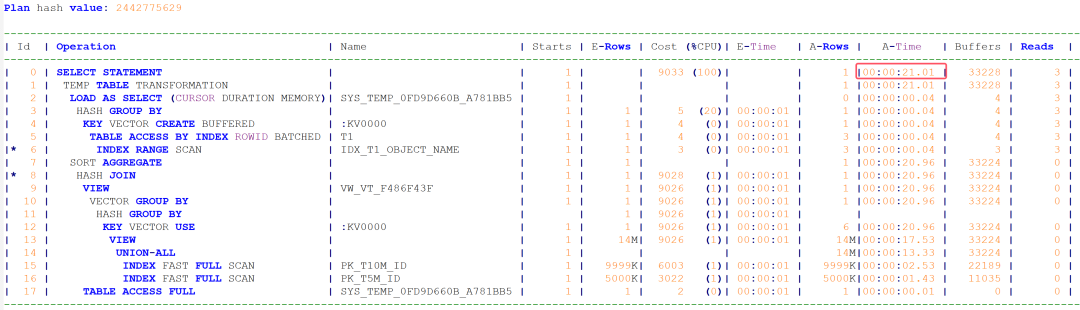
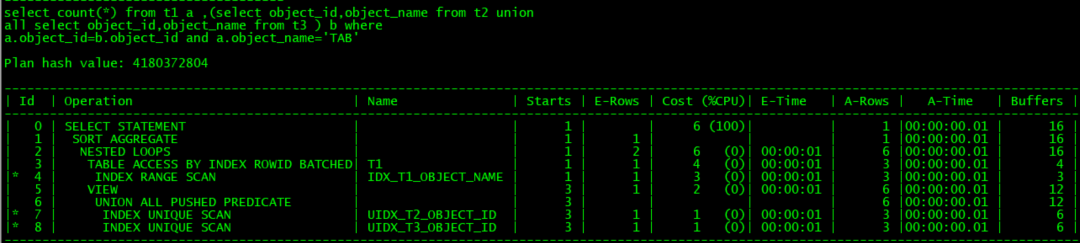
这个问题是我在测试时偶然发现的,找了一些bugs fixed lists,没有找到相关说明.select count(*) from t1 a
,(select id,object_name from t10m
union all
select id,object_name from t5m
) b
where a.object_id=b.id
and a.object_name='TAB';
其中t1表是从dba_objects复制而来,object_name字段上有索引; t10m表是t1复制多次到记录数1000万条,id是主键; t5m 表是t1 复制多次到记录数500万条, id是主键.19.3 版本的执行计划如下,执行时间不到0.01秒:19.19版本的执行计划如下, 执行时间21秒, 性能下降非常严重:19.19版本,如果把t10m和t5m换成t2,t3 两个类似t1的小表, 执行计划又正常了:Note
-----
- vector transformation used for this statement
根据上面提示,检查vector相关参数设置, 有如下发现:_optimizer_vector_min_fact_rows 10000000测试SQL使用的t10m表刚好1000万记录, 于是将改参数调大再测:alter session set "_optimizer_vector_min_fact_rows"=50000000; 这个问题不知道是在19c的哪个patch版本引入的, 如果你的系统存在类似SQL,如果相关表的记录数超过了1000万, 应该已经遇到了这个性能严重下降的问题. 如果相关表的记录数不到1000万,但是仍在逐渐增长, 那么就存在一个隐患,当表的记录数增长到1000万, 收集了统计信息后, 执行计划就会变差, 严重影响系统性能.我没有找到官方相关workaround, 我的建议是修改上述隐含参数,调大.