CloudBerryDB | 第2期 | 行列混合存储引擎
CloudBerryDB(Greenplum的接棒者)的行列混合存储引擎PAX多种encoding/compress算法、MVCC、XLOG以及VACUUM(目前正在做),也支持统计信息和稀疏过滤,另外还支持向量化执行器。当然它的向量化执行器目前还为开源,据hashdata老师讲,PAX计划明年Q1开源。这里的统计信息大致指一个block里面的最大值和最小值等,可以通过此统计信息进行过滤,减少IO。需要注意,他这里的PAX并不是指业界的PAX行列混合存储方案。
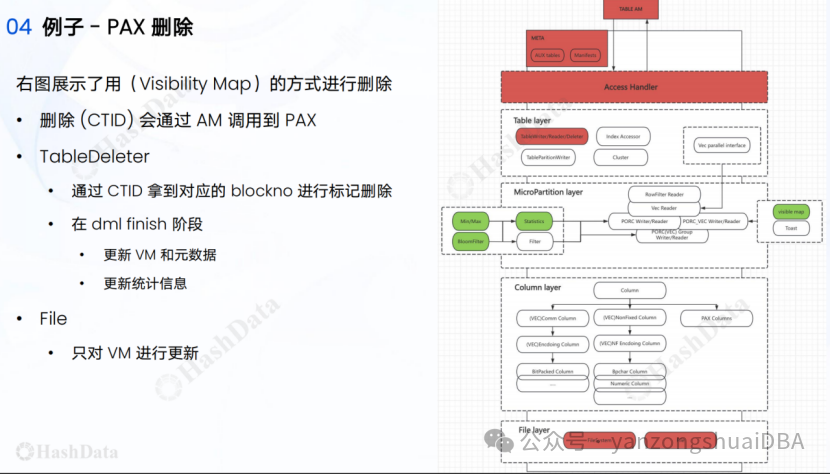
1、架构
它在存储上分为5层:Access Handler:和AM接口打交道,就是所谓的table am层;Table Layer:用于表级别的更新、删除、读和写,比如事务的处理等,上图最左边还有向量化并行接口,用于支持向量化并行扫描等;MicroPartition Layer:文件、Group级别的读、写、更新和删除,并且还有统计信息和filter的处理,这里的统计信息有Min/Max和布隆过滤信息,可以进一步减少IO;Column layer:内存中列信息的抽象,有一些转换都在这一层做;Filter layer:文件系统级别的读写等。
2、元数据
每个文件对应了一个PAX辅助表,这个辅助表是行存,通过这个行存辅助表就可以实现一些MVCC等功能。他有两个辅助表,第一个辅助表字段有:

第二个辅助表:
fast sequence 表:用做产生全局的 block name
3、MVCC
PAX的MVCC通过辅助表的MVCC+visimap完成,辅助表中的可见行代表了当前事务可见的文件。Visimap文件名为<blocknum>_<generation>_<tag>.visimap,blocknum为当前数据文件名;generation为当前visimap的代数,每个对该数据文件的删除,都会使得代数+1;tag为当前事务ID,该字段是为了保证visimap文件名的唯一性。
4、数据格式
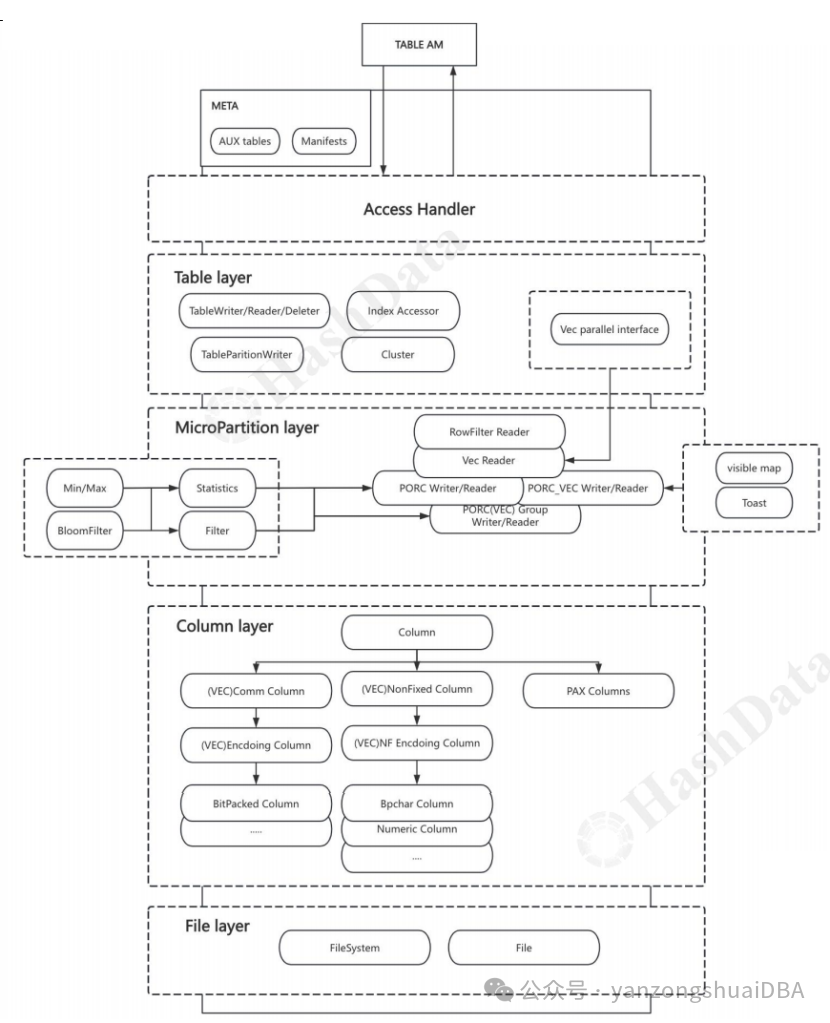
PAX的数据格式衍生于ORC,我们首先先看下ORC的格式:
一个ORC文件根据大小(通常是HDFS块大象)按行分割成多个stripe,也就是一个stripe里面包含多条记录,这些记录按照列进行独立存储;poststript提供了解释文件的必要信息,包含footer和metadata的长度、压缩类型、文件版本等;file footer包含了文件层级、schema、行数和列统计信息等。
Stripe内部按照列进行存储,每列连续存储,它内部包括:
1)索引数据:row group index,默认10000行一个row group,指向metadata streams
2)行数据:按列存储的数据,包括metadata stream和stream
Stripe footer:包含该stripe的统计结果,包括max、min、count等信息
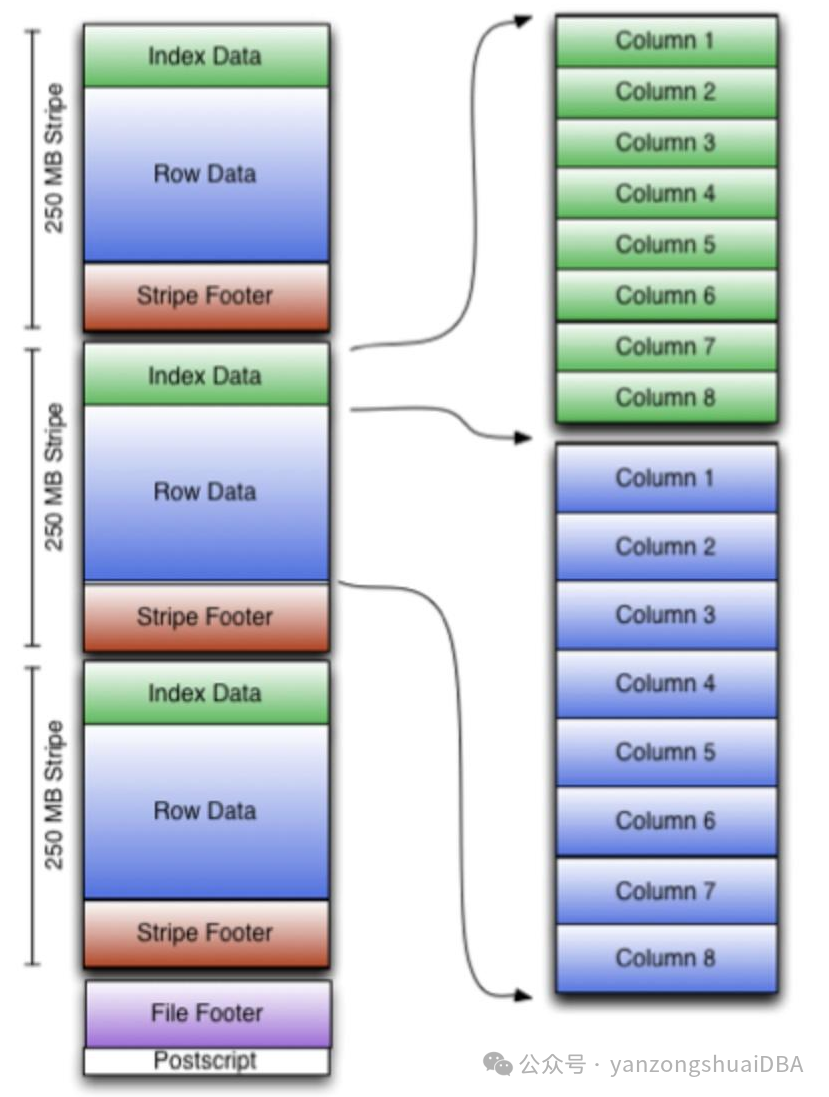
PAX的格式由datastream和metastream组成,统计信息独立存放,去掉了index data,只保留了部分种类的stream,重新涉及的列类型并且加入了对列的自定义attributes:
Datastream和metastream组成和orc区别较大,datastream中列数据和内存中column抽象是对应的,PAX中存在PORC和PORC_VEC两种格式,其中PORC格式是cloudberry执行器友好的存储格式,也就是对应普通执行器;PORC_VEC是对向量化执行器友好的存储格式,主要是减少转换。Metastream和datastream相对应。
列存具体长什么样,以及PORC_VEC格式是什么样,如何体现对向量化执行器友好的,有待开源后进行详细分析。
5、列
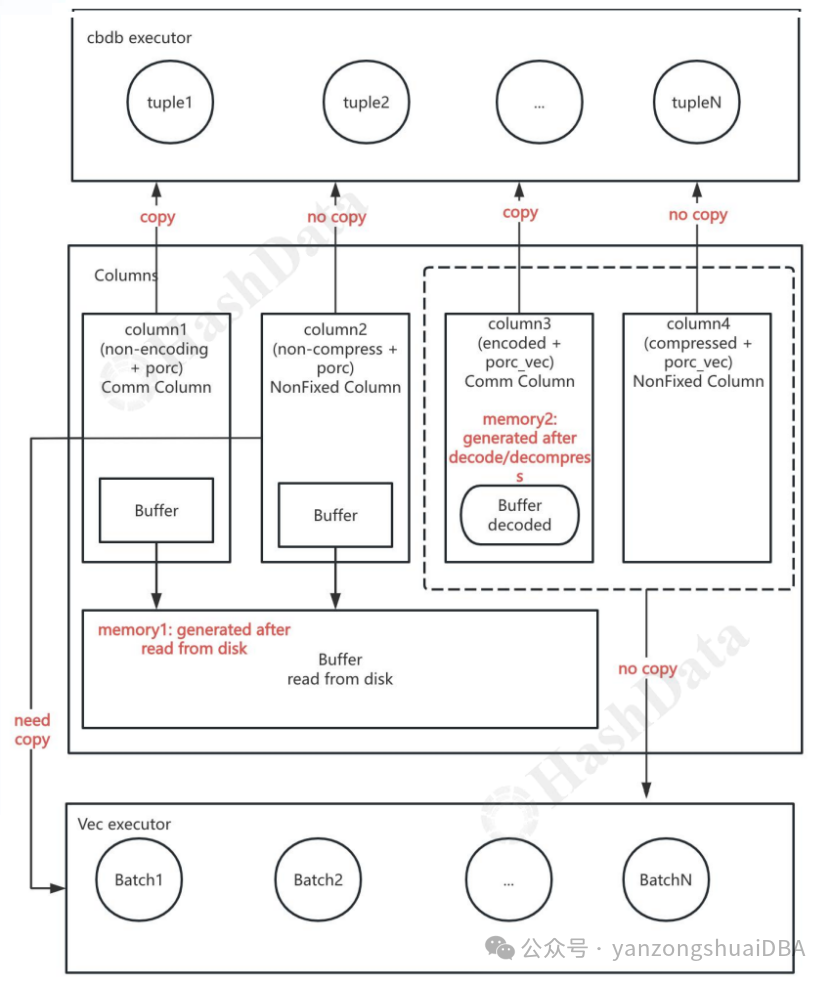
Column为列在内存中的结构,如下图所示,Columns映射磁盘数据,上面是cbdb的行执行器,下面是向量化执行器。Column1和column2从磁盘读到内存后,作为porc格式,若使用向量化执行器,则需要拷贝转换成batch去执行;若使用cbdb行执行器,则column1需要拷贝,column2不需要拷贝,column2是非固定列(变长字段竟然不需要拷贝?);column3和column4作为porc_vec格式在向量化引擎中不用拷贝,而在行执行器中column3需要拷贝,column4不需要拷贝。需要等开源出来后,看下他们各自的格式到底什么样,从而理解什么场景下拷贝,因为这个动作对性能影响非常大,尤其是变长字段。
6、编码和压缩

7、稀疏过滤
通过稀疏过滤可以快速跳过无关数据,从而加快查询响应,在列存在统计信息的情况下,默认会打开稀疏过滤。

8、分区写入
指的不是数据库级别的分区,对于列来说,能选定min/max范围进行分文件写入:新产生的文件将存在于特定的min/max范围内;稀疏过滤效果会更好。
9、cluster
可以对表进行物理重排,以提高查询性能,目前支持两种算法:Z-Order:主要用于将多维数据映射到一维数据进行排序;Lexical:用于对多维数据进行排序。
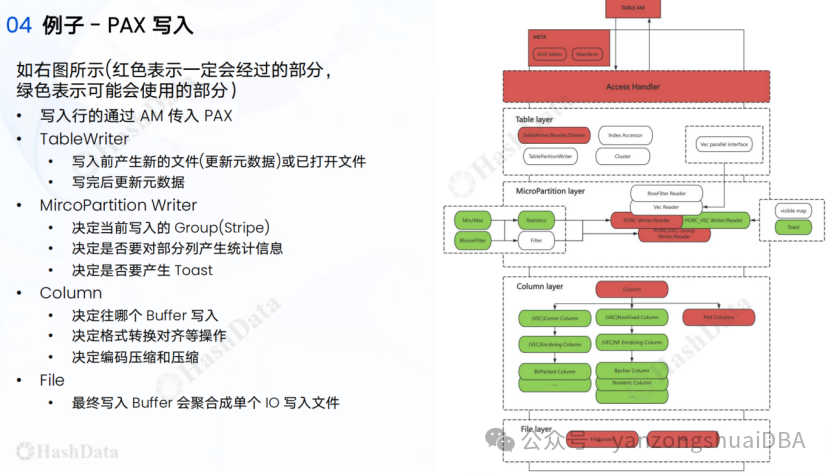
10、PAX写入
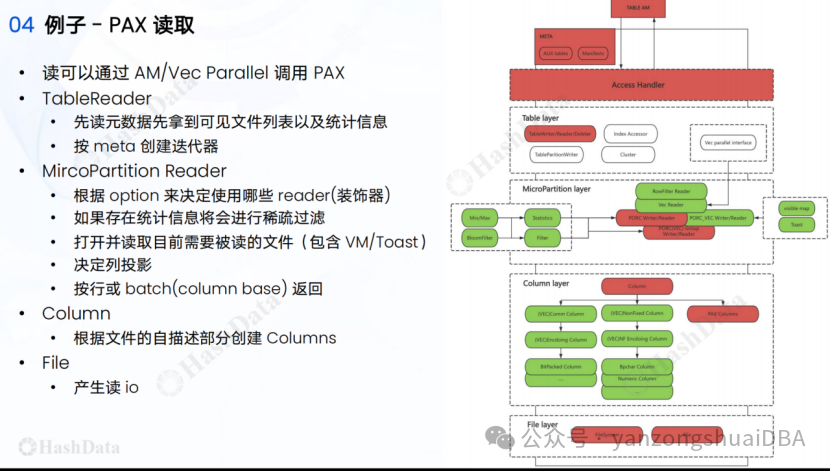
12、PAX读
13、PAX删除