




一、前言
前几天有个同事问了我一个问题,问题简化之后,大概如下面描述:在PostgreSQL中,存在一张表ta,表中数据存在两个值,分别是零和一。
[postgres@halo-centos8 ~]$ psql test
psql (16.6)
Type "help" for help.
test=# create table ta(a int);
CREATE TABLE
test=# insert into ta values(0);
INSERT 0 1
test=# insert into ta values(1);
INSERT 0 1然后有一个函数checkvalue,会对输入进来的参数值进行校验,如果等于0会抛出异常,如果是其他的值就正常返回true。
create or replace function checkvalue(int)
returns boolean
as $$
declare
begin
if $1 = 0 then
return 1/0;
end if;
return true;
end $$ language plpgsql;简单演示一下
test=# select * from ta where a > 0;
a
---
1
(1 row)
test=# select * from ta where checkvalue(a);
ERROR: division by zero
CONTEXT: SQL expression "1/0"
PL/pgSQL function checkvalue(integer) line 5 at RETURN大概的情况铺垫好了,问题便是当这个时候 a > 0 和 checkvalue(a) 共同作为过滤条件的时候,为什么总是a > 0 优先执行,而不会出现checkvalue优先执行抛出异常的情形。
即使尝试将二者交换先后顺序,依旧是 a > 0 优先执行。
test=# select * from ta where a > 0 and checkvalue(a);
a
---
1
(1 row)
test=# select * from ta where checkvalue(a) and a > 0; -- 交换顺序
a
---
1
(1 row)当时问我的时候,手头上刚好也有别的事情在处理,也就没有仔细去思考。
先入为主以为是优化器的逻辑(规则)优化导致的,比方说在某些场景下的OR转换成UNION ALL是等价的,便把我的猜想就这样说给了人家。
对逻辑优化感兴趣的同学,可以看看这位大佬的文章 Postgresql逻辑优化学习
规则优化、逻辑优化:把SQL对应到逻辑代数的公式,应用一些逻辑代数的等价规则做转换。例如选择下推,子查询提升、外连接消除,都是基于规则的优化,大部分有理论证明优化后的效果更好或至少不会更差,也有一些经验规则。
但是后面闲下来的时候,又想起了这个问题,后面越想越觉得给出去的这个答案是不对,所以便去求证了一下。
回顾了一下PostgreSQL优化器的设计,和简单调试了一下代码之后,悬着的心终于是死了。
果然是错的,在这里真正的原因其实纯粹就是cost。接下来给大家伙简单调试分析一下。
二、分析
我们以下面的调换了顺序的那条SQL进行调试,看起来会比较清晰一些。因为我们只要关注到checkvalue(a) 和 a > 0大概啥时候发生了调换或者是排序了就行。
select * from ta where checkvalue(a) and a > 0;所以废话少说直接上代码就好了,此处我们需要关注的优化器那块的内核代码,那里面的order_qual_clauses函数,简单简化一下便成了下面的样子
static List *
order_qual_clauses(PlannerInfo *root, List *clauses)
{
// ...
/*
* Collect the items and costs into an array. This is to avoid repeated
* cost_qual_eval work if the inputs aren't RestrictInfos.
*/
items = (QualItem *) palloc(nitems * sizeof(QualItem));
i = 0;
foreach(lc, clauses)
{
Node *clause = (Node *) lfirst(lc);
QualCost qcost;
cost_qual_eval_node(&qcost, clause, root);
// ...
}
/*
* Sort. We don't use qsort() because it's not guaranteed stable for
* equal keys. The expected number of entries is small enough that a
* simple insertion sort should be good enough.
*/
for (i = 1; i < nitems; i++)
{
QualItem newitem = items[i];
int j;
/* insert newitem into the already-sorted subarray */
for (j = i; j > 0; j--)
{
QualItem *olditem = &items[j - 1];
if (newitem.security_level > olditem->security_level ||
(newitem.security_level == olditem->security_level &&
newitem.cost >= olditem->cost))
break;
items[j] = *olditem;
}
items[j] = newitem;
}
/* Convert back to a list */
result = NIL;
for (i = 0; i < nitems; i++)
result = lappend(result, items[i].clause);
return result;
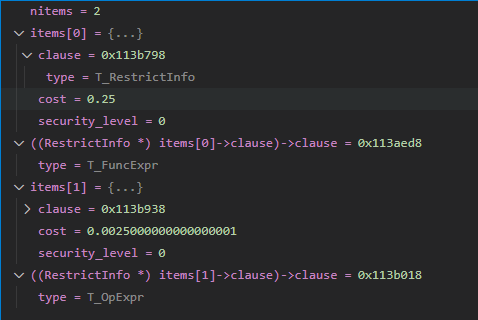
}可以很显眼的看到有一个很明显的收集成本的函数,然后后面紧接着一个排序逻辑。在还没排序之前,数据分别如下。这里需要简单说明一下的是,FuncExpr代表的即为checkvalue(a) 成本为0.25,OpExpr则代表的是a > 0 成本为0.0025。
之后便按照排序规则进行排序,也就是这段,可以自行带入一下数据。
for (i = 1; i < nitems; i++)
{
QualItem newitem = items[i];
int j;
/* insert newitem into the already-sorted subarray */
for (j = i; j > 0; j--)
{
QualItem *olditem = &items[j - 1];
if (newitem.security_level > olditem->security_level ||
(newitem.security_level == olditem->security_level &&
newitem.cost >= olditem->cost))
break;
items[j] = *olditem;
}
items[j] = newitem;
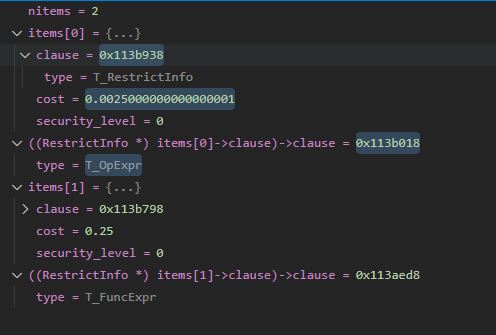
}最后排完序的结果,就变成了最后的样子,二者发生了调换,后面生成完整的执行计划,执行器按照计划执行优先处理a > 0,是不是简简单单~~~
有的朋友看到了这,估计很好奇这些个成本又是怎么来的,或者说是为啥a > 0的成本这么低,才0.0025。而checkvalue(a)的成本却来到了0.25,二者的差距整整100倍。
这里就需要对PostgreSQL的操作符要有一点理解,需要有点返璞归真的意思。
如果能正确的认识到就是在PostgreSQL中操作符的本质其实就是函数,更过分一点的说法就是在PostgreSQL中操作符是”语法糖“一般的存在,就会变得非常的好理解。
所以其实下面的语句是等价的。
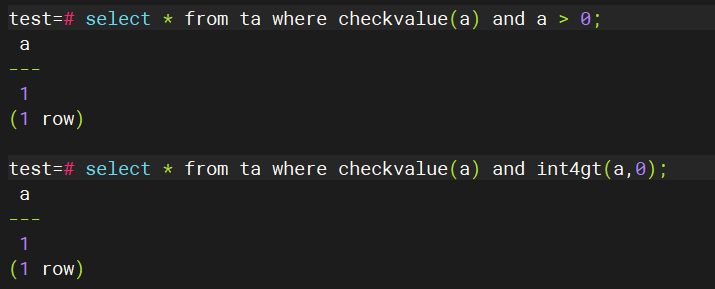
而这一百倍的答案就浮出了水面。

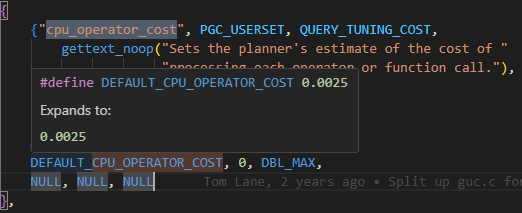
说到了这,这0.0025是啥,我也就不藏着掖着了。其实就是cpu_operator_cost的默认值。
对成本计算感兴趣的朋友可以看看内核的cost_qual_eval_walker函数,关于函数成本计算的内核函数则是add_function_cost,我这里就不在拓展了~
三、验证
好了,经过上面一堆的掰扯,我们的一个简单结论是对于这种场景,where子句中的执行顺序就是按照成本来排序的,因此不同的成本将会导致同一条SQL产生不一样的最终结果,让我们来简单验证一下,收个尾~
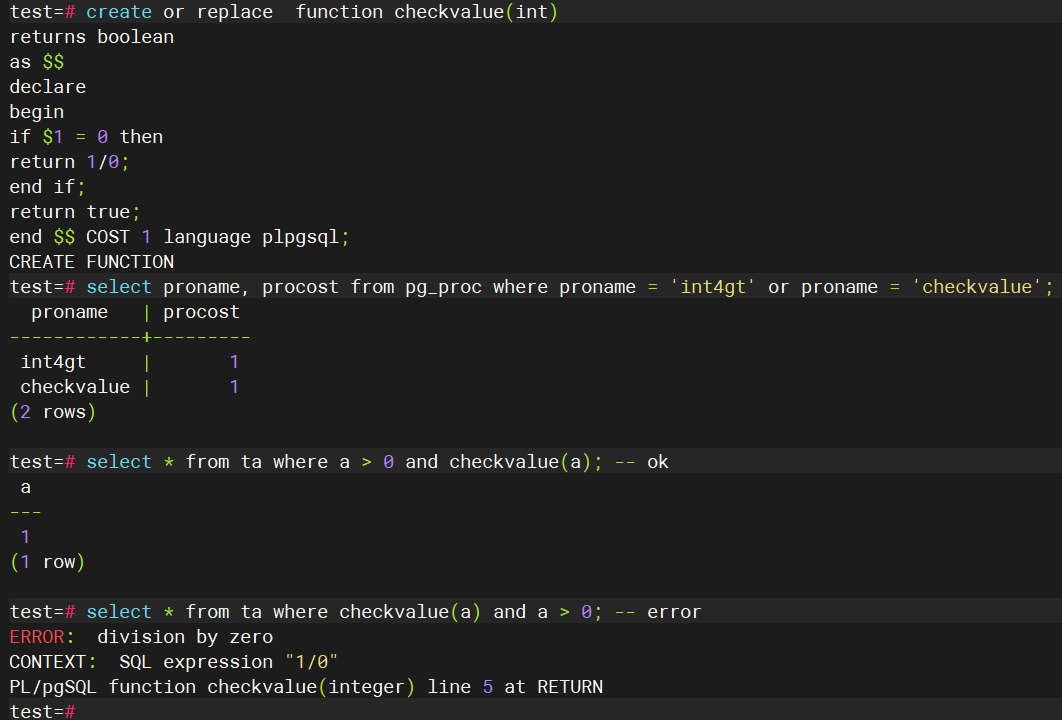
我们先将checkvalue这个函数的cost设置为1和int4gt保持一致。结果如下图,可以看到的是,当成本一致的时候,结果就取决于where子句中的输入顺序。
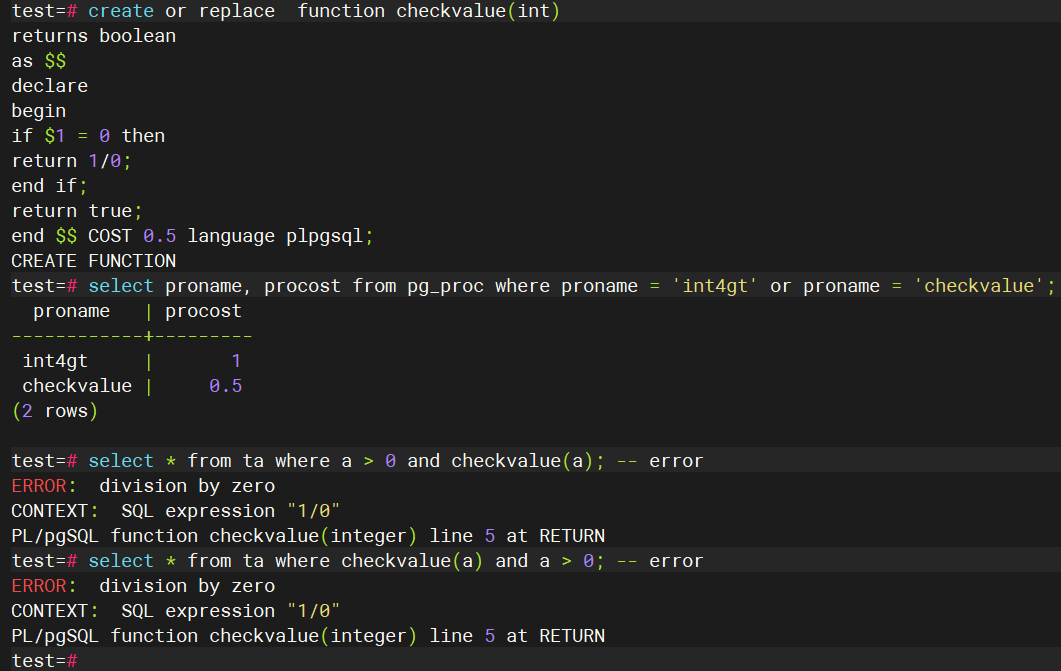
而当我们将checkvalue的cost降至比1还要小(比如说0.5)的时候,结果如下图,此时无论什么样的顺序,都将是checkvalue优先执行,和最开始时的现象完全相反。
四、声明
若文中存在错误或不当之处,敬请指出,以便我进行修正和完善。希望这篇文章能够帮助到各位。
文章转载请联系,谢谢合作。
