





我们最近完成了迄今为止最大的工程项目之一:将pg_searchPostgres 的全文搜索和分析扩展 迁移到 Postgres 的块存储系统。这pg_search是有史以来第一个将外部文件格式移植到 Postgres 块存储的扩展。
就上下文而言 - 块存储是 Postgres 的存储 API,它支持 Postgres 的所有表和内置索引类型。在迁移之前,pg_search块存储是在块存储之外运行的。这意味着扩展创建了 Postgres 未管理的文件,并且可以直接从磁盘读取这些文件的内容。虽然Postgres 扩展这样做并不罕见pg_search ,但块存储可以同时实现:
Postgres 预写日志 (WAL) 集成,这是索引的物理复制所必需的
崩溃和时间点恢复
全面支持 Postgres MVCC(多版本并发控制)
与 Postgres 的缓冲区缓存集成,从而大大缩短了索引创建时间并提高了写入吞吐量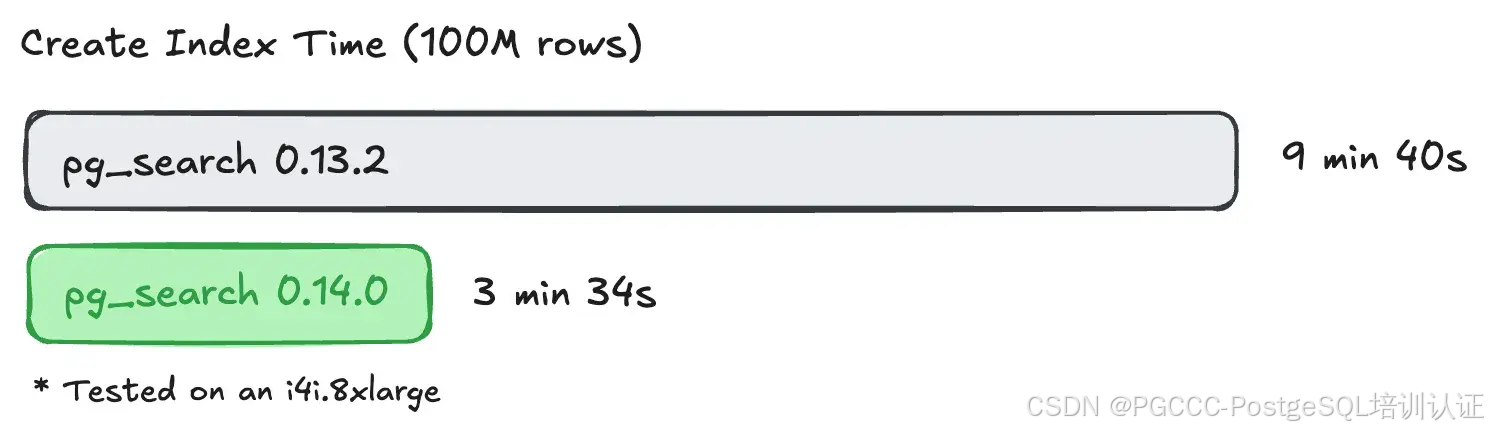

起初,我们不确定在不对 Tantivy 进行重大更改的情况下,是否可以协调 Postgres 和Tantivy(底层搜索库)的数据访问模式和并发模型。在这篇博文中,我们将深入探讨如何设计新的块存储布局和数据访问模式。pg_searchpg_search
在不久的将来,我们将发布另外两篇文章:一篇讨论我们如何设计和测试pg_search在更新频繁的场景中实现 MVCC 安全,另一篇深入探讨我们如何为分析工作负载(例如分面搜索、聚合)定制块存储布局。
什么是块存储?
块存储的基本单位是块:8192 字节的块。执行查询时,Postgres 将块读入缓冲区,这些缓冲区存储在 Postgres 的缓冲区缓存中。DML(INSERT、、、 )语句不会修改物理块。相反,UPDATE它们的更改会写入底层缓冲区,这些缓冲区稍后会在从缓冲区缓存中逐出或在检查点期间刷新到磁盘。DELETECOPY
如果 Postgres 崩溃,对尚未刷新的缓冲区的修改可能会丢失。为了防止这种情况,对索引的任何更改都必须写入预写日志 (WAL)。在崩溃恢复期间,Postgres 会重放 WAL 以将数据库恢复到其最新状态。
什么是pg_search?
pg_search 是一个 Postgres 扩展,它实现了用于全文搜索和分析的自定义索引。该扩展由 Tantivy 提供支持,Tantivy 是一个用 Rust 编写并受 Lucene 启发的搜索库。为什么要迁移到块存储?
自定义 Postgres 索引有两种持久性选择:使用 Postgres 块存储或文件系统。乍一看,使用文件系统似乎是更简单的选择。与块存储集成需要解决一系列问题:某些数据结构可能无法容纳在单个 8KB 块中。将数据拆分到多个块中可能会产生锁争用、垃圾收集和并发挑战。
一旦将块分配给 Postgres 索引,就无法将其物理删除 — 只能回收。这意味着索引的大小会严格增加,直到运行VACUUM FULL或REINDEX。索引必须小心地将已通过删除或清理而墓碑化的块返回到 Postgres 的可用空间映射以供重用。
在更新频繁的情况下,索引可能会被曾经属于死行(即已删除)的空间所占据。这可能会增加搜索和更新所需的 I/O 操作数量,从而降低性能。索引必须在清理期间找到重组和压缩索引的方法。
由于 Postgres 是单线程的,因此多个线程无法同时从块存储4读取数据。索引可能需要利用 Postgres 的并行工作器。
然而,一旦索引克服了这些障碍,Postgres 块存储就会承担大量繁重的工作。经过一年的文件系统工作,很明显块存储是未来的发展方向。
能够使用缓冲区缓存意味着磁盘 I/O 的大幅减少以及读写吞吐量的大幅提高。
Postgres 提供了简单且久经考验的 API 来将缓冲区写入 WAL。如果没有块存储,扩展必须定义自定义 WAL 记录类型并实现自己的 WAL 重放逻辑,这会大大增加复杂性和出现错误的几率。
DROP INDEXPostgres 为我们处理文件的物理创建和清理。中止事务或语句后,索引无需清理。
Tantivy 基于文件的索引布局
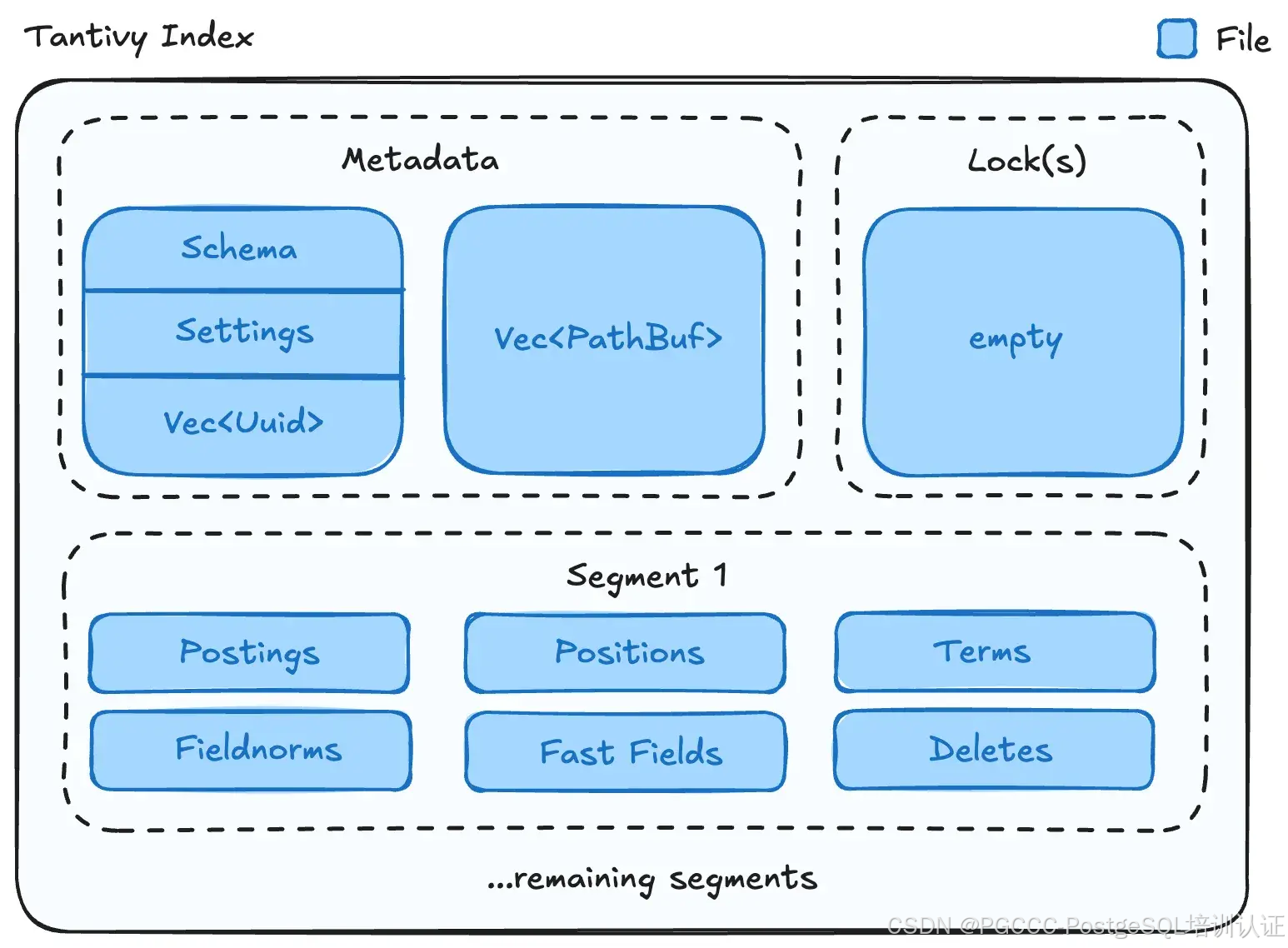
第一个挑战是将Tantivy基于文件的索引布局迁移到块存储。让我们快速检查一下 Tantivy 的索引是如何构建的。
细分
Tantivy 索引由多个段组成。段就像数据库分片一样 — 它包含索引中文档的子集。每个段又由多个文件组成:- 帖子:存储术语与文档 ID 和术语频率的映射,使 Tantivy 能够高效地检索包含特定术语的文档。这是倒排索引的支柱。
- 位置:跟踪文档中术语的位置,通过识别术语相对于彼此出现的位置来实现短语查询。
- 术语:包含索引中唯一术语的列表以及每个术语的元数据,例如文档频率和发布文件中的偏移量。
- Fieldnorms:存储文档中每个字段的规范化因子,用于在排名期间调整术语分数。
- 快速字段:数字和分类字段的列式存储,可实现快速过滤和排序。
- 删除:跟踪段中哪些文档已被删除的位集。
- Storepg_search :存储原始文档。由于堆表已包含原始值,因此该文件未被使用。
元数据
创建段时,Tantivy 会为其分配一个唯一的 UUID。段会在两个文件中进行跟踪。第一个文件包含Vec索引中的所有文件。第二个文件包含当前可见的段 UUID 列表。如果某个段存在于第一个文件中,但不存在于第二个文件中,则意味着该段已被合并过程删除,并且可能会被垃圾收集器删除。此外,第二个文件还存储索引的模式和设置。
锁
Tantivy 使用基于文件的锁定方法 — 如果存在锁定文件,则表示该锁定由另一个进程持有。锁定对于 Tantivy 来说非常重要,因为 Tantivy 不是能够处理并发读取和写入的数据库。它们确保每个索引只有一个写入器,并且对元数据文件的读取和写入是原子的。在第 2 部分中,我们将讨论如何使用 Postgres MVCC 控件来解除 Tantivy 的“每个索引一个写入器”限制。
迁移到块存储布局
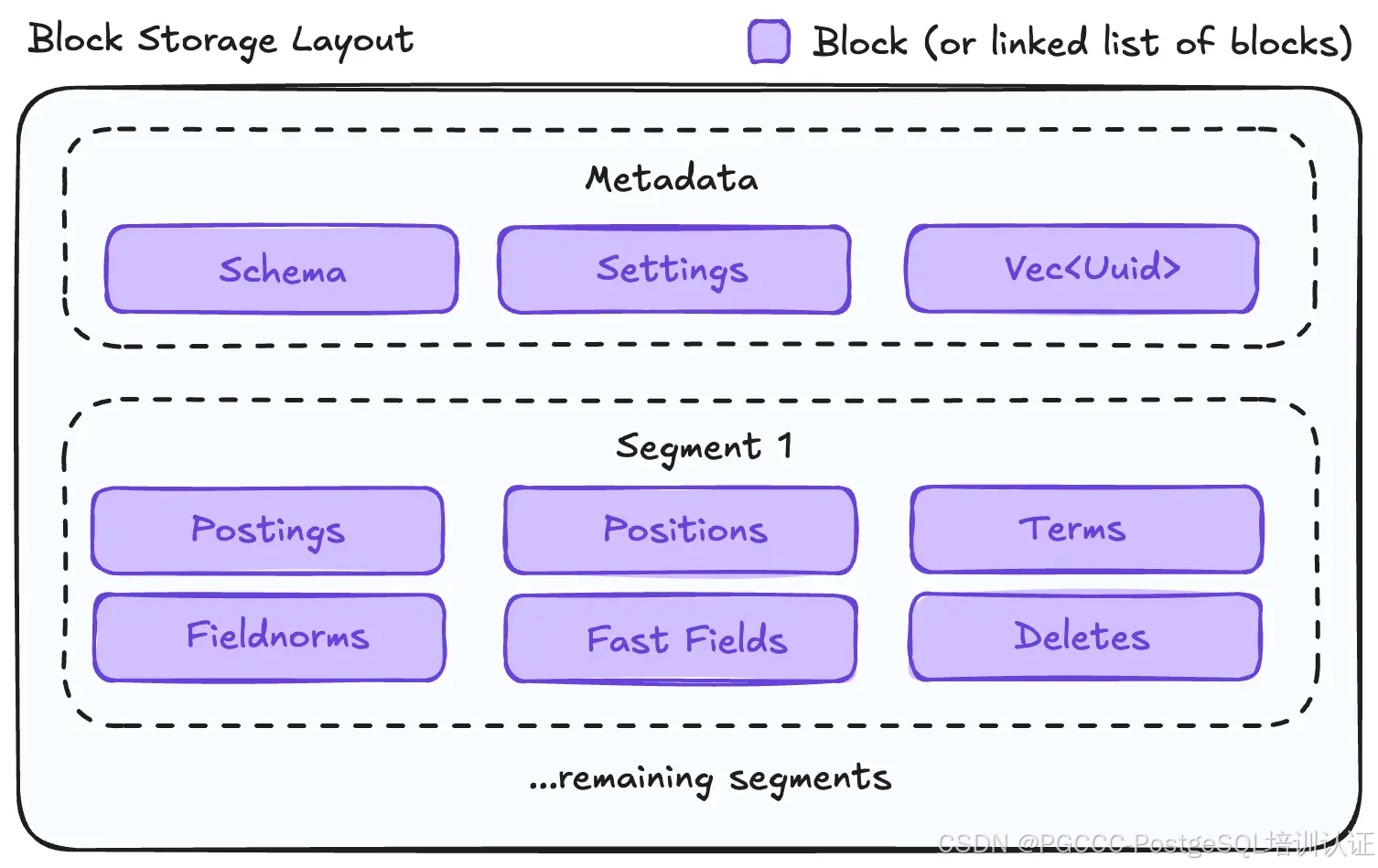
细分
段不是写入文件,而是被序列化并写入块。超出单个块的大型段存储在块的链接列表中。元数据
单独的块用于存储索引模式、设置和段 UUID 列表。Postgres MVCC 可见性信息与每个段 UUID 一起存储。在查询时,扩展使用 MVCC 可见性规则构建所有可见段列表的快照,从而无需第二个可见段列表4。
锁
由于 Postgres 提供了缓冲区级、进程间锁定机制,因此不再需要 Tantivy 的锁定文件。挑战 1:大文件可能会溢出单个块
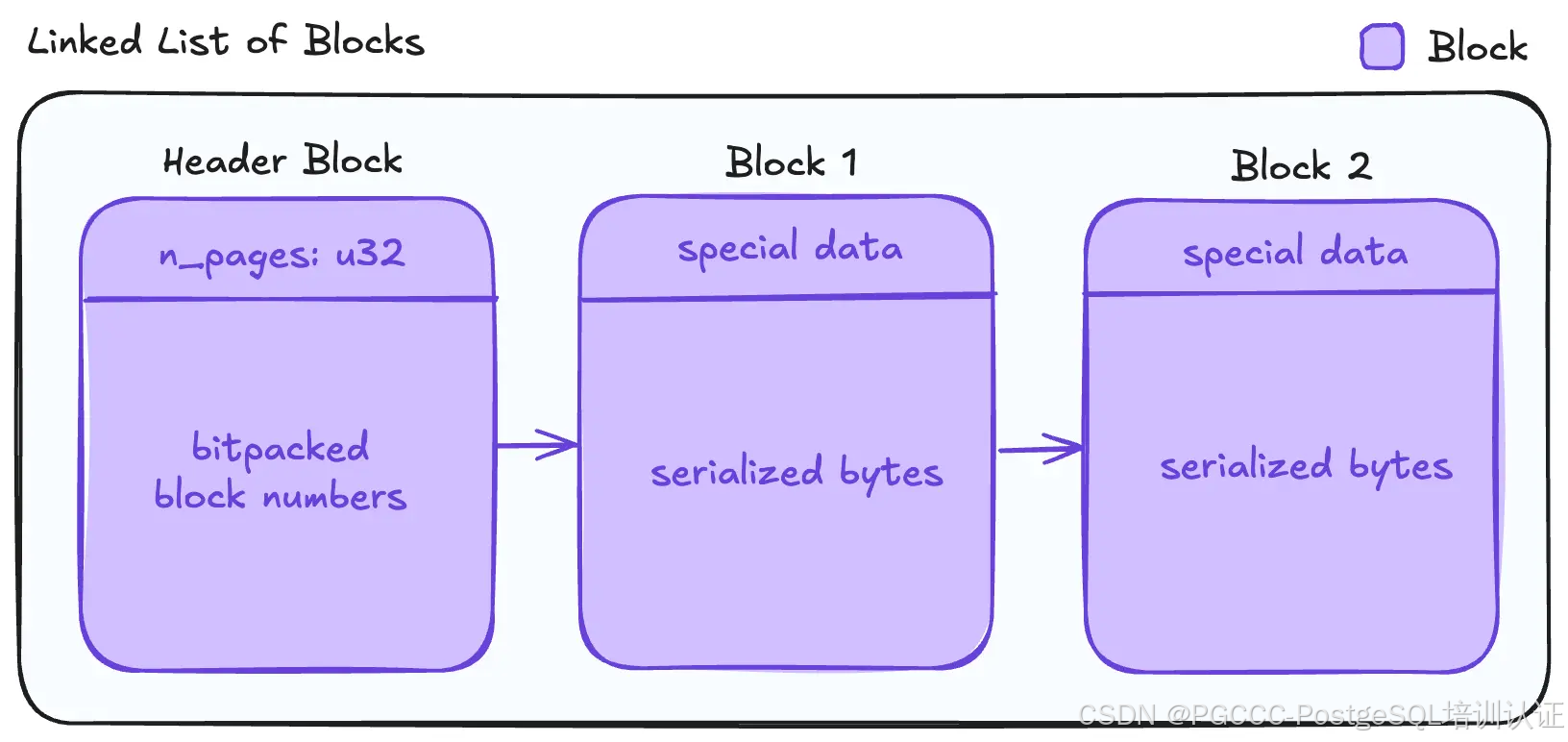
段文件可以超过 8KB 块。为了容纳这些文件,我们在块存储上实现了一个链表,其中每个块都是一个节点。
链表以包含所有后续块编号的位包表示的标头块开头。此结构通过将任何字节范围的起始偏移量直接映射到其在列表中的位置来实现 O(1) 查找。
在头块之后,下一个块存储文件的序列化数据。一旦块已满,就会分配一个新块。在 Postgres 中,每个块都有一个为元数据保留的区域,称为特殊数据。当前块的特殊数据部分会更新以存储新分配块的块号,从而形成链表。
挑战 2:块无法进行内存映射
Tantivy 的快速字段数据访问模式假设底层文件可以进行内存映射,这意味着 Tantivy 可以利用零拷贝访问整个快速字段。块存储则并非如此 — 缓冲区缓存只能提供指向单个块内容的指针。如果快速字段跨越多个块,则必须将每个块复制到内存中,从而带来大量开销。为了解决这个问题,我们修改了 Tantivy,使其推迟预先取消对大块字节的引用。相反,字节会延迟取消引用并缓存在内存中,以避免重新读取之前访问过的块。
挑战 3:更新频繁的场景下,Segment 数量激增
由于段是不可变的,因此 Tantivy 中的每个 DML 语句都会创建至少一个新段。段过多可能会降低性能,因为打开段读取器、搜索段以及将结果与其他段合并会产生成本。虽然理想的段数取决于数据集和底层硬件,但段数超过一百个通常不是最佳选择。如果表经历了大量更新,段的数量会迅速激增。为了解决这个问题,我们引入了一个名为的步骤merge_on_insert,它在完成后寻找合并机会INSERT。
至关重要的是,只能同时运行一个合并过程。如果两个合并过程同时运行,它们可能会同时看到相同的段,将它们合并在一起,并创建重复的段。为了防止这种情况,每个合并过程都会自动将其事务 ID 写入元数据块。后续合并尝试首先读取此事务 ID,并且只有当该事务 ID 的效果对 MVCC 可见时才允许继续。
#PG证书#PG考试#PostgreSQL培训#PostgreSQL考试#PostgreSQL认证
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
外国CTO也感兴趣的开源数据库项目——openHalo
小满未满、
614次阅读
2025-04-21 16:58:09
9.9 分高危漏洞,尽快升级到 pgAdmin 4 v9.2 进行修复
严少安
359次阅读
2025-04-11 10:43:23
3月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
344次阅读
2025-04-15 14:48:05
openHalo问世,全球首款基于PostgreSQL兼容MySQL协议的国产开源数据库
严少安
317次阅读
2025-04-07 12:14:29
转发有奖 | PostgreSQL 16 PGCM高级认证课程直播班招生中!
墨天轮小教习
155次阅读
2025-04-14 15:58:34
墨天轮PostgreSQL认证证书快递已发(2025年3月批)
墨天轮小教习
134次阅读
2025-04-03 11:43:25
SQL 优化之 OR 子句改写
xiongcc
100次阅读
2025-04-21 00:08:06
融合Redis缓存的PostgreSQL高可用架构
梧桐
91次阅读
2025-04-08 06:35:40
PostgreSQL拓展PGQ实现解析
chirpyli
89次阅读
2025-04-07 11:23:17
Mysql/Oracle/Postgresql快速批量生成百万级测试数据sql
hongg
78次阅读
2025-04-07 15:32:54



