








前情回顾
前面我们介绍了金仓数据库的版本发展脉络,如何安装金仓数据库 KES。在本文中,我们将继续阐述如何使用 KES 数据库的 Docker 镜像,同时分享几个实用的性能优化案例。
金仓数据库 Docker 镜像
从电科金仓官网的下载中心可以直接下载到最新的 Docker 镜像。这里我们选择 x86_64 架构的镜像。
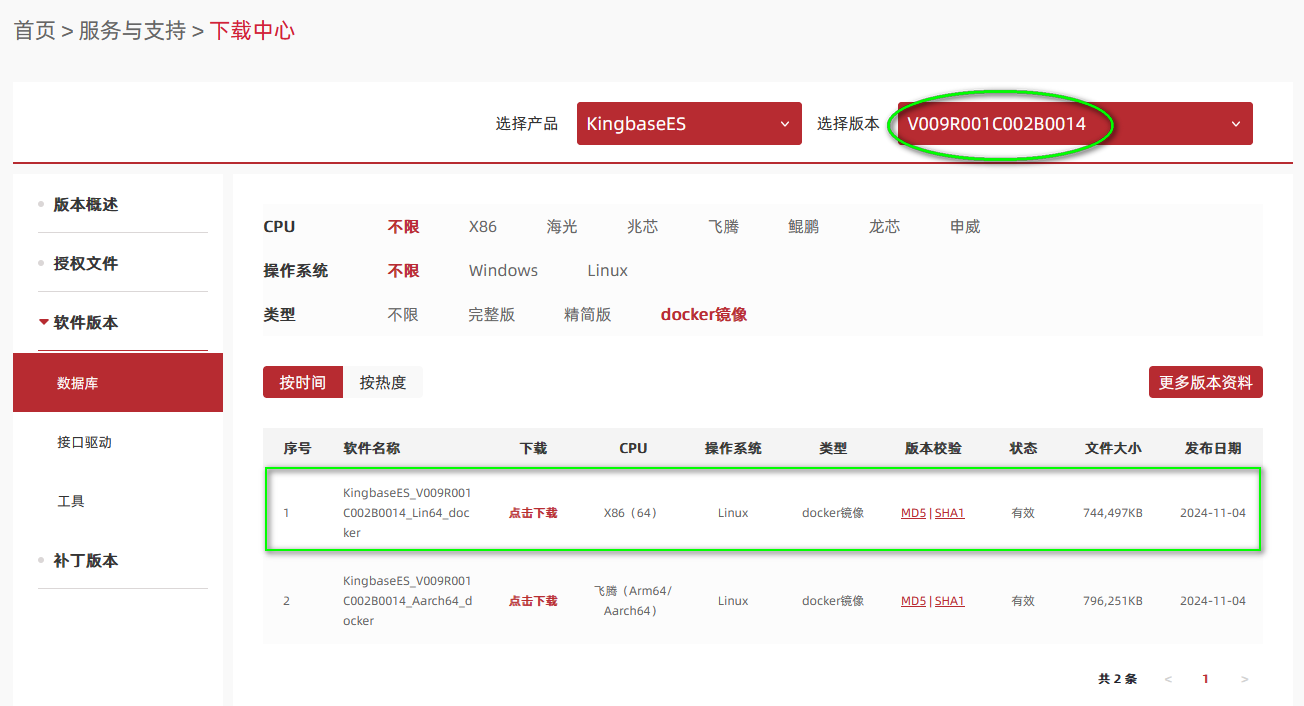
下载完成后上传到服务器,并导入镜像。
[shawnyan@rl9 ~]$ ll -h kdb_x86_64_V009R001C002B0014.tar -rw-r--r-- 1 shawnyan shawnyan 711M Jan 30 22:01 kdb_x86_64_V009R001C002B0014.tar [shawnyan@rl9 ~]$ podman load -i kdb_x86_64_V009R001C002B0014.tar Getting image source signatures ... Loaded image: localhost/kingbase_v009r001c002b0014_single_x86:v1 [shawnyan@rl9 ~]$ podman images REPOSITORY TAG IMAGE ID CREATED SIZE localhost/kingbase_v009r001c002b0014_single_x86 v1 a12899877a42 3 months ago 744 MB复制
接下来,我们可以运行该镜像。
podman run -dit --name kingbase a12899877a42复制
需要注意的是,系统存在以下默认配置:
- 系统用户默认密码:
123 - 数据库默认用户名:
system - 数据库默认密码:
12345678ab - 数据库默认数据目录:
/home/kingbase/userdata/data
容器启动后,数据库会自动运行。我们可以通过以下命令确认数据库的运行状态。
[shawnyan@rl9 ~]$ podman exec -it kingbase sys_ctl status -D /home/kingbase/userdata/data/ sys_ctl: server is running (PID: 100) /home/kingbase/install/kingbase/bin/kingbase "-D" "/home/kingbase/userdata/data"复制
最后,我们可以使用客户端 ksql 连接数据库。
[shawnyan@rl9 ~]$ podman exec -it kingbase ksql -Usystem -dkingbase Type "help" for help. kingbase=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+--------+----------+-------------+-------------+------------------- kingbase | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | security | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | template0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system + | | | | | system=CTc/system template1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system + | | | | | system=CTc/system test | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | (5 rows) kingbase=# \du List of roles Role name | Attributes | Member of ------------+------------------------------------------------------------+----------- kcluster | Cannot login | {} sao | No inheritance, Create role | {} sao_oper | No inheritance, Cannot login | {} sao_public | No inheritance, Cannot login | {} sso | No inheritance, Create role | {} sso_oper | No inheritance, Cannot login | {} sso_public | No inheritance, Cannot login | {} system | Superuser, Create role, Create DB, Replication, Bypass RLS | {} kingbase=# select version(); version ---------------------------------------------------------------------------------------------------------------------- KingbaseES V009R001C002B0014 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28), 64-bit (1 row) kingbase=# show database_mode; database_mode --------------- oracle (1 row) kingbase=#复制
SQL 优化之 Hint
KingbaseES 使用的是基于成本的优化器。该优化器会对 SQL 语句的每个可能的执行计划的成本,然后选择成本最低的执行计划来执行。因为优化器不计算数据的某些属性,比如列之间的相关性,优化器有时选择的计划并不一定是最优的。
Hint 的作用就是通过使用特殊形式的注释中的 Hint 短语来指定执行 SQL 语句所用的执行计划。Hint 为用户提供了直接影响执行计划生成的手段,用户可以通过指定 join 顺序,join、scan 方法,指定结果行数等多个手段来进行执行计划的调优,以提升查询的性能。
需要注意的是,KES 默认禁用了 Hint 特性,需要手动开启,具体操作如下。
kingbase=# show enable_hint ; enable_hint ------------- off (1 row) kingbase=# select sys_reload_conf(); sys_reload_conf ----------------- t (1 row) kingbase=# show enable_hint ; enable_hint ------------- on (1 row)复制
KES V9R1C1B3 对 Hint 功能进行了增强,增加以下 4 种 Hint 类型。
- 并行执行 ParallelAppend(workers)
- 聚集 ParallelHashagg 和 ParallelGroupagg
- 参数化路径行数更正 PRows(table_list table #|+|-|* const)
并行执行 ParallelAppend(workers)
并行执行类型的 Hint,针对 union all 的并行执行,需要在 union all 的外层进行指定,该 Hint 指定查询中的 append 节点强制并行执行。
使用以下脚本创建测试数据。
create table t2(id int, val int); create table t3(id int, val int); create index t2_idx on t2(id); create index t3_idx on t3(id); insert into t2 select i, i%5000 from generate_series(1,1000000) as x(i); insert into t3 select i, i%5 from generate_series(1,100) as x(i); analyze t2; analyze t3;复制
这是一个并行测试用例,需要将并行打开。
set max_parallel_workers_per_gather to 2;复制
查看实际执行计划,确认使用到了 Parallel Append。
kingbase=# explain analyze select /*+ParallelAppend(2)*/ * from (select * from t2 union all select * from t3) a; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------- Gather (cost=0.00..23594.88 rows=1000100 width=8) (actual time=0.543..127.860 rows=1000100 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Append (cost=0.00..23594.88 rows=1000042 width=8) (actual time=0.013..56.308 rows=333367 loops=3) -> Seq Scan on t3 (cost=0.00..2.00 rows=100 width=8) (actual time=0.018..0.024 rows=100 loops=1) -> Parallel Seq Scan on t2 (cost=0.00..8591.67 rows=416667 width=8) (actual time=0.009..30.558 rows=333333 loops=3) Planning Time: 0.240 ms Execution Time: 172.673 ms (8 rows)复制
聚集 ParallelHashagg 和 ParallelGroupagg
测试聚集 Hint,符合预期。
kingbase=# explain select/*+parallelhashagg*/t2.id, count(t3.val) from t2,t3 where t2.id=t3.val group by t2.id; QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Finalize HashAggregate (cost=1017.56..1018.56 rows=100 width=12) Group Key: t2.id -> Gather Merge (cost=1006.07..1017.14 rows=84 width=12) Workers Planned: 2 -> Partial GroupAggregate (cost=6.05..7.42 rows=42 width=12) Group Key: t2.id -> Merge Join (cost=6.05..6.79 rows=42 width=8) Merge Cond: (t2.id = t3.val) -> Parallel Index Only Scan using t2_idx on t2 (cost=0.42..24635.09 rows=416667 width=4) -> Sort (cost=5.32..5.57 rows=100 width=4) Sort Key: t3.val -> Seq Scan on t3 (cost=0.00..2.00 rows=100 width=4) (12 rows)复制
性能优化
在性能优化方面,金仓数据库提供分区表 LIKE 剪枝,以及 UPDATE/DELETE 语句执行时的剪枝优化功能,能够在多级分区表分区数量多、高并发场景下显著提升 SQL 语句查询性能。
同时,系统完善了 DBTime 模型。该模型可以帮助用户衡量数据库负载,精准定位性能瓶颈,从而为性能调优决策提供有力支持,为用户解决问题和分析问题提供了有效的帮助。
分区表执行计划优化
分区表支持范围分区、列表分区、HASH 分区的分区方式以及二级子分区。单表分区个数原则上不建议超过 500 个,全库不超过 10 万个分区。对象过多时,会造成数据字典庞大,数据库整体运行效率明显下降。
分区表执行计划优化,旨在解决高并发场景下分区表子表数量较多时,SELECT/UPDATE/DELETE 计划生成过程中出现的锁问题。
该功能由 GUC 参数 partition_table_limit 控制,0 表示不启用,默认值为 20。
kingbase=# show partition_table_limit ; partition_table_limit ----------------------- 20 (1 row)复制
当经过剪枝后的分区表子表数量超过该参数的值时,将启用该功能快速生成执行计划。否则将按原有逻辑生成执行计划。
分区表执行计划优化适用于以下场景:分区表子表数量较多;分区表上索引数量较多;分区表查询语句中等价类条件较多。
参数 enable_partition_pruning 意为:允许或者禁止查询规划器从查询计划中消除一个分区表的分区。这也控制着规划器产生允许执行器在查询执行期间移除(忽略)分区的查询计划的能力。默认值是 on。
shawnyan=# show enable_partition_pruning ; enable_partition_pruning -------------------------- on (1 row)复制
测试用例如下。
首先,创建一个分区表,及三个子分区,生产测试数据。
create table pt(col1 INT, col2 INT) PARTITION BY RANGE (col1); create table pt_1 partition of pt for values from (0) to (10); create table pt_2 partition of pt for values from (10) to (20); insert into pt select i, i from generate_series(1,19) as x(i);复制
进行点查,查看执行计划是扫描全部分区。
kingbase=# explain analyze select * from pt where col1 = 11; QUERY PLAN ---------------------------------------------------------------------------------------------------- Append (cost=0.00..1.00 rows=1 width=8) (actual time=0.020..0.022 rows=1 loops=1) -> Seq Scan on pt_1 (cost=0.00..0.50 rows=0 width=8) (actual time=0.016..0.016 rows=0 loops=1) Filter: (col1 = 11) Rows Removed by Filter: 9 -> Seq Scan on pt_2 (cost=0.00..0.50 rows=0 width=8) (actual time=0.003..0.004 rows=1 loops=1) Filter: (col1 = 11) Rows Removed by Filter: 9 Planning Time: 0.049 ms Execution Time: 0.041 ms (9 rows)复制
开启分区裁剪后,再次查看执行计划,可以发现这次只扫描 pt_2 分区。
kingbase=# show enable_partition_pruning; enable_partition_pruning -------------------------- on (1 row) kingbase=# explain analyze select * from pt where col1 = 11; QUERY PLAN ---------------------------------------------------------------------------------------------- Seq Scan on pt_2 (cost=0.00..1.00 rows=1 width=8) (actual time=0.021..0.022 rows=1 loops=1) Filter: (col1 = 11) Rows Removed by Filter: 9 Planning Time: 0.064 ms Execution Time: 0.041 ms (5 rows)复制
结语
本节内容就到这里。感谢大家的阅读,欢迎点点关注,我们下期再见。
文章被以下合辑收录
评论


 0 点赞
0 点赞


