





导读
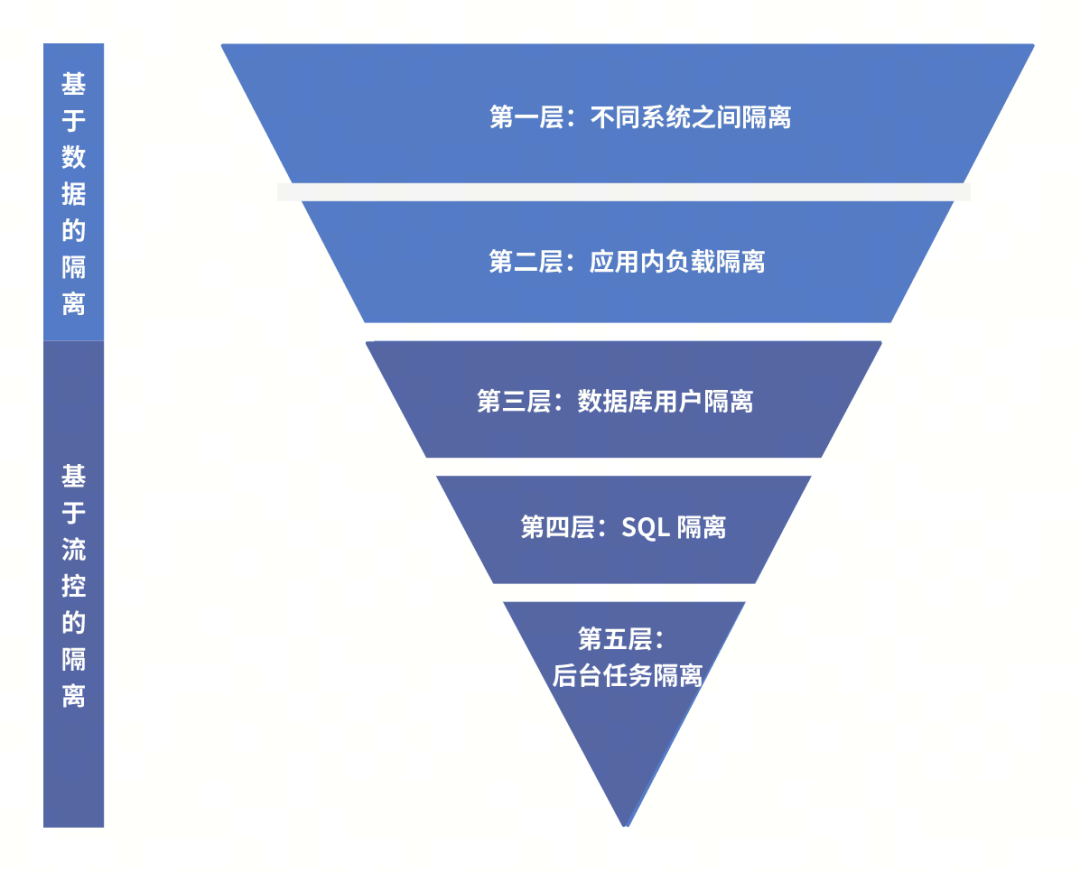
资源隔离是数据库性能优化的重要环节,TiDB 在当前版本已经实现了从数据级隔离到流控隔离的全面升级,无论是多系统共享集群、复杂负载隔离,还是小型系统整合和 SQL 精细化控制,TiDB 都提供了灵活且高效的解决方案。
本文以实际案例为切入点,详细解读了 Placement Rules in SQL、Resource Control 等关键功能,以及 7.2+ 版本新增的 Runaway Queries 管理机制,帮助各位开发者和管理员选择最适合自己的 TiDB 资源隔离方案。

1. 你需要什么样的隔离?
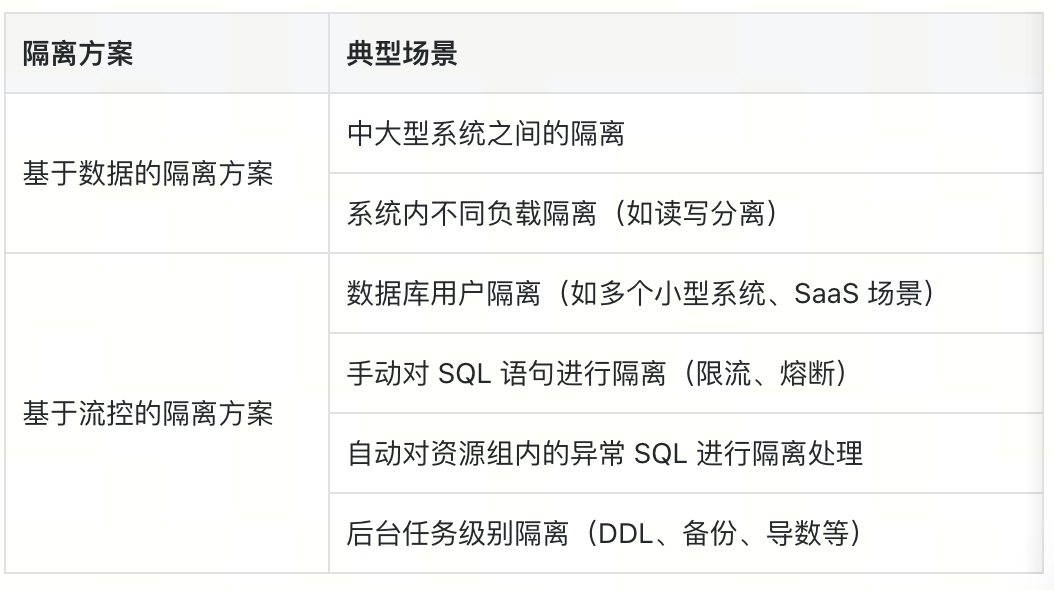
2. 基于数据的隔离方案
2.1 中大型系统之间隔离
2.2 系统内不同负载隔离
3. 基于流控的的隔离方案
3.1 数据库用户隔离
3.2 SQL 语句级别隔离
3.3 后台任务级别隔离
4. 总结


2.1 中大型系统之间隔离

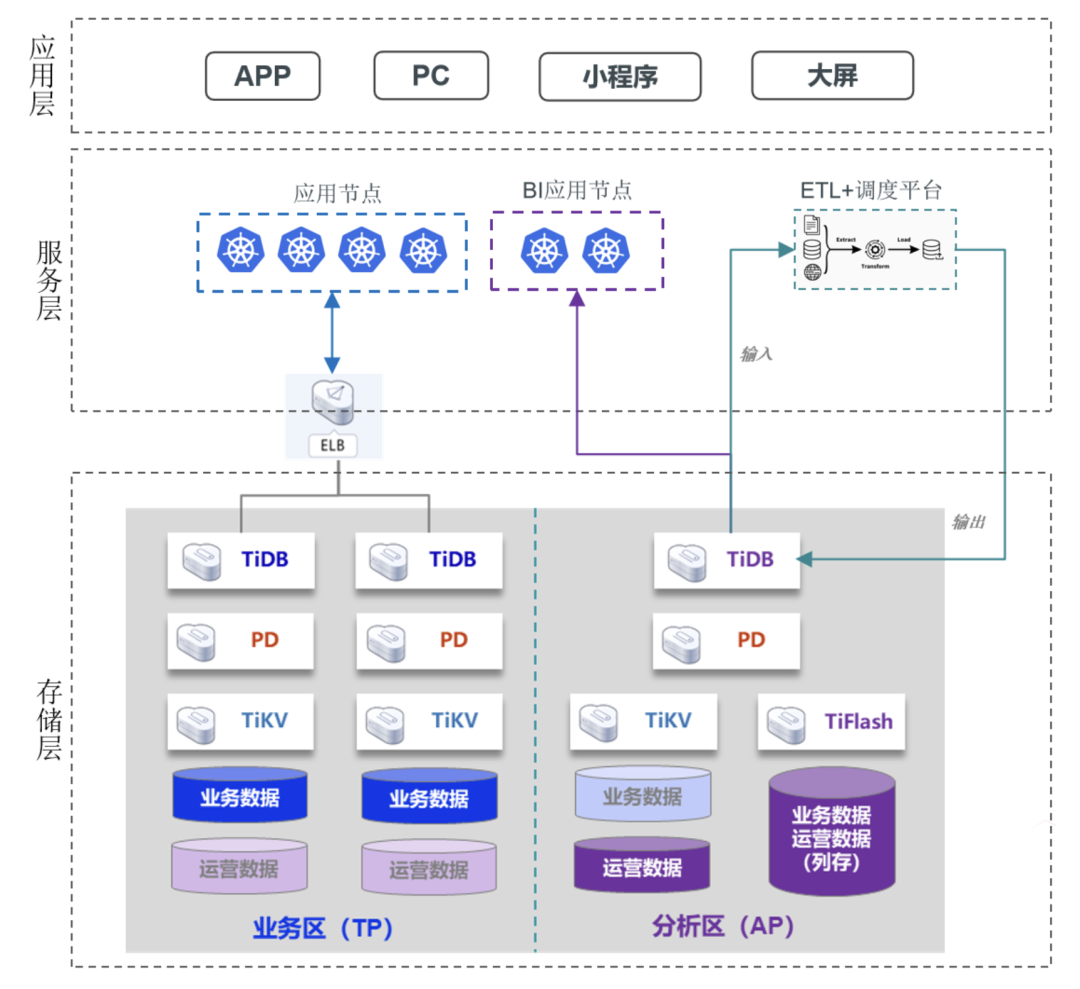
典型客户案例:TiDB x 云盛海宏丨加速精细化运营,云海零售系统的架构演进
示例:Placement Rules in SQL 规则(适合中大型系统)
create placement policy policy_order constraints="[+zone=order]";
create placement policy policy_inv constraints="[+zone=inventory]";
alter database retail_order placement policy policy_order;
alter database retail_inventory placement policy policy_inv;

create placement policy policy_server1 leader_constraints="[+host=host1]";
create placement policy policy_server2 leader_constraints="[+host=host2]";
create placement policy policy_server3 leader_constraints="[+host=host3]";
alter database DB1 placement policy policy_server1;
alter database DB2 placement policy policy_server2;
alter database DB3 placement policy policy_server3;
Placement Rules in SQL 规则(针对业务数据,Leader 分布在前两台 TiKV);
create placement policy policy_eyas leader_constraints="[-zone=zone3]";
alter database eyas placement policy policy_eyas;
Placement Rules in SQL 规则(针对运营数据,Leader 分布在第三台 TiKV);
create placement policy policy_bi leader_constraints="[+zone=zone3]" follower_constraints ='{"+zone=zone1": 1,"+zone=zone2": 1}';
alter database bi_eyas placement policy policy_bi;
alter database da_ping placement policy policy_bi;
alter database eyasbi placement policy policy_bi;
业务库+运营库均增加列存副本; TiDB 设置就近读。
set global tidb_replica_read = 'closest-replicas';

Placement Rule 规则(设置全局 Leader 和 Follower 分布策略),机房 q03 不分布任何 Leader,同时 q03 机房进行本地读取;
[
{
"group_id": "pd",
"id": "q01",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 1,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["q01"]}
],
"location_labels": ["host"]
},
{
"group_id": "pd",
"id": "q02",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 1,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["q02"]}
],
"location_labels": ["host"]
},
{
"group_id": "pd",
"id": "q03",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 1,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["q03"]}
],
"location_labels": ["host"]
}
]
TiDB 设置就近读。
set global tidb_replica_read='closest-replicas';

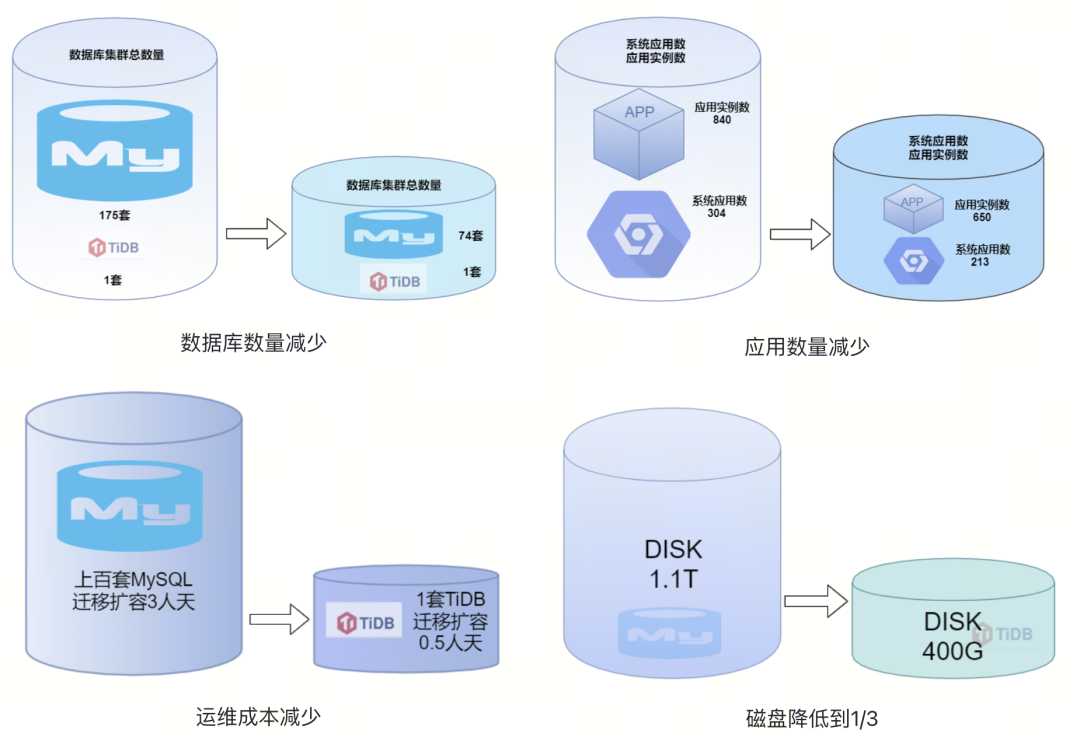
数据需要与存储节点进行绑定(也就是资源的最小单位是节点),该方案仅适用于中大型系统之间的隔离,基本不适应于小型系统
在扩缩容时,该方案可能需要迁移底层数据,无法立即生效
如果集群中仅有一套库表供多个系统共享,此时基于数据的隔离方案便无法工作了
将 CPU、IO、网络等资源统一抽象为资源单位(RU),大幅简化对资源的定义
提供数据库用户、SQL 语句、后台任务等三个层面的资源隔离
在扩容或缩容时,资源调整可以秒级生效,无需迁移数据,提供了极致弹性能力
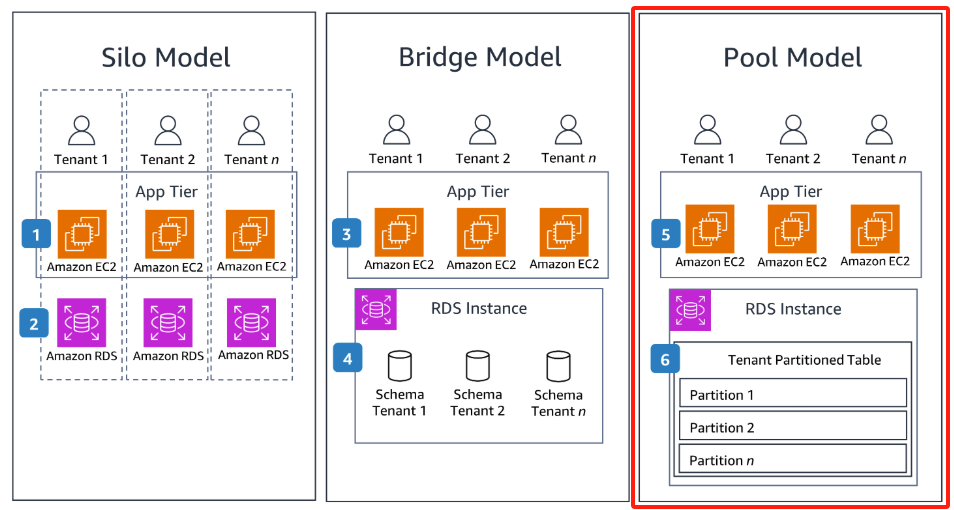

假设租户 1 是体量非常大,可为其单独创建数据库用户 user1,并为该用户创建独立资源组,优先级高,且允许超用;
CREATE RESOURCE GROUP rg_tenant1 RU_PER_SEC = 1000000 PRIORITY = HIGH BURSTABLE;
alter user 'user1' RESOURCE GROUP rg_tenant1;
其他租户由于体量较小,共用一个资源池;
CREATE RESOURCE GROUP rg_tenant_default RU_PER_SEC = 500000 PRIORITY = MEDIUM;
alter user 'user_default' RESOURCE GROUP rg_tenant_default;
扩容。
ALTER RESOURCE GROUP rg_tenant_default RU_PER_SEC = 900000 PRIORITY = MEDIUM;
CREATE USER 'USER_BATCH' IDENTIFIED BY '******';
CREATE RESOURCE GROUP rg_batch RU_PER_SEC = UNLIMITED PRIORITY = HIGH;
alter user 'USER_BATCH' RESOURCE GROUP rg_batch;
-- 假设批量任务超时运行到第二天白天,只需执行如下 SQL 即可立即将其限速
ALTER RESOURCE GROUP rg_batch RU_PER_SEC = 100000 PRIORITY = LOW;
3.2 SQL 语句级别隔离
QUERY_WATCH(手动处理):对发现的 SQL 进行限流或熔断
QUERY_LIMIT(自动处理):当不符合预期的 SQL 出现时,数据库可自己识别、并自适应处理
-- 该 SQL 执行时,单独使用 rg1 资源组执行(rg1 是一个 100 RU 的资源)
SELECT /*+ RESOURCE_GROUP(rg1) */ * FROM t where is_delete=0 and create_time>='2023-01-01';
-- 将 default 资源组中的这条 SQL 进行降低优先级,让其限速执行
QUERY WATCH ADD RESOURCE GROUP DEFAULT ACTION COOLDOWN SQL TEXT EXACT TO 'select * FROM t where is_delete=0 and create_time>='2023-01-01';
另外也可能存在一种情况,系统内突然出现一条之前从未运行过的大 SQL,它来历不明,我希望先直接将其熔断,不让其执行:
-- 根据 SQL DIGEST 维度进行拦截,并终止
QUERY WATCH ADD RESOURCE GROUP default ACTION KILL SQL DIGEST 'd08bc323a934c39dc41948b0a073725be3398479b6fa4f6dd1db2a9b115f7f57';
-- 另外还可以使用 SQL TEXT 维度(可单独拦截某一特定条件值的 SQL)
-- 以及 PLAN DIGEST 维度(可拦截 SQL 中某一很差的计划出现)
3.2.2 典型场景 - 超出预期的查询自适应管理(QUERY_LIMIT)
创建 rg_auto_cooldown 资源组,限额是 100000 RU,我们可以定义该资源组中执行时间超过 60 秒的查询为 Runaway Query,并让系统自动对 Runaway Query 进行降低优先级限流处理;
CREATE RESOURCE GROUP rg_auto_cooldown RU_PER_SEC = 100000 QUERY_LIMIT=(EXEC_ELAPSED='60s', ACTION=COOLDOWN);
创建 rg_over_10000资源组,限额是 100000 RU,我们可以定义该资源组中每秒超过 10000 RU 的查询为 Runaway Query,并让系统自动对他们进行降低优先级限流处理;
CREATE RESOURCE GROUP rg_colldown RU_PER_SEC = 100000 QUERY_LIMIT=(RU=10000, ACTION=COOLDOWN);
还可以在当前资源组,将大型查询隔离到其他资源组执行:定义 default资源组中处理数据行数超过 1000000 的查询为 Runaway Query,并让系统自动将他放到 rg_bigquery资源组中执行,避免与当前资源组中的请求发生争用。
CREATE RESOURCE GROUP rg_bigquery RU_PER_SEC = 10000 PRIORITY = LOW;
-- 假设我当前资源组为 default
ALTER RESOURCE GROUP default QUERY_LIMIT=(PROCESSED_KEYS=1000000, ACTION=SWITCH_GROUP(rg_bigquery));
ALTER RESOURCE GROUP `default` BACKGROUND=(TASK_TYPES='ddl', UTILIZATION_LIMIT=30);

基于 TiDB 资源管控 + TiCDC 实现多业务融合容灾测试
💡 点击文末【阅读原文】,立即下载试用 TiDB!







