新的项目接手一套Oracle11.2.0.4的数据库,运行在国产操作系统,通过初次巡检,发现并未开启大页,但是透明大页已经关闭,经过多方了解,之前的运维人员无法开启大页,所以做了一个定时任务每20min执行echo 3 > /proc/sys/vm/drop_caches的操作。但是这样的操作极其容易导致数据库宕机,由于初步接手此数据库,并且此业务已经运行10年,所以不敢贸然去修改只好先去观察。
为什么echo3会导致数据库宕机
alert日志中会lmd0进程开始报同样的错误;然后接着LMD0进程会强行把数据库实例终止。
ORA-00600: internal error code, arguments: [KGHLKREM1], [0x06BC00020] with stack trace similar to: kghnerror kghadd_reserved_ext kghgex -- or also ORA-07445: exception encountered: core dump [kglhdal()+1105][SIGSEGV] [Address not mapped to object] [0x000000008] [] [] ORA-07445: exception encountered: core dump [kghfnd()+2328] [SIGSEGV] [Address not mapped to object] [0xFFFFFFFFFFFFFFF0] [] []复制
lmd0 进程的trace文件内容会报类似的错误
Also the SGA heap Dump of memory around the offending addr (in this particular example: 0x6bc00020) shows it is zeroed out: asm1_lmd0_8600.trc ~~~~~~~~~~~~~~~~~~ *** 2010-02-08 15:57:38.274 ***** Internal heap ERROR KGHLKREM1 addr=0x6c400020 ds=0x60000058 ***** ***** Dump of memory around addr 0x6c400020: 06C3FF020 00000000 00000000 00000000 00000000 [................] Repeat 511 times复制
不当使用 drop_caches 导致 Oracle 数据库宕机的原因主要包括以下几点:
-
内存清理导致的数据不一致:当
drop_caches设置为3时,会触发 Linux 的内存清理回收机制,这可能导致内存中的脏页(已修改但尚未写入磁盘的数据页)被错误地释放。如果这些脏页包含了 Oracle 数据库的重要数据,那么在释放后,这些数据可能会丢失,导致数据库出现内存错误,进而引发宕机。 -
系统资源的突然释放:
drop_caches命令会释放大量的系统资源,这可能会导致数据库系统突然失去必要的内存支持。Oracle 数据库依赖于充足的内存资源来维持其缓存和缓冲区,以保证高效的数据访问和事务处理。如果这些资源被突然释放,数据库性能可能会急剧下降,甚至导致数据库无法正常运行。 -
与 HugePages 配置的冲突:在使用
drop_caches的同时启用了 HugePages 配置的情况下,可能会出现内存错误。HugePages 是一种内存管理技术,用于提高大内存系统的效率。当drop_caches与 HugePages 同时使用时,可能会触发 Linux 的某些 bug,导致 Oracle 数据库出现 ORA-600 错误,这是一种严重的错误,可能会导致数据库宕机。 -
系统 IO 负载增加:释放缓存时,系统需要确保缓存中的数据与硬盘上的数据一致,这通常伴随着系统 IO 的飙高。如果数据库正在执行大量的 IO 操作,
drop_caches可能会导致 IO 负载进一步增加,影响数据库的性能,甚至导致数据库无法处理请求而宕机。 -
计划任务的不当执行:如果在数据库高负载时执行
drop_caches,可能会导致服务器资源不足,从而引发数据库宕机。例如,如果定时任务在每天下午执行,而那天网站的在线用户超过预期,脚本运行时清除了缓存中的一切,导致所有用户都从磁盘读取数据,可能会引起服务器崩溃并损坏数据库。
综上所述,不当使用 drop_caches 可能会因为多种原因导致 Oracle 数据库宕机,包括内存数据不一致、系统资源突然释放、与 HugePages 配置的冲突、系统 IO 负载增加以及计划任务的不当执行。因此,在生产环境中应谨慎使用 drop_caches,并确保在执行前进行充分的测试和评估。
突发情况
更换了运维厂家以后,进行了一次大版本的发布以后,导致服务器每天在高峰期就会出现卡死状态,导致数据库任何查询都很慢,最终不得已重启服务器来解决问题。
通过排查,由于开启大页不成功,所以在sysctl.conf里面已经把vm.nr_hugepages参数已经注释,但是在/etc/security/limits.conf文件中添加memlock的限制并没有注释掉,这就会导致memlock的内存并不会给Oracle数据库所使用,因此第一次进行了参数注释操作,并重启了服务器。
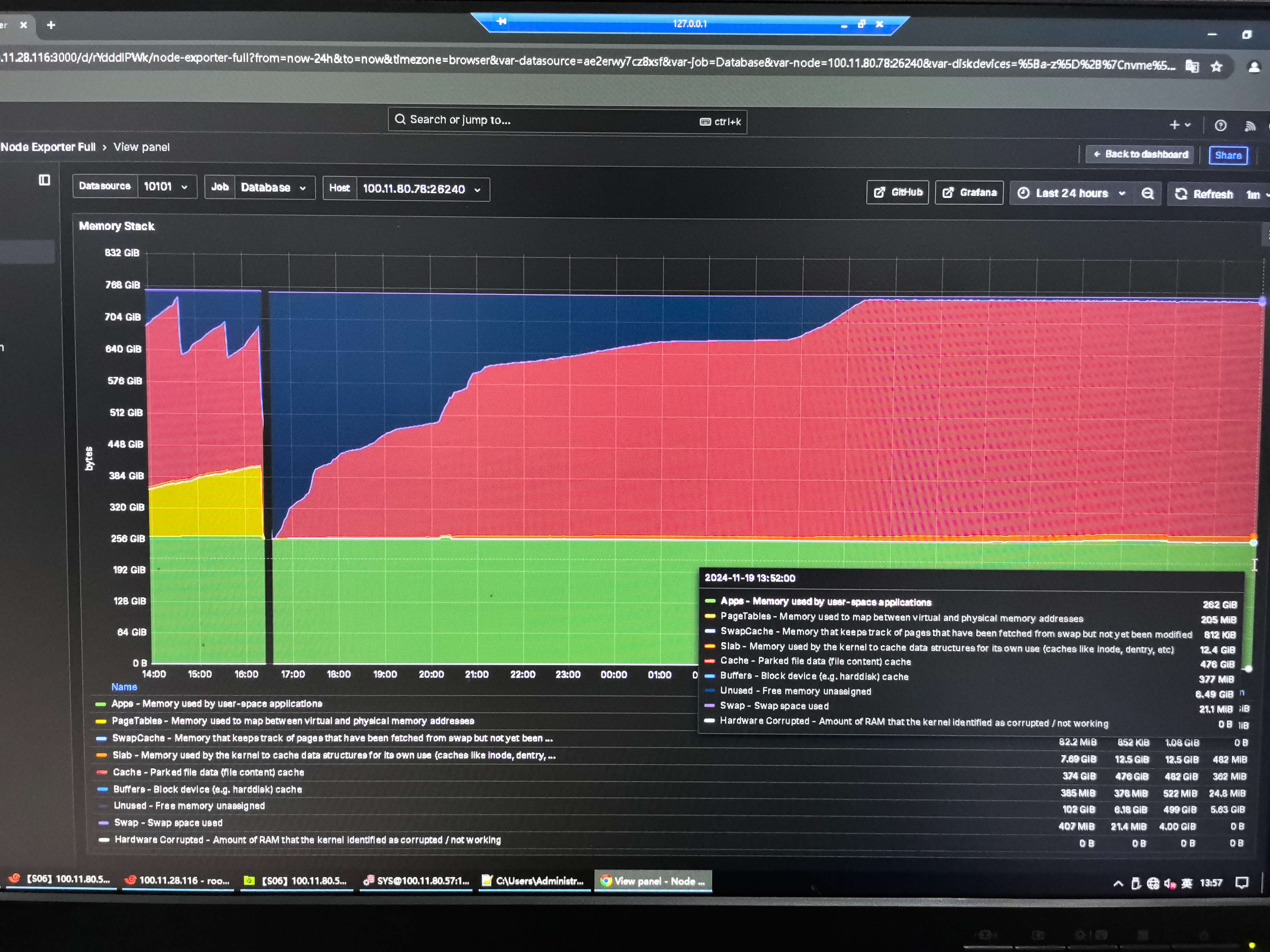
好景不长,现在是每隔2天就还会出现服务器卡死的情况。查询数据库卡死时的内存值:
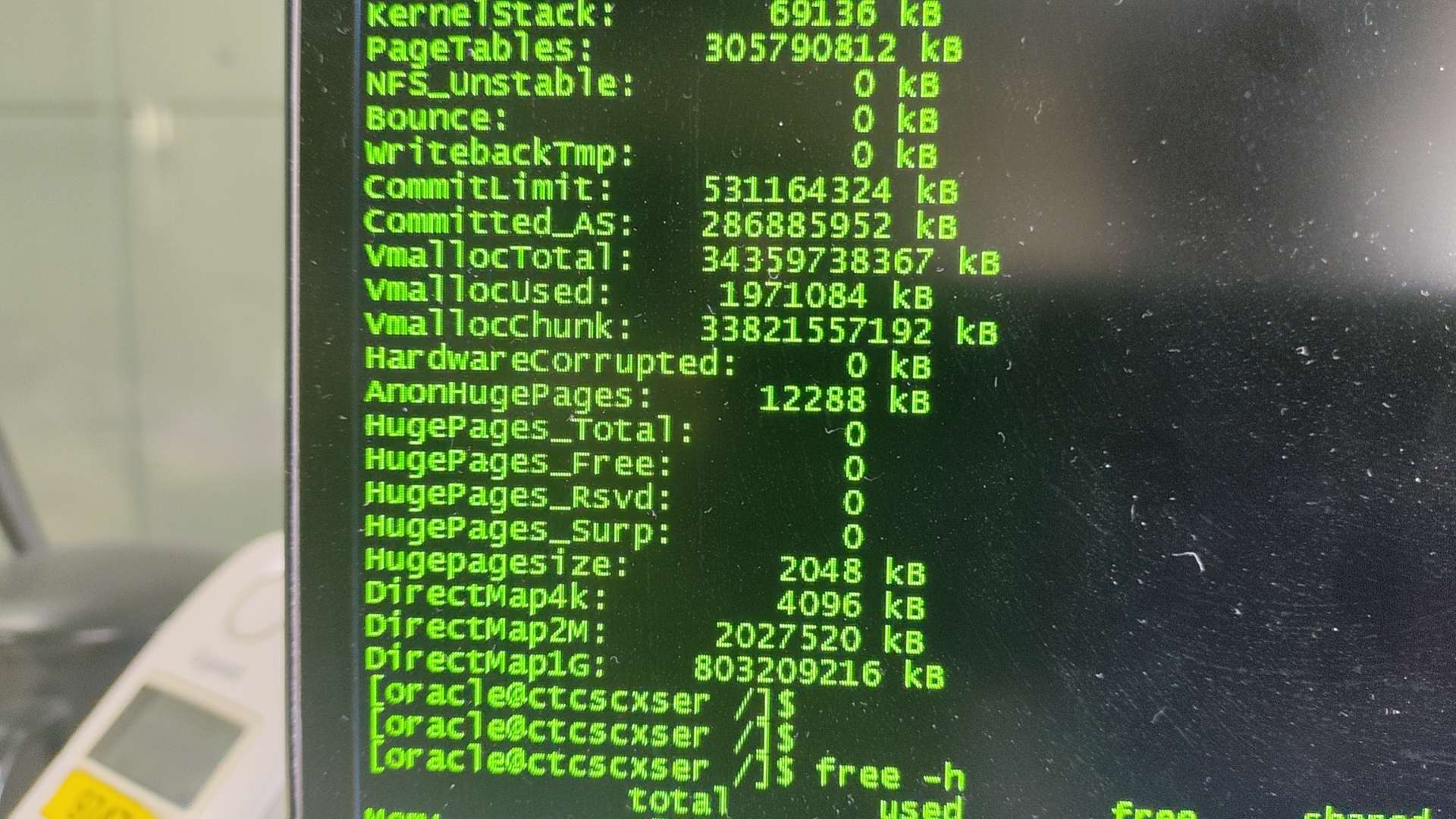
pagetables已经使用了305G左右,得亏服务器是757G内存,要不然根本撑不过1天。。
为什么pagetables大会导致服务器卡死
一个进程 PageTables 大小计算
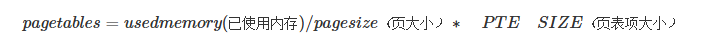
Linux系统 可以通过以下指令查看默认内存页大小,默认为4KB
$ getconf PAGESIZE //4096复制
通过计算公式可以得知,通过增加页大小,可以有效减少pagetables占用内存大小。
以Oracle服务器为例子,一般SGA设置会比较大,假定设置为64GB,且没有设置大页内存,按照默认内存页为4KB,64位操作系统页表项大小为(PTE) 8B,那么一个进程占用的PageTables的大小为
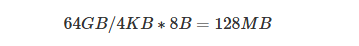
在实际生产环境中,Oracle数据库的链接进程比较多,每个进程都有自己的页表,如果每个进程都用到SGA的全部内存,那么按照上面计算,假设由100个进程,那么页表占用的内存空间就会达到12.8G
因此在大量session的情况下,就会产生大量的PageTables,并且pagetables里面的内容无法共享,因此每分配一个进程就会历遍一次pagetables。所以,实际上进程超过200以后,每个进程分配的pagetables会逐渐增大。
开启了大页为什么占用内存就少
1.Oracle使用大页可以减少页表占用内存大小,同时每个进程的pagetables会共享。
2.在TLB容量固定的情况下,提高TLB的命中率。大页2MB,同样大小的内存,换成4KB大小页,需要512项TLB条目。
3.减少了页表级数,也可以减少查找页表的时间。大页使得页表级数减少,例如原来多达4级的页表可以减少到2级。查找时间会改善。
4.减少缺页异常(page fault)的发生次数。系统按页大小为单位加载内存,2MB,大页只需要一次异常缺页就可以加载,而4KB需要512次缺页异常才能将2MB全部映射到物理内存。这也减少IO次数。
问题解决
通过上面的分析,解决服务器卡死的唯一方法就是开启大页,但通过了解,之前的DBA设置参数后操作系统并未使用参数,有可能是国产操作系统本身的问题。通过查看MOS文档中有相关的配置大页不生效的现象。
When a process uses some memory, the CPU is marking the RAM as used by that process. For efficiency, the CPU allocate RAM by chunks of 4K bytes (it's the default value on many platforms). Those chunks are named pages. Those pages can be swapped to disk, etc. Since the process address space are virtual, the CPU and the operating system have to remember which page belong to which process, and where it is stored. Obviously, the more pages you have, the more time it takes to find where the memory is mapped. When a process uses 1GB of memory, that's 262144 entries to look up (1GB / 4K). If one Page Table Entry consume 8bytes, that's 2MB (262144 * 8) to look-up. Most current CPU architectures support bigger pages (so the CPU/OS have less entries to look-up), those are named Huge pages (on Linux), Super Pages (on BSD) or Large Pages (on Windows), but it all the same thing. 1: [root@gsp cdrom]# id oracle 2: uid=501(oracle) gid=501(oinstall) groups=501(oinstall),502(dba) 3: [root@gsp cdrom]# more /proc/sys/vm/hugetlb_shm_group 4: 0 5: [root@gsp cdrom]# echo 502 >/proc/sys/vm/hugetlb_shm_group复制
因此我也进行了相关的配置,重新把vm.nr_hugepages参数和memlock的限制打开后,重启服务器,大页启用了,同时服务器的pagetables减低到210M,卡死的问题彻底解决。
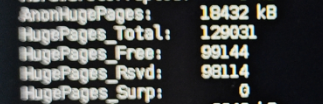
通过监控查看pagetables已经持续稳定(黄色为pagetables大小)