




大家好,这里是公众号 DBA学习之路,致力于分享数据库领域相关知识。
目录
前言
今天收到应用反馈:在 2025-01-03 13:30:42.058 发生了一起卡顿,持续 15 秒,到 2025-01-03 13:30:57.872 结束,需要帮忙排查下原因。
先介绍下数据库的环境信息:
- 19C RAC CDB(2 节点)架构,有 4 个 PDB,出问题的是其中一个 PDB
- DB 补丁版本:19.19
- 实际数据量 65G
本文记录一下我的分析过程。
问题分析
首先查看问题时间段的等待事件:
-- 查看等待事件
SQL> set line2222 pages1000 tab off
col event for a40
SELECT instance_number,
event,
COUNT(*)
FROM dba_hist_active_sess_history
WHERE sample_time BETWEEN to_date('2025-01-03 13:30:42',
'yyyy-mm-dd hh24:mi:ss') AND to_date('2025-01-03 13:30:57',
'yyyy-mm-dd hh24:mi:ss')
GROUP BY instance_number,
event
ORDER BY 3 desc;
INSTANCE_NUMBER EVENT COUNT(*)
--------------- ---------------------------------------- ----------
1 enq: TM - contention 42
1 log file sync 6
1 gcs drm freeze in enter server mode 2
2 gc cr block 2-way 1
1 enq: HW - contention 1
复制可以看到在问题时间段的主要等待事件是 enq: TM - contention,发生在节点 1 上。查看节点 1 对应时间段等待事件相关 sql:
SQL> alter session set container=<PDBNAME>;
SQL> SELECT event,
user_id,
sql_id,
COUNT(*)
FROM dba_hist_active_sess_history
WHERE sample_time BETWEEN to_date('2025-01-03 13:30:42',
'yyyy-mm-dd hh24:mi:ss') AND to_date('2025-01-03 13:30:57',
'yyyy-mm-dd hh24:mi:ss')
AND instance_number = 1
AND event = 'enq: TM - contention'
GROUP BY user_id,
event,
sql_id
ORDER BY 2;
EVENT USER_ID SQL_ID COUNT(*)
-------------------- ---------- ------------- ----------
enq: TM - contention 112 bwf9rt5u93cpx 42
复制等待事件对应的 SQL_ID 为 bwf9rt5u93cpx,查看具体的 SQL:
SQL> set line2222 pages1000 tab off
col sql_text for a100
select sql_id,sql_text from gv$sql where sql_id = 'bwf9rt5u93cpx' and rownum=1;
SQL_ID SQL_TEXT
------------- ----------------------------------------------------------------------------------------------------
bwf9rt5u93cpx update LUCIFER set .... where id=:51
复制可以发现等待事件对应的 SQL 是一个 update DML 语句,到这我们基本已经确定问题 SQL 了,接下来就是分析为什么这个 SQL 会导致 enq: TM - contention 等待事件,以及应用卡顿的原因。
enq: TM - contention
关于 enq: TM - contention 等待事件,可以参考 MOS 文档的介绍:
The ‘TM’ DML (Table Manipulation) Enqueue is acquired by a transaction when a table is modified by an INSERT, UPDATE, DELETE, MERGE, SELECT with the FOR UPDATE clause, or LOCK TABLE statement. DML operations require table locks to reserve DML access to the table on behalf of a transaction and to prevent DDL operations that would conflict with the transaction.
简单翻译一下:当通过 INSERT、UPDATE、DELETE、MERGE、带有 FOR UPDATE 子句的 SELECT,或 LOCK TABLE 语句修改表时,事务会获取 TM DML(表操作)队列锁。DML 操作需要表锁来为事务保留对表的 DML 访问权限,并防止与事务冲突的 DDL 操作。
一般造成 TM 锁的几种可能原因:
- 子表中外键(FK)约束列缺少索引:如果发生争用(contention),最常见的原因是子表中外键(FK)约束列上缺少相应的索引。
- 并行 DML:如果使用了并行 DML(PDML),则在对相同对象执行其他 DML 操作时,也可能发生“TM”锁争用。并行 DML 会在参与的分区上获取 TM 队列锁(共享模式),并在整个表上获取 TM 队列锁(行排他模式)。在 PDML 事务完成之前,不允许对受影响的分区执行其他 DML 操作。在这种情况下,等待 TM 队列锁的会话要么试图执行 PDML,要么正在等待其他会话完成 PDML 操作。
所以一般来说,这是一个应用程序设计问题,如果不创建缺失的 FK 索引,则无法修复。从 11.1.0.6 开始,外键锁定行为发生了变化,这是由于一个未公开的 Bug 修复的引入导致的。在修复后,对子表执行 DML 操作时,会在父表上获取 SX 模式的 DML 锁,而不是之前的 SS 模式 DML 锁。
参考 MOS 文档:
- WAITEVENT: “enq: TM - contention” Reference Note (Doc ID 1980175.1)
- Resolving Issues Where ‘enq: TM - contention’ Waits are Occurring (Doc ID 1905174.1)
- Script to Check for Foreign Key Locking Issues for a Specific User (Doc ID 1019527.6)
- Script: To list Foreign Key Constraints (Doc ID 1039297.6)
问题排查
知道了导致等待事件的可能原因后,大致的排查方向就出来:
- 检查 update DML 语句的表是否有外键缺少索引的情况。
- 表是否存在并行 DML 事务。
外键索引缺失检查
通过 SQL 检查是否存在外键
SQL> column owner_name format a10
column PARENT_TABLE format a25
column key_name format a15
column "referencing_table/CHILD_TABLE" format a40
column foreign_key_name format a15
SELECT a.owner owner_name,
a.table_name "PARENT_TABLE",
a.constraint_name key_name,
b.table_name "referencing_table/CHILD_TABLE",
b.constraint_name foreign_key_name,
B.STATUS fk_status
FROM ALL_CONSTRAINTS a,
ALL_CONSTRAINTS b
WHERE a.constraint_name = b.r_constraint_name
AND b.constraint_type = 'R' and a.table_name='&Parent_table'
ORDER BY 1, 2, 3, 4;
no rows selected
复制很明显没有看到对应的记录,说明并没有外键,自然也就排除了外键索引缺失的可能。
并行 DML 检查
其实这个可以直接排除,因为 update DML 的 SQL 中并没有加并行,除非在表或者索引上开启了并行度。检查表和索引是否开启并行:
col table_name format a35
col index_name format a35
Rem Tables that have Indexes with not the same DOP
Rem !!!!! This command can take some time to execute !!!
Rem ---------------------------------------------------;
set lines 150
select substr(t.owner,1,15) Owner ,
t.table_name ,
substr(trim(t.degree),1,7) Degree ,
substr(trim(t.instances),1,9) Instances,
i.index_name ,
substr(trim(i.degree),1,7) Degree ,
substr(trim(i.instances),1,9) Instances
from all_indexes i,
all_tables t
where ( trim(i.degree) != trim(t.degree) or
trim(i.instances) != trim(t.instances) ) and
i.owner = t.owner and
i.table_name = t.table_name;
no rows selected
复制同样没有发现开启并行的情况。
分析到这,线索似乎断了。所以,问题到底出在哪了?
付费群咨询
在付费群咨询了一下大佬,得到回复如下:
enq: TM - contention 这个等待事件,如果发生在 RAC 集群里他还有一种问题,以上分析主要是在单实例情况下。如果发生在集群中,他可是要考虑高速缓存融合问题的,需要高速缓存融合校验完成后确认无误且 GC-CR 被回收后才能释放的。
通过 awr 报告可以发现:
基本上所有的等待事件都指向了 GC 集群之间资源回收与高速缓存融合的问题。这个就是因为集群资源未能及时回收且集群高速缓存融合速度慢有很大的关系:
而且这集群和网络吞吐明显就高,最优方案是节点间才用更优良的网络设备。当时不是网络整体的问题,是在传输时产生了拥堵。
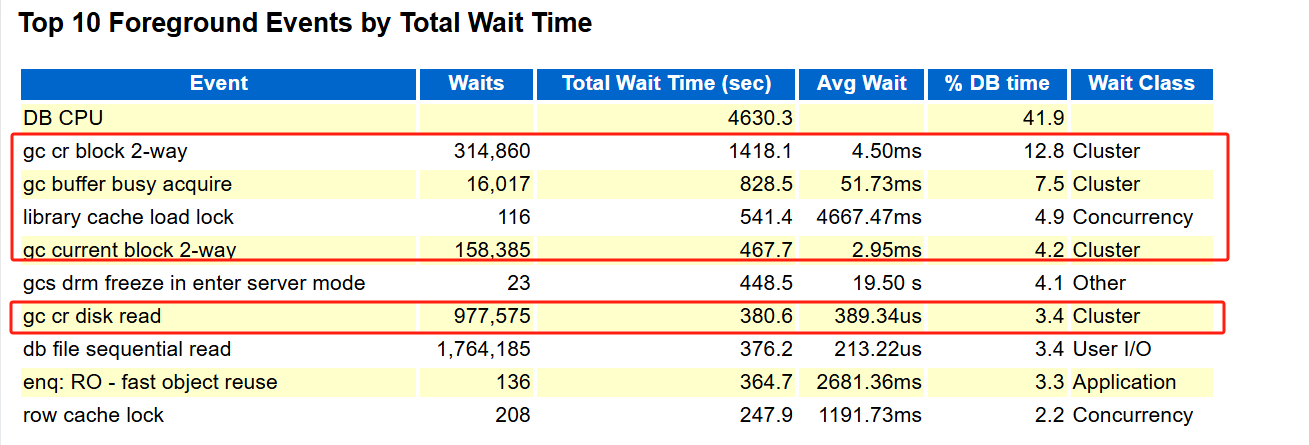
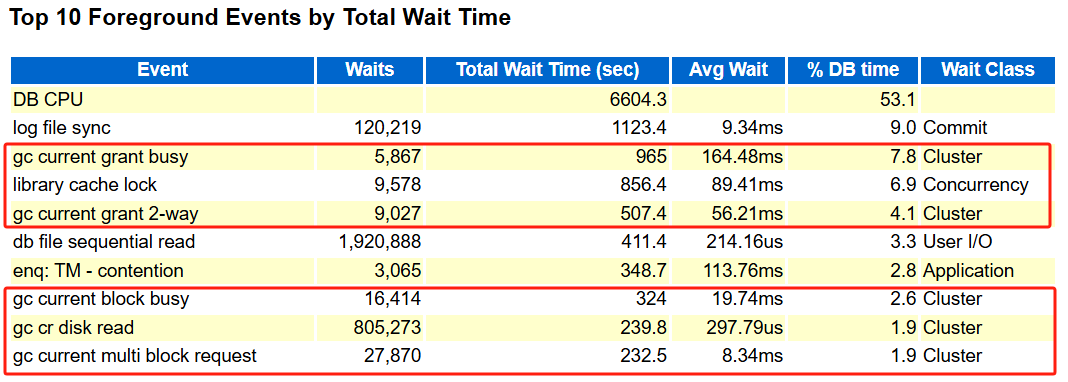
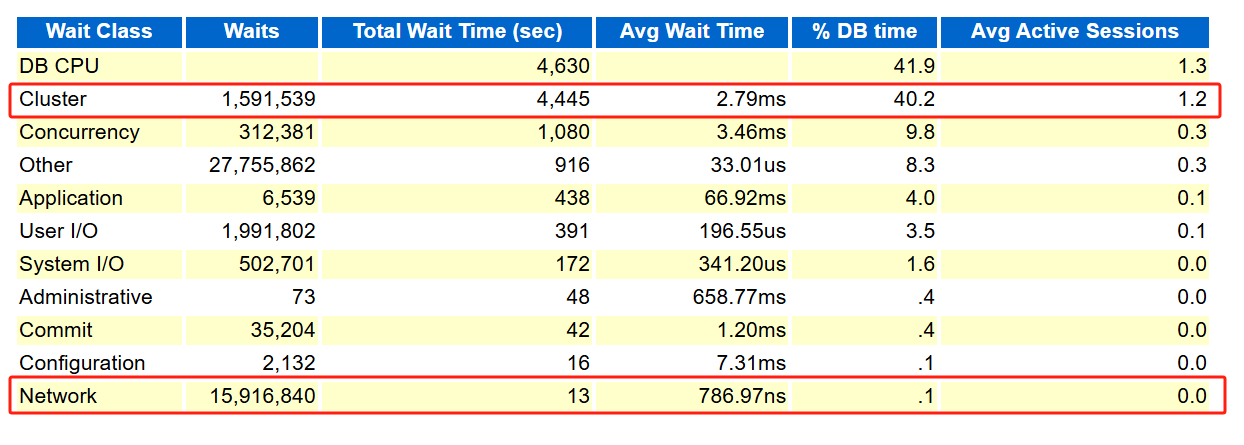
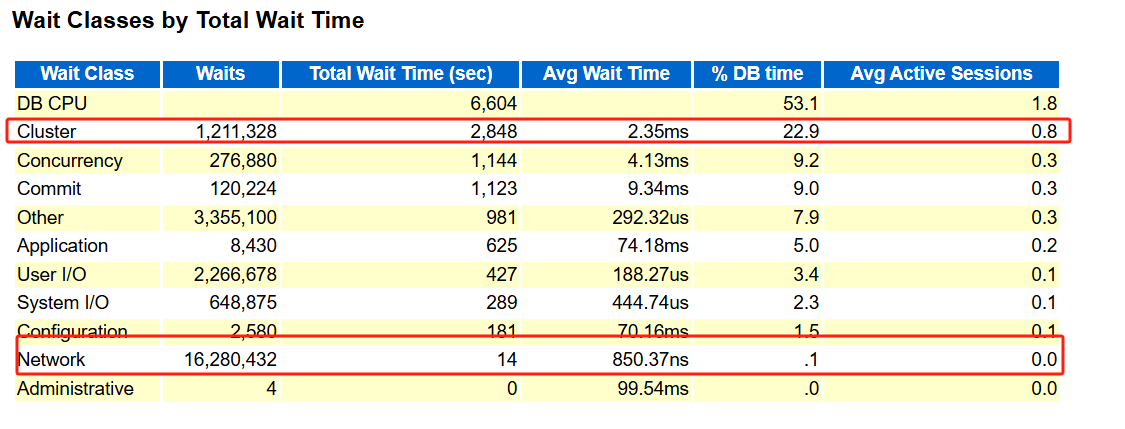
查看等待事件也能看到
gcs drm freeze in enter server mode等待事件的平均等待都很高,怀疑可能是 DRM 特性问题导致的 BUG。
通过 DRMDIAG 收集诊断信息:
-- NAME: DRMDIAG.SQL
-- ------------------------------------------------------------------------
-- AUTHOR: Oracle Support Services
-- ------------------------------------------------------------------------
-- PURPOSE:
-- This script is intended to provide a user friendly guide to troubleshoot
-- drm (dynamic resource remastering) waits. The script will create a file
-- called drmdiag_<timestamp>.out in your local directory.
set echo off
set feedback off
column timecol new_value timestamp
column spool_extension new_value suffix
select to_char(sysdate,'Mondd_hh24mi') timecol,
'.out' spool_extension from sys.dual;
column output new_value dbname
select value || '_' output
from v$parameter where name = 'db_name';
spool drmdiag_&&dbname&×tamp&&suffix
set trim on
set trims on
set lines 140
set pages 100
set verify off
set feedback on
PROMPT DRMDIAG DATA FOR &&dbname&×tamp
PROMPT Important paramenters:
PROMPT
PROMPT _gc_policy_minimum (default is 1500). Increasing this would cause DRMs to happen less frequently.
PROMPT Use the "OBJECT_POLICY_STATISTICS" section later in this report to see how active various objects are.
PROMPT
PROMPT _gc_policy_time (default to 10 (minutes)). Amount of time to evaluate policy stats. Use the
PROMPT "OBJECT_POLICY_STATISTICS" section later in this report to see how active various objects are for the
PROMPT _gc_policy_time. Usually not necessary to change this parameter.
PROMPT
PROMPT _gc_read_mostly_locking (default is TRUE). Setting this to FALSE would disable read mostly related DRMs.
PROMPT
PROMPT gcs_server_processes (default is derived from CPU count/4). May need to increase this above the
PROMPT default to add LMS processes to complte the work during a DRM but the default is usually adequate.
PROMPT
PROMPT _gc_element_percent (default is 110). May need to apply the fix for bug 14791477 and increase this to
PROMPT 140 if running out of lock elements. Usually not necessary to change this parameter.
PROMPT
PROMPT GC Related parameters set in this instance:
show parameter gc
PROMPT
PROMPT CPU count on this instance:
show parameter cpu_count
PROMPT
PROMPT SGA INFO FOR &&dbname&×tamp
PROMPT
PROMPT Larger buffer caches (above 100 gig) may increase the cost of DRMs significantly.
set lines 120
set pages 100
column component format a40 tru
column current_size format 99999999999999999
column min_size format 99999999999999999
column max_size format 99999999999999999
column user_specified_size format 99999999999999999
select component, current_size, min_size, max_size, user_specified_size
from v$sga_dynamic_components
where current_size > 0;
PROMPT
PROMPT ASH THRESHOLD...
PROMPT
PROMPT This will be the threshold in milliseconds for total drm freeze
PROMPT times. This will be used for the next queries to look for the worst
PROMPT 'drm freeze' minutes. Any minutes that have an average log file
PROMPT sync time greater than the threshold will be analyzed further.
column threshold_in_ms new_value threshold format 999999999.999
select decode(min(threshold_in_ms),null,0,min(threshold_in_ms)) threshold_in_ms
from (select inst_id, to_char(sample_time,'Mondd_hh24mi') minute,
sum(time_waited)/1000 threshold_in_ms
from gv$active_session_history
where event like '%drm freeze%'
group by inst_id,to_char(sample_time,'Mondd_hh24mi')
order by 3 desc)
where rownum <= 10;
PROMPT
PROMPT ASH WORST MINUTES FOR DRM FREEZE WAITS:
PROMPT
PROMPT APPROACH: These are the minutes where the avg drm freeze time
PROMPT was the highest (in milliseconds).
column event format a30 tru
column program format a35 tru
column total_wait_time format 999999999999.999
column avg_time_waited format 999999999999.999
select to_char(sample_time,'Mondd_hh24mi') minute, inst_id, event,
sum(time_waited)/1000 TOTAL_WAIT_TIME , count(*) WAITS,
avg(time_waited)/1000 AVG_TIME_WAITED
from gv$active_session_history
where event like '%drm freeze%'
group by to_char(sample_time,'Mondd_hh24mi'), inst_id, event
having sum(time_waited)/1000 > &&threshold
order by 1,2;
PROMPT
PROMPT ASH DRM BACKGROUND PROCESS WAITS DURING WORST MINUTES:
PROMPT
PROMPT APPROACH: What are LMS and RS/RMV doing when 'drm freeze' waits
PROMPT are happening? LMD and LMON info may also be relevant
column inst format 999
column minute format a12 tru
column event format a50 tru
column program format a55 wra
select to_char(sample_time,'Mondd_hh24mi') minute, inst_id inst,
sum(time_waited)/1000 TOTAL_WAIT_TIME , count(*) WAITS,
avg(time_waited)/1000 AVG_TIME_WAITED,
program, event
from gv$active_session_history
where to_char(sample_time,'Mondd_hh24mi') in (select to_char(sample_time,'Mondd_hh24mi')
from gv$active_session_history
where event like '%drm freeze%'
group by to_char(sample_time,'Mondd_hh24mi'), inst_id
having sum(time_waited)/1000 > &&threshold and sum(time_waited)/1000 > 0.5)
and (program like '%LMS%' or program like '%RS0%' or program like '%RMV%'
or program like '%LMD%' or program like '%LMON%' or event like '%drm freeze%')
group by to_char(sample_time,'Mondd_hh24mi'), inst_id, program, event
order by 1,2,3,5 desc, 4;
PROMPT
PROMPT POLICY HISTORY INFO:
PROMPT See if you can correlate policy history events with minutes of high
PROMPT wait time.
select * from gv$policy_history
order by event_date;
PROMPT
PROMPT DYNAMIC_REMASTER_STATS
PROMPT This shows where time is spent during DRM operations.
set heading off
set lines 60
select 'Instance: '||inst_id inst, 'Remaster Ops: '||remaster_ops rops,
'Remaster Time: '||remaster_time rtime, 'Remastered Objects: '||remastered_objects robjs,
'Quiesce Time: '||quiesce_time qtime, 'Freeze Time: '||freeze_time ftime,
'Cleanup Time: '||cleanup_time ctime, 'Replay Time: '||replay_time rptime,
'Fixwrite Time: '||fixwrite_time fwtime, 'Sync Time: '||sync_time stime,
'Resources Cleaned: '||resources_cleaned rclean,
'Replayed Locks Sent: '||replayed_locks_sent rlockss,
'Replayed Locks Received: '||replayed_locks_received rlocksr,
'Current Objects: '||current_objects
from gv$dynamic_remaster_stats
order by 1;
set lines 120
set heading on
PROMPT
PROMPT OBJECT_POLICY_STATISTICS:
PROMPT The sum of the last 3 columns (sopens,xopens,xfers) decides whether the object
PROMPT will be considered for DRM (_gc_policy_minimum). The duration of the stats
PROMPT are controlled by _gc_policy_time (default is 10 minutes).
select object,node,sopens,xopens,xfers from x$object_policy_statistics;
PROMPT
PROMPT ACTIVE OBJECTS (OBJECT_POLICY_STATISTICS)
PROMPT These are the objects that are above the default _gc_policy_minimum (1500).
select object, node, sopens+xopens+xfers activity
from x$object_policy_statistics
where sopens+xopens+xfers > 1500
order by 3 desc;
PROMPT LWM FOR LE FREELIST
PROMPT This number should never get near zero, if it does consider the fix for bug 14791477
PROMPT and/or increasing _gc_element_percent.
select sum(lwm) from x$kclfx;
PROMPT
PROMPT GCSPFMASTER INFO WITH OBJECT NAMES
column objname format a120 tru
select o.name || ' - '|| o.subname objname, o.type#, h.*
from v$gcspfmaster_info h, obj$ o where h.data_object_id=o.dataobj#
order by data_object_id;
PROMPT
PROMPT ASH DETAILS FOR WORST MINUTES:
PROMPT
PROMPT APPROACH: If you cannot determine the problem from the data
PROMPT above, you may need to look at the details of what each session
PROMPT is doing during each 'bad' snap. Most likely you will want to
PROMPT note the times of the high drm freeze waits, look at what
PROMPT LMS, RS, RMV, LMD0, LMON is doing at those times, and go from there...
set lines 140
column program format a45 wra
column sample_time format a25 tru
column event format a30 tru
column time_waited format 999999.999
column p1 format a40 tru
column p2 format a40 tru
column p3 format a40 tru
select sample_time, inst_id inst, session_id, program, event, time_waited/1000 TIME_WAITED,
p1text||': '||p1 p1,p2text||': '||p2 p2,p3text||': '||p3 p3
from gv$active_session_history
where to_char(sample_time,'Mondd_hh24mi') in (select
to_char(sample_time,'Mondd_hh24mi')
from gv$active_session_history
where event like '%drm freeze%'
group by to_char(sample_time,'Mondd_hh24mi'), inst_id
having sum(time_waited)/1000 > &&threshold)
and time_waited > 0.5
order by 1,2,3,4,5;
spool off
PROMPT
PROMPT OUTPUT FILE IS: drmdiag_&&dbname&×tamp&&suffix
PROMPT
复制根据输出内容发现,确实存在问题:
ASH WORST MINUTES FOR DRM FREEZE WAITS:
APPROACH: These are the minutes where the avg drm freeze time
was the highest (in milliseconds).
MINUTE INST_ID EVENT TOTAL_WAIT_TIME WAITS AVG_TIME_WAITED
------------------- ---------- ------------------------------ ----------------- ---------- -----------------
Sep25_2142 2 gcs drm freeze in enter server 114534.611 89 1286.906
Sep25_2321 2 gcs drm freeze in enter server 108782.598 117 929.766
Sep26_1312 1 gcs drm freeze in enter server 90174.892 81 1113.270
Sep26_1442 1 gcs drm freeze in enter server 168819.711 178 948.425
Sep26_1522 2 gcs drm freeze in enter server 128503.922 126 1019.872
Sep26_1622 2 gcs drm freeze in enter server 99923.706 98 1019.630
Sep26_2023 1 gcs drm freeze in enter server 200035.622 192 1041.852
Sep26_2024 1 gcs drm freeze in enter server 98015.416 64 1531.491
Sep26_2324 1 gcs drm freeze in enter server 134652.836 77 1748.738
复制查了下 MOS 文档:
查看对应的问题描述:
Beginning with the LSR (lock state resolution) feature introduced in 19c, it is possible to >see “gcs drm freeze in enter server mode” waits when there is no DRM running.
These could be triggered by a new feature called LSR which tries to resolve long GC waits.
There are a few wait chains like this: Chain 1 Signature: ‘rdbms ipc message’<=‘gcs drm >freeze in enter server mode’<=‘gc cr request’
针对 19.19 版本的 BUG 只有这个,临时解决方案是:
SQL> alter system set "_gcs_recoverable_asserts"=0 scope=both sid='*';
System altered.
复制最终解决方案是升级到 19.22 以上。
写在最后
本文仅分享问题分析思路,问题是否解决还得观察,暂且不表,如果进展,我再更新,收!
评论

 0 点赞
0 点赞 0 点赞
0 点赞 0 点赞
0 点赞
 0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞


