




一.介绍
Elasticsearch 是最近几年非常热门的分布式搜索和数据分析引擎,下文简称ES,ES的核心价值离不开Elastic Stack生态圈,它的使用场景很丰富,ES在被广泛使用在目前的业务领域中,但各个业务产品使用ES的情况不尽相同,不仅使用 ES 实现了大规模的日志平台,也广泛使用ES实现了各个业务场景的图像存储、属性搜索、以图搜图、聚类统计等。本文聚焦在业务以图搜图的场景分享了我们在做图片特征值比对方面的思考和实践,希望能对大家有所启发。
二.背景
以旷视城市物联网为例,某业务产品产生的结构化数据存储在ES的索引中,ES的版本为7.10.2,存在一个使用场景是通过一张图片去搜索相似的图片,后台服务会使用该图片的特征值去结构化数据中进行特征值比对,按照比对分数倒排进行返回,特征值是长度256的float数组,占用的存储大小是1KB左右。
使用三台如下配置的服务器搭建ES集群用来存储业务产品产生的结构化数据,假设数据总量为22亿,数据时间跨度为一年,单台服务器结构化数据量为200万/天,使用图片特征值进行比对的场景时间筛选条件通常是距离当前时间最近的15天内的数据,实测一次图片搜索耗时1分钟左右,服务器配置如下:
内存256GB
Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
HDD 51TB,SSD 480GB
三.优化
3.1一阶段优化
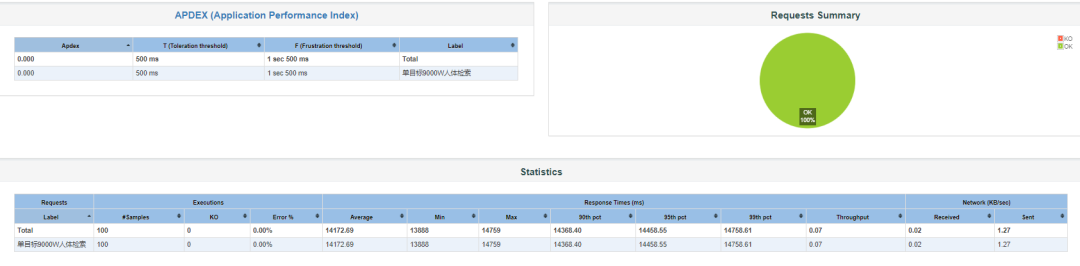
上述场景一次图片搜索耗时1分钟着实有点过长,考虑到搜索数据通常为最近15天内的数据及服务硬件的配置,我们首先想到的是优化方式是将最近15天内的数据作为热数据加载到内存,以提高检索性能,15天数据占用的内存大小为50~60GB,我们将ES启动参数中对内存的上限控制由30GB放大到100GB,重启ES集群,使用Jmeter对以图搜图的接口进行压力测试,接口的平均耗时为14.17秒左右,详情如下:
3.2二次优化
第一次优化后以图搜图的耗时由1分钟变为了14.17秒,为了进一步减少耗时我们结合产品部署形态进行了进一步分析,由于es节点数目足够,写入压力分摊比较小,多分片带来的随机写入io方面的压力可以忽略,我们使用的时机械硬盘,并发写入能力不是很高,直接15分片,检索时调整max_concurrent_shard_requests参数,增加检索并发度这里遇到一个小坑,我们的业务服务使用的开发语言是java,访问ES的客户端是high-level rest client,神奇的是该客户端不支持设置max_concurrent_shard_requests参数,详情见setting-max-concurrent-shard-requests-with-java-client贴子,RestHighLevevelClient部分源码实现如下:
RestHighLevelClient
public final SearchTemplateResponse searchTemplate(SearchTemplateRequest searchTemplateRequest, RequestOptions options) throws IOException {return (SearchTemplateResponse)this.performRequestAndParseEntity((ActionRequest)searchTemplateRequest, RequestConverters::searchTemplate, options, SearchTemplateResponse::fromXContent, Collections.emptySet());}protected final <Req extends Validatable, Resp> Resp performRequestAndParseEntity(Req request, CheckedFunction<Req, Request, IOException> requestConverter, RequestOptions options, CheckedFunction<XContentParser, Resp, IOException> entityParser, Set<Integer> ignores) throws IOException {return this.performRequest(request, requestConverter, options, (response) -> {return this.parseEntity(response.getEntity(), entityParser);}, ignores);}复制
RequestConverters部分源码实现如下:
RequestConverters
static Request searchTemplate(SearchTemplateRequest searchTemplateRequest) throws IOException {Request request;if (searchTemplateRequest.isSimulate()) {request = new Request("GET", "_render/template");} else {SearchRequest searchRequest = searchTemplateRequest.getRequest();String endpoint = endpoint(searchRequest.indices(), searchRequest.types(), "_search/template");request = new Request("GET", endpoint);RequestConverters.Params params = new RequestConverters.Params();addSearchRequestParams(params, searchRequest);request.addParameters(params.asMap());}request.setEntity(createEntity(searchTemplateRequest, REQUEST_BODY_CONTENT_TYPE));return request;}static void addSearchRequestParams(RequestConverters.Params params, SearchRequest searchRequest) {params.putParam("typed_keys", "true");params.withRouting(searchRequest.routing());params.withPreference(searchRequest.preference());params.withIndicesOptions(searchRequest.indicesOptions());params.withSearchType(searchRequest.searchType().name().toLowerCase(Locale.ROOT));params.putParam("ccs_minimize_roundtrips", Boolean.toString(searchRequest.isCcsMinimizeRoundtrips()));if (searchRequest.getPreFilterShardSize() != null) {params.putParam("pre_filter_shard_size", Integer.toString(searchRequest.getPreFilterShardSize()));}params.withMaxConcurrentShardRequests(searchRequest.getMaxConcurrentShardRequests());if (searchRequest.requestCache() != null) {params.withRequestCache(searchRequest.requestCache());}if (searchRequest.allowPartialSearchResults() != null) {params.withAllowPartialResults(searchRequest.allowPartialSearchResults());}params.withBatchedReduceSize(searchRequest.getBatchedReduceSize());if (searchRequest.scroll() != null) {params.putParam("scroll", searchRequest.scroll().keepAlive());}}复制
对源码分析可以发现ES的配置参数主要由RequestConverters中的Params保存,由addSearchRequestParams方法进行填充,现有逻辑中并没有把参数设置的口子放出来,我们想要自己设置max_concurrent_shard_requests的值,可以在这部分进行下改造,基本方案确定后我们做了如下patch,首先新增ElasticClientPatch类,对searchTemplate等方法增加一个Map类型的入参,用来传递用户设置的ES参数,增加transfer方法,用来对上述Map类型的入参遍历,将用户设置的ES参数填充到RequestConverters中的Params中,具体实现如下:
ElasticClientPatch
public static <Req extends ActionRequest> CheckedFunction<Req, Request, IOException> transfer(CheckedFunction<Req, Request, IOException> requestConverter,Map<String, String> queryParams) {return req -> {Request request = requestConverter.apply(req);request.addParameters(queryParams);return request;};}public static SearchTemplateResponse searchTemplate(RestHighLevelClient client,SearchTemplateRequest searchTemplateRequest,RequestOptions options,Map<String, String> queryParams) throws IOException {return client.performRequestAndParseEntity(searchTemplateRequest,transfer(RequestConverters::searchTemplate, queryParams),options,SearchTemplateResponse::fromXContent,emptySet());}复制
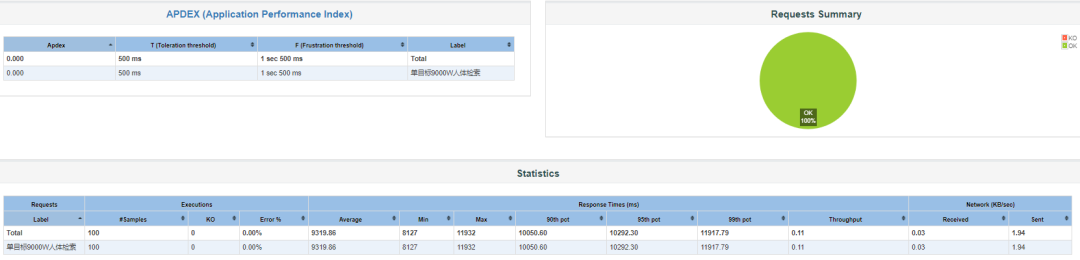
打包后,重新部署使用Jmeter对以图搜图的接口进行压力测试,以图搜图的平均耗时变为了9.32秒左右,详情如下:
3.3第三次优化
第二次优化后以图搜图的平均耗时变为了9.32秒左右,了解ES的同学可能会有一个疑问,即我们如何保证内存中存放的一定是最近15天的数据?假设接口调用者第一次对最近15的数据进行以图搜图,第二次对其它时间段的数据进行以图搜图,就会导致内存中的数据被替换,为了解决上述问题,我们想到的方案是增加锁定内存(mlock)的机制再配合ILM的滚动策略,做到最新的热数据锁定到文件缓存中的能力。ES中索引数据对应多中段文件,包含存储原文_source的文件.fdt .fdm .fdx、存储倒排索引的文件.tim .tip .doc、用于聚合排序的列存文件.dvd .dvm、全文检索文件.pos .pay .nvd .nvm等、加载到内存中的文件有.fdx .tip .dvm,其中.tip占用内存最大,而.fdt . tim .dvd文件占用磁盘最大,详情参见各文件作用解释,文件种类如下:

3.3.1方案一
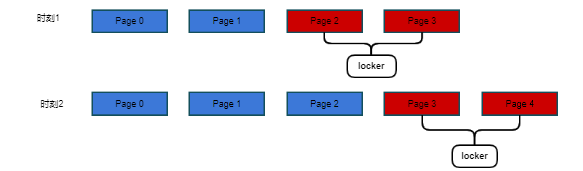
研发一款外挂程序,该程序基于mmap根据预设的规则锁定一定大小的内存,并根据规则进行内存中数据的刷新,示意图如下:
伪代码如下:
方案一伪代码
loop {file = 找到所有需要pin文件缓存的的文件;// 这里open文件,通过libc::mmap/libc::mlock的方式锁住文件缓存hold = MmapInner::map(&file).expect("failed");// 等待到下一次调度sleep(Duration::from_secs(300));// 清理对应的文件句柄 释放mmap和mlock的结果}复制
上述方案的优点是:
采用外挂程序的方式锁定内存,不需要对ES的源码进行改动;
缺点是:
外挂程序对机器资源会有一定的占用,内存读写会产生不可预知错误,且会影响到原产品的部署编排;
3.3.2方案二
剖析ES对文件缓存处理部分的源码FsDirectoryFactory.java中封装的Directory(MMapDirectory/PreloadMMapDirctory)中原有逻辑是并不能释放掉mmap产生的资源,如文件缓存等,我们要做的是在指定的时间内使用这个对象,超出时间范围内可以自动释放资源,结合ES的preload机制,对其进行patch,对dvd文件增加上述机制;
详细设计:
增加配置项
index.store.preload.rolling 是否锁定内存
index.store.preload.interval ,锁定内存多长时间(单位毫秒/按索引创建时间来算)
只锁定preload中设置的文件(当前的feature检索至少得锁定dvd文件)
锁定的时机
每次创建IndexInput对象时根据配置和当前时间,选择是否锁定内存
如果锁定则把当前对象发送到等待释放的队列中
使用jna直接访问mlock
mlock
public interface CLibrary extends Library {Logger LOG = Loggers.getLogger(CLibrary.class, "megvii");CLibrary INSTANCE = Native.load("c", CLibrary.class);int mlock2(Pointer addr, NativeLong len, int flags);int munlock(Pointer addr, NativeLong len);}复制
释放锁定的机制
定时扫描所有的已经mlock的indexinput对象,如果到达deadline或者对象已经被释放,则尝试调用munlock方法,伪代码如下:
ByteBufferIndexInputMlockTool
//锁定的资源信息UNLOCK_INFO = new ConcurrentHashMap<>(16);ScheduledExecutorService service = Executors.newScheduledThreadPool()//释放锁定的处理逻辑tryUnlock()//清除缓存unlockBuffer(Buffer buffer, int len) throws IOException//锁定内存tryMlock(ByteBufferIndexInput input, Deadline deadline)复制
3.3.3 验证
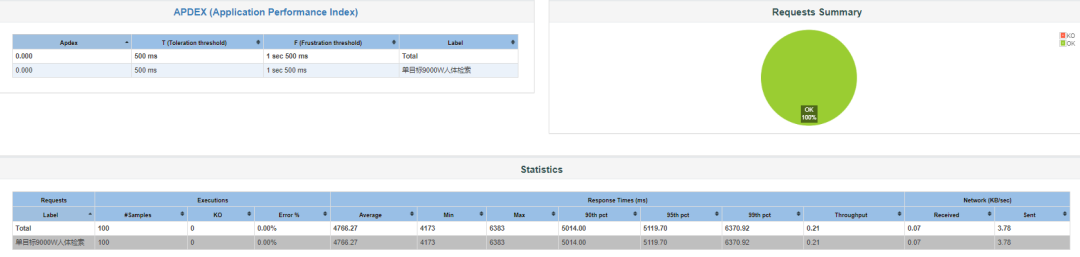
综合评估后,选用方案二进行优化改造,研发完成后打包重新部署,使用Jmeter对以图搜图的接口进行压力测试,以图搜图的平均耗时变为了4.77秒左右,详情如下:
四.进阶
经过三次优化后,以图搜图的性能已经有了显著提升,还有没有进一步优化的空间?关注JDK版本的小伙伴提供了一条信息,JDK16中有一个新特性SIMD,是JDK中配备的一个孵化模块jdk.incubator.vector,用于表达矢量计算编译为所支持的 CPU 架构上的最佳硬件指令。以实现优于同等标量计算的性能。矢量API提供了一种使用Java编写复杂矢量算法的机制,该机制使用 HotSpot 虚拟机中预先存在的支持连同一套用户模型进行矢量化,使其更可预测且更具健壮性。以图搜图过程中feature比对使用的数学公式为
4.1SIMD的几点使用建议
建议结合此Foreign-Memory Access读取文件里的数据,否则可能面临额外的字节拷贝
Foreign-Memory介绍
https://github.com/apache/lucene-solr/pull/2176/files
simd的使用有一定规范,不然会会遇上非预期的性能问题
Basics of SIMD Programming
尽量使用scaler操作,输入输出都是vector的。
类似vector求和的操作,尽量要减少,本次测试的过程中这个成为了性能的瓶颈点。
解决办法是用scaler操作,将需要sum的结果累加到一个vector。最后只做一次sum(我怀疑SIMD的指令中不包含求和操作)
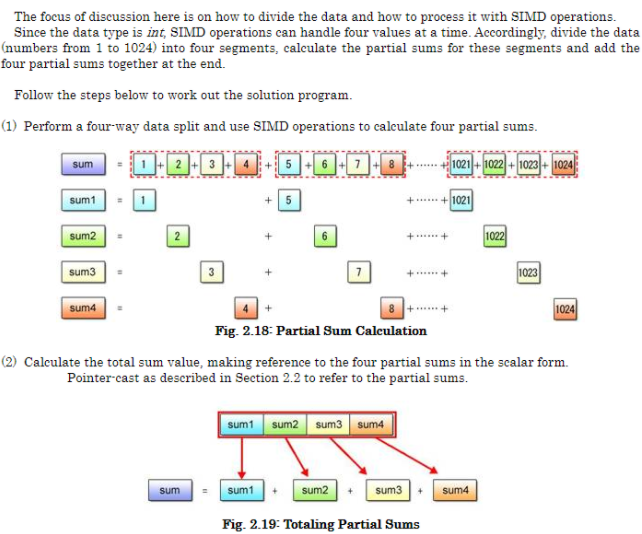
4.2对SIMD特性进行Benchmark
预期的加速效果是:(本次bit256 一次计算8个float)
无simd 需要计算 256减法 256乘法 256次加法 = 768次
有simd 需要计算 32减法 32乘法 32次加法 1次求和(目前按8计算) = 104
带来的加速部分为 768 / 104 = 7 倍
实际带来的加速(scoreOld → score)
纯计算的部分 (0.390 - 0.058) / (0.138 - 0.058) = 4.15
整体 0.390 / 0.138 = 2.82
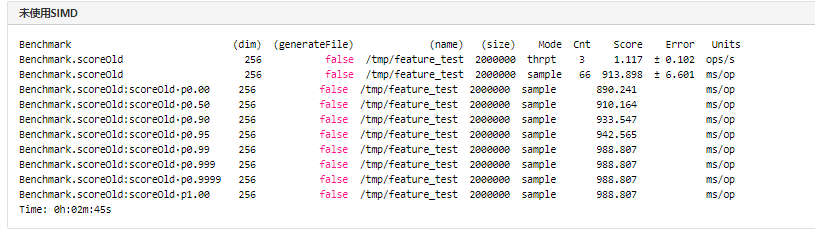
未使用SIMD方式进行测试结果如下:
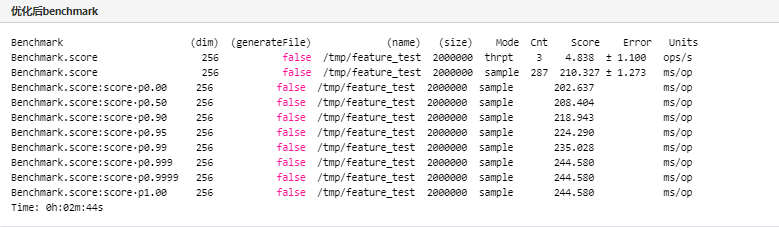
使用SIMD方式、去掉lucene的doc value LZ4压缩、去掉字节拷贝功能,测试结果如下:
4.3 SIMD在ES中的应用
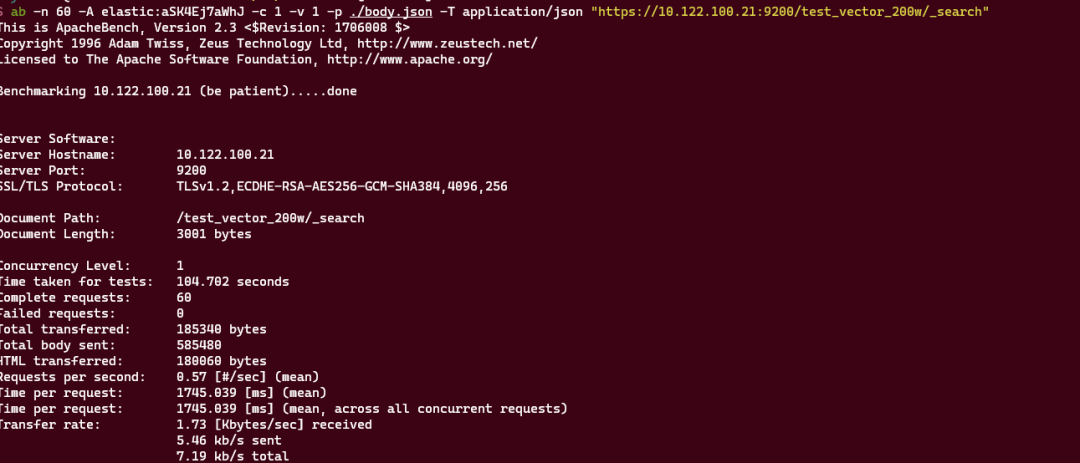
我们通过脚本工具构造了200万的feature数据,填充到ES的索引中,使用ab工具对feature比对接口进行60次请求测试,结果显示60次请求总耗时104.702秒,每秒钟处理0.57次请求,详情如下:
想要在ES使用SIMD特性,首先我们需要基于JDK16对ES进行打包,遇到第一坑:开源ES目使用Gradle 6.x构建的,打包不支持JDK16然而Gradle 6.x 版本不支持JDK16支持的是JDK13,所以需要绕开编译时的问题,解决方式如下:
额外增加个maven模块,依赖luncenes-core 8.7,将foreign和vector功能封装好,编译目标为JDK13。
使用JDK13 编译ES的源码,将ES的Dockefile中的JDK版本替换为JDK16。
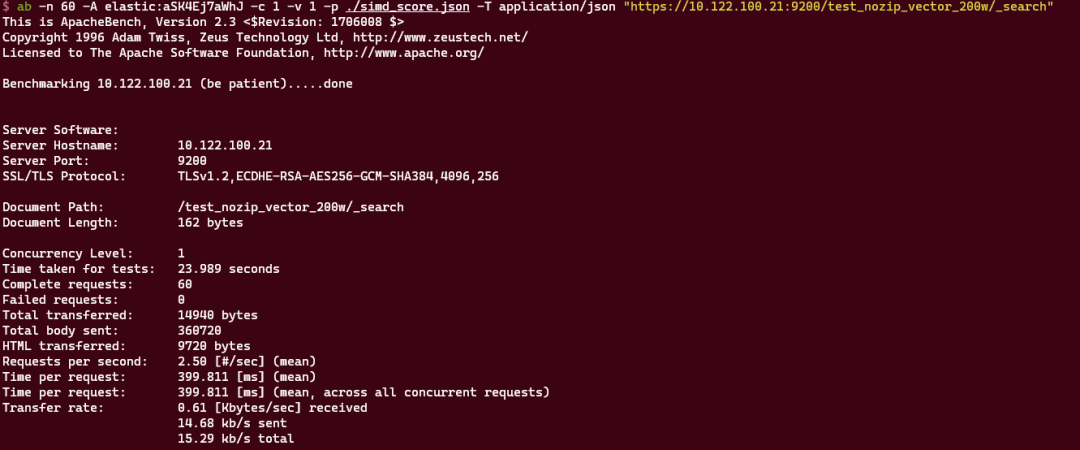
准备工作完成之后,我们使用ab工具对feature比对接口进行测试,使用ab工具对feature比对接口进行60次请求测试,结果显示60次请求总耗时23.989秒,每秒钟处理2.50次请求,详情如下:
五.总结与展望
结合业务产品的特点及ES的特定使用场景,我们对ES进行了几次调优,总体来看带来的性能提升较为明显,将JDK16中的SIMD特性与ES结合也可以显著提成性能,下一步计划对该方案进行稳定性测试及性能压测。
六. 参考文献
Elasticsearch官网资料:
SIMD原理介绍
Jenkins使用手册
Jmeter使用手册
