




数据库执行引擎性能黑科技
现在业界OLAP数据库中,包括商业数据库和开源数据库,都在执行引擎这块做了很多黑科技,使得执行性能大大提高。比如向量化执行引擎、push-based pipeline执行引擎、JIT和向量化结合等等,本文我们不关注整体的实现以及NVM、GPU、FPGA等新硬件方面的提速,而关注具体性能黑科技的细节。
1、clickhouse中向量化执行引擎中使用的手段
1)大量使用instrinsic函数对关键路径代码进行优化,实际上就是调用SIMD封装的inline函数。参见https://github.com/ClickHouse/ClickHouse/issues/37005
2)统计过滤后有多少个值满足条件?通过popcount函数计算
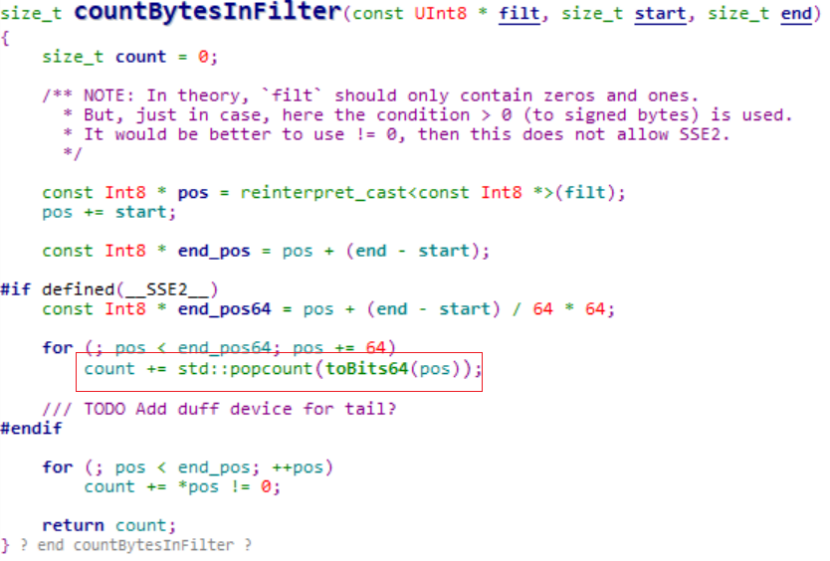
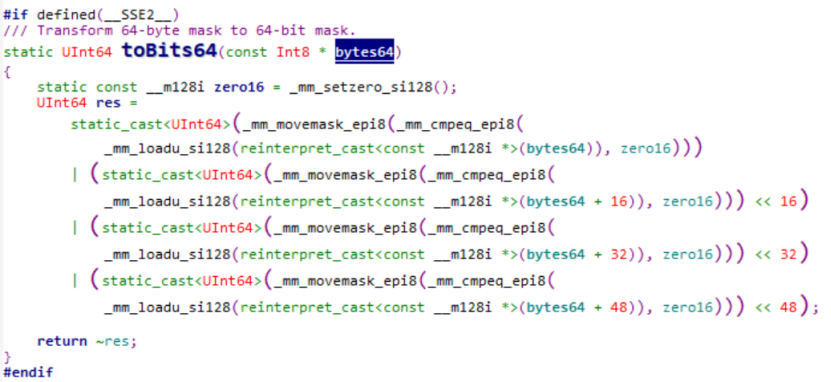
使用一个字节表示该行是否被选中,通过toBits64函数将64字节压缩成64位:
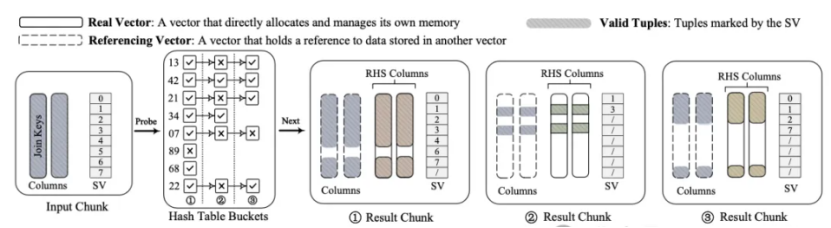
Join算子的探测端(外表的一个batch即DataChunk)会根内表多个Data Chunk进行组合产生小data Chunk,这些小data chunk可能共享同一个探测端的data chunk。比如探测端的一个Lbatch和内部两个Rbatch1(上图hash表的第一列)和Rbatch2(hash表的第2列)进行join,join的结果都比较小,那么可以将聚合join条件的两个结果的select vector合并,使用一个select vector来表示,Rbatch1和Rbatch2的符合join条件的值重新拷贝到一个batch中,并使用另外一个select vector进行表示:Selection Vector 记录的是 Data Chunk 里面有效数据条目的下标
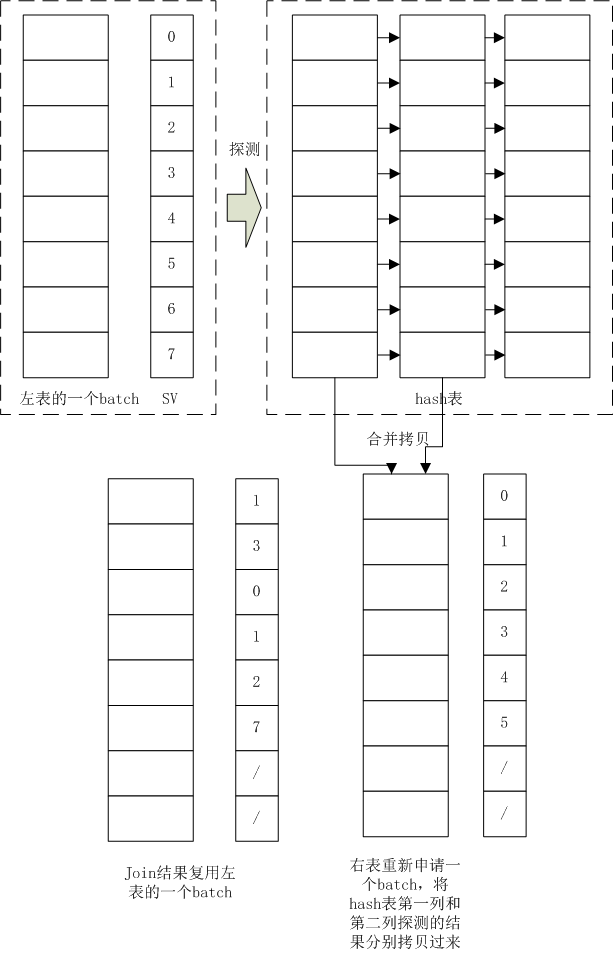
效果也不错,这种方式已经在duckdb中实现了,需要进一步看下duckdb中使用场景,在什么场景下适合使用这种方式。
Data Chunk Compaction in Vectorized Execution:SIGMOD 2025
https://github.com/duckdb/duckdb/pull/14956
5、stonedb向量化引擎中的优化
1)在 64 位操作系统中,CPU 从缓存中读取数据时按照 8 Bytes 对齐访问。如下图所示桔黄色为有效数据,数据被存放在 0x000000 ~ 0x00000F 一段连续内存中,偏移量为 0x000004,长度为 8 。CPU 会发出两个加载指令读取 0x00000 ~ 0x000007 和 0x000008 ~ 0x00000F 两个内存单元。然后通过位移操作后将两部分数据合并。如下图所示
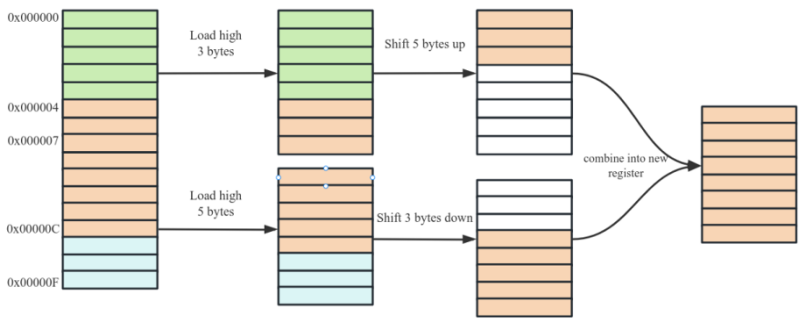
所以读取未对齐的数据会有额外的读取成本和寄存器操作成本,在高性能计算时尽量将数据对齐至 8 Bytes 读取,这样才能获得最好的性能。
2)循环展开

现代的编译器也会自动的做循环展开优化,值得注意的是循环展开将增加代码体积,特别对于循环体较大的代码,循环展开反而会降低性能。
3)内联优化
在介绍内联前,我们先要了解代码空洞的概念。如下图一段程序编译后,二进制可执行文件中依次包含 func funcA funcB 函数。在执行 func 函数时调用了 funcB 函数,此时需要 CPU 跳过一段内存空间加载并执行 funcB 函数。在本次执行过程中,我们称跳过的部分为 代码空洞。在执行过程中代码空洞越小,代码指令加载效率越高。
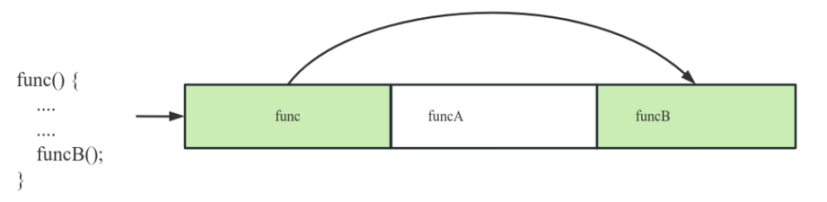
内联是指在编译器将函数内容展开到调用方的函数体中,这是一种解决代码空洞的方法。某个方法是否内联需要充分考虑,比如某个函数在低频的分支中调用,内联反而会加剧高频分支路径的空洞。内联还会造成代码膨胀,不推荐过长的函数内联到其它函数中
6、TDSQL向量化引擎中的优化
做了一个提前物化和延迟物化的物化策略,如下图
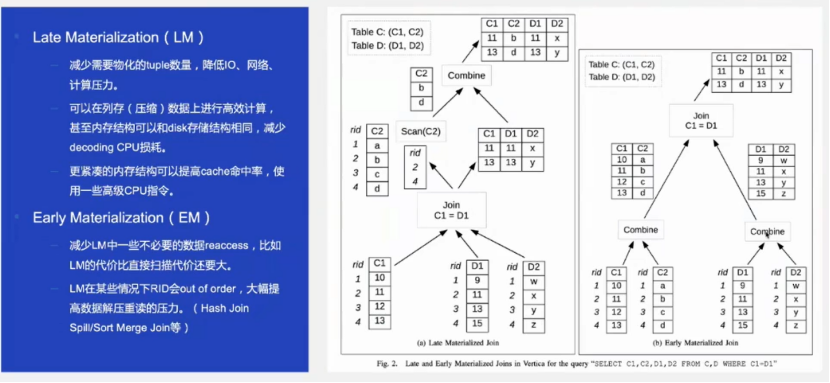
提前物化,很好理解,上图的(b):join结果的投影列包括表C的C1、C2和表D的D1、D2,join字段为C1=D1,扫描时将C和D表的所有列都进行扫描出来,然后进行join并输出join结果。
延迟物化,上图的(a),扫描时仅扫描C表的C1,然后和D表扫描出的数据进行join,根据join结果的selects数组,然后去扫描C表的C2列并进行过滤。将select下推到列存表C,根据列存的min/max/布隆等信息可以降低IO,从而减少需要物化的tuple数量;当然如果C是数据shuffle而来,那么通过这个select也可以减少网络压力。
参考
https://mp.weixin.qq.com/s/bqV5cWVweXl-4da0DHt5yQ
https://mp.weixin.qq.com/s/wW8a8gisrsUolJThcYkEUA
https://mp.weixin.qq.com/s/CgouiTvo1CcB9kiJE8sEUQ
https://www.modb.pro/db/1813144895893286912
https://mp.weixin.qq.com/s/tOqkHqj9y-4oPFC7Zr6vMg
向量化引擎对HTAP的价值与思考
https://news.qq.com/rain/a/20240704A09X5200
https://cloud.tencent.com/developer/article/1841367
https://github.com/YimingQiao/Chunk-Compaction-in-Vectorized-Execution
https://www.bilibili.com/video/BV1yY411x7RH/?vd_source=10ce859f3f7b1da2094a1283c19fe9b9
