




1 说明
值班的时候接收到某核心库节点连接数较高告警,上去查看等待事件挺正常,顺便查一下topsql,其中一个语句占用了大量cpu资源。

常用脚本都放在了 5 常用脚本 ,如需,自取。
下面开始进行分析,由于是生产数据,截图经过了脱敏处理,重点在分析方法。
2 分析思路
2.1 基本思路
cpu资源占用比较厉害的语句一般有以下几种:
- 全表扫描
- 低效sql语句
- 排序
- 重复解析
- 高并发
最常见的就是前面两种了,与之再配合上第5项高并发,通常会导致的cpu资源占用较高。
2.2 全表扫描
全表扫描其实挺正常的,不要觉得说走了全表就是错的,还要根据返回的数据量考虑,当返回的数据量比较多,走全表扫描多块读的效率是比走索引单块读高的。
因此,看到全表扫描,就要分析一下全表扫描步骤数据集占整个表的比例,一般建议返回表中总数5%以内的数据,走索引扫描,超过5%走全表扫描。
不过,5%只是一个参考值,适用于大部分场景,具体问题具体分析。
2.3 低效sql
低效sql这个概念听起来比较空旷,因为没有一个具体的解释去定义什么是慢sql,一般是应用测反馈变慢了,或者本来就慢。
一般来说最常见的就是走错执行计划,常见原因有:
- 统计信息过期
- 索引失效或缺少合适的索引
- 表连接顺序不对
- sql写法
3 分析过程
3.1 查看sql基本信息
一、sqltext
根据sql_id查gv$sql视图,获取执行实例id、sql_text和plan_hash_value等。
可以看到,此sql是个查询语句,比较简单的单表查询,使用了绑定变量。

下面是经过脱敏后的sql_text:
select t.*
from lu9up.tab01 t
where :"SYS_B_0" = :"SYS_B_1"
and hand_notes = :"SYS_B_2"
and mod(PS_ID, :"SYS_B_3") = :"SYS_B_4"
and rownum <= :"SYS_B_5"
order by t.create_date, t.ps_id
注意:实例5上执行的,后面步骤登录实例5排查,要不然执行计划查不到。
二、当前会话和等待事件
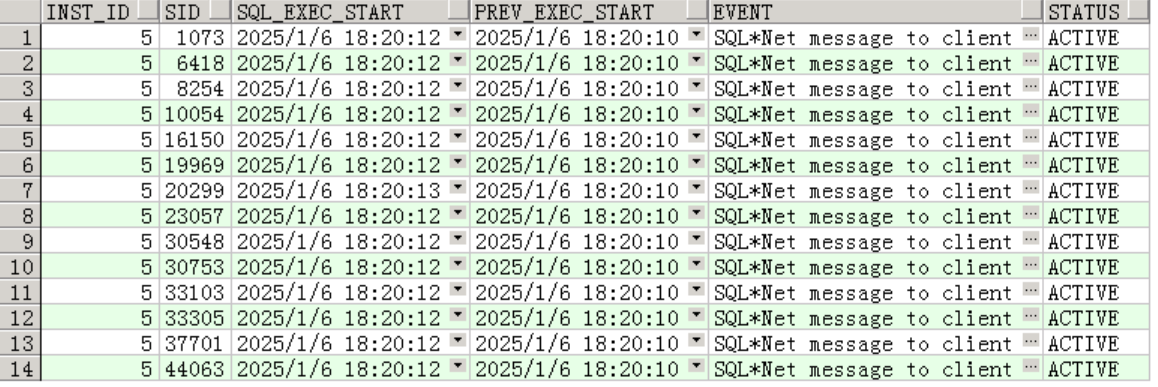
查gv$session,获取sid、执行时间、当前等待事件和会话状态。
有14个会话同时在执行,上一次执行时间是2秒前,并发量不少。当前等待事件正常:SQL* NET message to client。
三、每个快照内 sql执行统计
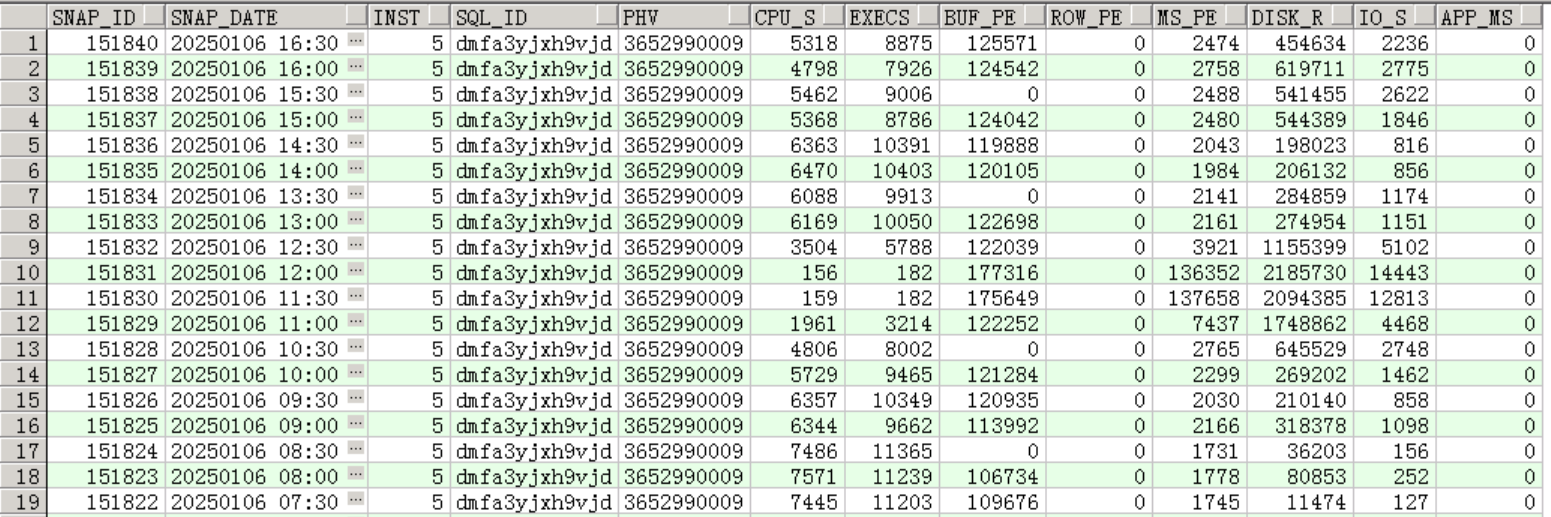
查dba_hist_sqlstat,统计每个快照时间内cpu耗时、执行次数、平均返回行数、平均执行时间等。
语句执行次数较多,每分钟300+次,cpu占用较高,但是返回行数为0?怀疑是统计信息过期或者表为空。
四、历史等待事件汇总
查看gv$active_session_history视图,有严重的gc等待,当一个实例需要访问另一个实例缓冲区中的数据块时,如果该数据块正在被其他进程使用(例如,正在被修改或读取),也就是数据块争用,则会触发 “gc buffer busy acquire” 等待事件。
目前来看,判断是并发量高以及sql执行缓慢引起的等待。

五、sql执行性能汇总
查看gv$sql视图,汇总平均执行时间、平均cpu占用时间、平均返回行数、总执行次数等。
语句平均执行时间2秒,平均cpu占用0.642秒,总执行次数436879,每天执行2万次。。。

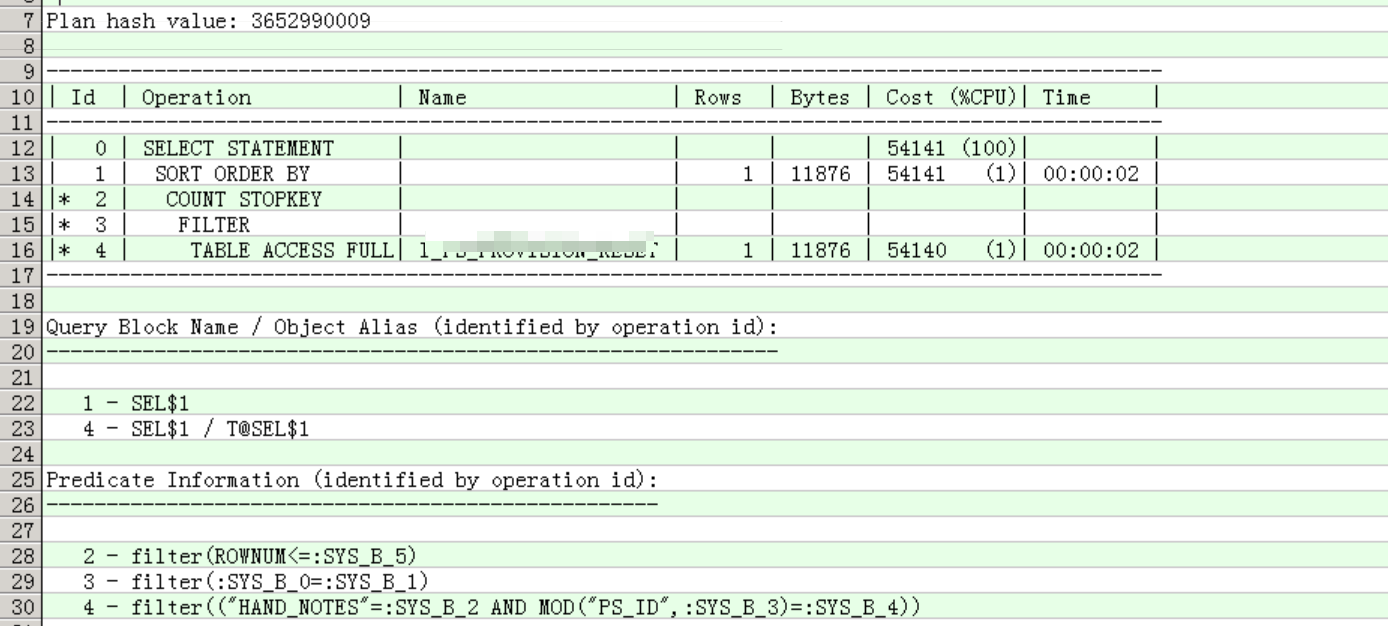
3.2 查看执行计划
使用dbms_xplan包和sql monitoring report查看真实的执行计划。走了全表扫描,返回数据预估1条,实际0条,开销比较大54141,执行时间是37s,其中io等待占6.95秒,集群等待占28秒,时间基本都花在这两个上面了。
dbms_xplan包:
sql_monitor:
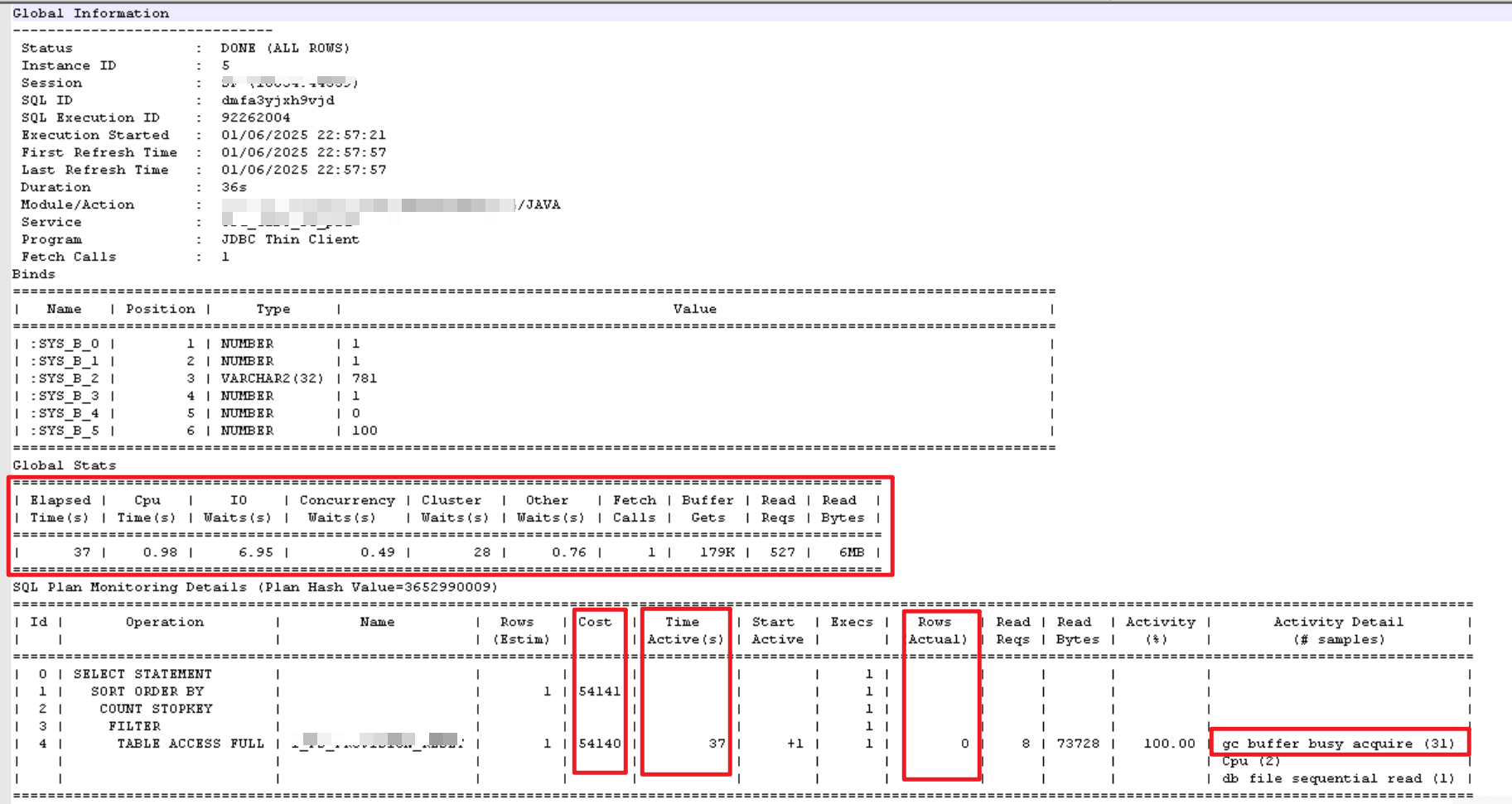
根据monitor report将变量值代入:
select t.*
from lu9up.tab01 t
where 1 = 1
and hand_notes = 782
and mod(PS_ID, 1) = 0
and rownum <= 100
order by t.create_date, t.ps_id
3.3 查看统计信息
一、表
统计信息未过期,空表。

二、索引
索引的统计信息也没过期,索引字段是ps_id,不少唯一索引。
这个索引对于此sql无效,因为相关谓词条件是mod(PS_ID, :“SYS_B_3”) = :“SYS_B_4”,这种写法本身返回的数据量就会很大,并且函数内部使用了绑定变量,索引并不好创建。



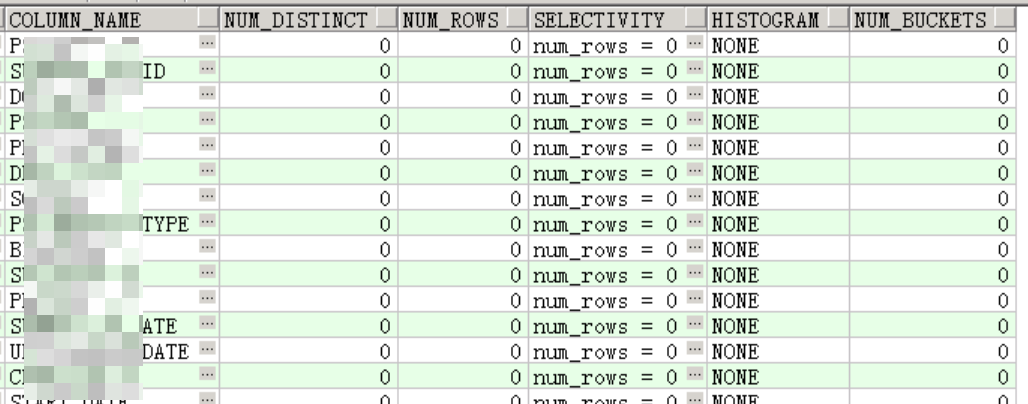
三、字段选择性
空表,无有效信息。
3.4 查看高水位
高水位未下降,这就是为什么空表但是查询性能缓慢的原因了,是一个优化项。

4 优化方法
根据前面的分析数据,此sql虽然是空表,但由于高水位的原因,执行效率比较低,且高并发,导致不必要的buffer被请求访问,增加了buffer busy的机会,造成了有严重的gc等待,数据块争用占用了比较多的cpu资源。
因此,需要想办法提升sql的执行效率,减少数据块争用,降低gc等待,减轻系统负担,降低占用资源。
4.1 降低高水位
一、空表
空表直接用truncate table的方式能够快速降低高水位。本次案例的表为空,因此可以采取此办法:
truncate table lu9up.tab01;
二、非空表
如果遇到了非空表,则需要将表move来降低水位线:
--在原来表空间内move
alter table lu9up.tab01 move;
--move到其他表空间(tbs02为其他表空间)
alter table lu9up.tab01 move tablespace tbs02 parallel 8;
需要注意的地方:
- move 需要额外(一倍)的空间。
- move 过程中会锁表,其他用户不能在该表上做 DML 或 DDL 操作。
- move 之后,相关索引都不可用了,表上的索引需要重建。
索引重建:
alter index lu9up.ind_ps_id rebuild online parallel 8 nologging;
alter index lu9up.ind_ps_id noparallel;
4.2 创建合适索引
由于表是空的,不知道具体的数据是怎么样的,当有新数据进来后,可以尝试创建以下组合索引:
create index lu9up.ind_hand_notes on lu9up.tab01(hand_notes,create_date,ps_id) parallel 8 nologging;
alter index lu9up.ind_hand_notes noparallel;
如果没有效果,删了便是。。。
索引测试小技巧:可以先在我们个人用户下ctas创建相同的测试表,然后基于此测试表创建索引去验证性能。因为在生产环境,不能随便给业务表创建索引,我们经过充分测试后,再交由应用测验证后,才能执行索引的创建,生产创建索引的动作最好也是应用测执行。
4.3 应用优化
gc等待在RAC数据库,同一数据在不同数据库实例上被请求访问。建议不同的应用功能/模块数据分布在不同的数据库实例上被访问,避免同一数据被多个实例交叉访问,可以减少buffer的争用,避免gc等待。
即在rac集群中多创建几个service(服务),每个service就单独配置在一个实例上,不要配置多个实例,要不然依旧解决不了gc的问题。这样,某个应用程序就会集中访问某个实例,可以避免跨实例的buffer的争用。但是也要注意service的分配均衡的问题。
5 常用脚本
--0 topsql 分钟
select ash.sql_id,
sum(decode(ash.session_state,'on cpu',1,0)) "cpu",
sum(decode(ash.session_state,'waiting',1,0)) -
sum(decode(ash.session_state,'waiting',decode(en.wait_class,'user i/o',1,0),0)) "wait",
sum(decode(ash.session_state,'waiting',decode(en.wait_class,'user i/o',1,0),0)) "io",
sum(decode(ash.session_state,'on cpu',1,1)) "total"
from v$active_session_history ash,v$event_name en
where sql_id is not null
and en.event# = ash.event#
and ash.sample_time > sysdate -&min/(24*60)
group by ash.sql_id
order by total desc;
--1 sql_text
select * from gv$sql where sql_id = '&sql_id';
--2 当前会话和等待事件
select inst_id,sid,sql_exec_start,prev_exec_start,event from gv$session where sql_id = '&sql_id' order by sid;
--3 每个快照内 sql执行统计
select a.snap_id,
to_char(b.end_interval_time, 'yyyymmdd hh24:mi') as snap_date,
a.instance_number as inst,
sql_id,
plan_hash_value as phv,
round((cpu_time_delta) / 1e6) as cpu_s,
(executions_delta) as execs,
round((BUFFER_GETS_DELTA) / greatest((executions_delta), 1)) as Buf_pe,
round((ROWS_PROCESSED_DELTA) / greatest((executions_delta), 1), 1) as Row_pe,
case
when (ELAPSED_TIME_DELTA) / 1e3 / greatest((executions_delta), 1) < 1 then
round((ELAPSED_TIME_DELTA) / 1e3 / greatest((executions_delta), 1),
2)
else
round((ELAPSED_TIME_DELTA) / 1e3 / greatest((executions_delta), 1))
end as ms_pe,
round((DISK_READS_DELTA)) as DISK_R,
round((IOWAIT_DELTA) / 1e6) as IO_s,
round((APWAIT_DELTA) / 1e3) as App_ms
from dba_hist_sqlstat a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.instance_number = b.instance_number
and b.end_interval_time > sysdate - &min/(24*60)
and sql_id = '&sql_id'
and a.instance_number = 6
order by snap_id desc;
--4 历史等待事件汇总
select *
from (select inst_id, event, count(*) cnt
from gv$active_session_history
where sql_id = '&sql_id'
group by inst_id, event
order by cnt desc)
where rownum <= 5;
--5 历史执行计划,需要在sql执行的实例查看
select * from table(dbms_xplan.display_awr('&sql_id',format=>'all')); --advanced all typical
--6 当前执行计划,需要在sql执行的实例查看
select * from table(dbms_xplan.display_cursor('&sql_id',null,'all')); --advanced all typical
--7 sql monitoring report,需要在sql执行的实例查看
select dbms_sqltune.report_sql_monitor(sql_id => '&sql_id',type => 'html') from dual;
--8 历史sql执行性能汇总
SELECT ROWNUM as rn,
t.plan_hash_value,
TO_CHAR(t.avg_elapsed_time_secs, '9999990D990') as avg_etime_s,
TO_CHAR(t.avg_cpu_time_secs, '9999990D990') as avg_cpu_s,
TO_CHAR(t.avg_user_io_wait_time_secs, '99999999999990D990') as avg_iowait_s,
t.avg_buffer_gets as avg_buffers,
t.avg_disk_reads as avg_reads,
t.avg_direct_writes,
t.avg_rows_processed as avg_rows,
t.delta_executions as execs,
t.min_optimizer_cost as min_cost,
DECODE(t.min_optimizer_cost, t.max_optimizer_cost, NULL, t.max_optimizer_cost) as max_cost,
TO_CHAR(t.first_snap_time, 'YYYY-MM-DD HH24:MI:SS') as first_snap,
TO_CHAR(t.last_snap_time, 'YYYY-MM-DD HH24:MI:SS') as last_snap
FROM
(
SELECT /*+ NO_MERGE */
h.plan_hash_value,
ROUND((SUM(h.elapsed_time_delta)/SUM(GREATEST(h.executions_delta, 1))) / 1e6, 3) avg_elapsed_time_secs,
ROUND((SUM(h.cpu_time_delta)/SUM(GREATEST(h.executions_delta, 1))) / 1e6, 3) avg_cpu_time_secs,
ROUND((SUM(h.iowait_delta)/SUM(GREATEST(h.executions_delta, 1))) / 1e6, 3) avg_user_io_wait_time_secs,
ROUND(SUM(h.buffer_gets_delta)/SUM(GREATEST(h.executions_delta, 1))) avg_buffer_gets,
ROUND(SUM(h.disk_reads_delta)/SUM(GREATEST(h.executions_delta, 1))) avg_disk_reads,
ROUND(SUM(h.direct_writes_delta)/SUM(GREATEST(h.executions_delta, 1))) avg_direct_writes,
ROUND(SUM(h.rows_processed_delta)/SUM(GREATEST(h.executions_delta, 1))) avg_rows_processed,
SUM(GREATEST(h.executions_delta, 1)) delta_executions,
MIN(h.optimizer_cost) min_optimizer_cost,
MAX(h.optimizer_cost) max_optimizer_cost,
MIN(s.end_interval_time) first_snap_time,
MAX(s.end_interval_time) last_snap_time
FROM dba_hist_sqlstat h,
dba_hist_snapshot s
WHERE h.sql_id = '&sql_id'
AND h.snap_id = s.snap_id
AND h.dbid = s.dbid
AND h.instance_number = s.instance_number
GROUP BY h.plan_hash_value
ORDER BY 2) t;
--9 当前sql执行性能汇总
SELECT ROWNUM as rn,
t.plan_hash_value,
TO_CHAR(t.avg_elapsed_time_secs, '9999990D990') as avg_etime_s,
TO_CHAR(t.avg_cpu_time_secs, '9999990D990') as avg_cpu_s,
TO_CHAR(t.avg_user_io_wait_time_secs, '99999999999990D990') as avg_iowait_s,
t.avg_buffer_gets as avg_buffers,
t.avg_disk_reads as avg_reads,
t.avg_direct_writes,
t.avg_rows_processed as avg_rows,
t.total_executions as total_exec,
DECODE(t.min_optimizer_cost, t.max_optimizer_cost, NULL, t.max_optimizer_cost) as max_cost,
t.first_load_time,
t.last_load_time,
TO_CHAR(t.last_active_time, 'YYYY-MM-DD HH24:MI:SS') as last_active
FROM (
SELECT /*+ NO_MERGE */
plan_hash_value,
ROUND((SUM(elapsed_time)/SUM(GREATEST(executions, 1))) / 1e6, 3) avg_elapsed_time_secs,
ROUND((SUM(cpu_time)/SUM(GREATEST(executions, 1))) / 1e6, 3) avg_cpu_time_secs,
ROUND((SUM(user_io_wait_time)/SUM(GREATEST(executions, 1))) / 1e6, 3) avg_user_io_wait_time_secs,
ROUND(SUM(buffer_gets)/SUM(GREATEST(executions, 1))) avg_buffer_gets,
ROUND(SUM(disk_reads)/SUM(GREATEST(executions, 1))) avg_disk_reads,
ROUND(SUM(direct_writes)/SUM(GREATEST(executions, 1))) avg_direct_writes,
ROUND(SUM(rows_processed)/SUM(GREATEST(executions, 1))) avg_rows_processed,
SUM(GREATEST(executions, 1)) total_executions,
MIN(optimizer_cost) min_optimizer_cost,
MAX(optimizer_cost) max_optimizer_cost,
MIN(first_load_time) first_load_time,
MAX(last_load_time) last_load_time,
MAX(last_active_time) last_active_time
FROM gv$sql
WHERE sql_id = '&sql_id'
GROUP BY plan_hash_value
ORDER BY 2) t;
--10 表统计信息
select * from dba_tab_statistics where owner = upper('&table_owner') and table_name = upper('&table_name')
--表数据变化情况
select * from dba_tab_modifications where table_owner = upper('&table_owner') and table_name = upper('&table_name');
--重新收集表统计信息
/*
begin
dbms_stats.gather_table_stats(ownname => '&table_owner',
tabname => '&table_name',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'for all columns size repeat', --auto/repeat
no_invalidate => FALSE,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
*/
--11 索引统计信息
select * from dba_ind_statistics where owner = upper('&table_owner') and table_name = upper('&table_name')
--索引字段
select * from dba_ind_columns where table_owner = upper('&table_owner') and table_name = upper('&table_name')
--12 字段统计信息(字段选择性、直方图类型直方图桶数)
select b.owner,b.table_name,a.column_name,a.num_distinct,b.num_rows,
case when b.num_rows = 0 then
'num_rows = 0'
else
round(a.num_distinct / b.num_rows * 100, 2) || '%'
end selectivity,
a.histogram,a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner and a.table_name = b.table_name
and b.owner = upper('&table_owner')
and b.table_name = upper('&table_name');
--13 高水位
select a.OWNER,a.TABLE_NAME,a.TABLESPACE_NAME,a.NUM_ROWS,a.BLOCKS,a.EMPTY_BLOCKS,a.NUM_ROWS * a.AVG_ROW_LEN real_bytes,b.BYTES
from dba_tables a,dba_segments b
where a.OWNER = b.owner
and a.TABLE_NAME = b.segment_name
and a.OWNER = upper('&table_owner')
and a.TABLE_NAME = upper('&table_name');
6 总结
虽然本篇是关于空表sql分析,但是方法都是通用的,适用于其他topsql场景。
