




1 模型描述
1.1 特征选取
我们需要从用户行为日志中提取出与用户流失相关的特征。在本模型中,我们选择以下几个特征:
最近一次登录距今天数(last_login_diff):反映用户的活跃程度。 近30天登录次数(login_count_30d):反映用户的登录频率。 近30天消费总金额(purchase_amount_30d):反映用户的消费能力。 近30天活跃天数(activity_days_30d):反映用户的参与度。
1.2 评分模型的构建
基于评分卡模型进行模型构建
根据特征的重要性,为每个特征分配一个权重,并计算每个用户的加权评分。
特征与权重说明
1.3 高风险用户识别
将评分高于某个阈值的用户识别为高风险用户。
风险等级划分
2 数据准备
2.1 用户表结构和数据
假设有一个名为user_behavior的用户行为日志表,包含以下字段:
user_id(INT):用户ID
login_time(STRING):登录时间
purchase_amount(DOUBLE):消费金额
activity_days(INT):活跃天数
示例数据:
2.2 SQL建表及数据
drop table user_behavior;CREATE TABLE IF NOT EXISTS user_behavior (user_id INT,login_time STRING,purchase_amount DOUBLE,activity_days INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t'STORED AS TEXTFILE;INSERT INTO TABLE user_behaviorVALUES(1, '2025-01-01 10:00', 100, 10),(1, '2025-01-21 10:00', 10, 10),(2, '2024-12-29 12:00', 50, 5),(3, '2024-12-02 15:00', 200, 15),(4, '2024-11-01 08:00', 10, 2),(5, '2024-12-03 09:00', 150, 8);

3 模型求解
步骤1:特征提取
WITH user_behavior_features AS (SELECTuser_id,-- 计算最近一次登录距今天数datediff(current_date, MAX(login_time)) AS last_login_diff,-- 计算近30天登录次数COUNT(DISTINCT CASE WHEN datediff(current_date, login_time) <= 30 THEN login_time END) AS login_count_30d,-- 计算近30天消费总金额SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN purchase_amount ELSE 0 END) AS purchase_amount_30d,-- 计算近30天活跃天数SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN activity_days ELSE 0 END) AS activity_days_30dFROMuser_behaviorGROUP BYuser_id)SELECTuser_id,last_login_diff,login_count_30d,purchase_amount_30d,activity_days_30dFROMuser_behavior_features;

步骤2:评分模型构建
计算加权评分,由于是风险模型,因此对于登录次数,消费金额以及活跃天数需要进行倒数处理,值越大风险越高WITH user_behavior_features AS (SELECTuser_id,-- 计算最近一次登录距今天数datediff(current_date, MAX(login_time)) AS last_login_diff,-- 计算近30天登录次数COUNT(DISTINCT CASE WHEN datediff(current_date, login_time) <= 30 THEN login_time END) AS login_count_30d,-- 计算近30天消费总金额SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN purchase_amount ELSE 0 END) AS purchase_amount_30d,-- 计算近30天活跃天数SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN activity_days ELSE 0 END) AS activity_days_30dFROMuser_behaviorGROUP BYuser_id),user_churn_score AS (SELECTuser_id,-- 计算加权评分,由于是风险模型,因此对于登录次数,消费金额以及活跃天数需要进行倒数处理,值越大风险越高(0.4 * last_login_diff) +(0.3 * (1.0 / NULLIF(login_count_30d, 0))) +(0.2 * (1.0 / NULLIF(purchase_amount_30d, 0))) +(0.1 * (1.0 / NULLIF(activity_days_30d, 0))) AS churn_scoreFROMuser_behavior_features)SELECTuser_id,churn_scoreFROMuserchurnscore;
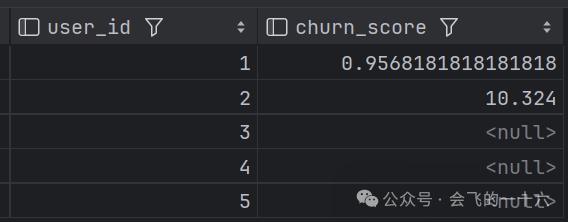
步骤3:用户风险等级划分
使用ntile()函数将用户划分为不同的风险等级
WITH user_behavior_features AS (SELECTuser_id,-- 计算最近一次登录距今天数datediff(current_date, MAX(login_time)) AS last_login_diff,-- 计算近30天登录次数COUNT(DISTINCT CASE WHEN datediff(current_date, login_time) <= 30 THEN login_time END) AS login_count_30d,-- 计算近30天消费总金额SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN purchase_amount ELSE 0 END) AS purchase_amount_30d,-- 计算近30天活跃天数SUM(CASE WHEN datediff(current_date, login_time) <= 30 THEN activity_days ELSE 0 END) AS activity_days_30dFROMuser_behaviorGROUP BYuser_id),user_churn_score AS (SELECTuser_id,-- 计算加权评分,由于是风险模型,因此对于登录次数,消费金额以及活跃天数需要进行倒数处理,值越大风险越高(0.4 * last_login_diff) +(0.3 * (1.0 / NULLIF(login_count_30d, 0))) +(0.2 * (1.0 / NULLIF(purchase_amount_30d, 0))) +(0.1 * (1.0 / NULLIF(activity_days_30d, 0))) AS churn_scoreFROMuser_behavior_features),user_risk_level AS (SELECTuser_id,churn_score,NTILE(100) OVER (ORDER BY churn_score DESC) AS risk_percentileFROMuser_churn_score)SELECTuser_id,churn_score,risk_percentile,CASEWHEN risk_percentile <= 20 THEN '高风险'WHEN risk_percentile <= 50 THEN '中风险'ELSE '低风险'END AS risklevelFROMuser_risk_level;

4 模型优化
4.1 特征工程优化
- 特征衍生
:利用 SQL 计算新的特征。比如,计算用户的平均每次消费金额,可通过 “近 30 天消费总金额” 除以 “近 30 天购买次数” 得到。假设购买次数字段为 purchase_count_30d
,消费总金额字段为purchase_amount_30d
,则 SQL 语句为
SELECT user_id , purchase_amount_30d / NULLIF(purchase_count_30d, 0) AS avg_purchase_amount_30dFROM user_behavior_features; 这里NULLIF用于避免除零错误。
- 特征组合
将多个特征组合成新特征。如将 “近 30 天登录次数” 和 “近 30 天活跃天数” 组合为一个活跃度综合指标,可设定规则:若登录次数多且活跃天数多则活跃度高。
示例 SQL:
SELECT user_id,CASEWHEN login_count_30d > 10 AND activity_days_30d > 20 THEN 'high'WHEN login_count_30d > 5 AND activity_days_30d > 10 THEN 'medium'ELSE 'low' END AS combined_activity_levelFROM user_behavior_features;
4.2 模型构建优化
- 动态权重调整
在计算用户流失评分时,可根据不同时间段或用户群体动态调整特征权重。例如,在促销活动期间,“近 30 天消费总金额” 权重可适当提高。假设在特定活动期间权重调整为 0.3(原为 0.2),SQL 代码调整为:
WITH user_churn_score AS (SELECT user_id,(0.4 * last_login_diff) + (0.3 * (1.0/NULLIF(login_count_30d,0))) +(0.3 * (1.0/NULLIF(purchase_amount_30d,0))) + (0.1 * (1.0/NULLIF(activity_days_30d,0))) AS churn_scoreFROM user_behavior_features)SELECT user_id, churn_score FROM user_churn_score;
- 分群建模
针对不同用户群体分别构建流失评分模型。比如按用户年龄分群,先创建年龄分组:
SELECT user_id,CASE WHEN age < 18 THEN 'teenager' WHEN age >= 18 AND age < 30 THEN 'young_adult' ELSE 'adult' END AS age_groupFROM user_profile;
然后针对每个年龄组分别计算流失评分,可通过JOIN
操作关联用户行为特征表和年龄分组表,在不同分组内计算评分。
4.3 模型评估优化
- 分层抽样评估
使用 NTILE
函数进行分层抽样,将用户按流失评分分成若干层(如 10 层),从每层中抽取一定比例样本用于评估。例如,将用户按流失评分从高到低分成 10 层,每层抽取 10% 样本:
WITH user_risk_level AS (SELECT user_id, churn_score, NTILE(10) OVER (ORDER BY churn_score DESC) AS risk_percentileFROM user_churn_score),sampled_users AS (SELECT user_id, churn_score, risk_percentileFROM user_risk_levelWHERE (risk_percentile, RAND()) IN(SELECT risk_percentile, MIN(RAND()) FROM user_risk_level GROUP BY risk_percentile))SELECT *FROM sampled_users;
这样能更全面评估模型在不同风险等级用户中的表现。
往期回顾
SQL进阶技巧:如何分析连续签到领金币数问题?
SQL进阶技巧:如何计算商品需求与到货队列表进出计划?
SQL进阶技巧:Hive中Left Join基于or形式匹配连接的一种优雅实现方式?
文章转载自会飞的一十六,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
