




前言
小A是一名练习PG两年半的DBA,某天被业务研发小B连环call并贴脸输出:“破PG,一个简单SQL跑了几十分钟都跑不出结果,真垃圾!!!”。小A也是出了名的暴脾气,毫不客气问候了对方之后立即开始分析。
最终分析下来是业务侧建了42亿的大对象,OID回卷,创建大对象的SQL一直在执行不能结束。
小B不断追问,到底多久能跑完?小A答复:”别等了,这SQL两年半也跑不完“。
一说“两年半”,小B更生气了…
小A梳了梳中分就开始科普,深入讲解了这个问题,以及业务使用的正确姿势。
分析
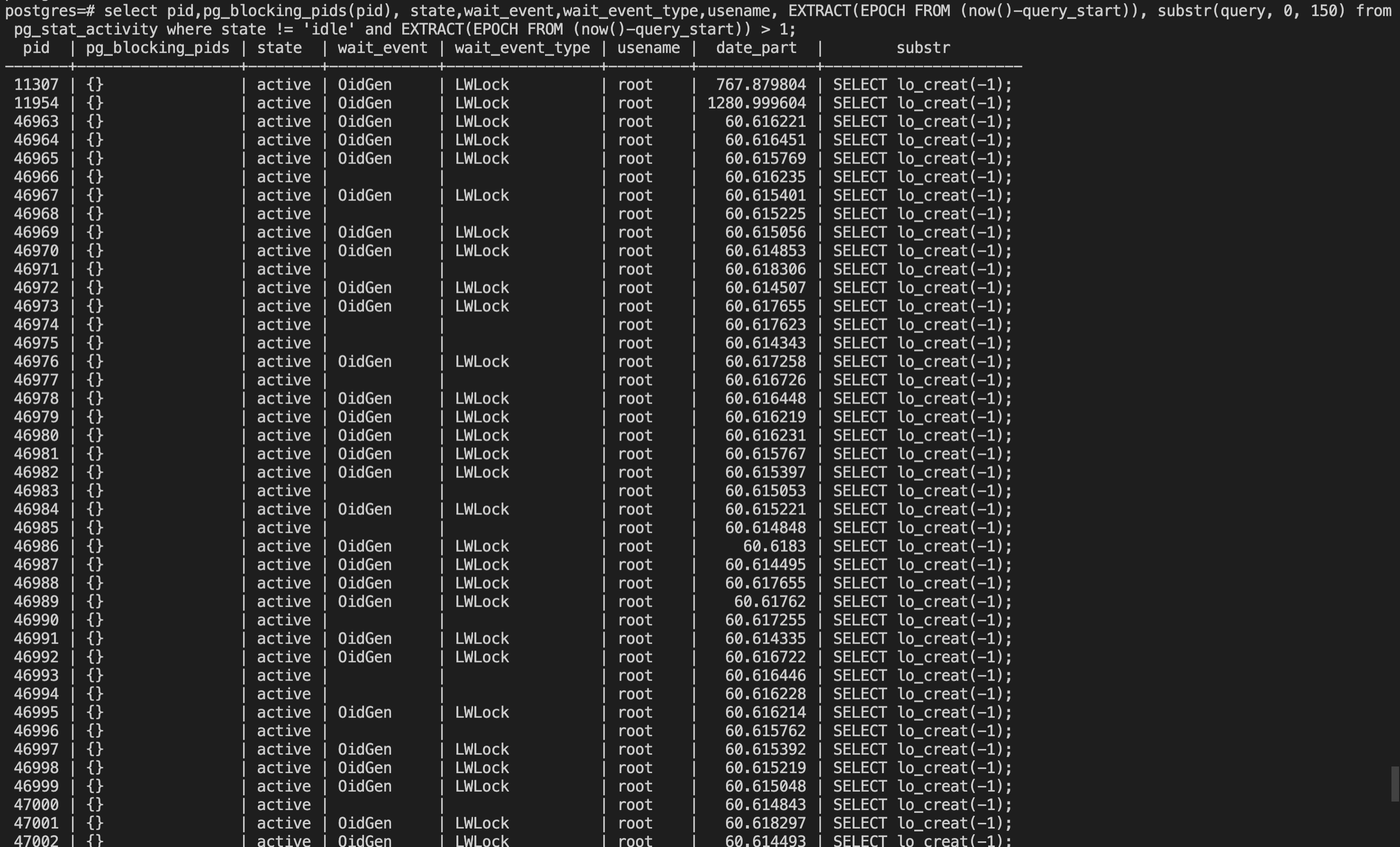
先看现场,业务调SELECT lo_creat(-1)创建新的大对象,一直在执行无法返回。
并且存在大量的LWLock类型的OidGen等待事件,这个等待事件说明这些进程在等待获取OID。
讲述OID的概念:OID即Object Identifiers指的是表,函数、等数据库对象的标识,是unsigned int类型,最大取值为2^32 - 1(4294967295)。一般在系统表中OID字段为主键或者唯一键。
从官方文档看,调用lo_creat(-1)是创建一个未使用的大对象并返回OID。
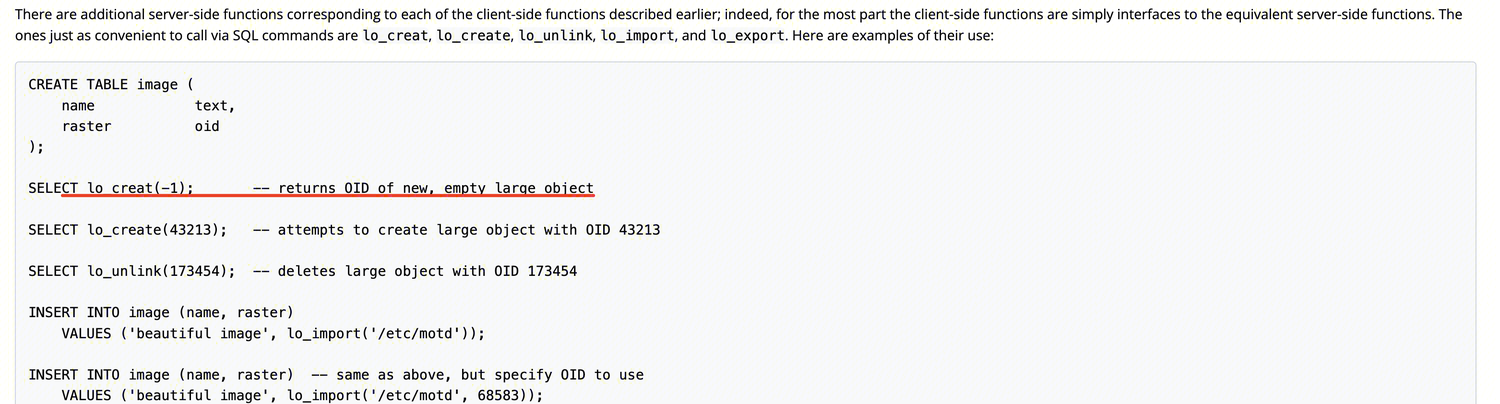
lo_creat是一个服务端函数,从定义看是SQL直接去调用内核函数be_lo_creat。
postgres=# \sf lo_creat
CREATE OR REPLACE FUNCTION pg_catalog.lo_creat(integer)
RETURNS oid
LANGUAGE internal
STRICT
AS $function$be_lo_creat$function$
postgres=#
抓取其中几个进程的火焰图,大致如下:

热点函数集中在LWLockAttemptLock和_bt_compare
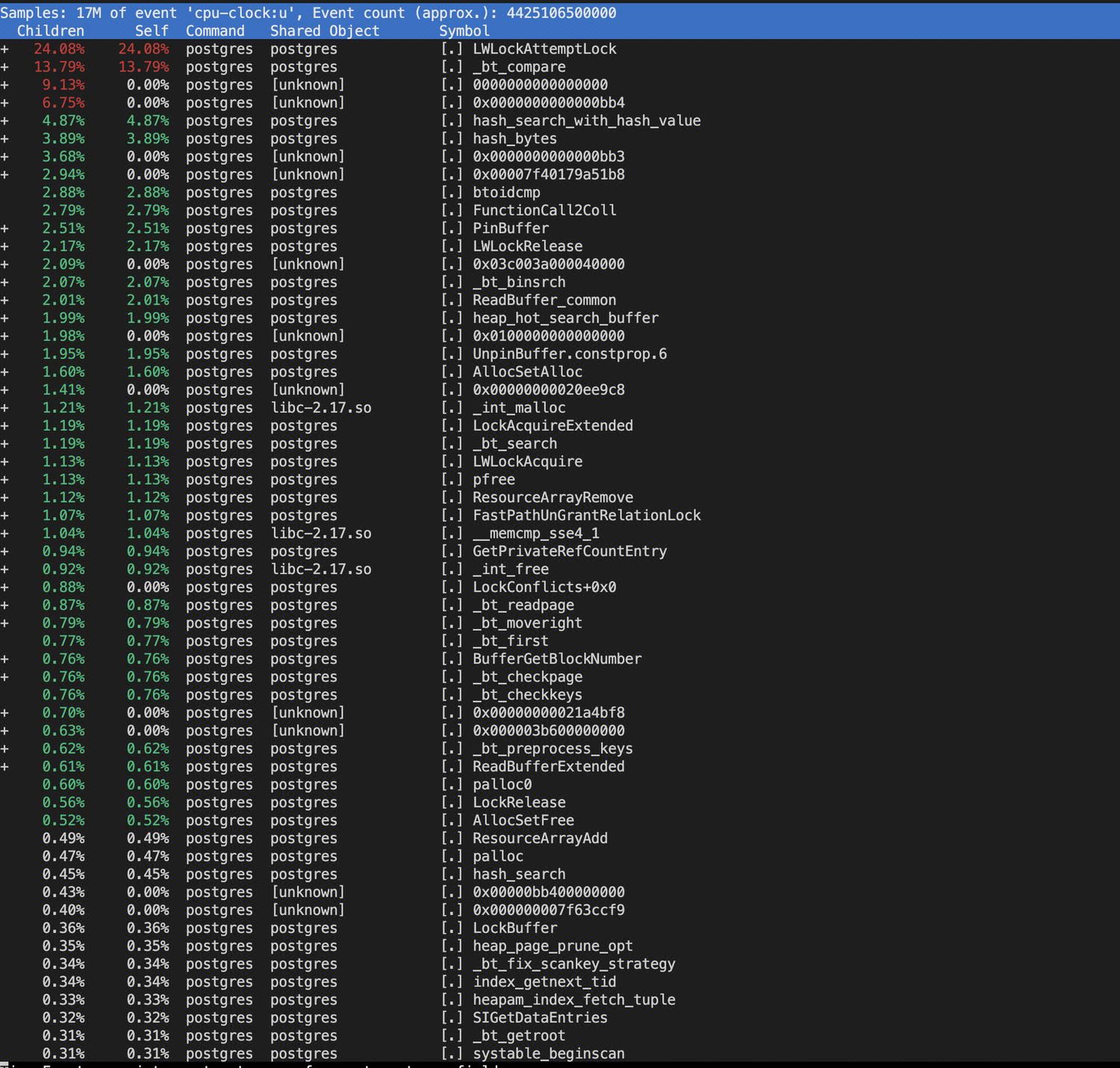
LWLockAttemptLock函数和LWlock加锁相关,在这个case里主要是用来获取OID,_bt_compare从函数命名就可以看出和Btree IndexScan相关。
所以lo_creat(-1)函数一直不返回结果主要是在访问共享内存/临界区,同时一直在执行IndexScan。
说明进程没hang死,当然直接打堆栈也可以看到堆栈一直在变化。
要想知道原因,那么必须从堆栈着手结合源码进行分析。
从堆栈可以看到从be_lo_creat到_bt_compare的调用链路,多次打印堆栈后,发现一个现象:只是GetNewOidWithIndex函数以上的调用栈一直在变化,以下没变化,因此突破口就是这个函数了。
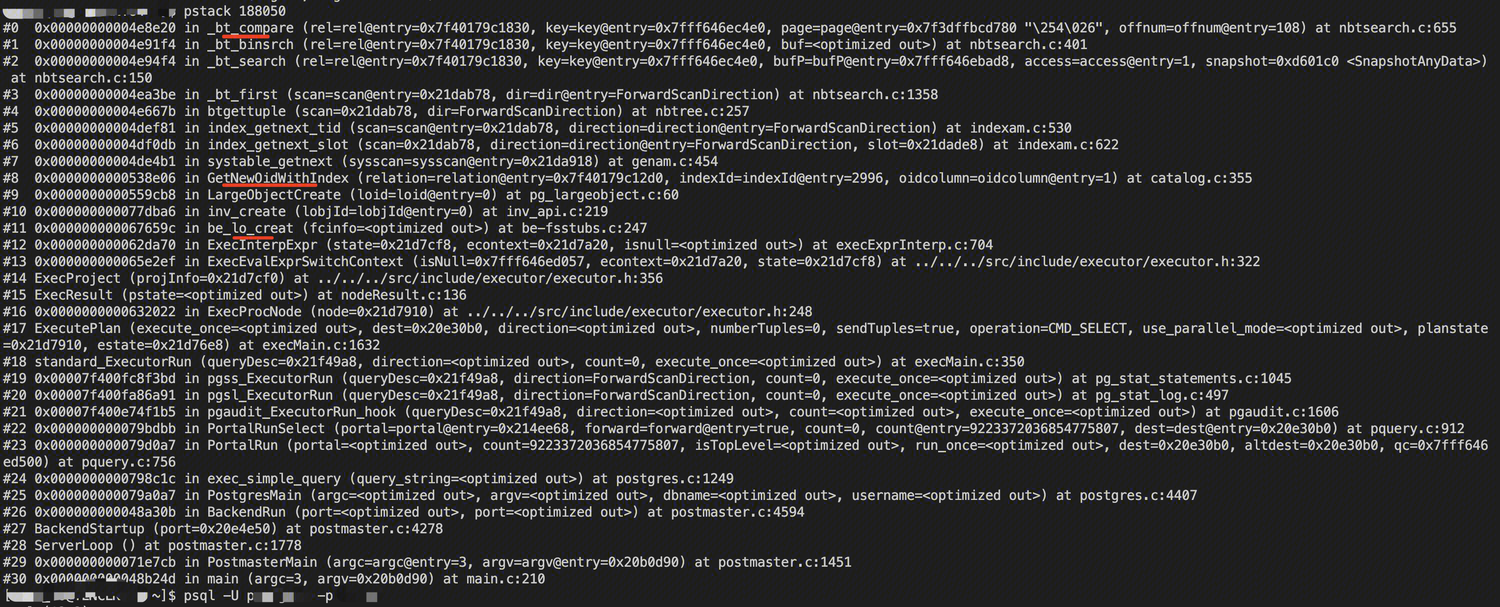
GetNewOidWithIndex:
关键步骤解读见中文注释
/*
* GetNewOidWithIndex
* Generate a new OID that is unique within the system relation.
*
* Since the OID is not immediately inserted into the table, there is a
* race condition here; but a problem could occur only if someone else
* managed to cycle through 2^32 OIDs and generate the same OID before we
* finish inserting our row. This seems unlikely to be a problem. Note
* that if we had to *commit* the row to end the race condition, the risk
* would be rather higher; therefore we use SnapshotAny in the test, so that
* we will see uncommitted rows. (We used to use SnapshotDirty, but that has
* the disadvantage that it ignores recently-deleted rows, creating a risk
* of transient conflicts for as long as our own MVCC snapshots think a
* recently-deleted row is live. The risk is far higher when selecting TOAST
* OIDs, because SnapshotToast considers dead rows as active indefinitely.)
*
* Note that we are effectively assuming that the table has a relatively small
* number of entries (much less than 2^32) and there aren't very long runs of
* consecutive existing OIDs. This is a mostly reasonable assumption for
* system catalogs.
*
* Caller must have a suitable lock on the relation.
*/
Oid
GetNewOidWithIndex(Relation relation, Oid indexId, AttrNumber oidcolumn)
{
Oid newOid;
SysScanDesc scan;
ScanKeyData key;
bool collides;
/* Only system relations are supported */
Assert(IsSystemRelation(relation));
/* In bootstrap mode, we don't have any indexes to use */
if (IsBootstrapProcessingMode())
return GetNewObjectId();
/*
* We should never be asked to generate a new pg_type OID during
* pg_upgrade; doing so would risk collisions with the OIDs it wants to
* assign. Hitting this assert means there's some path where we failed to
* ensure that a type OID is determined by commands in the dump script.
*/
Assert(!IsBinaryUpgrade || RelationGetRelid(relation) != TypeRelationId);
/* Generate new OIDs until we find one not in the table */
do
{
CHECK_FOR_INTERRUPTS();
// 1、获取本次要创建对象的OID
newOid = GetNewObjectId();
// 2、使用对象的OID生成键值
ScanKeyInit(&key,
oidcolumn,
BTEqualStrategyNumber, F_OIDEQ,
ObjectIdGetDatum(newOid));
/* see notes above about using SnapshotAny */
// 3、查询对象对应的元数据系统表,检索本次生成的OID是否在系统表中已存在(这里是创建大对象,对应系统表为pg_largeobject_metadata),这里走系统表的indexscan(一般都是系统表的oid字段,是唯一键)
scan = systable_beginscan(relation, indexId, true,
SnapshotAny, 1, &key);
// 4、如果查询结果不为NULL,也就是说系统表里已存在这个OID,则collides为true
collides = HeapTupleIsValid(systable_getnext(scan));
systable_endscan(scan);
// 5、当collides为true时,一直处于while循环中,重复以上步骤
} while (collides);
return newOid;
}
所以,在这个函数中通过调用GetNewObjectId()获取到一个OID,去当前要创建对象的元数据系统表检索是否OID已经被占用,如果被占用则,继续循环,直到找到没占用的OID才结束循环。
OID是一个有范围的值,假使已使用到最大42亿左右,扫描系统表42亿条数据并且还是走索引扫描,就算时间久一些但总会结束。从我们的观察来看,这个case感觉是一直在while循环中重复扫描,就像进入了“逻辑死循环”。
那么这里还有一个问题,OID到最大值后,GetNewObjectId()获取到的下一个OID会是什么?
GetNewObjectId:
关键步骤解读见中文注释
/*
* GetNewObjectId -- allocate a new OID
*
* OIDs are generated by a cluster-wide counter. Since they are only 32 bits
* wide, counter wraparound will occur eventually, and therefore it is unwise
* to assume they are unique unless precautions are taken to make them so.
* Hence, this routine should generally not be used directly. The only direct
* callers should be GetNewOidWithIndex() and GetNewRelFileNode() in
* catalog/catalog.c.
*/
Oid
GetNewObjectId(void)
{
Oid result;
/* safety check, we should never get this far in a HS standby */
if (RecoveryInProgress())
elog(ERROR, "cannot assign OIDs during recovery");
// 1、上来直接加LWLock排它锁,因为这里涉及到修改共享内存中的变量。加锁成功后,其他进程运行到这里需要等锁,即对应LWLock类型的OidGen等待事件
LWLockAcquire(OidGenLock, LW_EXCLUSIVE);
/*
* Check for wraparound of the OID counter. We *must* not return 0
* (InvalidOid), and in normal operation we mustn't return anything below
* FirstNormalObjectId since that range is reserved for initdb (see
* IsCatalogRelationOid()). Note we are relying on unsigned comparison.
*
* During initdb, we start the OID generator at FirstBootstrapObjectId, so
* we only wrap if before that point when in bootstrap or standalone mode.
* The first time through this routine after normal postmaster start, the
* counter will be forced up to FirstNormalObjectId. This mechanism
* leaves the OIDs between FirstBootstrapObjectId and FirstNormalObjectId
* available for automatic assignment during initdb, while ensuring they
* will never conflict with user-assigned OIDs.
*/
// 2、读取当前ShmemVariableCache->nextOid,是否小于FirstNormalObjectId即16384
if (ShmemVariableCache->nextOid < ((Oid) FirstNormalObjectId))
{
if (IsPostmasterEnvironment)
{
/* wraparound, or first post-initdb assignment, in normal mode */
// 3、如果是首次获取OID或者已经发生OID回卷,则重新赋值16384
ShmemVariableCache->nextOid = FirstNormalObjectId;
ShmemVariableCache->oidCount = 0;
}
else
{
/* we may be bootstrapping, so don't enforce the full range */
if (ShmemVariableCache->nextOid < ((Oid) FirstBootstrapObjectId))
{
/* wraparound in standalone mode (unlikely but possible) */
ShmemVariableCache->nextOid = FirstNormalObjectId;
ShmemVariableCache->oidCount = 0;
}
}
}
/* If we run out of logged for use oids then we must log more */
if (ShmemVariableCache->oidCount == 0)
{ // 4、持久化OID
XLogPutNextOid(ShmemVariableCache->nextOid + VAR_OID_PREFETCH);
ShmemVariableCache->oidCount = VAR_OID_PREFETCH;
}
// 5、oid传递到result变量
result = ShmemVariableCache->nextOid;
// 6、Nextoid计算,下次获取的值为当前+1,这里也就是为什么一开始就加LWLock排它锁
(ShmemVariableCache->nextOid)++;
(ShmemVariableCache->oidCount)--;
// 7、释放LWLock
LWLockRelease(OidGenLock);
// 8、返回result
return result;
}
所以OID的计数nextOid是整个实例共享的,实例拉起时记录到共享内存,定时持久化到XLOG 和pg_control。
当OID到最大值时,OID++溢出,计算值为0,不过在GetNewObjectId里会重置为16384,所以我们可以理解为如果调用GetNewObjectId获取OID,OID的值从16384到4294967295之间一直循环。
所以这个case一直在处于“逻辑死循环”:是由于大对象的OID从 16384–4294967295都已经被使用了,每次从16384开始遍历pg_largeobject_metadata,直到遍历到4294967295在系统表里都有值,下一步OID溢出,又从16384开始下一轮遍历,这样就进入了“逻辑死循环”的状态。
从16384到4294967295,共有4294950912个值,我们看下pg_largeobject_metadata表的情况:
nickdb=# select max(oid) from pg_largeobject_metadata;
max
------------
4294967295
(1 row)
nickdb=# select count(1) from pg_largeobject_metadata;
count
------------
4294950912
(1 row)
nickdb=# select min(oid) from pg_largeobject_metadata;
min
-------
16384
(1 row)
max(oid)为:4294967295
count总数为:4294950912
min(oid)为:16384
至此,真像大白。大对象创建了4294950912个,已经用满,无法继续创建了,创建大对象的sql一直循环扫描系统表。
要解决的话,只能是清理不需要的对象。
还有个问题,可能有朋友觉得oid溢出应该报错处理,这里允许一直循环溢出是有问题的?
其实不是,这个策略是合理的,我举个简单例子。
比如我现在对象的oid到4294967295了,下一步就溢出了,但是我oid为100000000至200000000的对象已经删除,这样溢出后,从16384开始遍历到100000000又可以重复利用这些oid了,不是说就只能是一直递增,可以回收重用的。
oid溢出只会影响到数量已用满的对象的创建,比如我这里大对象为4294950912个,所以无法创建大对象。但是可以创建表,因为表的数量还很少,也就451个。
nickdb=# select count(1) from pg_class;
count
-------
451
(1 row)
nickdb=# create table dba_users (userid int,username varchar(32));
CREATE TABLE
nickdb=#
小A装逼结束,反问小B,业务为什么创建42亿个大对象,并且不清理。小B没有正面回答,只是讲这属于历史问题,在它接手前就是如此。
小结
小A总结如下:
1、oid的nextOid是整个实例共享的,oid可以一直循环溢出回卷,oid回卷时,对于一些数量已经用满的对象就无法继续创建了。
2、业务要做好设计,不要无休止创建对象,无用的对象及时清理,以免对象数用满。
小B梳了梳中分,表示不屑:“我还以为有什么了不起的,不就是每种对象不能创建超过4294950912个吗?”
小A笑着回复到:“假如这个对象是表呢,可以创多少个?”
小B突然意识到不能继续顺着小A的节奏探讨下去了,于是提出灵魂拷问:“请问为什么OID没有做监控,对象数没有做监控?这个问题你我都有责任!”
小A也不好多说什么,讲述了一下对监控的想法。
1、监控OID:
执行select next_oid from pg_control_checkpoint();即可,设定一个阈值,达到阈值就触发告警。
2、监控对象数:
另外,我觉得更关键的是监控各系统表的记录数,因为即使oid溢出回卷也只有这些数量用满的对象才受影响,这些对象对应的系统表的记录也满了(最大42亿左右)。
监控系统表条目的sql:
可以根据需要增加需要监控的系统表,达到阈值就触发告警。
nickdb=# select relname,n_live_tup from pg_stat_all_tables where relname in ('pg_largeobject_metadata','pg_class');
relname | n_live_tup
-------------------------+------------
pg_class | 452
pg_largeobject_metadata | 4294950912
(2 rows)
nickdb=#
故事讲完,马上就到春节了,小A问候了小B全家,同时也祝大家春节快乐!!!
