




就在上月,国际权威数据库性能测试榜单 benchANT 更新了 Time Series: Devops(时序数据库)场景排名,KaiwuDB 数据库在 xsmall 和 small 两类规格下的时序数据写入吞吐、查询吞吐、查询延迟、成本效益等多项指标刷新榜单原有数据纪录。

KaiwuDB 在 xsmall 和 small 两类规格下的时序数据写入吞吐数据
上一期,我们为大家详细介绍了KaiwuDB 写入吞吐背后的 3 大核心技术。今天,我们想和大家分享 KaiwuDB 如何优化查询的独家秘籍 
查询吞吐优化
✅ 秘籍1:连接层优化
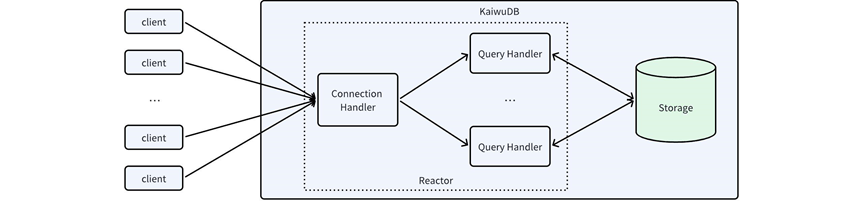
以本次 benchANT Time Series: DevOps 的 xSmall 场景为例,数据库部署在 2 核 8GB 的硬件资源上,需要处理来自 50 个客户端连接的高并发写入和查询请求。KaiwuDB 的多线程 Reactor 在这种资源受限但负载并发度高的场景下,既充分发挥了 CPU 的性能,又避免了单线程 Reactor 在处理某个连接上的业务时,整个进程无法处理其他连接事件的弊端。
查询延迟优化
✅ 秘籍2:查询执行流程优化
✅ 秘籍3:聚合算子优化
聚合查询是时序数据库中常见的负载类型,特别是带有时间窗口聚合的查询,例如 benchANT Time Series: DevOps 中涉及到的“查询指定设备在指定一小时时间段内每分钟的 usage_user 的最大值”。对此类时间窗口内的聚合查询,如果在扫描数据的同时可以完成聚合操作,则可以在很大程度上提高查询的执行效率。KaiwuDB 通过对聚合算子优化,实现了将聚合算子下推到存储层,缩短了查询执行链路、降低了数据遍历代价和数据传输开销。
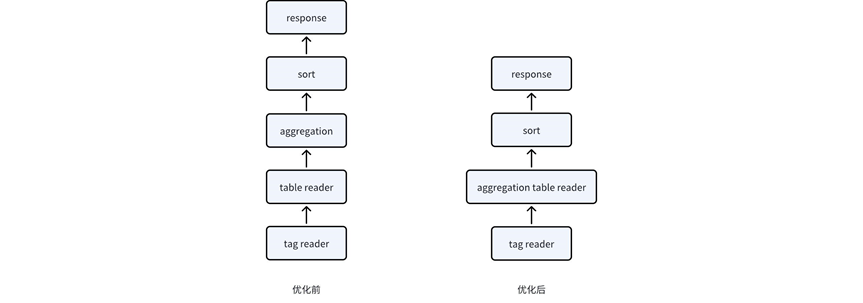
如下图所示,优化前,KaiwuDB 需要在读取数据的 tag 信息后,遍历 metrics 数据并且传输到聚合算子,再在聚合算子中进行聚合操作;而优化后,聚合算子直接下推到存储层,在扫描 metrics 数据的同时,完成时间戳改写、Groupby 判别以及聚合操作。通过聚合算子下推,KaiwuDB 的执行延时获得了 1.5 倍的加速比,大大提升了查询执行性能。
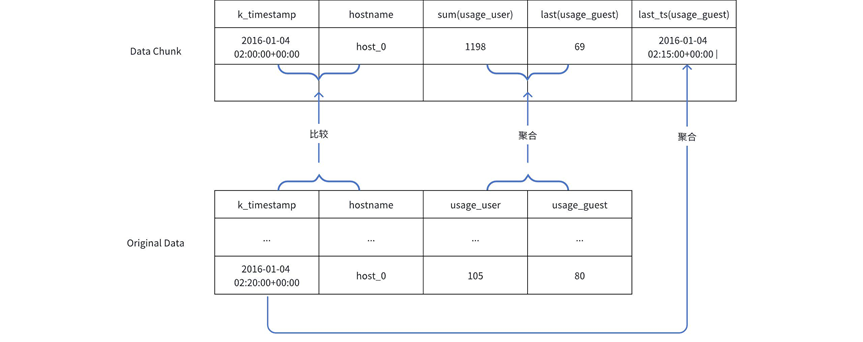
与此同时,针对时序数据的特点,KaiwuDB 进一步优化聚合算子的执行流程,实现了有序 Scan 算子,可以高效地读取时序数据,并生成有序结果集。在此基础上,实现了“数据扫描聚合融合算子”(AggTableScanOP),在扫描时序数据的同时完成数据聚合,使得时序数据的聚合性能提升了 40%~50%。
✅ 秘籍4:无锁时间字符串转换优化
KaiwuDB 使用 PG 编码协议,在将内部时间戳数据编码为 PG 编码时,需要将时序引擎中 timestamp 类型的转换为字符串返回,其中涉及到 gmtime_r(&sec, &ts) 函数(将 time_t 类型转换为带有年月日等信息的 std::tm 类型),但 gmtime_r 需要对操作系统的时区文件加锁(感兴趣可参考https://stackoverflow.com/questions/53889107/why-does-gmtime-r-call-tz-convert-which-grabs-a-global-lock),在高并发情况下,锁操作对查询性能产生较大影响。
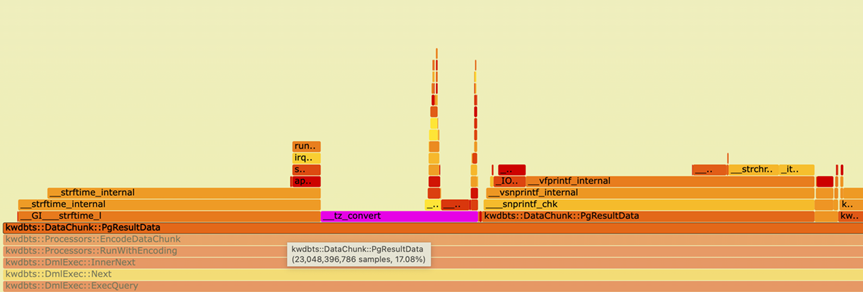
如下图所示,在优化前,使用 profiling 工具观测到的编码为 PG 编码的 CPU 开销约为17%,其中,gmtime_r 的锁操作占比较高。
对此,KaiwuDB 实现了无锁版本的时间字符串转换优化,不再通过访问操作系统的时区文件获取闰秒等信息,而是直接在优化后的函数内计算时间戳对应的年、月、日等信息,避免了高并发情况下访问操作系统时区文件锁机制带来的性能影响。在优化后,profiling 的结果显示编码过程的 CPU 开销占比大幅下降,由于gmtime_r 的锁操作造成的 CPU 开销被优化。

