搜索条件替换为TRUE,是因为我们不打算使用这些条件进行在该索引上进行过滤,所以不管索引的记录满不满足这些条件,我们都把它们选取出来,待到之后回表的时候再使用它们过滤)。
SELECT * FROM access_table WHERE key2 > 2222 AND TRUE;简化:SELECT * FROM access_table WHERE key2 > 2222;复制
由此可得,使用idx_key2的范围区间就是:(2222, +∞)。
同理,可得使用OR的情况:
SELECT * FROM access_table WHERE key2 > 2222 OR common_field = '039cb00';简化:SELECT * FROM single_table WHERE key2 > 2222 OR TRUE;简化:SELECT * FROM single_table WHERE TRUE;复制
如果强制使用idx_key2执行查询的话,对应的范围区间就是(-∞, +∞),也就是需要将全部二级索引的记录进行回表,这个代价肯定比直接全表扫描都大了。也就是说一个使用到索引的搜索条件和没有使用该索引的搜索条件使用OR连接起来后是无法使用该索引的。
03
复杂搜索条件下找出范围匹配的区间
SELECT * FROM access_table WHERE (key1 > 'ed' AND key2 = 66 ) OR (key1 < 'zc' AND key1 > 'zz') OR (key1 LIKE '%33' AND key1 > 'fa' AND (key2 < 7777 OR common_field = '97d435e')) ;复制
看到这种复杂条件的SQL,不要惊慌,一起来慢慢分析一下。
首先查看WHERE子句中的搜索条件都涉及到了哪些列,哪些列可能使用到索引。
这个查询的搜索条件涉及到了key1、key2、common_field这3个列,然后key1列有普通的二级索引idx_key1,key2列有唯一二级索引idx_key2。
对于那些可能用到的索引,分析它们的范围区间。
假设我们使用idx_key1执行查询
(key1 > 'ed' AND TRUE ) OR(key1 < 'zc' AND key1 > 'zz') OR(TRUE AND key1 > 'fa' AND (TRUE OR TRUE))继续简化:(key1 > 'ed') OR(key1 < 'zc' AND key1 > 'zz') OR(key1 > 'fa')复制
2、替换掉永远为TRUE或FALSE的条件。
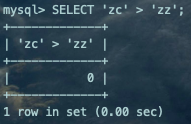
(key1 > 'ed') OR (key1 > 'fa')复制
3、继续化简区间。
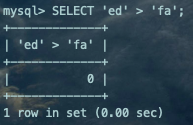
key1 > 'ed'和key1 > 'fa'之间使用OR操作符连接起来的,意味着要取并集,所以最终的结果化简的到的区间就是:key1 > 'ed'。也就是说:上述复杂搜索条件的查询语句如果使用 idx_key1索引执行查询的话,需要把满足key1 > 'ed'的二级索引记录都取出来,然后拿着这些记录的id再进行回表,得到完整的用户记录之后再使用其他的搜索条件进行过滤。
假设我们使用idx_key2执行查询
1、需要把那些用不到该索引的搜索条件暂时使用TRUE条件替换掉,其中有关key1和common_field的搜索条件都需要被替换掉:
(TRUE AND key2 = 66 ) OR(TRUE AND TRUE) OR(TRUE AND TRUE AND (key2 < 7777 OR TRUE))复制
2、key2 < 7777 OR TRUE的结果是TRUE,继续简化:
key2 = 66 OR TRUE继续简化:TRUE复制
这个结果意味着如果我们要使用idx_key2索引执行查询语句的话,需要扫描idx_key2二级索引的所有记录,然后再回表,和使用idx_key1二级索引相比,得不偿失,两种方法对比结果下不会使用idx_key2索引。
索引合并
SHOW VARIABLES LIKE 'optimizer_switch'\G复制

index_merge=on(索引合并)index_merge_union=on(Union索引合并—非聚簇索引获取到的id值取并集)index_merge_sort_union=on(Sort-Union索引合并—非聚簇索引获取到的id值先排序-取并集)index_merge_intersection=on(Intersection索引合并—非聚簇索引获取到的id值取交集)engine_condition_pushdown=on(引擎条件下推—只用于NDB引擎,开启后时按照WHERE条件过滤后的数据发送到SQL节点来处理,不开启所有数据节点的数据都发送到SQL节点来处理。)index_condition_pushdown=on(索引条件下推—ICP)mrr=on(Multi-Range Read-MRR—这个优化的主要目的是尽量使用顺序读盘)mrr_cost_based=on(cost-based choice—是否计算基于使用MRR的成本计算/判断消耗)block_nested_loop=on(基于块的嵌套循环连接—BNL)batched_key_access=off(BKA—针对Index Nested-Loop Join(NLJ) 算法的优化)materialization=on(物化)subquery_materialization_cost_based=on(是否开启子查询物化的成本计算)semijoin=on(半连接)loosescan=on(半连接—松散扫描)firstmatch=on(半连接—首次匹配)duplicateweedout=on(半连接—重复值消除)use_index_extensions=on(使用索引扩展)condition_fanout_filter=on(条件(扇出)过滤)derived_merge=on(视图/派生表合并,需要配合好Auto_key)复制
这些优化特性会在后面的文章中慢慢铺开详解,回到今天的内容,我们前边说过MySQL在一般情况下执行一个查询时最多只会用到单个二级索引,但在某些特殊情况下也可能在一个查询中使用到多个二级索引,MySQL把这种使用到多个索引来完成一次查询的执行方法称之为:index merge,就是位置排在最前面的优化特性,具体的索引合并算法有下边三种。
Intersection合并
Intersection直译就是交集。这里是说某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取交集。
SELECT * FROM access_table WHERE key1='4a' AND key3='c84';复制
这个查询使用Intersection合并的方式执行的话,那这个过程就是这样的:
1、从idx_key1二级索引对应的B+树中取出key1 = '4a'的相关记录。
2、从idx_key3二级索引对应的B+树中取出key3 = 'c84'的相关记录。
3、二级索引的记录都是由索引列 + 主键构成的,所以我们可以计算出这两个结果集中id值的交集。
既然是一个优化特性,那么价值在哪儿呢?我们来分析一下。
只读取一个二级索引的成本:按照某个搜索条件读取一个二级索引;根据从该二级索引得到的主键值进行回表操作,然后再过滤其他的搜索条件;循环往复,回多次表。 读取多个二级索引之后取交集成本:按照不同的搜索条件分别读取不同的二级索引;将从多个二级索引得到的主键值取交集,然后进行回表操作;只回一次表。
MySQL可能会使用到Intersection索引合并优化特性的触发条件:
情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
情况二:主键列可以是范围匹配。
对于InnoDB的二级索引来说,记录先是按照索引列进行排序,如果该二级索引是一个联合索引,那么会按照联合索引中的各个列依次排序。而二级索引的用户记录是由索引列 + 主键构成的,二级索引列的值相同的记录可能会有好多条,这些索引列的值相同的记录又是按照主键的值进行排序的。在二级索引列都是等值匹配的情况下才可能使用Intersection索引合并,是因为只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的。
从各个二级索引中查询的到的结果集本身就是已经按照主键排好序的,那么求交集的过程就很简单。求交集的过程就是这样:逐个取出这两个结果集中最小的主键值,如果两个值相等,则加入最后的交集结果中,否则丢弃当前较小的主键值,再取该丢弃的主键值所在结果集的后一个主键值来比较,直到某个结果集中的主键值用完。这个过程其实很快,时间复杂度是O(n),但是如果从各个二级索引中查询出的结果集并不是按照主键排序的话,那就要先把结果集中的主键值排序完再来做上边的那个过程,就比较耗时了。
情况一和情况二只是发生Intersection索引合并的必要条件,不是充分条件。即使情况一、情况二成立,也不一定发生Intersection索引合并,最终还是要看优化器如何选择。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数太多,导致回表开销太大,而通过Intersection索引合并后需要回表的记录数大大减少时才会使用Intersection索引合并。
Union合并
情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。 情况二:主键列可以是范围匹配。 情况三:使用Intersection索引合并的搜索条件(这种情况其实也挺好理解,就是搜索条件的某些部分使用Intersection索引合并的方式得到的主键集合和其他方式得到的主键集合取交集)。
Sort-Union合并
Union索引合并的使用条件太苛刻,必须保证各个二级索引列在进行等值匹配的条件下才可能被用到。先按照二级索引记录的主键值进行排序,之后按照Union索引合并方式执行的方式称之为Sort-Union索引合并,这种Sort-Union索引合并比单纯的Union索引合并多了一步对二级索引记录的主键值排序的过程。
为啥有Sort-Union索引合并,就没有Sort-Intersection索引合并么?是的,的确没有Sort-Intersection索引合并这么一说。Sort-Union的适用场景是单独根据搜索条件从某个二级索引中获取的记录数比较少,这样即使对这些二级索引记录按照主键值进行排序的成本也不会太高。而Intersection索引合并的适用场景是单独根据搜索条件从某个二级索引中获取的记录数太多,导致回表开销太大,合并后可以明显降低回表开销,但是如果加入Sort-Intersection后,就需要为大量的二级索引记录按照主键值进行排序,这个成本可能比回表查询都高了,所以也就没有引入Sort-Intersection。
小结
针对单表的访问方式(access method):
const:通过主键或者唯一二级索引列来定位一条记录的访问方法定义为:const,意思是常数级别的,代价是可以忽略不计的。 ref:搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为:ref。 ref_or_null:使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问方法就称为:ref_or_null。 range:利用索引进行范围匹配的访问方法称之为:range。 index:遍历二级索引记录的执行方式称之为:index。 all:使用全表扫描执行查询的方式称之为:all。
索引合并(index merge)的三种算法:
Intersection合并(index_merge_intersection)。 Union合并(index_merge_union)。 Sort-Union合并(index_merge_sort_union)。
我们也学习了索引合并三种算法的触发条件都是必要且不充分的,最终是否会使用到相关算法,仍需通过优化器做出最终判断。同时还学习了range访问方法使用的范围区间,通过人为分析的方式预估出使用不同索引执行SQL时所花费的成本高低。今天的内容偏原理,但理解起来很简单,大家多结合前面MySQL之B+树索引知识来感受MySQL设计的精妙之处。又是站在巨人肩膀的一天,每天进步一点点 。
。
参考资料
小孩子4919《MySQL是怎样运行的:从根儿上理解MySQL》

end



