




说到边缘计算, 顾名思义, 边缘计算的定义里面特指在数据就近的地方进行计算。不同于当下计算在云厂商或IDC的数据中心进行再通过网络协议沟通计算结果。边缘计算的优势是靠近数据的输入端或者用户,从而提供更小的延迟和分散云端服务压力。目前,边缘计算主要被用来与物联网挂钩,因为在当下的基础设施中,靠近用户,承载微型计算任务的场景是典型的物联网应用场景,但是,边缘计算绝不仅仅是为了物联网而定义,在一些场景中,需要多客户多数据中心部署,在共享云端数据的同时确保用户的数据隐私也是边缘计算的一个典型的应用场景,相信在不远的将来,某些场景下边缘托管甚至将演变成一种新的应用交付模式,将越来越多的计算任务分布到靠近用户的一端。
一、当下业务计算的痛点
承载双十一、12306业务的背后是消耗超过十万百万主机规模的庞大应用,而这仍然难以保障高峰期完美的用户体验。业务需要不断的扩大用户规模,更好更优质的使用体验以留住用户, 因此业务所需算力需求也不断提高,数据存储规模持续刷新,成本如同滚雪球一样不断上涨。
用户对于数据安全越来越重视,网络上各种数据泄漏事件,让用户对云服务的信任度下降,一些敏感用户更愿意把数据放进自己的数据中心中,在此同时却又需要云端的共享数据。
光速限定了光纤链路距离与网络延迟的正比关系,所以物理距离所产生的的延迟不可避免。北京到上海 1468 公里,光速:299 792 458 m / s ,一个报文从北京传递到上海一次来回,物理极限起码需要10ms的延迟,更不用说在当下和未来的业务场景中,很可能需要跨越整个中国的业务交互, 而目前国内的网络基建现状是:南北互通、带宽容量、层层NAT之下额外的延迟开销很大。部署在同一个数据中心中的应用自然不会出现这个问题。但是对于跨异地进行业务交互的分布式应用来说, 交互中产生的延迟成本是不能接受的。
二、边缘计算和云计算
边缘计算诞生的主要目的是解决服务的延时、数据隐私的问题。因为涉及到将计算任务下发到边缘进行计算,从概念上说边缘计算在一定程度上也可以说是一种分布式。
若是在边缘就可以完成业务计算,则在避免了延迟的同时对数据也起到了保护的作用。然而,直到2021年的今天, 银行、政府行业对云计算的利用仍处于不信任的阶段。云计算的本质是通过虚拟化技术资源整合虚拟出资源池并再分配, 但是出于数据安全上的考虑,云计算的数据安全在一定程度上来说确实不能保障,理论上说云服务商可以获取所有数据。所以我们有理由相信, 未来一定不会是云计算一统天下, 而是云计算和边缘计算齐头并进。互补共生。云计算具备充足且优质、稳定的基础资源,对于互联网业务来说云计算不可或缺, 但是在网络延迟不能打破物理极限的前提下,边缘计算补充了云计算在延迟和数据隐私问题的短板,此外,边缘计算也在一些特定领域中例如:CDN、物联网具有非常广阔的前景。
三、边缘计算与分布式业务部署
在政企、金融等数据高敏的场景下,用户既需要享受互联网带来的技术创新, 又需要保证数据隐私。用户希望业务数据存放在用户信任的数据中心中,拥有独立入口,同时又想获得利用云端的共享数据配合私有数据进行计算的结果。在边缘自治的同时还能利用云端能力。利用边缘计算来满足数据隐私需求的同时,我们还需要在业务上做支撑并通过云边交互来满足边缘的独立计算。
业务内聚:
尽可能的实现在同一个机房内完成尽可能多的计算任务, 完美的情况下当然是一个操作链路可以在一个数据中心中完成。
在保障一定实时性或这对实时性要求不高的业务功能使用多地缓存技术,将用户操作所需的计算任务尽量归拢在一个数据中心中。
松耦合:
业务解耦,一个模块能够独立完成单一功能。便于缩小边缘部署规模。
通用数据(例如可共享的数据)沉淀为基础能力, 边缘从云端缓存数据,通过缓存做计算。
通用能力:云服务为主,支持租户功能,利用CDN或云分布式WAF产品实现体验上的一致。
云原生技术应用:
统一的资源调度和伸缩,利用kubernetes云原生能力进行统一的资源编排、弹性伸缩调度实现扩展及异常自愈。
边缘自治能力,弱云端依赖。
四、云原生的边缘计算解决方案:Kubeedge vs Openyurt
云原生出现之前,边缘计算因为具备资源广分布、高异构、多碎片的特质,一直因为很高的运维和协同成本而饱受诟病,幸运的是云原生技术出现了,云原生计算基于低开销容器化的运行方式非常契合边缘计算的场景。云原生助力边缘计算,已经收到了广泛的认可。也出现了挺多比较优秀的框架,其中最为火热的就是由华为开源的kubeedge和由阿里云开源的openyurt。
kubeedge 通过定制修改kubernetes的kubelet组件实现了非常低成本的边缘计算方案。kubeedge可以实现将任意一台安装了容器runtime的设备转化为边缘节点的能力。极致轻量,具备很低的资源消耗(内存只需要几十M),非常适用于轻量的,边缘资源受限的场景。
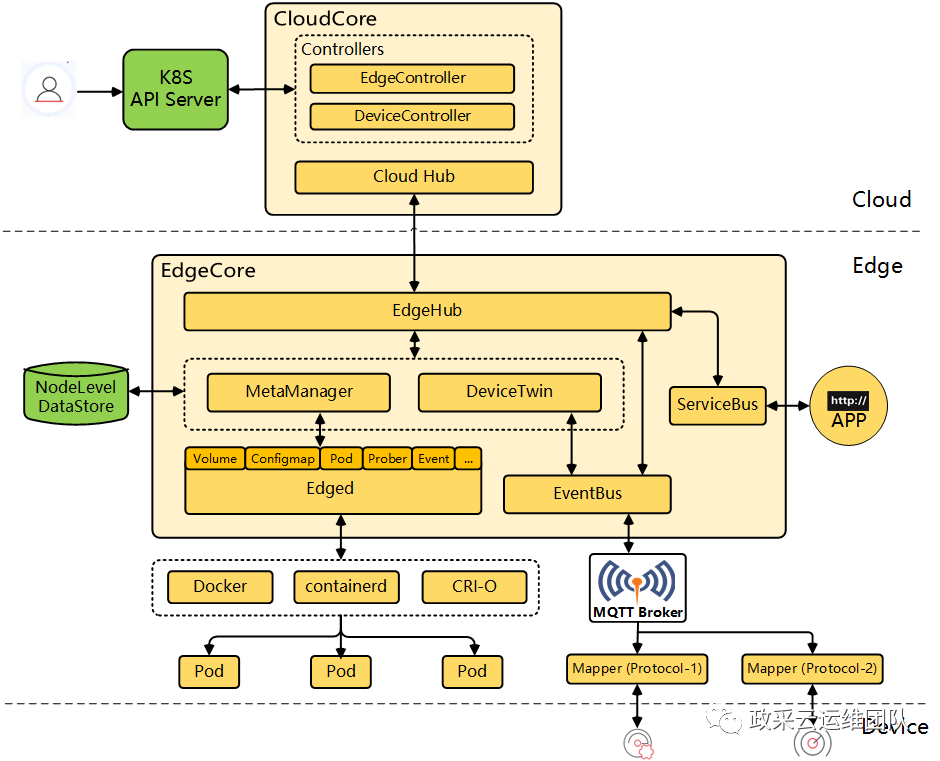
openyurt: 不同于kubeedge, 侵入性的修改了kubelet组件, openyurt是通过在原生的kubernetes之上进行扩展实现的边缘管理能力。且因为没有对kubernetes进行改造所以openyurt几乎不用关注kubernetes的版本升级, 而kubeedge则需要针对版本进行定制修改。openyurt不侵入提供原生kubernetes能力的代价是:资源消耗与kubernetes原生组件一致, 所以不适用于边缘资源受限的场景, 但是适合大型业务交付场景。
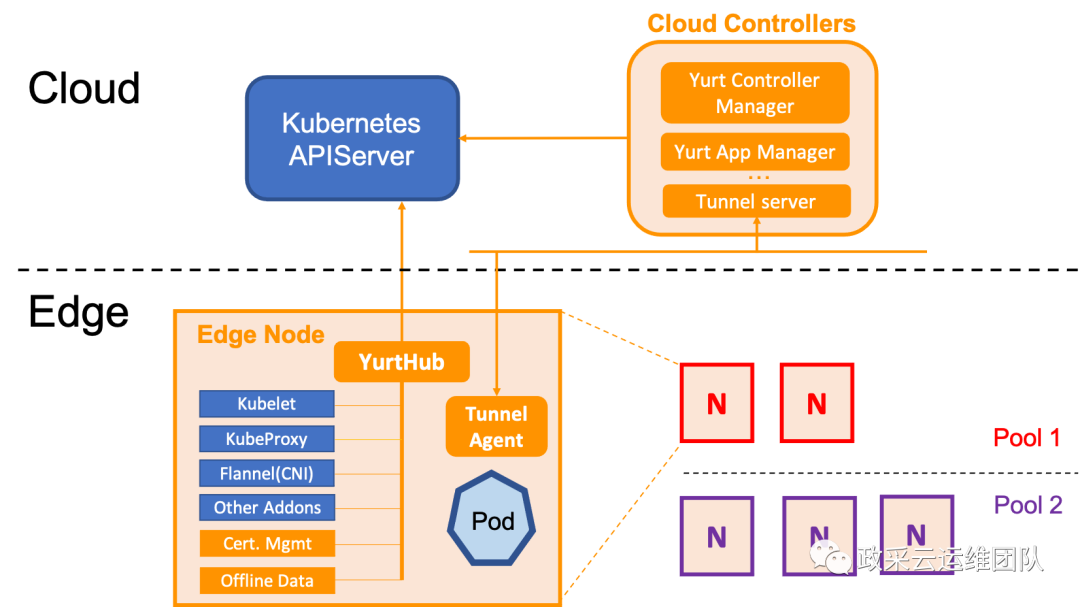
openyurt 所提供的的tunnel网络隧道提供了轻量优雅的云边互通的管理网络方案。
kubeedge vs openyurt
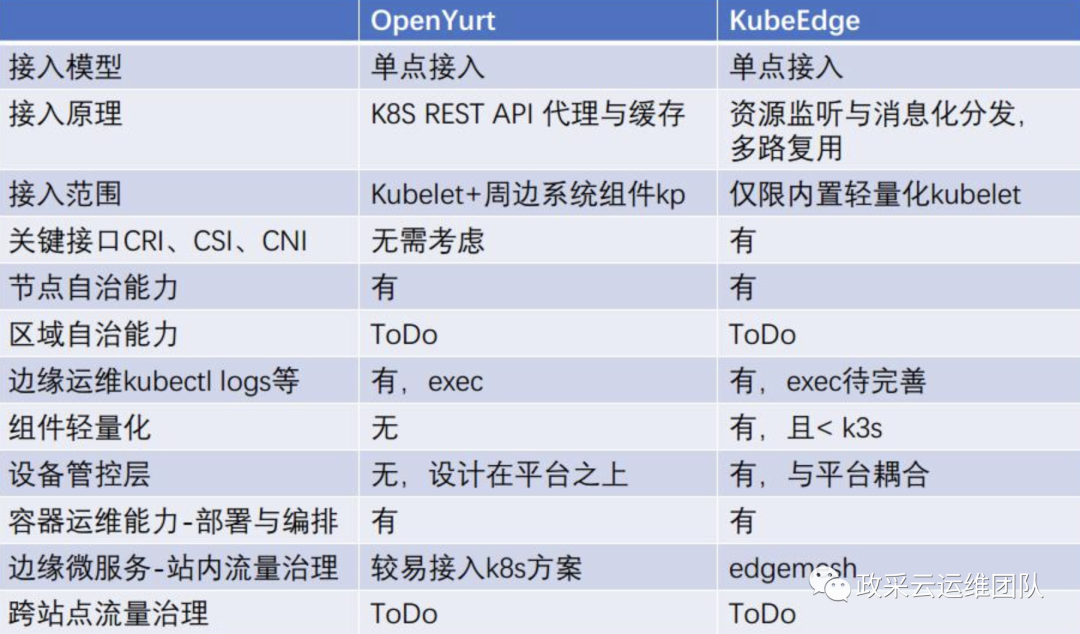
比较来看openyurt 更偏向于分布式数据中心场景,提供完整的原生的kubernetes能力, 不像kubeedge精简严重。
五、云边交互
基于云原生的边缘计算方案解决了管理层面的云边交互问题。通过隧道技术的应用,低成本的实现了在网络受限场景下的云边互通。
在本文的场景中,云端主要是部署在云服务商的数据中心中, 而边缘则通常是指用户自建或合作的数据中心。云端具有完整的能力来为云端的用户提供服务, 而边缘,则应对差异化需求,和数据隐私需求。将部分业务组件部署在边缘, 由边缘独立完成计算任务,此时相对于边缘云端只是作为通用数据和功能的提供者来提供服务。
业务耦合严重的情况下全链路的独立计算会导致边缘的部署规模过于庞大,所以除了业务上要解耦之外,还可以利用数据同步技术保障边缘缓存数据并保障边缘缓存的实时性,然后利用缓存数据进行计算。
虽然边缘计算解决了数据隐私问题,但是无法避免的是当云端需要进行数据计算的情况下,云端获取边缘数据,这又违背了用户数据隐私的需求, 在这种场景下,可以通过远端预设好并下发计算任务,交由边缘来进行计算,也可以利用安全计算技术,在不接触明文的情况下完成计算。
云边协同中, 网络是无法绕开的一环,运维管理通道可以通过边缘计算的云原生框架所提供的的隧道功能来解决, 但是业务上,一旦需要云边交互仍无法绕开高延迟问题,此时只能利用公网、专线、VPN等方案确保云边互通。非敏感数据可以直接通过公网进行传输,敏感数据可以通过公网加密传输或者通过专线或者VPN隧道来传输。
六、总结
在云端业务+ 边缘业务的混合场景下, 边缘计算具有广阔的应用场景,边缘计算很好的解决了计算延迟、数据隐私的问题。结合云原生技术,实现云边一体的管理方案。非常适用于大规模,多边缘的业务场景。openyurt作为无侵入, 边缘计算和普通kubernetes之间自由切换的特性很适合作为大规模业务边缘交付的场景, 而kubeedge更适用于小规模交付和物联网场景。
