




1 说明
月初值班的时候应用反馈跑报表有报错,某个进程出现 No more data to read from socket错误:

这个错误通常与网络连接异常有关,导致数据库无法从socket中读取更多数据。由于该问题影响了报表的生成,因此需要尽快排查并解决。
2 问题分析
2.1 以往经验
依据过往处理类似问题的历史经验,socket 相关报错大多是由网络原因致使连接异常。在以往的案例中,当出现此类 socket 报错时,重跑程序任务通常能够解决问题。这是因为网络的短暂波动或连接的临时不稳定,在重跑程序后,重新建立的连接有可能恢复正常,从而使程序能够顺利执行。
2.2 根因排查
一、检查alert日志
比较有迷惑性的是,因为应用给的程序报错截图没有返回ORA相关错误,一开始以为不是数据库层面的原因,但出于谨慎还是查了alert日志,发现对应时间点有ORA-07445错误:

二、检查trace文件
查看xxx_i2479149.trc文件信息。
11:48:50数据库出现1次报错,进程号是am_balance_solid_999:

相关sql类似如下:
与应用反馈的表一致,5个线程同时执行以上sql,其中一个sql报no data found,对sql在执行计划、索引使用、数据量等方面的情况进行性能分析,确定该 sql 没有性能问题。
call stack信息如下:
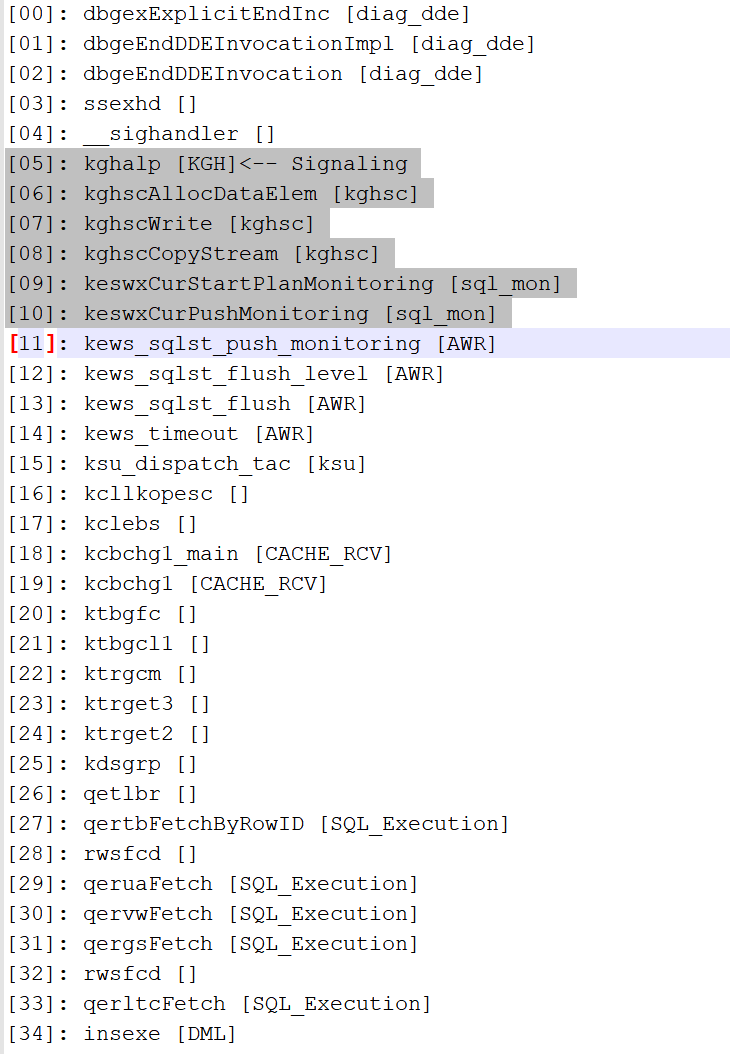
从上面call stack可以看出,sql触发了sql monitor,然后在分配内存时报错。
三、查找问题解释
在官网找到相关问题解释,此问题应该是由于 Bug 21157342 - dump on kghalp/_intel_new_memcpy with SQL Monitoring enabled (default):
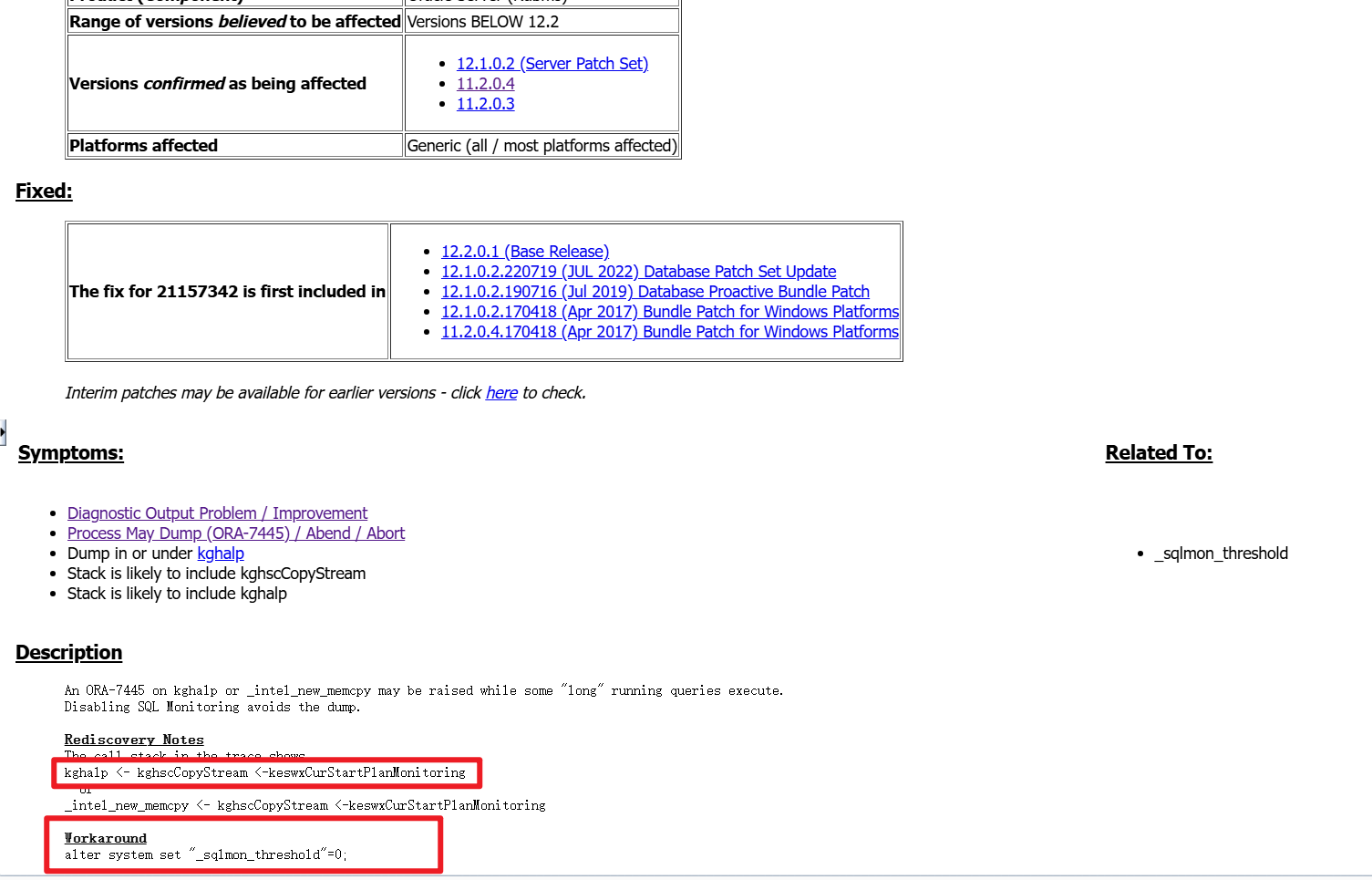
由于sql超过5秒触发sql monitor时,sql monitor在分配内存时暂时无法请求到。
可以考虑通过关闭sql monitor功能:
alter system set "_sqlmon_threshold"=0;
或者调大默认的5秒阈值:
--1分钟
alter system set "_sqlmon_threshold"=60;
3 总结
当应用程序遇到 socket 相关问题时,从经验角度出发,可以先建议应用尝试重跑操作。一般情况下,重跑都能够使程序正常运行,解决因网络临时波动等原因导致的问题。
然而,如果该问题频繁出现,或者应用重跑所耗费的时间成本过高,严重影响业务效率时,就必须优先查找问题的根本原因。在此案例中,所遇到的 ORA - 07445 [kghalp] 错误,可以通过关闭 sql monitor 功能或调大阈值的方式去规避。在实际操作中,需要根据业务对性能监控的需求以及系统的实际运行情况,谨慎选择合适的解决方案,以确保系统的稳定运行和业务的高效开展。同时,后续还应持续关注类似问题的出现,建立问题预警机制,以便在问题发生时能够更快速、有效地进行处理。
