




由于本篇文章涉及到的内容比较多,大家先总览下
1.简介
在前面两篇文章中我们分析了配置文件和映射文件的解析流程,相对于mybatis来说就是已经做好了准备了,等着被执行了,而执行过程其实 是一个比较复杂的过程涉及到很多点,包括但不限于
1:为mapper接口生成代理类
2:根据配置信息生成sql,并把我们的参数传递进去
3:一二级缓存
4:插件机制
5:还有一些数据库事务,连接池等
6:还有最后的我们的结果的映射
上面只是sql执行过程中的一部分,下面我们会对其中一些过程进行分析
2.sql执行流程分析
我们在使用sqlSession操作mybatis时我们有几种方式,比如
//mybatis的配置文件
String resource="SqlMapconfig.xml";
//得到配置文件的流
InputStream inputStream = Resources.getResourceAsStream(resource);
//1.创建会话工厂,传入mybatis文件的配置信息
SqlSessionFactory sqlSessionFactory=new SqlSessionFactoryBuilder().build(inputStream);
//2.通过会话工厂得到sqlSession
SqlSession session = sqlSessionFactory.openSession();
//3.通过SqlSession操作数据库
//第一个参数:映射文件中的stamenent的id,等于namespace+"."+stamenent的id
//第二个参数:指定和映射文件中所匹配的parameterType类型的参数
//session.selectOne的结果是与映射文件中所匹配的resultType类型的对象
//查询出一条记录
User user=session.selectOne("test.findUserById", 3);复制
如果按照面向对象的思想,我们经常使用的是下面的方式
mapper接口的方式
UserMapper userMapper = session.getMapper(UserMapper.class);
User user = userMapper.findUserById(3);复制
下面的分析我们会以mapper接口的方式为例,进行分析,在说这个之前,我们看见了我们需要SQLSession,我们先简单说下SQLSession的创建过程
2.1.sqlSession的创建
在说其它过程之前,我们先来分析下SQLSession,SqlSession是Mybatis工作的最顶层API会话接口,所有的数据库操作都经由它来实现,由于它就是一个会话,即一个SqlSession应该仅存活于一个业务请求中,也可以说一个SqlSession对应这一次数据库会话,它不是永久存活的,每次访问数据库时都需要创建它。
因此,SqlSession并不是线程安全,每个线程都应该有它自己的 SqlSession 实例,所以我们千万不要把SQLSession搞成单例的或者静态的,这个会出现事物问题的,所以我们也可以从另外一个方面看,在同一个事物中我们的SQLSession是同一个的
在第一篇文章中我们分析了SQLSessionFacotry的创建过程,大家可以自行去看下,通过SQLSessionFactory的openSession方法,我们可以得到我们的SQLSession,我们来看下相关过程
SqlSessionFactory的类定义
public interface SqlSessionFactory {
SqlSession openSession();
SqlSession openSession(boolean autoCommit);
SqlSession openSession(Connection connection);
SqlSession openSession(TransactionIsolationLevel level);
SqlSession openSession(ExecutorType execType);
SqlSession openSession(ExecutorType execType, boolean autoCommit);
SqlSession openSession(ExecutorType execType, TransactionIsolationLevel level);
SqlSession openSession(ExecutorType execType, Connection connection);
Configuration getConfiguration();复制
我们选择最简单的一个也就是第一个进行分析
public SqlSession openSession() {
//调用重载方法
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
//执行器类型
public enum ExecutorType {
SIMPLE, REUSE, BATCH
}
//事物
public enum TransactionIsolationLevel {
NONE(Connection.TRANSACTION_NONE),
READ_COMMITTED(Connection.TRANSACTION_READ_COMMITTED),
READ_UNCOMMITTED(Connection.TRANSACTION_READ_UNCOMMITTED),
REPEATABLE_READ(Connection.TRANSACTION_REPEATABLE_READ),
SERIALIZABLE(Connection.TRANSACTION_SERIALIZABLE);
//autoCommit 是否自动提交
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//获取环境相关配置
final Environment environment = configuration.getEnvironment();
//创建事物工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
//创建链接管理对象
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//创建执行器(sqlSession执行我们的sql,其实是通过执行器执行的)
final Executor executor = configuration.newExecutor(tx, execType, autoCommit);
//创建SQLSession
return new DefaultSqlSession(configuration, executor);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}复制
我们简单总结下,SQLSession的创建过程
1:从configuration中获取environment
2.从数据源中获取DataSource和TransactionFactory链接管理对象
3.创建执行器(sqlSession其实不是真正干活的,干活的是执行器)
4.创建SQLSession
我们接下来看下SQLSession的实现类
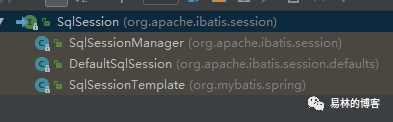
如果我们使用的SqlSessionTemplate,我们在执行业务方法时,最终会执行到
SqlSessionTemplate
//创建SqlSessionTemplate对象
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
notNull(sqlSessionFactory, "Property 'sqlSessionFactory' is required");
notNull(executorType, "Property 'executorType' is required");
this.sqlSessionFactory = sqlSessionFactory;
this.executorType = executorType;
this.exceptionTranslator = exceptionTranslator;
this.sqlSessionProxy = (SqlSession) newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class },
new SqlSessionInterceptor());
}
//执行业务代码
private class SqlSessionInterceptor implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//创建SQLSession
final SqlSession sqlSession = getSqlSession(
SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType,
SqlSessionTemplate.this.exceptionTranslator);
try {
//执行sql
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
Throwable translated = SqlSessionTemplate.this.exceptionTranslator.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType, PersistenceExceptionTranslator exceptionTranslator) {
notNull(sessionFactory, "No SqlSessionFactory specified");
notNull(executorType, "No ExecutorType specified");
SqlSessionHolder holder = (SqlSessionHolder) getResource(sessionFactory);
//开启了事物
if (holder != null && holder.isSynchronizedWithTransaction()) {
if (holder.getExecutorType() != executorType) {
throw new TransientDataAccessResourceException("Cannot change the ExecutorType when there is an existing transaction");
}
holder.requested();
if (logger.isDebugEnabled()) {
logger.debug("Fetched SqlSession [" + holder.getSqlSession() + "] from current transaction");
}
//获取已有的
return holder.getSqlSession();
}
if (logger.isDebugEnabled()) {
logger.debug("Creating a new SqlSession");
}
//sqlSession是第一次创建(创建代码上面分析了)
SqlSession session = sessionFactory.openSession(executorType);
// Register session holder if synchronization is active (i.e. a Spring TX is active)
//
// Note: The DataSource used by the Environment should be synchronized with the
// transaction either through DataSourceTxMgr or another tx synchronization.
// Further assume that if an exception is thrown, whatever started the transaction will
// handle closing / rolling back the Connection associated with the SqlSession.
//存在事物的
if (isSynchronizationActive()) {
Environment environment = sessionFactory.getConfiguration().getEnvironment();
if (environment.getTransactionFactory() instanceof SpringManagedTransactionFactory) {
if (logger.isDebugEnabled()) {
logger.debug("Registering transaction synchronization for SqlSession [" + session + "]");
}
//把SQLSession放入holder
holder = new SqlSessionHolder(session, executorType, exceptionTranslator);
// 绑定当前SqlSessionHolder到线程ThreadLocal中
bindResource(sessionFactory, holder);
//注册SqlSession同步回调器
registerSynchronization(new SqlSessionSynchronization(holder, sessionFactory));
holder.setSynchronizedWithTransaction(true);
//会话使用次数
holder.requested();
} else {
if (getResource(environment.getDataSource()) == null) {
if (logger.isDebugEnabled()) {
logger.debug("SqlSession [" + session + "] was not registered for synchronization because DataSource is not transactional");
}
} else {
throw new TransientDataAccessResourceException(
"SqlSessionFactory must be using a SpringManagedTransactionFactory in order to use Spring transaction synchronization");
}
}
} else {
if (logger.isDebugEnabled()) {
logger.debug("SqlSession [" + session + "] was not registered for synchronization because synchronization is not active");
}
}
return session;
}复制
上面关于SQLSession如果是在同一个事物中是会缓存起来的,sqlsession缓存到holder,holder缓存大ThreadLocal,如果没有事物的话,每次都会创建新的SQLSession,还有一些关于事物的代码,我们就不分析了,到这里我们分析完了整个sqlSession的创建
2.2.mapper接口代理对象创建
DefaultSqlSession
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
Configuration
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
MapperRegistry
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
/*
如果大家看过我们上篇文章,这个应该是比较熟悉的,我们文章的最后在绑定mapper接口时候就绑定了type和mapperProxyFactory的关系
*/
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null)
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
try {
//创建代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
MapperProxyFactory
public T newInstance(SqlSession sqlSession) {
//创建mapperPxoxy,
//MapperProxy实现了InvocationHandler接口,所以代理逻辑也也就在里面
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
//jdk动态代理创建大地理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}复制
到这里我们就分析完了整个代理对象的创建:
1:从knownMappers取出type对于的MapperProxyFactory
2:创建MapperProxyFactory,并且它实现了InvocationHandler,也就是我们的代理逻辑
3:jdk动态代理创建我们的代理对象
2.3.执行代理方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//是在object类中的方法,直接调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
//从缓存中获取MapperMthod对象,若不存在,则创建
final MapperMethod mapperMethod = cachedMapperMethod(method);
//执行业务方法(执行我们的sql语句)
return mapperMethod.execute(sqlSession, args);
}
private MapperMethod cachedMapperMethod(Method method) {
//从缓存中获取
MapperMethod mapperMethod = methodCache.get(method);
if (mapperMethod == null) {
//为空,则创建mapperMthod对象
mapperMethod = new MapperMethod(mapperInterface, method, sqlSession.getConfiguration());
//缓存
methodCache.put(method, mapperMethod);
}
return mapperMethod;
}复制
上面就是执行代理方法的逻辑,从整体上看,还是比较简单的
1:创建获取MapperMethod
2:执行代理逻辑
下面我们对上面的两个过程继续分析
2.3.1.创建MapperMethod
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
//创建sqlCommand(保留sql的一些信息)
this.command = new SqlCommand(config, mapperInterface, method);
// 创建 MethodSignature 对象(保留一些拦截方法的信息)
this.method = new MethodSignature(config, method);
}复制
这个创建逻辑,好像什么都么有,但是新引入了两个类SqlCommand,MethodSignature,我们不防跟进去看看,这两个类是干嘛的
2.3.2.SqlCommand
SqlCommand 是MapperMethod的一个内部类
public static class SqlCommand {
private final String name;
private final SqlCommandType type;
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) throws BindingException {
//获取statementName
String statementName = mapperInterface.getName() + "." + method.getName();
MappedStatement ms = null;
//mappedStatements集合中是否存在这个key
if (configuration.hasStatement(statementName)) {
//获取MappedStatement
ms = configuration.getMappedStatement(statementName);
}/如果mapper接口的名字和方法名字不是同一个,说明我们可能调用的是父类的方法
else if (!mapperInterface.equals(method.getDeclaringClass().getName())) { // issue #35
//获取父类的parentStatementName
String parentStatementName = method.getDeclaringClass().getName() + "." + method.getName();
if (configuration.hasStatement(parentStatementName)) {
//获取MappedStatement
ms = configuration.getMappedStatement(parentStatementName);
}
}
if (ms == null) {
throw new BindingException("Invalid bound statement (not found): " + statementName);
}
//id
name = ms.getId();
//是什么语句(UNKNOWN, INSERT, UPDATE, DELETE, SELECT;)
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
public String getName() {
return name;
}
public SqlCommandType getType() {
return type;
}
}复制
上面就是SqlCommand创建过程,其实获取MappedStatement中的id和sql类型,而关于MappedStatement的解析过程,我们上篇分析过了,我们可以简单理解为,它存储了所有的sql语句相关的信息
2.3.3.MethodSignature
从字面上来看就是方法签名,肯定就是存储的一些方法有关的信息。比如返回类型,参数列表
MethodSignature 是MapperMethod的一个内部类
public static class MethodSignature {
private final boolean returnsMany;
private final boolean returnsMap;
private final boolean returnsVoid;
private final Class<?> returnType;
private final String mapKey;
private final Integer resultHandlerIndex;
private final Integer rowBoundsIndex;
private final SortedMap<Integer, String> params;
private final boolean hasNamedParameters;
public MethodSignature(Configuration configuration, Method method) throws BindingException {
//方法的返回类型
this.returnType = method.getReturnType();
//检查返回类型是否是Void
this.returnsVoid = void.class.equals(this.returnType);
//返回类型是是否是Collection,Array
this.returnsMany = (configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray());
//解析 @MapKey 注解,获取注解的值
this.mapKey = getMapKey(method);
this.returnsMap = (this.mapKey != null);
//是否有Param注解
this.hasNamedParameters = hasNamedParams(method);
//获取RowBounds参数的索引位置,如果有多个会报异常
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
//获取ResultHandler参数的索引位置,如果有多个会报异常
this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);
//获取参数列表
this.params = Collections.unmodifiableSortedMap(getParams(method, this.hasNamedParameters));
}
private SortedMap<Integer, String> getParams(Method method, boolean hasNamedParameters) {
final SortedMap<Integer, String> params = new TreeMap<Integer, String>();
//获取方法的参数列表
final Class<?>[] argTypes = method.getParameterTypes();
for (int i = 0; i < argTypes.length; i++) {
//不是RowBounds类型和ResultHandler类型
if (!RowBounds.class.isAssignableFrom(argTypes[i]) && !ResultHandler.class.isAssignableFrom(argTypes[i])) {
String paramName = String.valueOf(params.size());
if (hasNamedParameters) {
paramName = getParamNameFromAnnotation(method, i, paramName);
}
//缓存参数
params.put(i, paramName);
}
}
return params;
}复制
过程也比较简单,主要就是获取方法返回类型和参数信息
到这里我们就分析完了MapperMethod的创建过程了,下面我们开始分析执行逻辑
2.3.4.执行代理逻辑(也就是我们的execute方法)
public Object execute(SqlSession sqlSession, Object[] args) {
//根据不同的sql类型,执行相应的数据库操作
Object result;
//插入操作
if (SqlCommandType.INSERT == command.getType()) {
// 参数转换
Object param = method.convertArgsToSqlCommandParam(args);
//执行insert操作
result = rowCountResult(sqlSession.insert(command.getName(), param));
} else if (SqlCommandType.UPDATE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
} else if (SqlCommandType.DELETE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
} else if (SqlCommandType.SELECT == command.getType()) {
//返回类型是空,但是有ResultHandler,说明调用者是想通过ResultHandler获取返回值,而不是通过方法的返回值
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
//执行查询,返回多个结果集
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
//执行查询,返回map
result = executeForMap(sqlSession, args);
} else {
// 执行返回返回一个结果对象
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
} else {
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}复制
执行方法的逻辑也比较清晰,根据不同的sql类型:
1:转换参数
2:执行相应sql
下面我们首先分析下转换参数,然后分析具体sql语句的执行
MapperMethod
public Object convertArgsToSqlCommandParam(Object[] args) {
//参数个数
final int paramCount = params.size();
//如果没有直接返回空
if (args == null || paramCount == 0) {
return null;
} else if (!hasNamedParameters && paramCount == 1) {
//方法没有Param注解,且有一个参数
return args[params.keySet().iterator().next()];
} else {
final Map<String, Object> param = new ParamMap<Object>();
int i = 0;
for (Map.Entry<Integer, String> entry : params.entrySet()) {
// 添加 <参数名, 参数值> 键值对到 param 中
param.put(entry.getValue(), args[entry.getKey()]);
// issue #71, add param names as param1, param2...but ensure backward compatibility
// 如 param1, param2, ... paramN
final String genericParamName = "param" + String.valueOf(i + 1);
//使用者显式将参数名称配置为 param1,即 @Param("param1")
if (!param.containsKey(genericParamName)) {
// 添加 <param*, value> 到 param 中
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}复制
上面的过程也比较简单,下面我们分析sql语句真正的执行过程了
关于sql语句的分析我们分为两块,一个是查询语句的分析(select),一个是更新语句的分析(update,delete,insert)
2.3.5.查询语句的分析
我们上面的查询语句分为下面几种,如下
executeWithResultHandler:执行优handler的查询语句
executeForMany:执行Collection,数组的查询语句
executeForMap:执行map的查询语句
selectOne:执行普通的查询语句
不知道大家有没有注意到,它们的返回类型都是object,那就说明,这个方法肯定是做做了两件事的,第一执行我们的sql语句,第二转换相应的结果类型,下面我们挑其中一个最简单的进行分析
DefaultSqlSession
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
//执行的是selectList方法
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
//取其中第一个结果
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}复制
我们继续往下看
public <E> List<E> selectList(String statement, Object parameter) {
//重载方法
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//获取mapper语句信息
MappedStatement ms = configuration.getMappedStatement(statement);
//调用executor的query方法,执行逻辑
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}复制
上面的代码最终会调用execute的,query方法,接下来我们就去看execute的query方法,但是这里有个问题,excutor的实现类
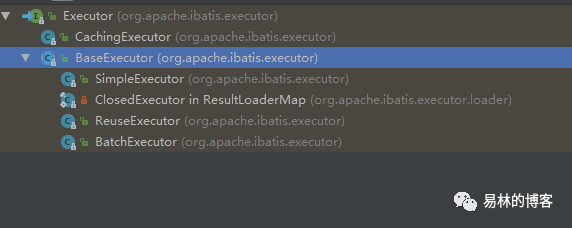
我们这里到底是使用的CachindExecutor(其实是一个装饰器,用于给目标executor增加二级缓存的功能)还是BaseExecutor,这块其实可以从我们创建SQLSession那块找到答案
我们直接看那一块代码
创建sqlSession时,会创建我们的executor,默认情况下executorType=simple
public Executor newExecutor(Transaction transaction, ExecutorType executorType, boolean autoCommit) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
//默认值是true,修饰executor,增加二级缓存功能
if (cacheEnabled) {
executor = new CachingExecutor(executor, autoCommit);
}
//插件相关代码
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}复制
那说明我们是给simpleExecutor增加的二级缓存功能
我们继续接着上面的query方法分析,接下来应该是分析CachingExecutor的query方法了
CachingExecutor
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//获取BoundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建 CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//执行查询
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}复制
上面的方法比较简单,但是出现了一个新的类BoundSql,我们暂时先放一放,后面会分析它,继续分析我们的query方法
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
//从 MappedStatement 获取缓存
Cache cache = ms.getCache();
//缓存不为空
if (cache != null) {
//如果需要清空缓存,则清空
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
//boundSql的检查工作
ensureNoOutParams(ms, parameterObject, boundSql);
//默认值范围false,当flushCacheIfRequired满足条件可以执行,则变为true,这里说明缓存有数据
if (!dirty) {
//上一把读锁
cache.getReadWriteLock().readLock().lock();
try {
@SuppressWarnings("unchecked")
//从缓存中获取数据
List<E> cachedList = (List<E>) cache.getObject(key);
if (cachedList != null) return cachedList;
} finally {
cache.getReadWriteLock().readLock().unlock();
}
}
//调用被装饰类的 query 方法
List<E> list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//缓存结果
tcm.putObject(cache, key, list); // issue #578. Query must be not synchronized to prevent deadlocks
return list;
}
}
return delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}复制
接下来我们继续分析,delegate是我们的simpleExecutor,理应是调用我们这个类的query方法,如果大家进去看,会线这个类中是没有这个方法的,那说明我们的从它的父类中找,也就是baseExecutor
BaseExecutor
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//从一级缓存中取缓存的数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//存储过程相关的,不做分析
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//查数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
//延迟加载
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache(); // issue #482
}
}
return list;
}复制
关于延迟加载的不在本文分析的范畴,我们继续分析queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//一级缓存存储一个字符串
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//执行查询操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//删除那个字符串
localCache.removeObject(key);
}
//一级缓存中存储查询结果
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}复制
继续向下分析doQuery,这个方法是个抽象方法,按照我们前面分析的,现在应该是调用simpleExecutor的doQuery方法
SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
//获取配置信息
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, rowBounds, resultHandler, boundSql);
//创建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
//执行查询操作
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}复制
这个地方又涉及到了两个类StatementHandler,stament,我们一样的先放一放,继续跟query方法
PreparedStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//执行sql
ps.execute();
//处理执行结果
return resultSetHandler.<E> handleResultSets(ps);
}复制
到这里我们总算看到执行结束了,关于最后的处理结果,我们在单独分析下
2.3.6.处理查询的结果
DefaultResultSetHandler
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
//取第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
//获取结果集
ResultMap resultMap = resultMaps.get(resultSetCount);
//处理结果集
handleResultSet(rsw, resultMap, multipleResults, null);
//获取下一个结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {
//获取结果集
ResultSet rs = stmt.getResultSet();
while (rs == null) {
// move forward to get the first resultset in case the driver
// doesn't return the resultset as the first result (HSQLDB 2.1)
//移动 ResultSet 指针到下一个上,有些数据库驱动可能需要使用者先调用 getMoreResults 方法,然后才能调用 getResultSet 方法获取到第一个 ResultSet
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
// no more results. Must be no resultset
break;
}
}
}
//返回ResultSetWrapper
return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}复制
代码还算比较简单,我们继续分析其中的过程
处理结果集
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
//多结果集的处理
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
/*
* 检测 resultHandler 是否为空。ResultHandler 是一个接口,我们可以实现该接口,对于返回的数据按照我们自己的意愿进行处理,比如说
我们可以检查结果中是否有一些敏感信息,如果存在,我么可以替换,我们也可以直接把结果置为空{我们可以对于返回值为空的方法,我们都能获取到sql执行的返回值}
*/
if (resultHandler == null) {
//结果处理器
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
//处理行结果数据
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
//把结果放入要返回的集合中
multipleResults.add(defaultResultHandler.getResultList());
} else {
//处理行结果数据
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
closeResultSet(rsw.getResultSet()); // issue #228 (close resultsets)
}
}复制
下面我们继续分析handleRowValues
DefaultResultSetHandler
private void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
//处理嵌套映射,
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
//处理简单结果映射
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}复制
处理简单结果集映射,和处理嵌套映射(<resultMap>标签中还有<resultMap>标签),我们只分析简单的结果映射
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext resultContext = new DefaultResultContext();
//跳到指定的行,根据rowBounds
skipRows(rsw.getResultSet(), rowBounds);
//是否还有更多行的数据需要处理
while (shouldProcessMoreRows(rsw.getResultSet(), resultContext, rowBounds)) {
//获取resultMap
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
//获取resultSet中的结果
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
//存储结果
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}复制
我们简单总结下:
1:跳到指定的行,根据rowBounds【单独分析】
2:遍历处理多行数据结果(计算selectOne,其实也是调用的selectList)
3:获取由鉴别器处理的resultMap【自行去看相关代码比较简单】
4:获取resultSet中的结果【单独分析淡定】
5:存储我们的结果【单独分析】
对于上面总结的,我们继续深入进去看相关代码
2.3.6.1.跳到指定的行
private void skipRows(ResultSet rs, RowBounds rowBounds) throws SQLException {
//rs的类型不等于TYPE_FORWARD_ONLY
if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {
//根据rowBounds的偏移量直接跳
rs.absolute(rowBounds.getOffset());
}
} else {
for (int i = 0; i < rowBounds.getOffset(); i++) {
/*
通过不断循环调用next来到达指定的位置,如果偏移量非常大,就比较损耗性能了
*/
rs.next();
}
}
}复制
RowBounds 参数会告诉 MyBatis 略过指定数量的记录,还有限制返回结果的数量。RowBounds 类有一个构造方法来接收 offset 和 limit,另外,它们是不可二次赋值的。
int offset = 100;
int limit = 25;
RowBounds rowBounds = new RowBounds(offset, limit);复制
所以在这方面,不同的驱动能够取得不同级别的高效率。为了取得最佳的表现,请使用结果集的 SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 的类型(换句话说:不用 FORWARD_ONLY)。
2.3.6.2.获取resultSet中的结果并设置我们的对象中
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey rowKey) throws SQLException {
//懒加载相关
final ResultLoaderMap lazyLoader = instantiateResultLoaderMap();
//创建实体对象.即我们在poji对象
Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null);
/没有类型处理器
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
//创建元数据操作对象
final MetaObject metaObject = configuration.newMetaObject(resultObject);
//<constructor>标签的映射
boolean foundValues = resultMap.getConstructorResultMappings().size() > 0;
//是否应自动映射结果集
if (shouldApplyAutomaticMappings(resultMap, !AutoMappingBehavior.NONE.equals(configuration.getAutoMappingBehavior()))) {
//自动映射
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
//根据 <resultMap> 节点中配置属性进行映射
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = (lazyLoader != null && lazyLoader.size() > 0) || foundValues;
resultObject = foundValues ? resultObject : null;
return resultObject;
}
return resultObject;
}复制
我们简单总结下:
1:创建我们的实体类对象
2:如果结果中需要自动映射,则进行自动映射
3:处理<resultMap>配置关系的手动映射
2.3.6.2.1创建我们的实体类对象
DefaultResultSetHandler
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final List<Class<?>> constructorArgTypes = new ArrayList<Class<?>>();
final List<Object> constructorArgs = new ArrayList<Object>();
//重载方法
final Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
//是否有类型处理器
if (resultObject != null && configuration.isLazyLoadingEnabled() && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
//需要关联查询
if (propertyMapping.getNestedQueryId() != null) { // issue #109 (avoid creating proxies for leaf objects)
//创建代理对象。这个地方用的不是java的动态代理,因为我们的pojo是很少去实现接口的,这个地方用的是Javassist框架
return proxyFactory.createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
}
}
}
return resultObject;
}复制
第一步会创建我们的实体对象
第二步会循环检查我们的配置属性是否需要关联查询,如果需要则会创建代理对象
首先我们分析第二点,在分析时,我们需要明白什么要需要关联查询,比如说我有两个类,如
/**
* 学生类
*/
public class Student {
private String name;
private Integer age;
private MyClass myClass;
}
/**
* 班级类
*/
public class MyClass {
private Integer classNo;
private String className;
}复制
我们在获取学生类的信息时,我们需要班级类的信息[这就是关联查询],比如说当我们获取学生类的信息时,我们在调用getMyClass时,我们此时需要获取班级的信息,那么此时通过代理对象获取我们的查询结果,这个就分析到这里,第一步才是我们的重点
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix)
throws SQLException {
//获取<resultMap>的type类型
final Class<?> resultType = resultMap.getType();
// 获取 <constructor> 节点对应的 ResultMapping
final List<ResultMapping> constructorMappings = resultMap.getConstructorResultMappings();
//结果集是否有类型处理器
if (typeHandlerRegistry.hasTypeHandler(resultType)) {
//通过typeHandler生成返回对象
return createPrimitiveResultObject(rsw, resultMap, columnPrefix);
} else if (constructorMappings.size() > 0) {
//由<constructor>配置的信息从resultSet中取出相应的value,把其作为参数,传给构造方法,创建对象
return createParameterizedResultObject(rsw, resultType, constructorMappings, constructorArgTypes, constructorArgs, columnPrefix);
} else {
//通过无参构造方法创建对象
return objectFactory.create(resultType);
}
}复制
上面过程就是说几种创建实体类对象的方法,通过情况下是使用无参构造器创建我们的映射对象,到这里相当于我们已经创建好了我们的映射对象了
2.3.6.2.2自动映射
mybatis自动映射有三种情况
NONE - 禁用自动映射。仅设置手动映射属性
PARTIAL - 将自动映射结果除了那些有内部定义内嵌结果映射的(joins)
FULL - 自动映射所有
默认值是 PARTIAL
除了上面的方式,我们可以手动配置<resultMap>标签的autoMapping属性,来启用会禁用自动映射
我们直接看相关代码
private boolean shouldApplyAutomaticMappings(ResultMap resultMap, boolean def) {
//获取resultMap的autoMapping属性
return resultMap.getAutoMapping() != null ? resultMap.getAutoMapping() : def;
}
//处理自动映射
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
/*
UnMappedColumnAutoMapping 未映射的列名:关于什么是未映射的大家看下面的代码会 有说明的
*/
final List<String> unmappedColumnNames = rsw.getUnmappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
for (String columnName : unmappedColumnNames) {
String propertyName = columnName;
//columnPrefix==null 跳过这段
if (columnPrefix != null && columnPrefix.length() > 0) {
// When columnPrefix is specified,
// ignore columns without the prefix.
if (columnName.startsWith(columnPrefix)) {
propertyName = columnName.substring(columnPrefix.length());
} else {
continue;
}
}
//根据propertyName获取到对应的属性
final String property = metaObject.findProperty(propertyName, configuration.isMapUnderscoreToCamelCase());
//有熟悉的set方法
if (property != null && metaObject.hasSetter(property)) {
//获取set方法的class类型
final Class<?> propertyType = metaObject.getSetterType(property);
//是有有类型处理器
if (typeHandlerRegistry.hasTypeHandler(propertyType)) {
//获取类型处理器
final TypeHandler<?> typeHandler = rsw.getTypeHandler(propertyType, columnName);
//获取类型处理器的执行结果
final Object value = typeHandler.getResult(rsw.getResultSet(), columnName);
if (value != null || configuration.isCallSettersOnNulls()) { // issue #377, call setter on nulls
if (value != null || !propertyType.isPrimitive()) {
//设置属性值为类型处理器后的属性值
metaObject.setValue(property, value);
}
foundValues = true;
}
}
}
}
return foundValues;
}复制
我们总结下自动映射的过程:
1:通过ResultSetWrapper获取未映射的列名(没有配置在<resutlMap中的>,大家可以看下面的分析)
2:遍历1得到的结果columnName
3:通过metaObject根据columnName即propertyName找对应的属性
4:通过ResultSetWrapper获取对于的类型处理器,调用类型处理器的get方法获取到对应的值
5:最后通过metaObject调用set方法设置我们创建对象的属性值
到这里我们就把未配置到resultMap中的值,映射到我们创建的对象中了
代码也比较简单,大家跟着注释读,我们接着看下getUnmappedColumnNames方法
public List<String> getUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
if (unMappedColumnNames == null) {
//加载已映射和未映射的列名
loadMappedAndUnmappedColumnNames(resultMap, columnPrefix);
//获取未映射列名
unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
}
return unMappedColumnNames;
}
private void loadMappedAndUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
//已映射列名的集合
List<String> mappedColumnNames = new ArrayList<String>();
//未映射列名的集合
List<String> unmappedColumnNames = new ArrayList<String>();
final String upperColumnPrefix = columnPrefix == null ? null : columnPrefix.toUpperCase(Locale.ENGLISH);
//给列拼接前缀
final Set<String> mappedColumns = prependPrefixes(resultMap.getMappedColumns(), upperColumnPrefix);
//遍历列名
for (String columnName : columnNames) {
final String upperColumnName = columnName.toUpperCase(Locale.ENGLISH);
if (mappedColumns.contains(upperColumnName)) {
//已映射列名的集合
mappedColumnNames.add(upperColumnName);
} else {
unmappedColumnNames.add(columnName);
}
}
mappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), mappedColumnNames);
unMappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), unmappedColumnNames);
}复制
上面说的已映射合未映射是什么呢,我们简单说下,就比如说我有一个类
public class MyClass {
private Integer classNo;
private String className;
}
public class Student {
private String name;
private Integer age;
private MyClass myClass;
}复制
我在myClassMapper.xml中有一个这样的resultMap
<resultMap id="myclass" type=MyClass>
<result property="classNo" column="class_no">
</resultMap>
<select id="findInfo" resulltMap=“myclass”> select class_no,className from myClass </select>复制
上面的resultMap中我们的MyClass有两个属性,但是只有classNo在resultMap中,那么classNo就属于已经映射的集合,className属于未映射的集合
我们在调用findInfo的方法时,className 会采用自动映射的方式放入我们的myClass实体中,classNo则会采用属性映射的方式放入我们的myClass实体中(属性映射即applyPropertyMappings),但是默认情况下我们是不支持我们自己实体类的自动映射的
我们接下里继续分析applyPropertyMappings
2.3.6.2.3applyPropertyMappings 属性映射
属性映射即把属性映射到我们创建的实体对象中
DefaultResultSetHandler
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
//获取已映射的列名
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
//获取所有的属性映射resultMapping
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
//遍历
for (ResultMapping propertyMapping : propertyMappings) {
//拼接列名的前缀,得到完整的列名
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
/*
1.propertyMapping.isCompositeResult():检测 column 是否为 {prop1=col1, prop2=col2} 形式,一般用于关联查询
2.mappedColumnNames.contains(column):当前的列名是否在已映射的列名的集合中
3. propertyMapping.getResultSet():配置是resultSet
*/
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
//从rsw中获取指定的数据
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
//属性
final String property = propertyMapping.getProperty(); // issue #541 make property optional
if (value != NO_VALUE && property != null && (value != null || configuration.isCallSettersOnNulls())) { // issue #377, call setter on nulls
if (value != null || !metaObject.getSetterType(property).isPrimitive()) {
//把获取到的值设置到我们对象中
metaObject.setValue(property, value);
}
foundValues = true;
}
}
}
return foundValues;
}
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
//关联查询
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
//resultSet
addPendingChildRelation(rs, metaResultObject, propertyMapping);
return NO_VALUE;
} else if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
return NO_VALUE;
} else {
//类型处理器
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
//获取完整的列名
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
//调用类型处理器的get方法获取值
return typeHandler.getResult(rs, column);
}
}复制
到这里我们就分析完了整个<resultMap>中属性的填充过程,我们总结下:
1:通过ResultSetWrapper获取所有的已映射的列名集合
2:从<resultMap>获取所有的resultMapping
3:遍历2得到的结果,ResultMapping
4:获取resultMapping的完整列名
5:调用getPropertyMappingValue获取指定列的值
6:把5得到结果用metaObject.setValue方法设置到我们创建的实例对象中
2.3.6.2.4getNestedQueryMappingValue关联查询
mybatis是提供了一对一<association>和一对多<collection>个关联查询,关于关联查询是什么,我们就不分析了,我们直接看是怎么处理关系查询的
DefaultResultSetHandler
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 获取关联查询 id,id = 命名空间 + <association>或<collection> 的 select 属性值
final String nestedQueryId = propertyMapping.getNestedQueryId();
//获取对应的属性
final String property = propertyMapping.getProperty();
//根据id获取对于的MappedStatement
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
//参数的class类型
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
//获取关联查询的参数对象
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = NO_VALUE;
if (nestedQueryParameterObject != null) {
//创建boundSQL
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
//创建缓存key
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
//获取缓存结果
final List<Object> nestedQueryCacheObject = getNestedQueryCacheObject(nestedQuery, key);
if (nestedQueryCacheObject != null) {
value = resultExtractor.extractObjectFromList(nestedQueryCacheObject, targetType);
}//一级缓存是否该查询结果
else if (executor.isCached(nestedQuery, key)) {
//从缓存中获取结果,并调用 metaResultObject设置属性
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
} else {
//结果加载器
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
//是否配置了懒加载
if (configuration.isLazyLoadingEnabled()) {
//添加延迟加载对象到loaderMap中
lazyLoader.addLoader(property, metaResultObject, resultLoader);
} else {
//否则直接加载结果,返回
value = resultLoader.loadResult();
}
}
}
return value;
}复制
上面就是整个处理关联查询的结果的逻辑,我们总结下:
1:首先会获取id
2:根据1的结果获取MappedStatement
3:生成关联查询的参数对象
4:根据3创建BoundSql
5:首先从关联查询缓存中去查找我们的执行结果,如果命中则获取结果,并通过metaObject的set方法设置属性
6:当5不满足时,会优先从1级缓存查找结果,如果命中则获取结果,并通过metaObject的set方法设置属性
7:当6不满足时,此时会看是否需要延迟加载,如果需要则添加延迟加载对象到loaderMap中,否则调用resultLoader.loadResult()返回我们的结果
上面我们说到了延迟加载的相关东西,我们进去看看
2.3.6.2.4延迟加载相关
<!-- 开启延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>复制
我们说一个延迟加载的场景:
public class MyClass {
private Integer classNo;
private String className;
}
public class Student {
private String name;
private Integer age;
private MyClass myClass;
public MyClass getMyClass(myClass cla){
retrun this.myClass=cla
}
}复制
我们有个业务方法叫findStudentInfo()方法会返回某一个学生的信息,从上面的实体可知道,我们的student会关联查询class信息{会执行两条语句,一条用于获取student自己的信息,一条用于获取class的信息},但是如果我们配置为启动懒加载,那我们在调用findStudentInfo()时是不会去获取class的信息的,只有当我们手动调用getMyClass时才会再次触发一次sql的执行,去获取我们的class信息
ResultLoaderMap
public void addLoader(String property, MetaObject metaResultObject, ResultLoader resultLoader) {
//属性名准大写
String upperFirst = getUppercaseFirstProperty(property);
if (!upperFirst.equalsIgnoreCase(property) && loaderMap.containsKey(upperFirst)) {
throw new ExecutorException("Nested lazy loaded result property '" + property +
"' for query id '" + resultLoader.mappedStatement.getId() +
" already exists in the result map. The leftmost property of all lazy loaded properties must be unique within a result map.");
}
创建LoadPair.并加入到loaderMap集合中
loaderMap.put(upperFirst, new LoadPair(property, metaResultObject, resultLoader));
}复制
通过最后一行代码,我们可以知道这个延迟加载应该是委托给了LoadPair对象,当我们调用相关的getXXX方法(比如我们上面分析到的getMyClass方法时)它的load方法会被调用,接下来我们去看看它是怎么执行我们的load方法的
LoadPair
public void load() throws SQLException {
/* These field should not be null unless the loadpair was serialized.
* Yet in that case this method should not be called. */
if (this.metaResultObject == null) throw new IllegalArgumentException("metaResultObject is null");
if (this.resultLoader == null) throw new IllegalArgumentException("resultLoader is null");
//调用重载方法
this.load(null);
}
public void load(final Object userObject) throws SQLException {
if (this.metaResultObject == null || this.resultLoader == null) {
if (this.mappedParameter == null) {
throw new ExecutorException("Property [" + this.property + "] cannot be loaded because "
+ "required parameter of mapped statement ["
+ this.mappedStatement + "] is not serializable.");
}
final Configuration config = this.getConfiguration();
//获取mapperStatMent
final MappedStatement ms = config.getMappedStatement(this.mappedStatement);
if (ms == null) {
throw new ExecutorException("Cannot lazy load property [" + this.property
+ "] of deserialized object [" + userObject.getClass()
+ "] because configuration does not contain statement ["
+ this.mappedStatement + "]");
}
this.metaResultObject = config.newMetaObject(userObject);
this.resultLoader = new ResultLoader(config, new ClosedExecutor(), ms, this.mappedParameter,
metaResultObject.getSetterType(this.property), null, null);
}
/* We are using a new executor because we may be (and likely are) on a new thread
* and executors aren't thread safe. (Is this sufficient?)
*
* A better approach would be making executors thread safe. */
//线程安全相关
if (this.serializationCheck == null) {
final ResultLoader old = this.resultLoader;
this.resultLoader = new ResultLoader(old.configuration, new ClosedExecutor(), old.mappedStatement,
old.parameterObject, old.targetType, old.cacheKey, old.boundSql);
}
this.metaResultObject.setValue(property, this.resultLoader.loadResult());
}复制
我们直接看最后一行代码的loadResult就好了
public Object loadResult() throws SQLException {
//获取执行结果
List<Object> list = selectList();
resultObject = resultExtractor.extractObjectFromList(list, targetType);
return resultObject;
}
private <E> List<E> selectList() throws SQLException {
Executor localExecutor = executor;
if (Thread.currentThread().getId() != this.creatorThreadId || localExecutor.isClosed()) {
localExecutor = newExecutor();
}
try {
return localExecutor.<E> query(mappedStatement, parameterObject, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER, cacheKey, boundSql);
} finally {
if (localExecutor != executor) {
localExecutor.close(false);
}
}
}复制
看到没有,我们最后跟到了我们的selectList方法,也就说明load方法内部在做延迟加载时,会再次调用selectList获取我们的结果
2.3.6.3.存储我们的结果
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
private void storeObject(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
//多个结果集的处理
linkToParent(rs, parentMapping, rowValue);
} else {
//存储结果
callResultHandler(resultHandler, resultContext, rowValue);
}
}
private void callResultHandler(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue) {
//将结果存储到resultContext
resultContext.nextResultObject(rowValue);
//一个结果集的回调了
resultHandler.handleResult(resultContext);
}
DefaultResultContext
public void nextResultObject(Object resultObject) {
resultCount++;
this.resultObject = resultObject;
}复制
代码比较简单,我们就分析到这里
2.3.7.BoundSql ,StatementHandler
2.3.7.1.回顾整个查询过程
前面我们基本上是分析玩乐了整个查询过程,但是我们还遗留了几个类
BoundSql
StatementHandler
下面我们继续分析
首先我们简单回顾下在执行查询操作时
CachingExecutor
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取 BoundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建 CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 调用重载方法
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}复制
上面的方法最终会调用到下面的doQuery方法
SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询操作
return handler.<E>query(stmt, resultHandler);
} finally {
// 关闭 Statement
closeStatement(stmt);
}
}
PreparedStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行 SQL
ps.execute();
// 处理执行结果
return resultSetHandler.<E>handleResultSets(ps);
}复制
2.3.7.2.BoundSql
boundSql即我们的sql片段,什么意思呢,我们在映射文件中配置的sql语句会存在一些标签比如 <if>、<where>,还有一些占位符#{},以及动态sql,所以我们是不能直接使用在映射文件配置的sql语句的,boundSql会把它解析成一个一个的小片段,最后把小片段合起来就组成了我们的sql语句
首先我们来看下boundSql的类信息
public class BoundSql {
private String sql;
private List<ParameterMapping> parameterMappings;
private Object parameterObject;
private Map<String, Object> additionalParameters;
private MetaObject metaParameters;复制
我们解释下上面的意思
| 变量 | 对应的类型 | 功能 |
|---|---|---|
| sql | String | 它是一个完整的sql语句,但是可能会包括?占位符 |
| parameterMappings | List | 参数映射列表,即sql中的每个 #{x}占位符都会被解析成parameterMapping对象 |
| parameterObject | Object | 运行时参数,即用户传的参数 |
| additionalParameters | Map | 一些附加的信息,比如我们的dataBaseid |
| metaParameters | MetaObject | 一些元信息对象 |
下面我们开始分析获取boundSql,getBoundSql方法
MappedStatement
public BoundSql getBoundSql(Object parameterObject) {
//获取boundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
//参数映射
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.size() <= 0) {
//创建一个新的boundSql
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
//一些检查逻辑
// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}复制
我们继续跟进去看getBoundSql方法,sqlSource是一个接口,它有几个实现类
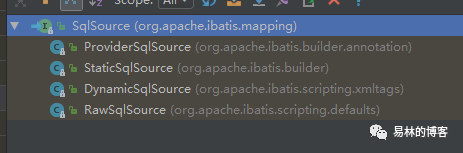
上面两个很少用的,第三个的话,是不叫常用的,按照它的名字,我们也能猜一些信息,动态的sqlSource,比如我们的sql语句中存在一些动态标签如 <if>、<where> 等,会使用这个类,当是一个比较基本的sql时hi使用最后一个,我们直接来分析第三个
DynamicSqlSource
public BoundSql getBoundSql(Object parameterObject) {
//创建DynamicContext
DynamicContext context = new DynamicContext(configuration, parameterObject);
//解析sql片段,会将解析结果春存到DynamicContext 中
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
//创建SqlSource,它的作用是将sql语句中的占位符 #{} 替换为问号 ?,并未占位符生成ParameterMapping
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
// 调用 StaticSqlSource 的 getBoundSql 获取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
//设置一些元信息
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}复制
我们总结下整个过程:
1:创建DynamicContext
2:解析我们的sql片段
3:创建SqlSource,并解析占位符
4:获取boundSql
5:遍历DynamicContext中的信息,并把它放入boundSql中
由于篇幅原因,上面的几个过程就不展开分析了,大家可以自行去看下
我们需要清楚到这里我们除了运行时参数的处理(?占位符,接受用户输入的参数),我们基本上是一个可以被执行的sql语句了
2.3.7.3.StatementHandler
我们直接分析它的创建过程
Configuration
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//创建具有路由功能的StatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//插件代码{本篇不分析}
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//创建不同的statementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}复制
默认情况下,statementType 值为 PREPARED,到这里我们就分析完了statementHandler的创建,我们想要执行sql,还需要做两件事创建 Statement,以及将运行时参数和 Statement 进行绑定
首先我们来看下statment接口的实现
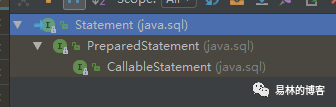
Statement 接口提供了执行 SQL,获取执行结果等基本功能。PreparedStatement 在此基础上,对 IN 类型的参数提供了支持。使得我们可以使用运行时参数替换 SQL 中的问号 ? 占位符,而不用手动拼接 SQL。CallableStatement 则是 在 PreparedStatement 基础上,对 OUT 类型的参数提供了支持,该种类型的参数用于保存存储过程输出的结果
SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
//获取数据库链接
Connection connection = getConnection(statementLog);
//创建 Statement
stmt = handler.prepare(connection);
//设置参数
handler.parameterize(stmt);
return stmt;
}复制
我们总结下:
1:获取数据库链接
2:创建Statement
3:设置运行时参数
我们继续分析
获取数据库链接
BaseExecutor
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog);
} else {
return connection;
}
}复制
关于数据库链接的,我们先分析到这里,接下来继续分析2和3
BaseStatementHandler
public Statement prepare(Connection connection) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
//创建statement
statement = instantiateStatement(connection);
//设置超时
setStatementTimeout(statement);
//设置可以查询的最大行数
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
PreparedStatementHandler
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
//创建不同的PreparedStatemen
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}复制
代码比较简单,我们接着分析3,运行时参数的绑定
PreparedStatementHandler
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
DefaultParameterHandler
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
/*
从 BoundSql 获取 ParameterMapping 集合,
ParameterMapping 与原始 SQL 中的 #{x} 占位符一一对应,用来处理我们的运行时参数
*/
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
MetaObject metaObject = parameterObject == null ? null : configuration.newMetaObject(parameterObject);
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
//排除参数为out,即存储过程的蕾西
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
//属性名
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
//从additionalParameters获取我们的属性值
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} //是否有类型处理器
else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
//通过用户传过来的参数获取属性值
value = metaObject == null ? null : metaObject.getValue(propertyName);
}
//类型处理器
TypeHandler typeHandler = parameterMapping.getTypeHandler();
//获取处理器的类型
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) jdbcType = configuration.getJdbcTypeForNull();
//设置我们的参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}复制
其实设置运行时参数大概分为两个部分
第一:获取我们的属性值value
第二,通过类型处理器设置我们的属性值
到这里我们的sql的运行参数也填充完了,可以执行了。
2.4.更新语句分析
2.4.1.更新语句流程分析
在上面我们基本上完整的分析了整个查询语句的执行过程,接下来我们分析更新语句,它们之间的比较大的区别就是更新语句的执行结果类型单一,处理逻辑要简单,还有,更新过程会立即刷新缓存,而查询过程则不会
我们从MapperMethod 的 execute 方法看
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
//插入
if (SqlCommandType.INSERT == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
}//更新
else if (SqlCommandType.UPDATE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
} else if (SqlCommandType.DELETE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
}//查询
else if (SqlCommandType.SELECT == command.getType()) {
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
} else {
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}复制
上面的查询,更新,删除的都是执行rowCountResult方法,返回结果就是影响的行数,我们进去看看
DefaultSqlSession
public int insert(String statement) {
return insert(statement, null);
}
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
public int update(String statement) {
return update(statement, null);
}
public int update(String statement, Object parameter) {
try {
//是否有脏数据
dirty = true;
// 获取 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//执行 Executor 的 update 方法
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
public int delete(String statement) {
return update(statement, null);
}
public int delete(String statement, Object parameter) {
return update(statement, parameter);
}复制
上面最终都是调用update方法,我们继续往下分析
CachingExecutor
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 刷新二级缓存
flushCacheIfRequired(ms);
//调用测量器的update
return delegate.update(ms, parameterObject);
}
BaseExecutor
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
//刷新一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
SimpleExecutor
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
// 创建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
//执行update
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}复制
StatementHandler 和 Statement 上面分析了,我们接下来分析 PreparedStatementHandler 的 update 方法。
PreparedStatementHandler
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//执行sql
ps.execute();
//获取影响的行数
int rows = ps.getUpdateCount();
//获取用户传入的参数值
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
//获取自增主键的值,并将值填入到参数对象中
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}复制
我们总结下:
1:执行我们的sql
2:获取我们的影响行数
3:获取自增主键的值,并将值放入参数对象中(主要是用于,我们对于insert操作时需要,有时我们需要获取自增主键的值)
上面的执1大家可以参考我们的查询流程的分析,2的话就比较简单,我们接下来分析3
2.4.2.自增主键-KeyGenerator分析
大家自行去看Jdbc3KeyGenerator,我们主要说一下场景
比如说我们在建表时,对于主键我们一般都设置为自增,我们在插入每行记录的时候不需要插入主键的值,主键为自动进行插入
那么如果我们的主键没有设置自增,怎么满足上面的要求呢
<insert id="insert" keyProperty="id" useGeneratedKeys="true">
INSERT INTO
myclass (`class_no`, `class_name`)
VALUES
(#{classNo}, #{className})
</insert>复制
通过这个配置,我们也能满足在插入时,主键自增的操作
2.4.3.处理返回结果
MapperMethod
private Object rowCountResult(int rowCount) {
final Object result;
//是空返回类型,直接把结果置为空
if (method.returnsVoid()) {
result = null;
} else if (Integer.class.equals(method.getReturnType()) || Integer.TYPE.equals(method.getReturnType())) {
result = rowCount;
} else if (Long.class.equals(method.getReturnType()) || Long.TYPE.equals(method.getReturnType())) {
result = (long) rowCount;
} else if (Boolean.class.equals(method.getReturnType()) || Boolean.TYPE.equals(method.getReturnType())) {
result = (rowCount > 0);
} else {
throw new BindingException("Mapper method '" + command.getName() + "' has an unsupported return type: " + method.getReturnType());
}
return result;
}复制
代码比较简单,就不分析了
3.总结
到这里我们分析完了整个sql的执行过程,篇幅比较大,有些内容也没有分析到,大家见谅,如果在分析过程中有错误的,希望大家指出来,最后谢谢大家
参考
MyBatis技术内幕:https://book.douban.com/subject/27087564/
MyBatis官方文档:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
