




阿里云 DataWorks 数据集成介绍
1.1 DataWorks 数据集成在阿里云具有悠久的历史
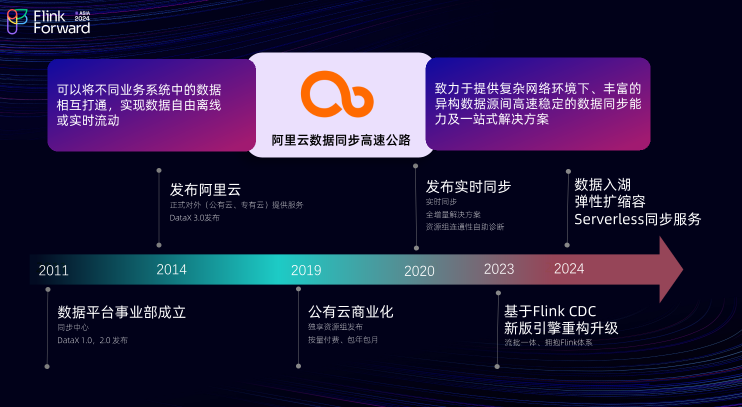
1.2 数据集成的定位
数据集成的定位是数据上云的核心枢纽,致力于打造一个可靠、安全、低成本且可弹性伸缩的异构数据源之间的数据同步平台。
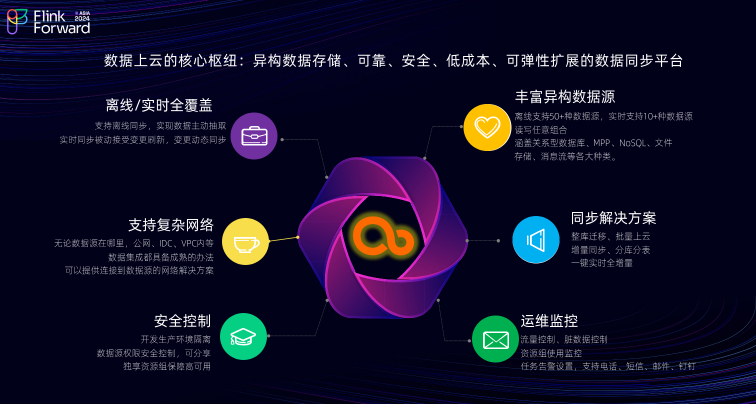

DataWorks 数据集成入湖解决方案的架构和原理
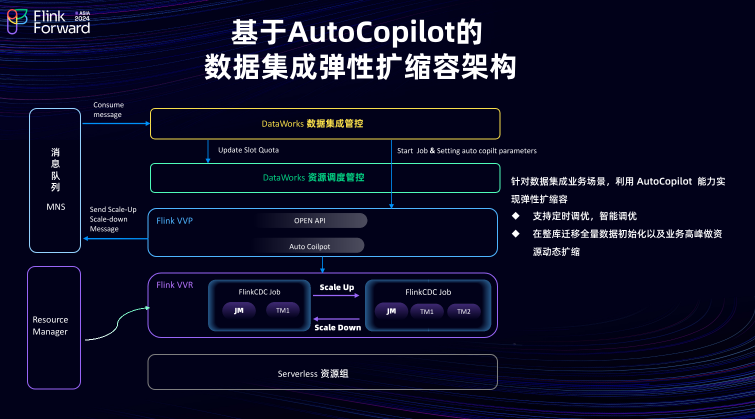
数据集成平台的架构主要可分为四个部分,包含接入层、管控层、引擎层、资源层。
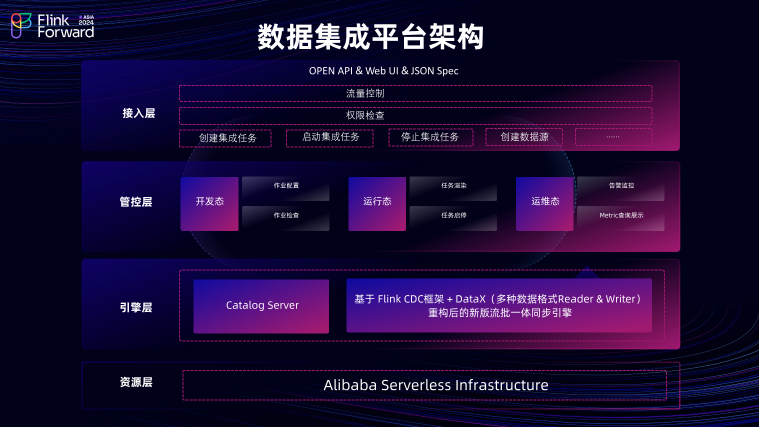


源头支持多种数据源,包括关系数据库,如 MySQL 、 PostgreSQL 以及实时的消息流,如 Kafka、Loghub 等。利用 Flink CDC Source 实现全量和增量的数据摄取。 事件解析组件,将源头的 Event 事件转化为 Insert 、 Update 、 Delete 及 Alter 等操作类型。 在数据分发层按照主键做 Hash 分发,能有效避免源头热点表数据问题。 TableMapping 组件,做数据的映射转发,将源头的 Event 事件映射到目的表,确保数据传输的准确性。同时提供了一系列丰富的T节点能力,涵盖了字符串替换、数据脱敏、JSON解析、数据过滤以及逻辑删除等能力,以满足用户多样化的数据处理需求。 在 Flink CDC 基础上实现了包括 Paimon 、Hudi、Iceberg 等多种湖格式的 Sink pipeline 支持,能够实现 DML 数据以及 DDL 在目的端重放。此外在入湖场景下也支持将 Paimon 、 Hudi、Iceberg 等表结构的元数据同步到阿里云的 DLF 上。用户在配置入湖同步解决方案时,可以选择将元数据构建在阿里云的 DLF 上,而实际的数据存储则依托于阿里云的 OSS 或 OSS-HDFS 文件存储服务。
2.4 数据集成-全增量入湖的解决方案流程
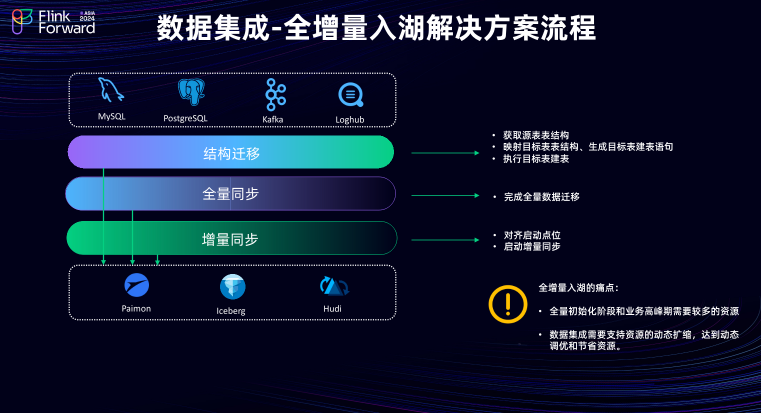
结构迁移:其核心工作在于获取源头表的表结构信息,并将其映射到目的端表结构,同时生成目的端所需的建表语句并执行建表。 全量同步:完成从源头数据库到目的端的历史数据迁移。 增量同步:在全量同步完成后需进行位点对齐操作,并启动增量同步。增量同步能够实时捕捉源头数据和表的 Schema 变化,并将其同步到目的端,从而保持数据的实时性和一致性。
DataWorks 数据集成入湖场景的产品化案例分享
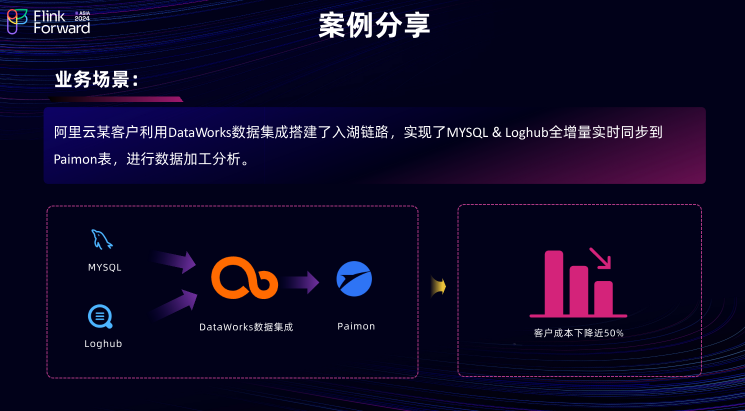 阿里云某客户利用 DataWorks 数据集成链路,成功搭建了一条入湖链路,实现了将源端 MySQL 的数据全增量同步到目的端的 Paimon表,进而进行数据加工和分析。借助 DataWorks 引擎的性能优势和弹性扩缩容架构,用户的成本最终下降了大约 50% .
阿里云某客户利用 DataWorks 数据集成链路,成功搭建了一条入湖链路,实现了将源端 MySQL 的数据全增量同步到目的端的 Paimon表,进而进行数据加工和分析。借助 DataWorks 引擎的性能优势和弹性扩缩容架构,用户的成本最终下降了大约 50% .未来规划

计划支持更多的云端用户使用场景
打造基于 AI 的任务诊断系统
推出数据质量检验功能



 点击「阅读原文」跳转阿里云实时计算 Flink~
点击「阅读原文」跳转阿里云实时计算 Flink~文章转载自Flink 中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
