




关于 PolarDB PostgreSQL 版
PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。
简介
在使用PostgreSQL数据库过程中,对SQL调优最常用的手段是使用explain查看执行计划,很多时候我们只关注了执行计划的结果而未深入了解执行计划是如何生成的。优化器作为数据库核心功能之一,也是数据库的“大脑”,理解优化器将有助于我们更好地优化SQL,下面将会为大家解开PostgreSQL优化器神秘的面纱。
SQL执行过程

在PG数据库中,对于DDL语句无需进行优化,到utility模块处理,对于DML语句需要到优化器中处理,一个用户连接从接收SQL到执行的流程如下: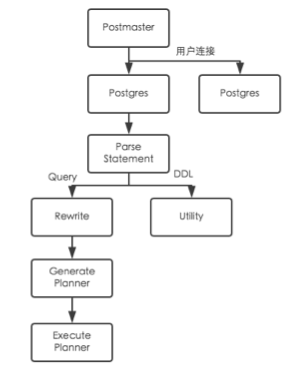
查询重写
主要目的是为了消除view、rule等,如下示例,视图v_t_1_2在执行计划里面已经被t1、t2替换。
create view v_t_1_2 as SELECT t1.a1, t1.b1, t2.a2, t2.b2 FROM t1, t2;
postgres=> explain select * from v_t_1_2, t1 where v_t_1_2.a1 = 10 and t1.b1 = 20; QUERY PLAN
-------------------------------------------------------------------------------------
Nested Loop (cost=0.55..41.59 rows=1000 width=24)
-> Nested Loop (cost=0.55..16.60 rows=1 width=16)
-> Index Scan using t1_a1_key on t1 t1_1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (a1 = 10)
-> Index Scan using b1_1 on t1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (b1 = 20)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=8)
(7 rows)复制
提升子链
目标是将IN和exists子句递归提升。
select * from t1 where t1.a1 in (select t2.a2 from t2 where t2.b2 = 10); 假设t2.a2为unique
转化为:
select t1.a1,t1,a2 from t1 join t2 where t1.a1=t2.a2 and t2.b2 = 10;
in子链接执行计划如下:
postgres=> explain select * from t1 where t1.a1 in (select t2.a2 from t2 where t2.b2 = 10);
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.28..25.80 rows=1 width=8)
-> Seq Scan on t2 (cost=0.00..17.50 rows=1 width=4)
Filter: (b2 = 10)
-> Index Scan using t1_a1_key on t1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (a1 = t2.a2)复制
explain select * from t1 where exists (select t2.a2 from t2 where t2.a2 = t1.a1) ; 假设t2.a2为unique
转化为:
select t1.a1, t1.b1 from t1, t2 where t1.a1=t2.a1;
exists子链接执行计划如下:
postgres=> explain select * from t1 where exists (select t2.a2 from t2 where t2.a2 = t1.a1) ;
QUERY PLAN
-----------------------------------------------------------------
Hash Join (cost=26.42..54.69 rows=952 width=8)
Hash Cond: (t2.a2 = t1.a1)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=4)
-> Hash (cost=14.52..14.52 rows=952 width=8)
-> Seq Scan on t1 (cost=0.00..14.52 rows=952 width=8)
(5 rows)复制
提升子查询
子查询和子链接区别:子查询不在表达式中子句,子链接在in/exists表达式中的子句。
select * from t1, (select * from t2) as c where t1.a1 = c.a2;
转化为:
select * from t1, t2 where t1.a1 = t2.a2;
postgres=> explain select * from t1, (select * from t2) as c where t1.a1 = c.a2;
QUERY PLAN
-----------------------------------------------------------------
Hash Join (cost=26.42..54.69 rows=952 width=16)
Hash Cond: (t2.a2 = t1.a1)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=8)
-> Hash (cost=14.52..14.52 rows=952 width=8)
-> Seq Scan on t1 (cost=0.00..14.52 rows=952 width=8)
(5 rows)复制
并不是所有的子查询都能提升,含有集合操作、聚合操作、sort/limit/with/group、易失函数、from为空等是不支持提升的。
如下:
postgres=> explain select t1.a1 from t1, (select a2 from t2 limit 1) as c where c.a2 = 10;
QUERY PLAN
------------------------------------------------------------------------
Nested Loop (cost=0.00..24.07 rows=952 width=4)
-> Subquery Scan on c (cost=0.00..0.03 rows=1 width=0)
Filter: (c.a2 = 10)
-> Limit (cost=0.00..0.01 rows=1 width=4)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=4)
-> Seq Scan on t1 (cost=0.00..14.52 rows=952 width=4)
(6 rows)复制
化简条件
包含逻辑推理、表达式计算等




