




大家好,我是 JiekeXu,江湖人称“强哥”,青学会 MOP 技术社区主席,荣获 Oracle ACE Pro 称号,墨天轮 MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及 PCA、PCTA、OBCA、OGCA、金仓KCA、KCP 等众多国产数据库认证证书,今天和大家一起来看看 遇到一个比较奇葩的 Oracle 小故障,欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!

前 言
12 月 31 号下午快要下班的时候,看到监控突然告警,一套 19c 核心 ADG 备库出现“apply lag”应用延迟,心想难道是刚才表空间扩容添加数据文件导致的吗?赶紧跑到监控室登录生产环境看看。
【Oracle】 发生告警: Oracle Dataguard Lagtime Abnormal(More than 10 Minutes) Alert Name: DataguardLagtimeAbnormal 告警级别: warning 实例: 192.168.132.117:9161 描述: Lag of Dataguard sync process 'apply lag' on instance '192.168.132.117:9161' is: 1253s. 开始时间: 2024-12-31 16:47:22 结束时间:
数据库版本及架构说明
x86 RHEL7.9 Oracle 19c RAC + 单机 FS ADG + 单机级联灾备 FS ADG

故障排查
首先登录到备库查看延迟情况,确实有两个多小时的 apply lag 延迟时间,通过 V$MANAGED_STANDBY 视图继续查看 MRP 进程发现已经不存在了。
18:48:47 SYS@JIEKEDB> set linesize 150;
18:48:48 SYS@JIEKEDB> set pagesize 20;
18:48:48 SYS@JIEKEDB> column name format a13;
18:48:48 SYS@JIEKEDB> column value format a20;
18:48:48 SYS@JIEKEDB> column unit format a30;
18:48:48 SYS@JIEKEDB> column TIME_COMPUTED format a30;
18:48:48 SYS@JIEKEDB> select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
NAME VALUE UNIT TIME_COMPUTED
------------- -------------------- ------------------------------ ------------------------------
transport lag +00 00:00:00 day(2) to second(0) interval 12/31/2024 18:38:48
apply lag +00 02:15:00 day(2) to second(0) interval 12/31/2024 18:38:48
18:48:48 SYS@JIEKEDB> SELECT PROCESS, STATUS,SEQUENCE#,thread# FROM V$MANAGED_STANDBY;
PROCESS STATUS SEQUENCE# THREAD#
--------- ------------ ---------- ----------
ARCH CLOSING 315536 1
DGRD ALLOCATED 0 0
DGRD ALLOCATED 0 0
ARCH CLOSING 315706 1
ARCH CLOSING 324334 2
ARCH CLOSING 324528 2
RFS IDLE 0 2
RFS IDLE 0 1
RFS IDLE 315707 1
RFS IDLE 324529 2
LNS WRITING 315707 1
LNS WRITING 324529 2
RFS IDLE 0 0
DGRD ALLOCATED 0 0
jieke-rac19cdg:/home/oracle(JIEKEDB)$ ps -ef | grep mrp
oracle 9398 8871 0 18:39 pts/0 00:00:00 grep --color=auto mrp
alert日志
然后去查看 alert 日志发现了问题,MRP 进程因 ORA-00059 进程挂掉了,参数 db_files 达到了最大值备库恢复中断,提示控制文件 SCN 比 数据文件 SCN 大一点,数据库仍然是 open 状态,可进行查询,但需要恢复。
2024-12-31T16:26:01.960271+08:00 PR00 (PID:89993): MRP0: Background Media Recovery terminated with error 59 2024-12-31T16:26:01.960486+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekdbdg/JIEKEDB/trace/JXRTDB_pr00_89993.trc: ORA-00059: maximum number of DB_FILES exceeded PR00 (PID:89993): Managed Standby Recovery not using Real Time Apply 2024-12-31T16:26:02.980126+08:00 Recovery interrupted! IM on ADG: Start of Empty Journal IM on ADG: End of Empty Journal Standby recovery stopped due to failure in applying recovery marker (opcode 17.30). Datafiles are recovered to a consistent state at change 108685791720 but controlfile is ahead at change 108685791755. Database remains open for continuous queries. Please continue recovery. Stopping change tracking 2024-12-31T16:26:03.860602+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekdbdg/JIEKEDB/trace/JXRTDB_pr00_89993.trc: ORA-00059: maximum number of DB_FILES exceeded 2024-12-31T16:26:04.283338+08:00 Background Media Recovery process shutdown (JIEKEDB)
查看 DB_FILES 参数
分别登录不同的环境查看 db_files 参数以及数据文件总数,确实主备库和级联备库都不一样。
--主库查看
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.15.0.0.0
18:38:04 SYS@JIEKEDB1> show parameter db_files
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_files integer 2048
18:39:13 SYS@JIEKEDB1> select count(*) from dba_data_files;
COUNT(*)
----------
201
--备库
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.15.0.0.0
18:37:56 SYS@JIEKEDB> show parameter db_files
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_files integer 200
18:40:13 SYS@JIEKEDB> select count(*) from dba_data_files;
COUNT(*)
----------
200
--级联灾备库
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.23.0.0.0
SQL> show parameter db_files
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_files integer 200
SQL> select count(*) from dba_data_files;
COUNT(*)
----------
200
果然,主备库 DB_FILES 值不一样,因这个参数在时候修改的可能性不大,因此则可能就是在刚开始搭建是忘记修改导致的。当去查看备库参数文件时,居然发现没有这个参数,那么也就能说得通了,这个参数默认值就是 200,没有配置则使用默认的 200,那么很大一个可能就是在搭建备库时多删除了一个参数导致的。
cd $ORACLE_HOME/dbs strings spfileJIEKEDB.ora | grep db_files
当去查看 alert 修改记录时发现在 2023 年开始上线时就已经修改为 2048 了。23 年 2 月 21 日下午启动时此值还是 2048;23 年 2 月 24 日晚启动时就没有参数 db_files 了,可见,当时由于错误操作删除了此参数,导致在备库没有,则默认为 200。又因今天下午刚加了主库表空间数据文件,当备库数据文件达到 200 后参数限制,第 201 个数据文件则没法在备库自动添加,进而导致 MRP 进程挂掉。
2023-02-21T15:30:23.967007+08:00 ALTER SYSTEM SET db_files=2048 SCOPE=SPFILE; --2 月 21 日下午启动时就有参数 db_files。。 Starting ORACLE instance (normal) (OS id: 132421) 2023-02-21T15:33:09.113947+08:00 **************************************************** Sys-V shared memory will be used for creating SGA **************************************************** 2023-02-21T15:33:09.114544+08:00 ********************************************************************** 2023-02-21T15:33:09.114584+08:00 Dump of system resources acquired for SHARED GLOBAL AREA (SGA) --2 月 24 日晚启动时就没有参数 db_files。 Starting ORACLE instance (normal) (OS id: 127153) 2023-02-24T23:28:24.241558+08:00 **************************************************** Sys-V shared memory will be used for creating SGA **************************************************** 2023-02-24T23:28:24.242146+08:00 ********************************************************************** 2023-02-24T23:28:24.242186+08:00 Dump of system resources acquired for SHARED GLOBAL AREA (SGA)
对于 db_files 的坑,这个我之前也写过 《Oracle 表空间和数据文件遇到的坑》,当数据量超过 5、6T 以后,如果 db_files 是默认的 200 则没法添加数据文件扩容,只能修改参数重启数据库,这对于生产核心而言是比较坑的,所以一般建议一开始就将此参数调整为更大值重启数据库即可,但也要注意不能大于 65534。
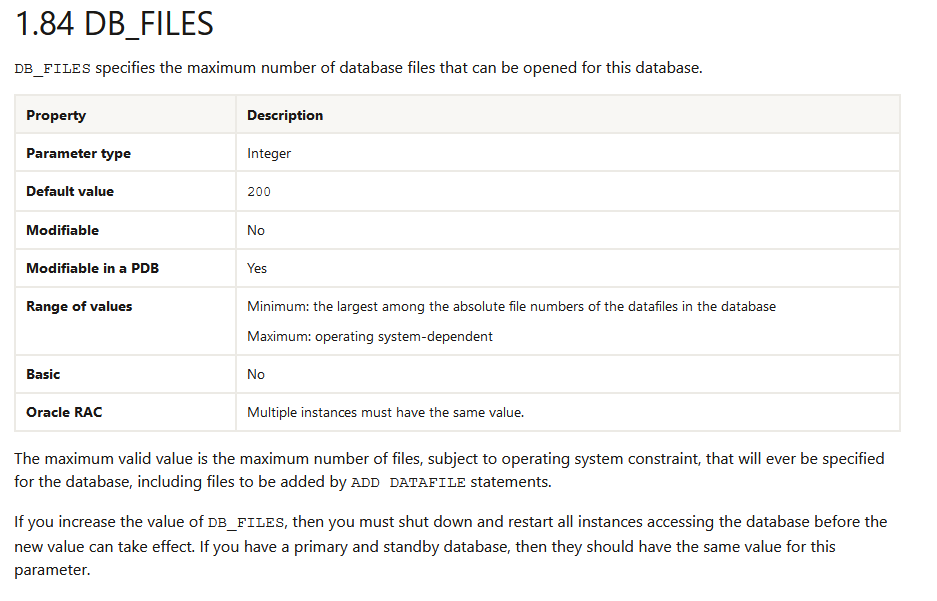
解决问题
那么,解决方案也比较简单,修改此参数就行,只不过需要重启数据库实例。
寻找停机窗口,修改 DB_FILES 参数,并重启备库。
ALTER SYSTEM SET db_files=2048 SCOPE=SPFILE;
shu immediate
startup
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
顺便说点离谱的
元旦前夕,群友还在问新建的 11g ADG 环境, rman duplicate 正常,但 alter 日志报错好多个 “Warning: Datafile 201 /XXX/XXX/XXX.dbf is offline during full database recovery and will not be recovered”,ADG 端少了 64 个数据文件,查看源端自 201 以后的数据文件都是正常的 online 但备库状态都是 recover 状态。可据说 ADG 备库正常没有其他错误还能应用日志,这真是“离谱他妈给离谱开门,离谱到家了”,真没见过这么离谱的事情,更离谱的事情是今天说从主库重新生成了备库的控制文件就好了,离谱极了。
当时我也在 MOS 上搜索了如果主备库 db_files 参数不一致,备库 alert 日志中会有 Warning 告警有 offline 的数据文件。Standby Database Report ORA-00059: maximum number of DB_FILES During Recovery (Doc ID 2653327.1)
Warning: Datafile 4997 (/data/oradata/<pdb name>/DRIVE_ACCOUNTS.dbf) is offline during full database recovery and will not be recovered Warning: Datafile 4998 (/data/oradata/<pdb name>/DRIVE_MISC.dbf) is offline during full database recovery and will not be recovered Warning: Datafile 4999 (/data/oradata/<pdb name>/DRIVE_STOCK.dbf) is offline during full database recovery and will not be recovered <<< file# 4999
参考链接
官方文档参考:https://docs.oracle.com/en/database/oracle/oracle-database/19/admin/managing-data-files-and-temp-files.html#GUID-CAC446B4-7E44-419B-9A4C-306677CD95E0
https://www.modb.pro/db/1763125793060884480
--你可能还想看:
How to Recover from errors ORA-01171 ORA-01122 ORA-01251 ORA-01186 (Doc ID 333620.1)
Standby Database Report ORA-00059: maximum number of DB_FILES During Recovery (Doc ID 2653327.1)
How to Create Standby Database for Primary with Offline Datafile (Doc ID 2445611.1)
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————
