




目录导航
1.背景
OLAP(On-Line Analytical Processing)联机分析处理,应用在数据仓库,使用对象是决策者。OLAP系统强调的是数据分析,响应速度要求没那么高。OLAP数据量大,因为OLAP支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大。对于海量数据的查询分析,虽然不要求及时出数据分析结果,能尽量的产后结果也显得比较重要了。假如一个SQL一天出不了结果,那决策者肯定也会不想用。为了提高SQL处理效率,GaussDB(for MySQL)提供了并行查询的方式。
2.并行查询
那什么是并行查询呢,官方介绍如下:
并行查询的基本实现原理是将查询任务进行切分并分发到多个CPU核上进行计算,充利用cpu的多核计算资源来缩短查询时间。并行查询的性能提升倍数理论上与CPU的核数正相关,也就是说并行度越高能够使用的CPU核数就越多,性能提升的倍数也就越高。
比如一个表count(*)的执行过程,如下图
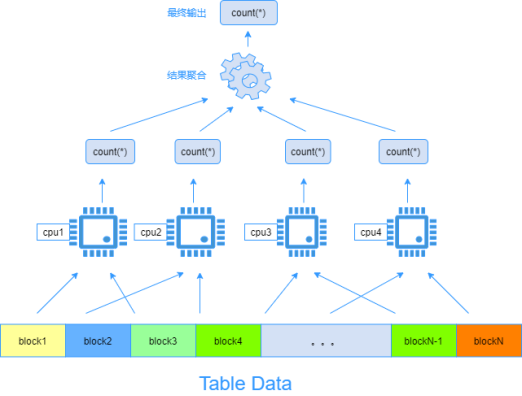
3.分布式海量数据提高查询效率
在海量数据场景下,一般会使用到分库分表,读写分离,业务拆分,数据库分布式部署,各种中间件,各种缓存技术。对于已经落地的数据而言,如果要分析数据,如何提高查询效率呢,这又是一种比较棘手的问题。对于此种问题,GaussDB(for MySQL)提出了一种新的处理方式,就是NDP(Near Data Processing)。
NDP主要针对是数据密集型查询,将提取列,条件过滤,聚合运算等操作向下推送给GaussDB(for MySQL)的分布式存储层的多个节点并行执行。通过计算下推,提升并行处理能力,减少网络流量和计算节点的压力,提升查询处理执行效率。
NDP目前支持如下三类:
3.1、Projection
列裁剪,只有需要到的相关列才被发送到查询引擎;
3.2、Aggregate
典型的聚合操作包括:count、sum、avg、max、min,只发送聚合结果(而不是所有元组)到查询引擎,count (*)是一个最常见的场景;
3.3、Select - where子句过滤
常见的条件表达式:Compare(>=, <=,<,>,==)、Between、In、And/Or, Like.
将过滤表达式下推送到存储层,只有满足条件的行才会发送到查询引擎。
3.4、支持范围
- 当前支持InnoDB表进行计算下推;
- 当前支持COMPACT或DYNAMIC行格式的表;
- 当前支持对Primary Key或BTREE Index计算下推,HASH Index或Full-Text Index不支持计算下推;
- 当前只支持SELECT查询操作进行计算下推,其他DML语句不支持计算下推,INSERT INTO SELECT也不支持计算下推;SELECT 加锁查询(如 SELECT FOR SHARE/UPDATE)不支持计算下推;
- 聚集操作下推当前支持COUT/SUM/AVG/MAX/MIN函数,带GROUP BY语句的聚集操作暂不支持下推;
- 表达式下推支持支持数值类型,日志和时间类型和部分字符串类型(CHAR, VARCHAR),支持utf8mb4, utf8字符集;
- 表达式下推谓词支持比较运算(<,>,=,<=,>=,!=), IN, NOT IN, LIKE, NOT LIKE, BETWEEN AND, AND/OR等操作符。
NDP官方架构图如下:
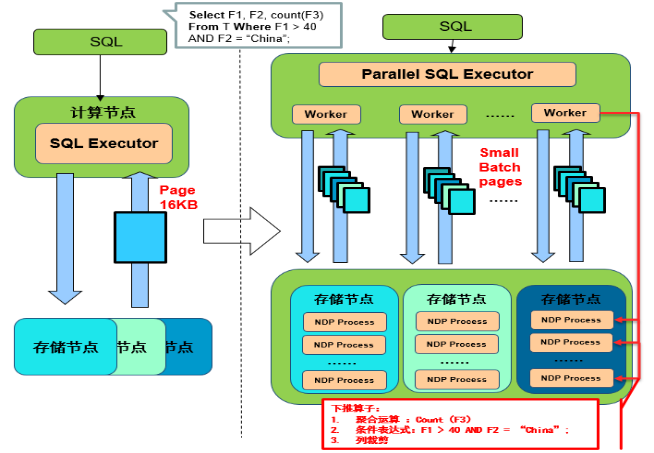
4.测试环境

4.1、开启并行(PQ)
GaussDB(for MySQL) 开启并行
全局参数force_parallel_execute来控制是否强制启用并行执行;
使用全局参数parallel_default_dop来控制使用多少线程并行执行。
使用全局参数parallel_cost_threshold来控制当数据规模为多大时开启并行执行。
mysql> SET force_parallel_execute=1;
Query OK, 0 rows affected (0.00 sec)
mysql> SET parallel_default_dop=16;
Query OK, 0 rows affected (0.00 sec)
mysql> SET parallel_cost_threshold=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set innodb_parallel_select_count=off; – 单表count(*)开并行
Query OK, 0 rows affected (0.00 sec)
mysql> explain
\-> select
\-> l_returnflag,
\-> l_linestatus,
\-> sum(l_quantity) as sum_qty,
\-> sum(l_extendedprice) as sum_base_price,
\-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
\-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
\-> avg(l_quantity) as avg_qty,
\-> avg(l_extendedprice) as avg_price,
\-> avg(l_discount) as avg_disc,
\-> count(*) as count_order
\-> from
\-> lineitem
\-> where
\-> l_shipdate <= date ‘1998-12-01’ - interval ‘90’ day
\-> group by
\-> l_returnflag,
\-> l_linestatus
\-> order by
\-> l_returnflag,
\-> l_linestatus \\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table:
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Parallel execute (16 workers, tpch.lineitem)
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Using pushed NDP condition ((`tpch`.`lineitem`.`L_SHIPDATE` <= ((DATE’1998-12-01’ - interval ‘90’ day)))); Using pushed NDP columns; Using temporary; Using filesort
2 rows in set, 1 warning (0.00 sec)
复制或用hint开启并行
mysql> explain
\-> select /*+ PQ(8) */
\-> l_returnflag,
\-> l_linestatus,
\-> sum(l_quantity) as sum_qty,
\-> sum(l_extendedprice) as sum_base_price,
\-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
\-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
\-> avg(l_quantity) as avg_qty,
\-> avg(l_extendedprice) as avg_price,
\-> avg(l_discount) as avg_disc,
\-> count(*) as count_order
\-> from
\-> lineitem t1
\-> where
\-> l_shipdate <= date ‘1998-12-01’ - interval ‘90’ day
\-> group by
\-> l_returnflag,
\-> l_linestatus
\-> order by
\-> l_returnflag,
\-> l_linestatus \\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table:
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Parallel execute (8 workers, tpch.t1)
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Using where; Using temporary; Using filesort
2 rows in set, 1 warning (0.00 sec)
复制4.2、开启NDP
GaussDB(for MySQL)查看NDP是否开启
mysql> show variables like ‘ndp_mode’;
±--------------±------+
| Variable_name | Value |
±--------------±------+
| ndp_mode | OFF |
±--------------±------+
1 row in set (0.00 sec)
复制GaussDB(for MySQL)开启NDP查询
mysql> set ndp_mode=on;
Query OK, 0 rows affected (0.00 sec)
mysql> explain select
\-> l_returnflag,
\-> l_linestatus,
\-> sum(l_quantity) as sum_qty,
\-> sum(l_extendedprice) as sum_base_price,
\-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
\-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
\-> avg(l_quantity) as avg_qty,
\-> avg(l_extendedprice) as avg_price,
\-> avg(l_discount) as avg_disc,
\-> count(*) as count_order
\-> from
\-> lineitem
\-> where
\-> l_shipdate <= date ‘1998-12-01’ - interval ‘90’ day
\-> group by
\-> l_returnflag,
\-> l_linestatus
\-> order by
\-> l_returnflag,
\-> l_linestatus\\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Using pushed NDP condition ((`tpch`.`lineitem`.`L_SHIPDATE` <= ((DATE’1998-12-01’ - interval ‘90’ day)))); Using pushed NDP columns; Using temporary; Using filesort
1 row in set, 1 warning (0.00 sec)
复制或者用hint 开启 NO_NDP_PUSHDOWN ,NDP_PUSHDOWN
如下:
mysql> explain
\-> select /*+ NDP_PUSHDOWN(t1) */
\-> l_returnflag,
\-> l_linestatus,
\-> sum(l_quantity) as sum_qty,
\-> sum(l_extendedprice) as sum_base_price,
\-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
\-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
\-> avg(l_quantity) as avg_qty,
\-> avg(l_extendedprice) as avg_price,
\-> avg(l_discount) as avg_disc,
\-> count(*) as count_order
\-> from
\-> lineitem t1
\-> where
\-> l_shipdate <= date ‘1998-12-01’ - interval ‘90’ day
\-> group by
\-> l_returnflag,
\-> l_linestatus
\-> order by
\-> l_returnflag,
\-> l_linestatus \\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 555253035
filtered: 33.33
Extra: Using pushed NDP condition ((`tpch`.`t1`.`L_SHIPDATE` <= ((DATE’1998-12-01’ - interval ‘90’ day)))); Using pushed NDP columns; Using temporary; Using filesort
1 row in set, 1 warning (0.00 sec)
复制测试的数据是通过tpch工具导入数据库中,100G数据。
TPC-H 是业界常用的一套 Benchmark,由 TPC 委员会制定发布,用于评测数据库的分析型查询能力。TPC-H 查询包含 8 张数据表、22 条复杂的 SQL 查询,大多数查询包含若干表 Join、子查询和 Group-by 聚合等等。Q17,Q20不支持,所以没测。NDP适合全内存场景,大数据IO场景有效果。
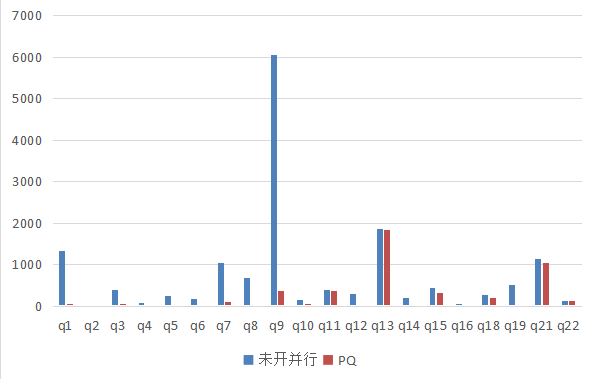
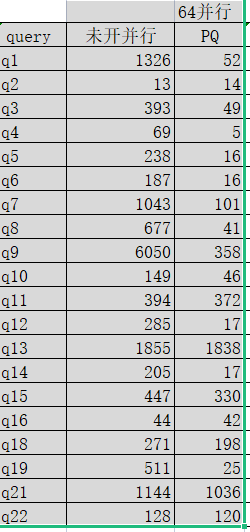
以下为64并行数据,由于NDP不明显,暂不测。
Q13 pq_msg_queue_size=67108864,为64M.
Q18 optimizer_switch =‘subquery_to_derived=ON’.
5.总结:
GaussDB(for MySQL)比官方MySQL8.0快,Q9快的达到了100多倍,当然有些SQL差不多,比如第q13,q21,q22。PQ+NDP还有待优化,PQ与PQ+NDP 性能差不多。
开64并行有的SQL比开30并行要快,但并不是所有SQL都会提升,有的反而变慢,比如Q2,Q11等,可能会有资源争用问题。
总的来说,GaussDB(for MySQL)的NDP和PQ有了很大的性能得升,期待以后支持更多的SQL场景。



