





本文字数:18333;估计阅读时间:46分钟

Meetup活动
ClickHouse 上海第二届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!

大约一年前,我们参与了 Gunnar Morling 发起的 “十亿行挑战 (One Billion Row Challenge)”,测试了 10 亿行文本文件的聚合性能。
现在,我们发起了一个新的挑战:“十亿文档 JSON 挑战 (One Billion Documents JSON Challenge)”,旨在评估数据库在存储和聚合大规模半结构化 JSON 文档数据集时的表现。
为了解决这一问题,我们需要一个高效的 JSON 方案。最近,我们详细介绍了如何从零开始为 ClickHouse 构建一个全新的强大 JSON 数据类型,并展示了它为何成为列式存储的最佳 JSON 方案。
在本文中,我们将 ClickHouse 的 JSON 实现与其他支持 JSON 的数据存储方案进行对比,测试结果可能会让你大吃一惊。
为了完成这项测试,我们开发了 JSONBench——一个完全可复现的基准测试工具,它能够将相同的 JSON 数据集加载到五个主流的、具备原生 JSON 支持的数据存储系统中:
ClickHouse MongoDB Elasticsearch DuckDB PostgreSQL
JSONBench 评估了 JSON 数据集的存储占用情况,以及五种常见分析查询的执行性能。
以下是 10 亿 JSON 文档存储与查询的基准测试结果预览。
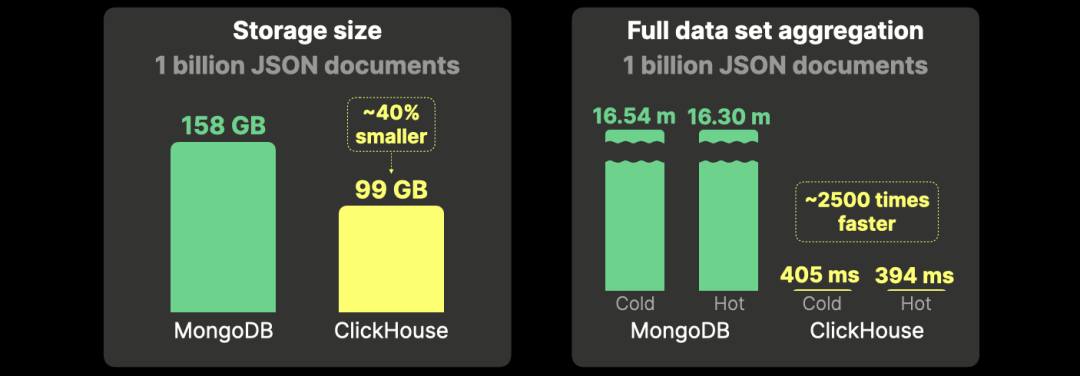
ClickHouse 的存储效率比 MongoDB 高 40%,聚合查询速度快 2500 倍。
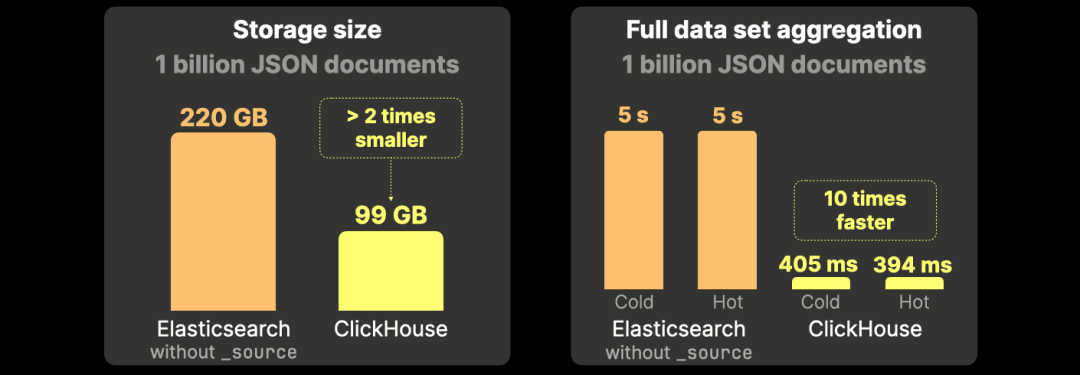
ClickHouse 仅需 Elasticsearch 一半的存储空间,聚合查询速度快 10 倍。
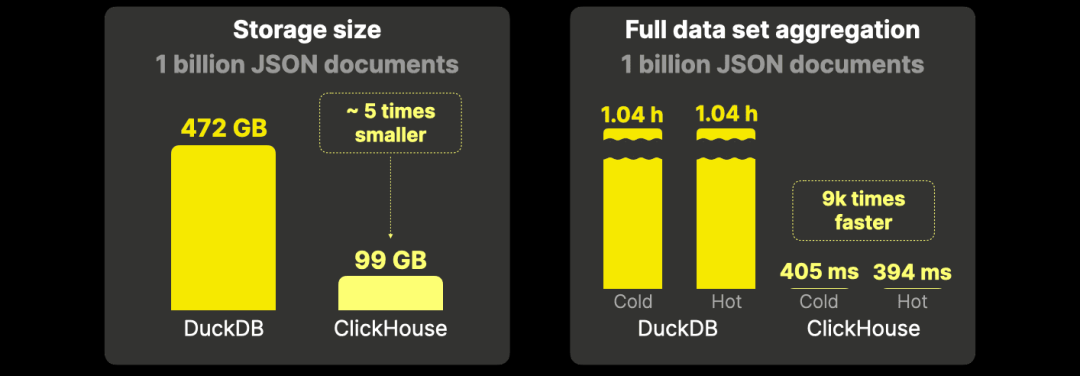
ClickHouse 的磁盘占用仅为 DuckDB 的五分之一,在分析查询上的速度快 9000 倍。
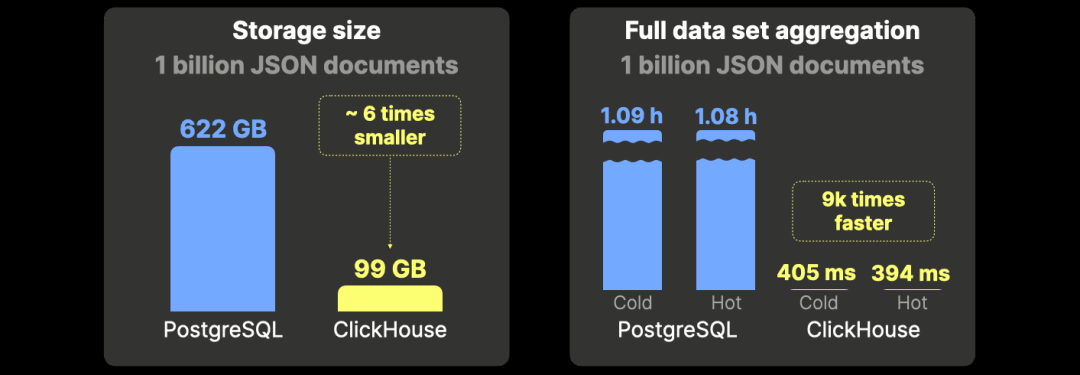
ClickHouse 仅使用 PostgreSQL 六分之一的磁盘空间,在分析查询上的速度同样快 9000 倍。
最后值得一提的是,即使采用相同的压缩算法,ClickHouse 存储 JSON 文档的空间利用率仍比将其作为压缩文件存储提高 20%。

接下来的内容将首先介绍我们的测试 JSON 数据集,并简要概述每个基准测试对象的 JSON 处理能力(如果你对技术细节不感兴趣,可以跳过这部分)。接着,我们将介绍基准测试的环境配置、查询以及测试方法。最后,我们将展示并深入分析测试结果。
我们的测试 JSON 数据集来自对 Bluesky 社交媒体平台的事件流抓取。在另一篇文章中,我们详细介绍了如何使用 Bluesky API 获取这些数据。这些数据天然以 JSON 文档格式存储,每个文档代表一个特定的 Bluesky 事件(例如帖子、点赞、转发等)。
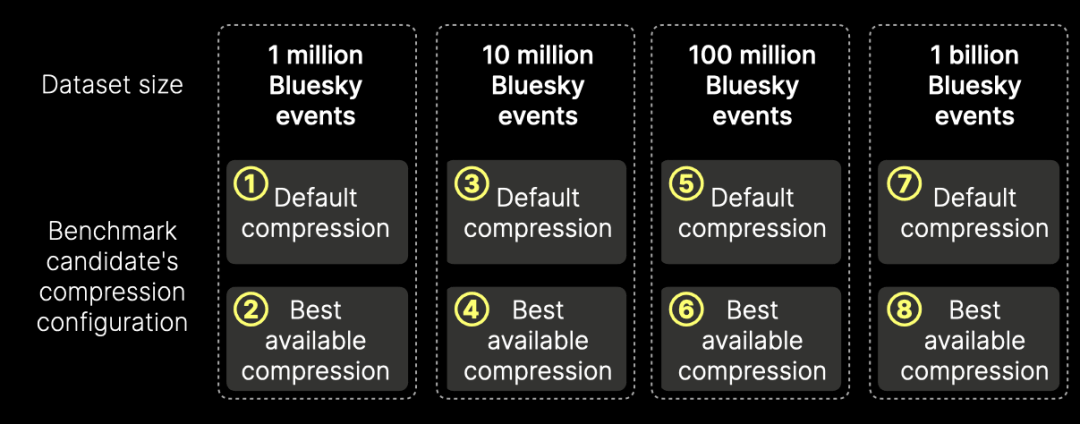
基准测试会将以下 8 个 Bluesky 事件数据集(下图中的 ① 到 ⑧)加载到每个基准测试候选系统中:
本节概述了基准测试系统的 JSON 处理能力、数据压缩技术以及查询加速特性(例如索引和缓存)。理解这些技术细节有助于澄清各系统的配置方式,以确保基准测试的公平性和准确性。
如果你对这些技术细节不感兴趣,可以跳过本节。
ClickHouse
ClickHouse 是一款列式分析数据库。在本文中,我们将对其进行基准测试,与其他候选系统对比,以突出其在处理 JSON 数据方面的卓越能力。
JSON 支持
我们最近为 ClickHouse 构建了一个强大的新 JSON 数据类型,具备真正的列式存储,支持在不统一类型的情况下动态变化数据结构,并能以极快的速度查询特定的 JSON 路径。
JSON 存储
ClickHouse 将每个唯一 JSON 路径的值存储为原生列,从而实现高效的数据压缩,并且——正如本文所展示的——在查询性能方面保持与经典数据类型相同的高水平:
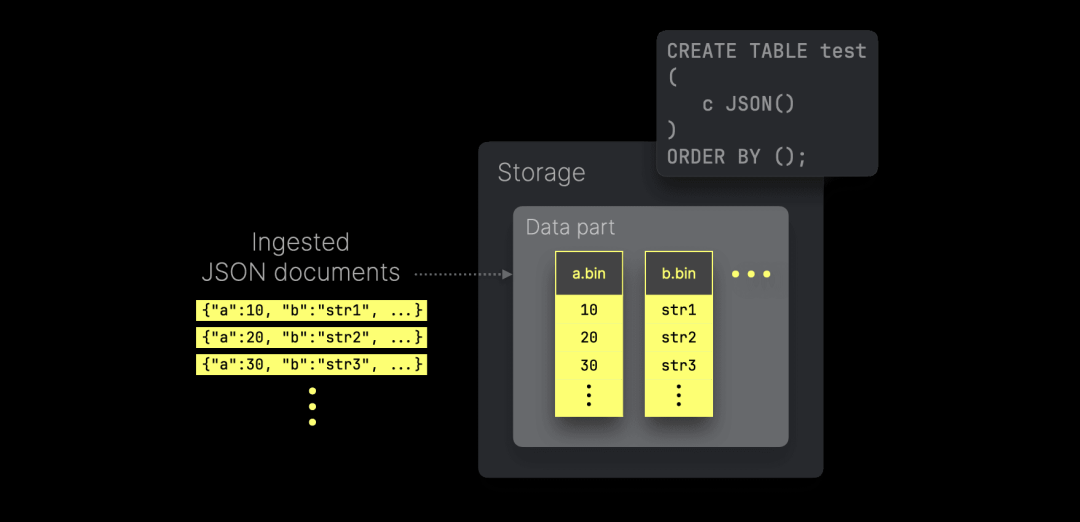
上图概述了每个唯一 JSON 路径的值如何存储在磁盘上的独立(高度压缩的)列文件中(位于数据分片中)。这些列可以独立访问,最小化查询时对无关 JSON 路径的 I/O 操作。
数据排序与压缩
ClickHouse 的 JSON 类型允许将 JSON 路径用作主键列。这确保了写入的 JSON 文档在存储时,在每个数据分片内部按照这些路径的值排序。此外,ClickHouse 生成稀疏主索引,以自动加速基于这些主键列的查询:
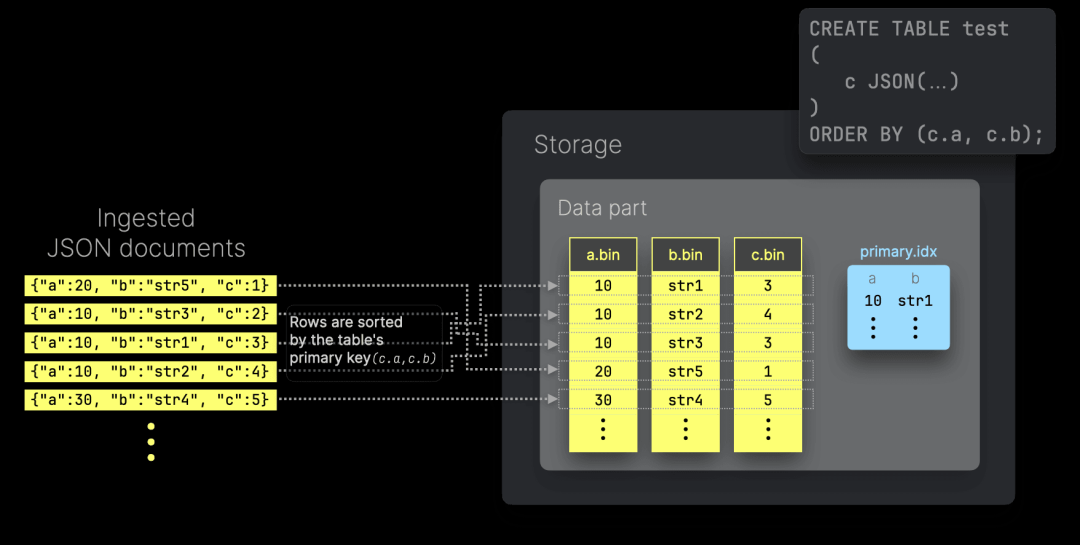
将 JSON 子列作为主键列可以更好地将相似数据组织到同一列文件中,从而提高数据压缩率,前提是主键列按照基数递增的顺序排列。磁盘上的数据排序还可以避免查询时的重新排序,并在查询的搜索排序与物理数据排序匹配时实现短路优化。
灵活的压缩选项
在默认情况下,ClickHouse 在自托管版本中对每个数据列文件分别应用 lz4 压缩,而在 ClickHouse Cloud 中使用 zstd 压缩。
此外,还可以在 CREATE TABLE 语句中为单独的列定义压缩编解码器。ClickHouse 支持通用、高级和加密编解码器,并允许进行级联压缩。
对于 JSON 类型,ClickHouse 目前支持对整个 JSON 字段定义编解码器(例如,在此将默认的 lz4 编解码器更改为 zstd)。未来,我们计划支持针对单个 JSON 路径指定编解码器。
灵活的 JSON 格式选项
ClickHouse 支持 20 多种不同的 JSON 格式用于数据导入和查询结果的输出。
查询处理
由于 ClickHouse 在基准测试中的卓越性能,我们在此简要介绍其 JSON 数据查询的处理方式。
正如前文所述,ClickHouse 以类似传统数据类型(例如整数)的方式存储每个唯一 JSON 路径的值,使其能够对 JSON 数据进行高效聚合。
ClickHouse 专为互联网规模的分析而构建,能够利用所有可用资源,通过完全并行化的 90 多种内置聚合函数高效筛选和聚合数据。这一方法可以通过 avg(平均值)聚合函数来说明:
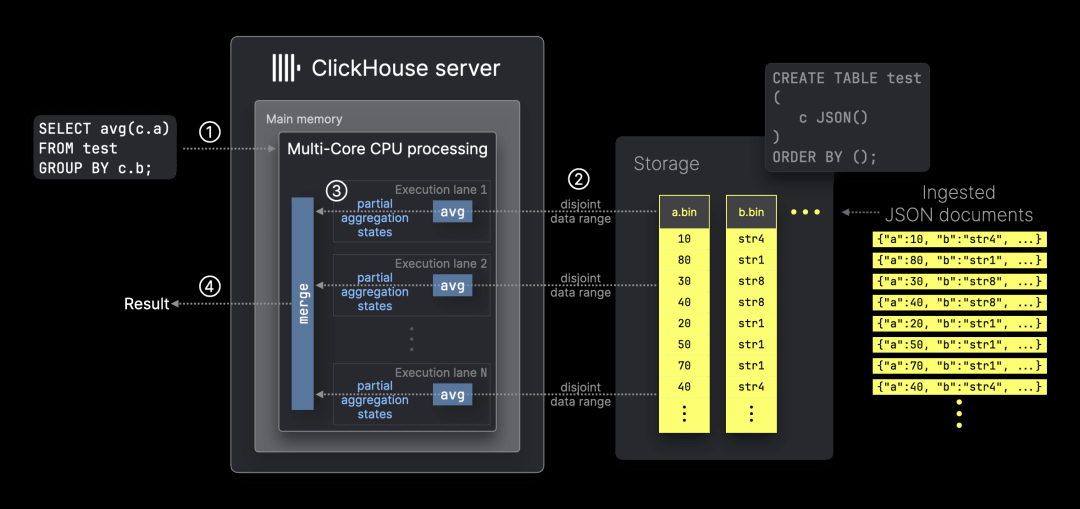
上图展示了 ClickHouse ① 处理引用 JSON 路径 c.a 和 c.b 的 avg 聚合查询的方式。ClickHouse 仅使用对应的数据列 a.bin 和 b.bin,在单台服务器上的 N 个 CPU 核心上并行处理 N 个不重叠的数据范围。这些数据范围独立于分组键,并动态平衡以优化工作负载分布。这种并行化处理得益于部分聚合状态的使用。
在 ClickHouse 的基准测试中,我们还跟踪物理执行计划,以深入分析这一并行化方法。例如,在这里,你可以看到 ClickHouse 在测试机器(32 核 CPU)上如何使用 32 条并行执行通道处理基准查询 ① 的全数据集聚合。
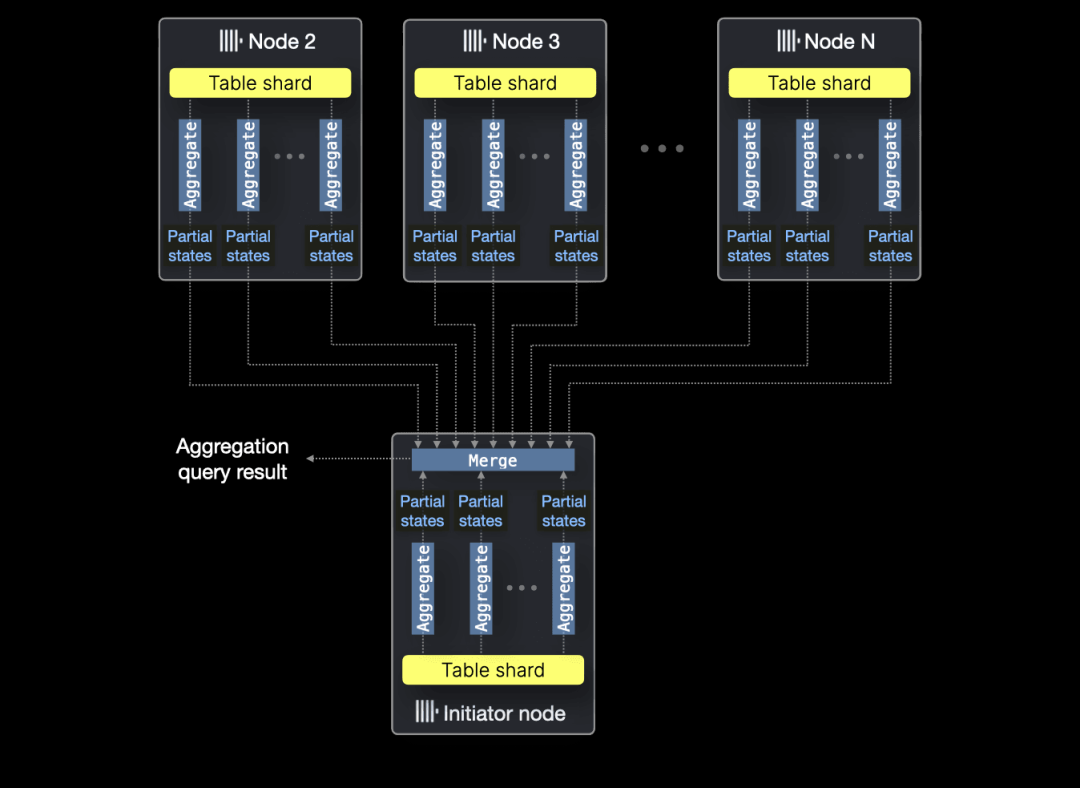
多节点并行化
虽然本次基准测试仅关注单节点性能,但需要补充说明的是,如果聚合查询的 JSON 源数据分布在多个节点上(以表分片的形式),ClickHouse 能够无缝地在所有节点的所有 CPU 核心上并行执行聚合函数:
缓存
在查询执行过程中,ClickHouse 依赖多个内置缓存,以及操作系统的页面缓存。例如,尽管默认情况下禁用,但 ClickHouse 还提供查询结果缓存。
MongoDB
MongoDB 是最知名的 JSON 数据库之一。
JSON 支持
MongoDB 以 BSON 文档集合的形式原生存储所有数据,其中 BSON 是 JSON 文档的二进制表示形式。
JSON 存储
MongoDB 的默认存储引擎 WiredTiger 在磁盘上以 B-Tree 结构存储数据,数据块以页面的形式组织。根节点和内部节点存储键及其指向其他节点的引用,而叶子节点存储 BSON 文档的数据块:
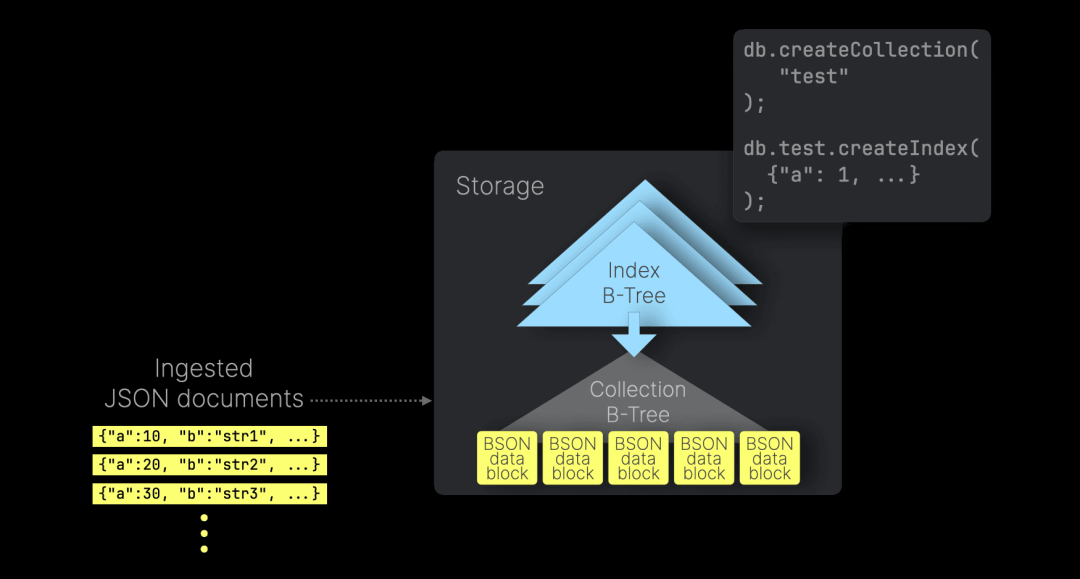
MongoDB 允许用户为 JSON 路径创建二级索引,以加速基于这些路径的查询。二级索引采用 B-Tree 结构,每个索引条目对应一个写入的 JSON 文档,并存储该文档的索引 JSON 路径值。这些索引会加载到内存中,使查询优化器能够快速遍历 B-Tree 以查找匹配的文档,然后从磁盘加载这些文档进行处理。
覆盖索引扫描(Covered Index Scans)
如果查询仅涉及已建立索引的 JSON 路径,MongoDB 可以完全依赖内存中的 B-Tree 索引来满足查询,而无需从磁盘加载文档。这种优化称为“覆盖索引扫描”,适用于覆盖查询(Covered Queries):
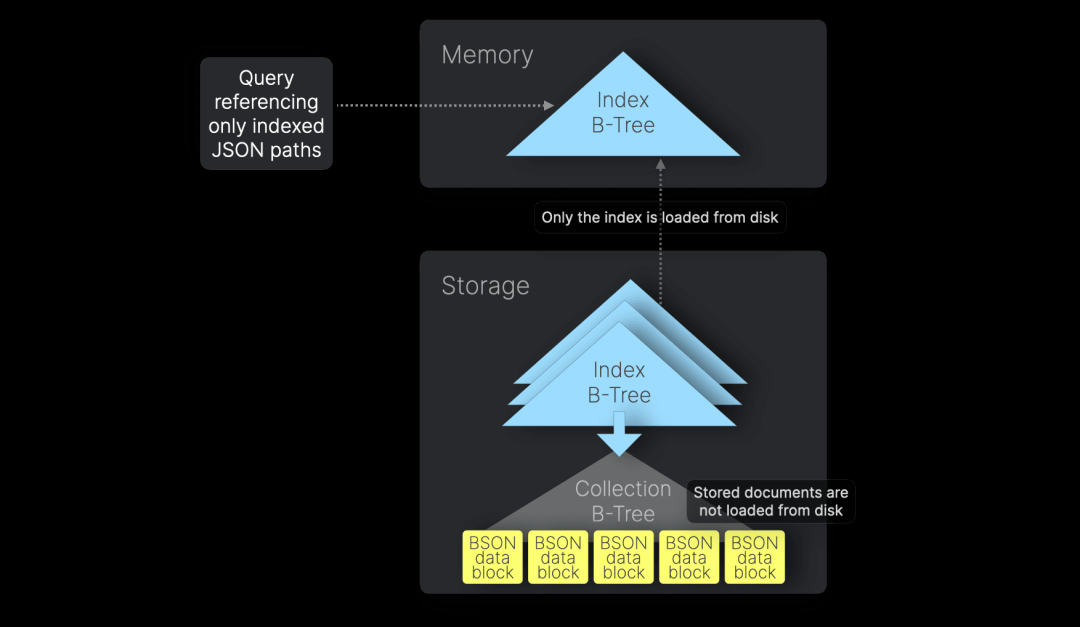
在 MongoDB 的基准测试中,我们的五个查询均为覆盖查询。这是因为我们为所有集合创建的默认复合索引包含了所有查询所需的字段。按照最佳实践,我们还显式启用了覆盖索引扫描。
可以通过查询执行计划来验证这一点。例如,在 10 亿文档集合上执行查询时,执行计划仅包含 IXSCAN(索引扫描)阶段,而没有 COLLSCAN(集合扫描)或 FETCH(文档提取)阶段。而在启用覆盖索引扫描之前的较早执行计划中,可以看到 COLLSCAN 或 FETCH,表明查询过程中仍需要从磁盘加载文档。
此方法依赖于索引能够完全装入内存。在我们拥有 128 GB RAM 的测试机器上,最大的测试数据集的 27 GB 索引可以轻松装入内存。然而,在分片环境中,覆盖索引扫描要求索引包含分片键。
数据压缩
WiredTiger 默认使用 Snappy 库进行块压缩,并对 B-Tree 索引应用前缀压缩。此外,用户可以选择启用 zstd 压缩以提高集合的压缩率。
数据排序
MongoDB 支持“聚簇集合”(Clustered Collections),即按照指定的聚簇索引顺序存储文档,以提高数据局部性并提升压缩率。然而,由于聚簇索引键必须唯一,并且最大长度限制为 8 MB,我们无法在测试数据上使用该功能。
缓存机制
MongoDB 依赖 WiredTiger 内部缓存和操作系统的页面缓存,但不具备查询结果缓存。WiredTiger 缓存独立于操作系统页面缓存,存储最近访问的数据和索引。默认情况下,其大小设定为可用 RAM 的 50% 减去 1 GB。此缓存只能通过重启 MongoDB 服务器来清除。
限制
在我们的 Bluesky 测试数据中,time_us JSON 路径包含微秒级精度的时间戳。然而,MongoDB 目前仅支持毫秒级精度,而 ClickHouse 能够处理纳秒级时间戳。
此外,MongoDB 的聚合框架缺少内置的 COUNT DISTINCT 操作符。因此,在基准查询 ② 中,我们使用了效率较低的 `$addToSet` 作为替代方案。
Elasticsearch
Elasticsearch 是一个基于 JSON 的搜索和分析引擎。
JSON 支持
Elasticsearch 以 JSON 文档的形式原生接收所有写入的数据。
JSON 存储与数据压缩
在 Elasticsearch 中,写入的 JSON 数据会被索引并存储在多个针对特定访问模式优化的数据结构中。这些结构存储在“段”(Segment)中,段是 Lucene(为 Elasticsearch 提供搜索和分析功能的 Java 库)的核心索引单元:
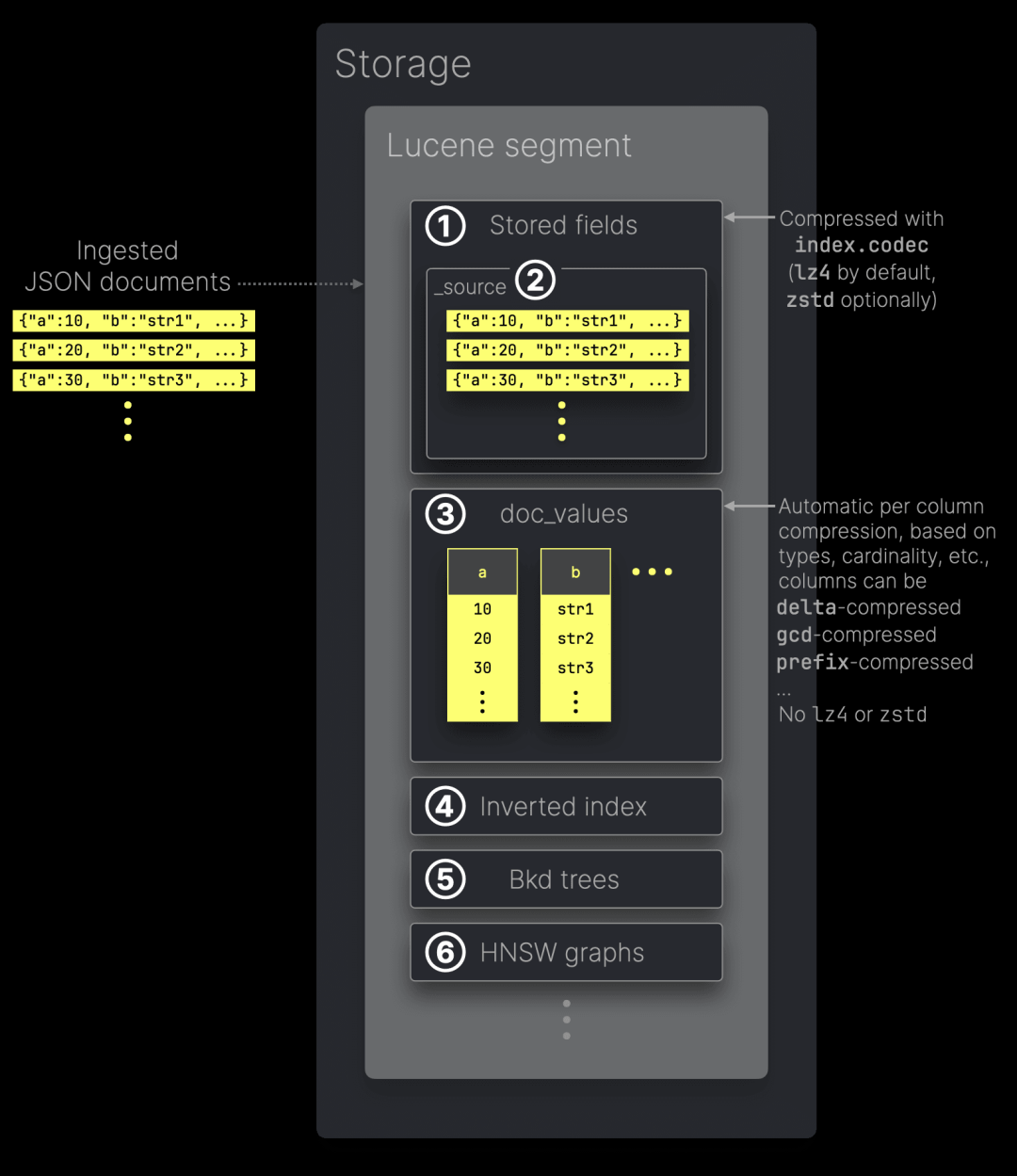
① 存储字段(Stored Fields)用作文档存储,以便在查询响应中返回字段的原始值。默认情况下,它们还存储 ② _source,其中包含写入的原始 JSON 文档。存储字段使用 index.codec 设置指定的算法进行压缩——默认采用 lz4,或者可以选择 zstd 以获得更高的压缩比(但性能较低)。
③ doc_values 以面向列的磁盘结构存储来自 JSON 文档的值,针对聚合和排序等分析型查询进行了优化。需要注意的是,doc_values 不使用 lz4 或 zstd 进行压缩,而是根据列值的数据类型、基数等因素,采用特定的编解码方式对每一列单独编码。
此外,我们详细描述了其他 Lucene 段的数据结构,例如 ④ 倒排索引(Inverted Index)、⑤ Bkd 树和 ⑥ HNSQ 图。
_source 的作用
在 Elasticsearch 开源版本(OSS)中,_source 字段在重建索引或将索引升级到新主版本时至关重要,同时对返回原始文档的查询也很有用。禁用 _source 可以显著减少磁盘占用,但会失去这些功能。
在 Elasticsearch 企业版中,合成 _source(Synthetic _source)功能可以根据其他 Lucene 数据结构按需重建 _source。
我们的基准查询使用 doc_values,并不依赖 _source,因为查询返回的是聚合值而非原始文档。因此,我们通过禁用 _source 运行基准测试,以模拟合成 _source 带来的存储节省效果。同时,我们也测试了在不同压缩级别下启用 _source 的存储开销。
配置 Elasticsearch 以进行公平的存储对比
如前所述,Elasticsearch 以不同的结构索引和存储数据,以优化特定的访问模式。由于本次基准测试专注于数据聚合,我们对 Elasticsearch 进行了以下优化,使其更符合这一场景:
最小化倒排索引大小:禁用了全文搜索,将所有字符串字段映射为 keyword 类型。这既能支持高效过滤,又能填充 doc_values,提高聚合查询性能。
日期字段映射:将 JSON 文档中的日期字段映射为 Elasticsearch 的 date 类型,以便使用 Lucene 的 Bkd 树优化日期范围查询。
减少存储开销:禁用了所有元字段,仅存储 JSON 文档中的字段,并测试了禁用 _source 后的存储占用,以模拟合成 _source 的效果。
索引排序:使用与 ClickHouse 排序键相同的字段进行索引排序,以优化数据压缩和查询性能。
单节点优化:由于 Elasticsearch 运行在单节点环境,我们禁用了副本(Replicas)。
优化索引滚动和合并:遵循最佳实践,优化索引的滚动(Rollovers)和合并(Merges)。
下图总结了我们在 Elasticsearch 数据结构上的基准测试配置:
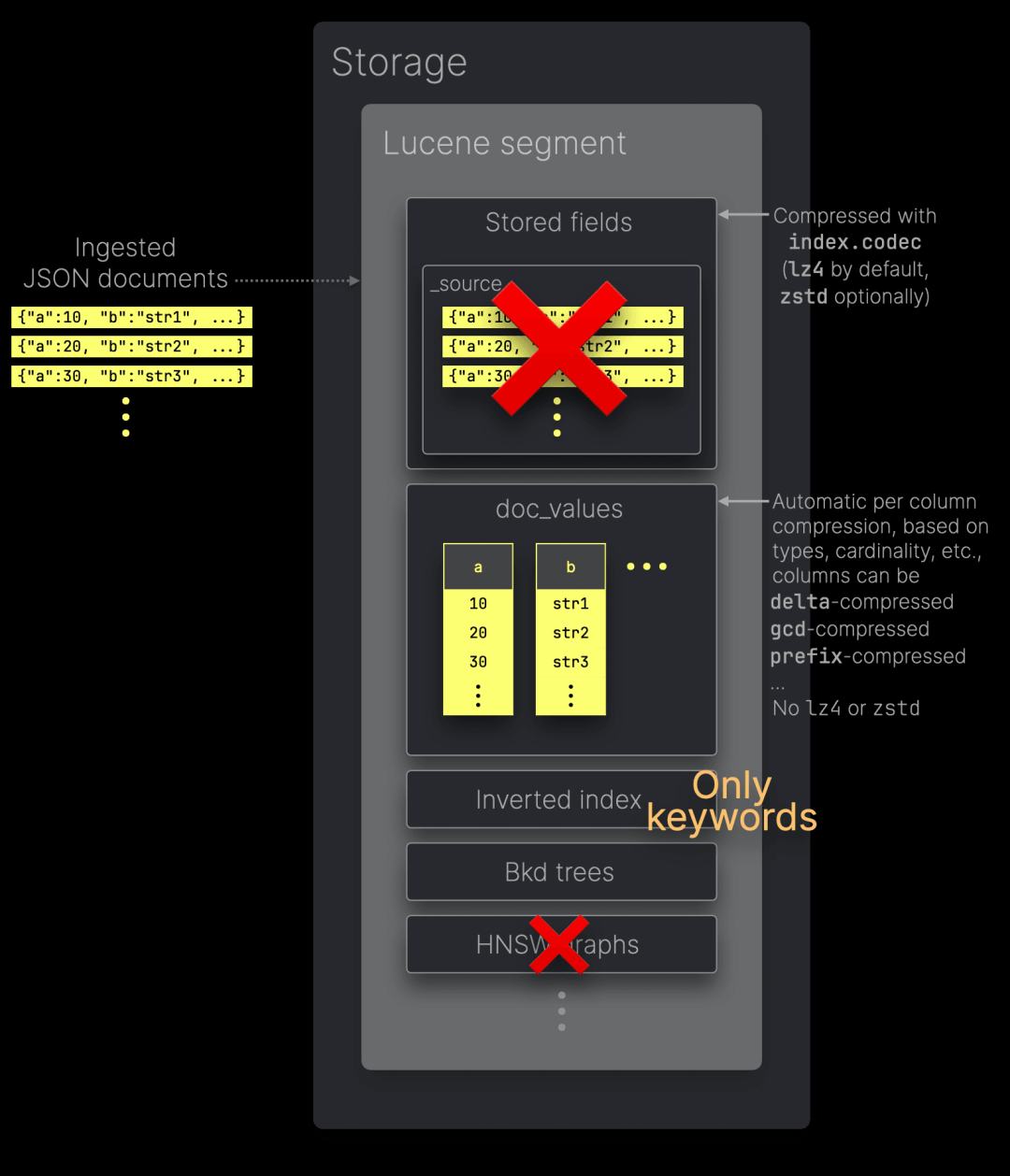
需要注意的是,禁用 _source 会使 index.codec 设置失效。无论选择 lz4 还是 zstd,都不会有数据可供这些算法进行压缩。
数据排序
为了提高存储字段和 doc_values 的压缩率,Elasticsearch 允许在数据压缩前进行磁盘数据排序。与 ClickHouse 类似,此排序还可以提升查询性能,因为它支持“提前终止”(Early Termination)。
缓存机制
Elasticsearch 主要依赖操作系统的页面缓存,并提供两种查询结果缓存:分片级请求缓存(Shard-Level Request Cache)和段级查询缓存(Segment-Level Query Cache)。
此外,Elasticsearch 在 Java 虚拟机(JVM)内执行所有查询,并在启动时通常分配一半的物理 RAM(最高 32 GB)作为堆内存(Heap)。这个 32 GB 的限制有助于提高对象指针的内存效率。超过该限制的物理 RAM 将用于操作系统页面缓存,以缓存从磁盘加载的数据。
限制
在大规模数据分析和可观测性(Observability)应用场景中,查询通常需要在数十亿行数据上执行 count(*) 和 count_distinct(...) 聚合。
为了模拟真实场景,我们的大部分基准查询都包含 count(*) 聚合,其中查询 ② 还包含 count_distinct(...) 聚合。
在 Elasticsearch 中:
当数据分布在多个分片(Shards)时,count(*) 聚合的结果是近似值。
ES|QL(Elasticsearch Query Language)的 COUNT_DISTINCT 聚合函数也是近似值,基于 HyperLogLog++ 算法。
相比之下,ClickHouse 可以精确计算 count(*),并提供 count_distinct(...) 的近似版和精确版。在查询 ② 中,我们选择了精确版本,以保证数据的准确性。
在 Bluesky 测试数据集中,time_us JSON 路径包含微秒精度的时间戳。Elasticsearch 支持将这些时间戳存储为 date_nanos 类型,但 ES|QL 的日期和时间函数仅适用于 date 类型(精度为毫秒)。作为变通方案,我们将 time_us 存储为 date 类型,从而降低精度。
ClickHouse 在日期和时间处理上支持纳秒精度,因此可以直接处理这些高精度数据。
DuckDB
DuckDB 是一个面向单节点环境设计的列式分析数据库。
JSON 支持
DuckDB 于 2022 年引入了 JSON 逻辑类型(JSON Logical Type)来支持 JSON 数据。
JSON 存储
DuckDB 是一个列式数据库。然而,与 ClickHouse 不同,DuckDB 采用不同的方式存储 JSON 数据。在包含 JSON 列的 DuckDB 表中,写入的 JSON 文档会被存储为普通字符串,而不会被分解或优化为列式存储格式:
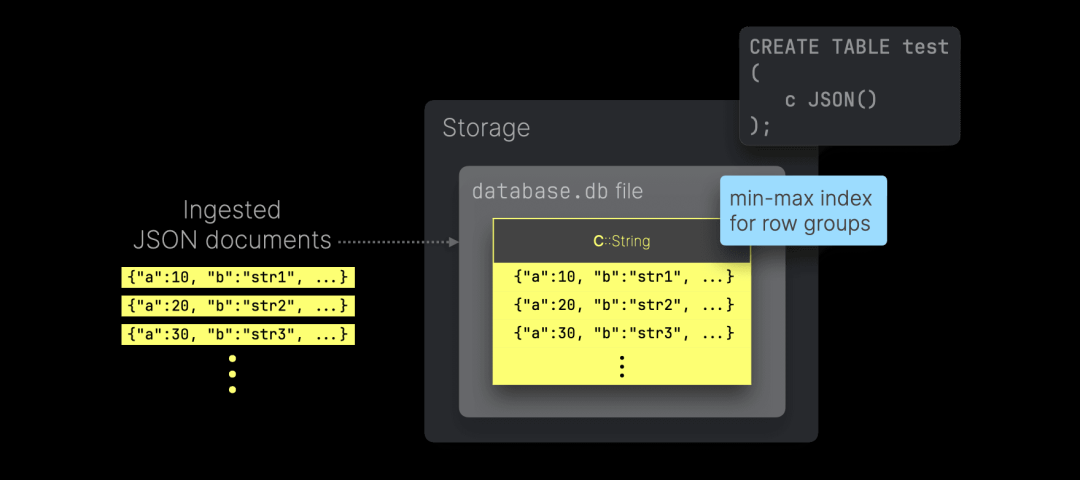
DuckDB 会自动为通用数据类型列创建最小-最大(min-max)索引,在每个行组(Row Group)中存储最小值和最大值,以加速过滤和聚合查询。
此外,对于具有 PRIMARY KEY、FOREIGN KEY 或 UNIQUE 约束的列,DuckDB 还会生成自适应基数树(Adaptive Radix Tree,ART)索引。ART 索引也可以显式添加到其他列上,但存在以下限制:
需要存储一份额外的数据副本;
其作用仅限于点查询(Point Queries)或高度选择性的过滤条件(目标数据量约占总行数的 0.1% 或更少)。
数据压缩
DuckDB 会根据数据类型、基数(Cardinality)等因素,自动对列数据应用轻量级压缩算法。
数据排序
DuckDB 文档建议在数据插入时预排序,以便将相似的值分组,从而提高压缩率并增强最小-最大索引的效果。然而,DuckDB 并不提供自动数据排序功能。
缓存机制
DuckDB 依赖操作系统的页面缓存(Page Cache)以及自身的缓冲区管理器(Buffer Manager)来缓存来自持久化存储的数据页(Pages)。
PostgreSQL
PostgreSQL 是一个成熟的行存关系型数据库,具有一流的 JSON 支持。我们选择它作为行存数据库的代表,以比较其在性能和存储方面与 ClickHouse 和 DuckDB 等现代列式数据库的差异。然而,PostgreSQL 并非为 JSONBench 测试中的大规模分析工作负载设计,因此在这个上下文中,它并不直接与其他系统竞争。
JSON 支持
PostgreSQL 通过 JSON 和 JSONB 数据类型原生支持 JSON 数据。
JSON 类型于 2012 年随 PostgreSQL 9.2 版本引入,它以文本形式存储 JSON 文档,因此每次执行处理函数时都需要重新解析文档,这与 DuckDB 目前的逻辑 JSON 类型类似。
2014 年,PostgreSQL 9.4 引入了 JSONB 类型,它采用类似于 MongoDB BSON 的分解二进制格式。由于 JSONB 在性能和功能上都有改进,因此现在是 PostgreSQL 处理 JSON 数据的推荐选项。
JSON 存储
PostgreSQL 是基于行的存储系统,因此写入的 JSON 文档以 JSONB 元组的形式按顺序存储在磁盘上:
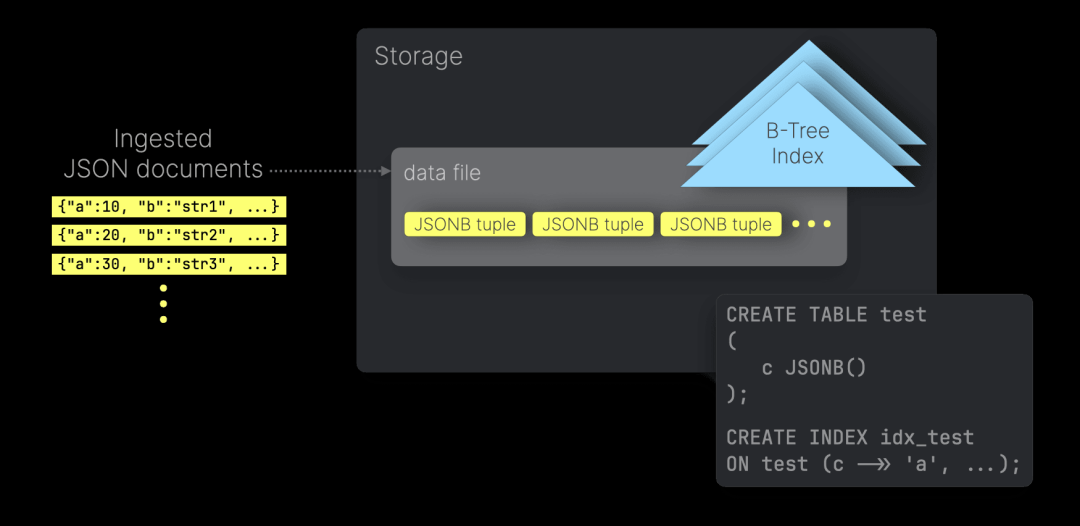
用户可以在特定的 JSON 路径上创建二级索引,以加速基于这些路径的查询过滤。默认情况下,PostgreSQL 使用 B-Tree 索引数据结构,其中每个索引条目对应一个已写入的 JSON 文档,并存储该文档中被索引的 JSON 路径的值。
仅索引扫描(Index-only scans)
PostgreSQL 通过 B-Tree 索引支持仅索引扫描(Index-only Scans),类似于 MongoDB。这适用于查询仅引用索引中存储的 JSON 路径的情况。然而,该优化并非自动启用,而是依赖于表数据的稳定性,即行数据在可见性映射(Visibility Map)中被标记为可见。这样,查询可以直接从索引读取数据,而无需再访问主表进行额外检查。
要验证 PostgreSQL 的查询规划器是否为某些基准查询使用了仅索引扫描,可以检查 PostgreSQL 基准测试跟踪的查询执行计划。
数据压缩
PostgreSQL 采用行存格式,在磁盘上以 8 KB 页面存储数据,目标是尽可能填充每个页面。为了优化存储,元组(Tuple)最好保持在 2 KB 以下。任何超过 2 KB 的元组都会使用 TOAST 处理,该机制会压缩并拆分数据为更小的块。TOAST 机制支持的压缩方法包括 pglz 和 lz4,而小于 2 KB 的元组则保持未压缩状态。
数据排序
PostgreSQL 支持簇表(Clustered Tables),即数据会根据索引元组的顺序进行物理重排。然而,与 ClickHouse 和 Elasticsearch 不同,PostgreSQL 的数据压缩率不会因数据排序而提高。这是因为,正如前文所述,PostgreSQL 的压缩是基于单个元组进行的(仅针对大于 2 KB 的元组),而不考虑数据顺序。此外,PostgreSQL 采用行存格式,无法像列存数据库那样将相似的数据集中存储,从而利用相邻数据的相似性提高压缩效果。
缓存机制
PostgreSQL 采用内部缓存来加速数据访问,包括缓存查询执行计划以及频繁访问的表和索引数据块。与其他基准测试对象类似,它也利用操作系统的页面缓存(Page Cache)。然而,PostgreSQL 并未提供专门的查询结果缓存。
受 ClickBench 的启发,我们创建了 JSONBench——一个完全可复现的基准测试,您可以在几分钟内在自己的机器上搭建并运行。详细的安装指南请参见此处。
硬件和操作系统
每个基准测试对象均在一台专用的 AWS EC2 `m6i.8xlarge` 实例上运行,该实例配置如下:
32 核 CPU
128 GB 内存
10 TB `gp3` 存储卷
操作系统:Ubuntu Linux 24.04 LTS
测试系统版本
我们基准测试了以下开源 (OSS) 版本的数据库,这些数据库均原生支持 JSON 数据:
ClickHouse 25.1.1
MongoDB 8.0.3
Elasticsearch 8.17.0
DuckDB 1.1.3
PostgreSQL 16.6
度量指标
本基准测试评估存储大小和查询性能,并在默认数据压缩设置及最佳可用压缩选项下对各系统进行测试。
此外,根据不同数据库的自省(Introspection)能力,我们还记录了以下数据:
索引存储大小:
[ClickHouse 示例](点阅读原文网页版看示例)
[MongoDB 示例](点阅读原文网页版看示例)
[PostgreSQL 示例](点阅读原文网页版看示例)
仅包含数据(不含索引)的存储大小:
[ClickHouse 示例](点阅读原文网页版看示例)
[MongoDB 示例](点阅读原文网页版看示例)
[PostgreSQL 示例](点阅读原文网页版看示例)
总存储大小(数据 + 索引):
[ClickHouse 示例](点阅读原文网页版看示例)
[MongoDB 示例](点阅读原文网页版看示例)
[Elasticsearch 示例]点阅读原文网页版看示例()
[DuckDB 示例](点阅读原文网页版看示例)
[PostgreSQL 示例](点阅读原文网页版看示例)
查询执行计划(用于检查索引使用情况等):
[ClickHouse 逻辑计划、物理计划示例](点阅读原文网页版看示例)
[MongoDB 示例](点阅读原文网页版看示例)
[DuckDB 示例](点阅读原文网页版看示例)
[PostgreSQL 示例](点阅读原文网页版看示例)
每个查询的峰值内存使用量:
[ClickHouse 示例](点阅读原文网页版看示例)
对于每个基准测试对象,我们分别测试 5 种典型分析查询在 8 组配置数据集上的冷运行(cold)和热运行(hot)性能。这些查询按顺序执行。
我们使用 SQL 语句为 ClickHouse、DuckDB 和 PostgreSQL 设定查询;对于 MongoDB,则采用等效的聚合管道查询;对于 Elasticsearch,则使用等效的 ES|QL 查询。为证明这些查询是等效的,我们还提供了在 100 万条 JSON 文档数据集上运行这些查询的结果链接(该数据集的质量在所有系统中均保持 100%):
查询 ① - Bluesky 事件类型排行
[ClickHouse 版本 + 结果](点阅读原文网页版看结果)
[MongoDB 版本 + 结果](点阅读原文网页版看结果)
[Elasticsearch 版本 + 结果](点阅读原文网页版看结果)
[DuckDB 版本 + 结果](点阅读原文网页版看结果)
[PostgreSQL 版本 + 结果](点阅读原文网页版看结果)
查询 ② - 按事件类型统计 Bluesky 的唯一用户数
[ClickHouse 版本 + 结果](点阅读原文网页版看结果)
[MongoDB 版本 + 结果](点阅读原文网页版看结果)
[Elasticsearch 版本 + 结果](点阅读原文网页版看结果)
[DuckDB 版本 + 结果](点阅读原文网页版看结果)
[PostgreSQL 版本 + 结果](点阅读原文网页版看结果)
查询 ③ - 用户何时使用 Bluesky
[ClickHouse 版本 + 结果](点阅读原文网页版看结果)
[MongoDB 版本 + 结果](点阅读原文网页版看结果)
[Elasticsearch 版本 + 结果](点阅读原文网页版看结果)
[DuckDB 版本 + 结果](点阅读原文网页版看结果)
[PostgreSQL 版本 + 结果](点阅读原文网页版看结果)
查询 ④ - 最活跃的 3 位发帖用户
[ClickHouse 版本 + 结果](点阅读原文网页版看结果)
[MongoDB 版本 + 结果]点阅读原文网页版看结果()
[Elasticsearch 版本 + 结果](点阅读原文网页版看结果)
[DuckDB 版本 + 结果](点阅读原文网页版看结果)
[PostgreSQL 版本 + 结果](点阅读原文网页版看结果)
查询 ⑤ - 活跃时间跨度最长的 3 位用户
[ClickHouse 版本 + 结果](点阅读原文网页版看结果)
[MongoDB 版本 + 结果](点阅读原文网页版看结果)
[Elasticsearch 版本 + 结果](点阅读原文网页版看结果)
[DuckDB 版本 + 结果](点阅读原文网页版看结果)
[PostgreSQL 版本 + 结果](点阅读原文网页版看结果)
在本博客文章中,我们分析并比较了最多 10 亿条 Bluesky JSON 文档的存储大小,以及在这些数据上依次执行的五种典型分析查询的查询性能。
本次评测涵盖了五种不同的开源数据存储系统,每种系统均运行在单节点环境下,并遵循严格定义的方法学,具体如下。
无调优
与 ClickBench 类似,我们对所有系统都使用标准配置,不进行任何精细化调优。
唯一的例外是 MongoDB,我们在运行查询 ② 时遇到了异常:
MongoServerError[ExceededMemoryLimit]: PlanExecutor error during aggregation :: caused by :: Used too much memory for a single array. Memory limit: 104857600. Current set has 2279516 elements and is 104857601 bytes.复制
此问题是由于 $addToSet 操作符引起的。该操作符被用作 MongoDB 缺少 COUNT DISTINCT 操作符的替代方案。然而,默认情况下,$addToSet 对内存集合(以数组形式实现)的大小限制为 100 MB,而在查询执行过程中,该限制被超出。为了解决这个问题,我们增加了 internalQueryMaxAddToSetBytes 的值。
此外,为了遵循最佳实践,并与 ClickBench 中的 MongoDB 设置保持一致,我们启用了 internalQueryPlannerGenerateCoveredWholeIndexScans 选项。此设置允许查询规划器生成覆盖索引扫描,确保 MongoDB 中的所有五个基准查询都是覆盖查询。因此,所报告的查询运行时间表示最优情况的下限,因为如果不启用该优化,查询运行时间会显著变慢。
无查询结果缓存
当启用查询结果缓存时,Elasticsearch 和 ClickHouse 等系统可以直接从缓存中获取结果,从而实现即时查询。然而,虽然这种方式高效,但无法为我们的基准测试提供有意义的性能分析。因此,为了确保一致性,我们在每次执行后禁用或清除查询结果缓存。
不提取顶级字段
我们的目标是仅测试各系统对 JSON 数据类型的处理性能。为确保一致性,每个被测试的系统及其数据配置都限制为使用仅包含一个 JSON 类型字段的表*。
在 ClickHouse**:
CREATE TABLE bluesky (data JSON) ORDER BY();复制
在 DuckDB:
CREATE TABLE bluesky (data JSON);复制
在 PostgreSQL:
CREATE TABLE bluesky (data JSONB);复制
* 虽然我们专注于测试不同系统的 JSON 数据类型,但需要注意,MongoDB 和 Elasticsearch 并非关系型数据库,它们对 JSON 数据的处理方式有所不同。
在 Elasticsearch 中,所有 JSON 路径的叶子值都会自动存储到多个数据结构中,以加速查询性能。
在 MongoDB 中,所有文档均以 BSON 文档的形式原生存储,并针对其文档型架构进行了优化。
** 在关联的 ClickHouse DDL 文件中,特定的 JSON 路径被定义为主键列,并在 JSON 类型子句中提供必要的类型提示。这与 DuckDB 和 PostgreSQL 等系统有所不同,后者使用二级索引来实现类似功能,而这些索引是在 `CREATE TABLE` 语句之外定义的。具体内容请参见下一节。
某些 JSON 路径可用于索引和数据排序
为了优化基准测试查询的性能,每个系统可以在以下 JSON 路径上创建索引:
kind:此路径主要决定后续结构,包括提交 (commit)、身份 (identity) 和账户 (account) 事件类型。
commit.operation:对于提交事件,指示操作类型,例如创建 (create)、删除 (delete) 或更新 (update)。
commit.collection:对于提交事件,标识特定的 Bluesky 事件类型,如发布 (post)、转发 (repost)、点赞 (like) 等。
did:触发事件的 Bluesky 用户 ID。
time_us:由于 Bluesky 时间戳路径结构不一致,我们假设 time_us 作为事件时间戳,尽管它实际记录的是我们从 Bluesky API 抓取事件的时间。
在除 DuckDB 和 Elasticsearch 之外的所有基准测试系统中,我们为上述所有路径创建了一个复合索引,并按照唯一值数量从低到高排序,以提高查询性能:
(kind, commit.operation, commit.collection, did, time_us)复制
在 ClickHouse 中,我们使用相应的主键 排序键创建索引:
ORDER BY (data.kind,data.commit.operation,data.commit.collection,data.did,fromUnixTimestamp64Micro(data.time_us));复制
在 MongoDB 中,我们创建了一个二级索引:
db.bluesky.createIndex({"kind": 1,"commit.operation": 1,"commit.collection": 1,"did": 1,"time_us": 1});复制
在 PostgreSQL 中,我们同样创建了一个二级索引:
CREATE INDEX idx_blueskyON bluesky ((data ->> 'kind'),(data -> 'commit' ->> 'operation'),(data -> 'commit' ->> 'collection'),(data ->> 'did'),(TO_TIMESTAMP((data ->> 'time_us')::BIGINT 1000000.0)));复制
对于 DuckDB,由于其索引类型无法为基准查询提供性能优化,同时 DuckDB 也不支持自动数据排序,因此未创建索引。
Elasticsearch 虽然不支持二级索引,但会自动将所有 JSON 路径的叶子值存储在多个数据结构中,以优化查询性能。此外,我们利用上述 JSON 路径进行索引排序,正如之前提到的,这有助于提高存储字段和 doc_values 在磁盘上的压缩率,减少存储开销。
我们为 MongoDB 和 PostgreSQL 启用了仅索引扫描
在基准测试中,我们的大多数查询都会对 kind、commit.operation 和 commit.collection 进行过滤(单个查询中涉及这三个路径),因此,我们在一个复合索引中包含了这些路径,以优化查询效率。
虽然 did 和 time_us 并未在任何查询中用作过滤条件,但我们仍然将它们纳入索引,以支持 MongoDB 和 PostgreSQL 的仅索引扫描,因为它们的查询优化器依赖这些字段已被索引。此外,在 ClickHouse 的索引中,我们也包含了 did 和 time_us,以便更直观地比较数据与索引在磁盘上的存储占用差异。
通过查询执行计划验证索引使用情况
正如前文所述,我们会分析每个系统的查询执行计划,以验证基准查询是否正确利用了指定的索引,确保基准测试的公平性和准确性。
允许数据集加载数量存在一定误差
在大规模 JSON 数据集中,由于不同系统的 JSON 解析方式存在差异,某些文档可能会出现加载失败。这些问题可能由 JSON 解析实现的不同、文档格式的边界情况或其他意外的数据特性导致。
在本次基准测试中,我们认为不需要强求 100% 的完全加载率。只要成功加载的文档数量与原始数据集规模大致相当,测试结果依然可以用于性能和存储对比。
在测试结果中,我们会跟踪基准数据集的大小 (dataset_size 字段) 以及成功加载的文档数 (num_loaded_documents 字段)。
例如,在 10 亿文档数据集中,各系统成功加载的 Bluesky JSON 文档数量如下:
ClickHouse:999,999,258
MongoDB:893,632,990
Elasticsearch:999,998,998
DuckDB:974,400,000
PostgreSQL:804,000,000
在 JSONBench 在线仪表板中,我们将每个系统成功加载的 Bluesky JSON 文档数作为数据质量 (Data Quality) 指标进行跟踪,并展示 100 万、1000 万、1 亿和 10 亿文档规模的数据集质量情况。
我们欢迎社区贡献 Pull Request,以改进数据加载方法,并减少不同系统间的解析误差。
冷启动与热启动查询时间
与 ClickBench 的测试方法类似,我们在每个系统和数据配置上执行每个基准查询三次,以分别测量冷启动和热启动的查询性能。第一次运行的时间被记录为冷启动时间,而热启动时间取第二次和第三次运行中的最短值。
在执行冷启动查询前,我们会清除操作系统级别的页面缓存(例如,ClickHouse 的缓存清理方法可参考此文档【https://github.com/ClickHouse/JSONBench/blob/c7afa7078aed72c55ff4441a2da635424fde7724/clickhouse/run_queries.sh#L16C5-L16C40】)。
现在让我们深入分析基准测试结果!按照前文所述的方法,我们对 10 亿 JSON 文档数据集进行了基准测试,并重点关注实际数据规模下的表现。
为了确保数据对比的清晰性和实际意义,我们仅展示了在每个系统采用最佳压缩方式时的存储结果。这样不仅便于对比(因为大多数系统都使用相同的 zstd 压缩算法),而且符合 PB 级数据场景,在这些场景下,数据压缩对降低存储成本至关重要。
出于避免重复的考虑,我们未展示较小数据集的测试结果。此外,在大规模数据处理环境下,这些数据集的参考价值相对有限。例如,Bluesky 这样的平台每秒可能会生成数百万个事件,因此较小的数据集难以真实反映系统的负载情况。
如果您希望查看完整的测试结果,包括不同压缩选项下的数据表现以及较小数据集的测试情况,可以访问我们的 JSONBench 在线仪表板,方便地分析和比较不同系统的结果:
· 100 万 JSON 文档:存储大小、冷启动时间、热启动时间
· 1000 万 JSON 文档:存储大小、冷启动时间、热启动时间
· 1 亿 JSON 文档:存储大小、冷启动时间、热启动时间
· 10 亿 JSON 文档:存储大小、冷启动时间、热启动时间
采用最佳压缩方式的存储大小

接下来,我们将逐步分析上图中的存储数据,从左到右依次解读七个数据柱的含义。
Bluesky 的 JSON 数据在未压缩状态下占用 482 GB 磁盘空间,而使用 zstd 压缩后,该数据量减少至 124 GB。
存储数据对比(最佳压缩方案)
将这些 JSON 文件导入 ClickHouse,并启用 zstd 压缩后,总磁盘占用为 99 GB。
值得注意的是,ClickHouse 存储的数据体积甚至小于使用相同压缩算法压缩后的原始文件。如前所述,ClickHouse 通过将每个唯一的 JSON 路径的值存储为独立列,并对每列进行单独压缩,从而优化存储。此外,使用主键后,相似的数据会被按列分组并排序,这进一步提升了压缩率。
在 MongoDB 中,启用 zstd 压缩后,存储 JSON 数据需要 158 GB 磁盘空间,比 ClickHouse 多 60 GB,增幅约 40%。
在我们的基准测试环境下,Elasticsearch 经过尽可能公平的配置。在禁用 _source 并启用 zstd 压缩的情况下,Elasticsearch 需要 220 GB 磁盘空间,超过 ClickHouse 的两倍(多出 121 GB)。
正如前文所述,Elasticsearch 的压缩算法仅适用于存储字段(如 _source)。因此,当 _source 被禁用时,压缩无法生效。这可以通过对比相同配置下使用 lz4 压缩的数据大小来验证。
如果必须启用 _source(例如在开源版本中,企业版的合成 _source 功能不可用),磁盘占用会进一步上升。在保持相同配置并启用 _source 后,所需存储空间达到 360 GB,是 ClickHouse 的 3.6 倍。而在启用 _source 且使用默认的 lz4 压缩时,磁盘占用进一步增加至 455 GB。
DuckDB 不提供可选的压缩算法,而是自动应用内置的轻量级压缩机制。导入 10 亿 JSON 文档后,磁盘占用达到 472 GB,接近 ClickHouse 的 5 倍。
PostgreSQL 仅对超出特定阈值的元组(tuples)进行压缩,并且仅在单个元组级别应用压缩。因此,在我们的数据集中,由于绝大多数元组未超出该阈值,压缩基本无效。即便使用最佳的 lz4 压缩,存储 10 亿 JSON 文档仍需 622 GB 磁盘空间,与默认 pglz 选项的存储占用几乎相同,比 ClickHouse 高出 6 倍以上。
基准查询执行时间
接下来,我们将展示各个系统在这些导入的 JSON 数据上的基准测试查询执行时间。
查询 ① 的聚合性能
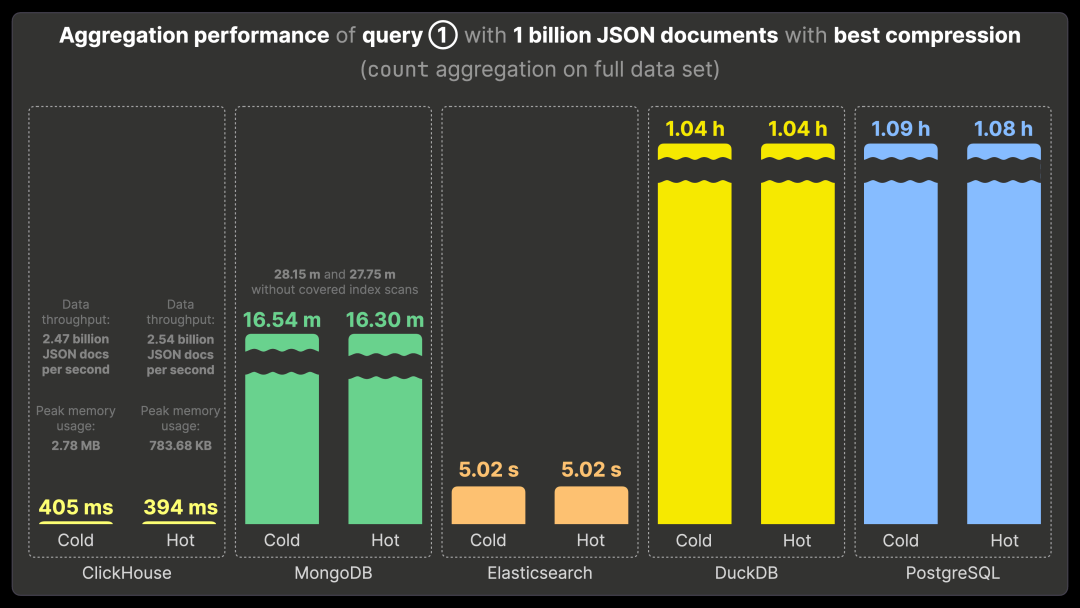
下图展示了各系统在存储 10 亿条 JSON 文档的数据集上,使用最佳压缩方式运行基准测试查询 ① 的执行时间,包括首次运行(Cold Runtime)和重复运行(Hot Runtime)。查询 ① 需要对整个数据集执行计数聚合,以统计最常见的 Bluesky 事件类型。
我们将按照图表中从左到右的 5 个部分,依次分析各系统的查询运行时间。
在 ClickHouse 上,查询 ① 首次运行耗时 405 毫秒,重复运行耗时 394 毫秒。其数据处理吞吐量分别为每秒 24.7 亿和 25.4 亿条 JSON 文档。此外,我们可以追踪 ClickHouse 的查询峰值内存使用情况,查询 ① 在首次和重复运行时均小于 3 MB。
MongoDB 启用了覆盖索引扫描(Covered Index Scans),以优化所有基准查询的执行效率。在此模式下,查询 ① 无论首次还是重复运行,均需约 16 分钟,比 ClickHouse 慢约 2500 倍。由于覆盖索引扫描会将查询所需的数据预存于索引的内存中,避免了从磁盘加载数据,因此首次和重复运行的时间几乎相同。
作为补充,我们还测试了 MongoDB 在未启用覆盖索引扫描时的查询性能:查询 ① 的首次和重复运行均需约 28 分钟,比 ClickHouse 慢 4200 倍。
Elasticsearch 使用 ES|QL 版本的查询 ①,执行时间约为 5 秒,无论首次还是重复运行,均比 ClickHouse 慢 12 倍。
DuckDB 处理查询 ① 需要约 1 小时(首次和重复运行时间相同),比 ClickHouse 慢 9000 倍。
PostgreSQL 处理查询 ① 也需要约 1 小时,与 DuckDB 表现类似,比 ClickHouse 慢 9000 倍。
DuckDB 和 PostgreSQL 在处理 10 亿规模的 JSON 数据时遇到了严重的性能瓶颈,所有 5 个基准查询的执行时间均极长。所有系统均在相同硬件环境和默认配置下进行测试。尽管我们尚未深入分析这些系统的具体瓶颈,但我们欢迎专家提供优化建议或提交 Pull Request 以改进性能。
查询 ② 的聚合性能
查询 ② 在查询 ① 的基础上增加了一个过滤条件,并额外执行 count_distinct 聚合,以补充每种流行的 Bluesky 事件的唯一用户数量。
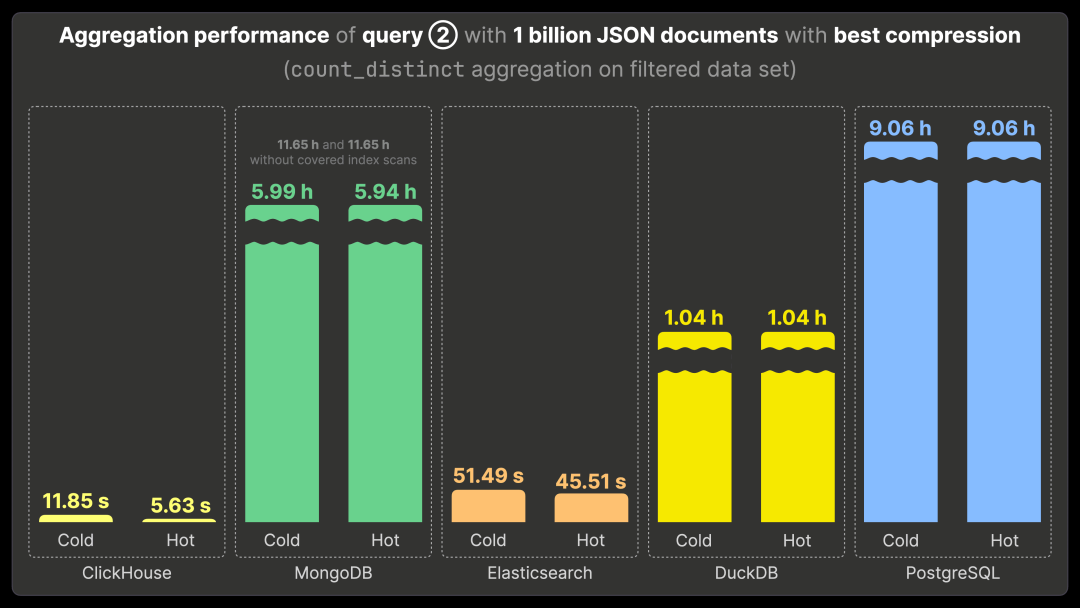
ClickHouse 运行查询 ② 需要 11.85 秒(首次运行)和 5.63 秒(重复运行)。性能对比如下:
比 MongoDB 快 3800 倍(MongoDB 运行时间约 6 小时)。
比未启用覆盖索引扫描的 MongoDB 快 7000 倍(运行时间约 11 小时)。
比 Elasticsearch 快 8 倍(冷运行 51.49 秒,热运行 45.51 秒)。
比 DuckDB 快 640 倍(运行时间约 1 小时)。
比 PostgreSQL 快 5700 倍(运行时间约 9 小时)。
查询 ③ 的聚合性能
查询 ③ 从事件时间戳中提取小时信息,并按小时分组,以分析特定的 Bluesky 事件在一天中最流行的时段。
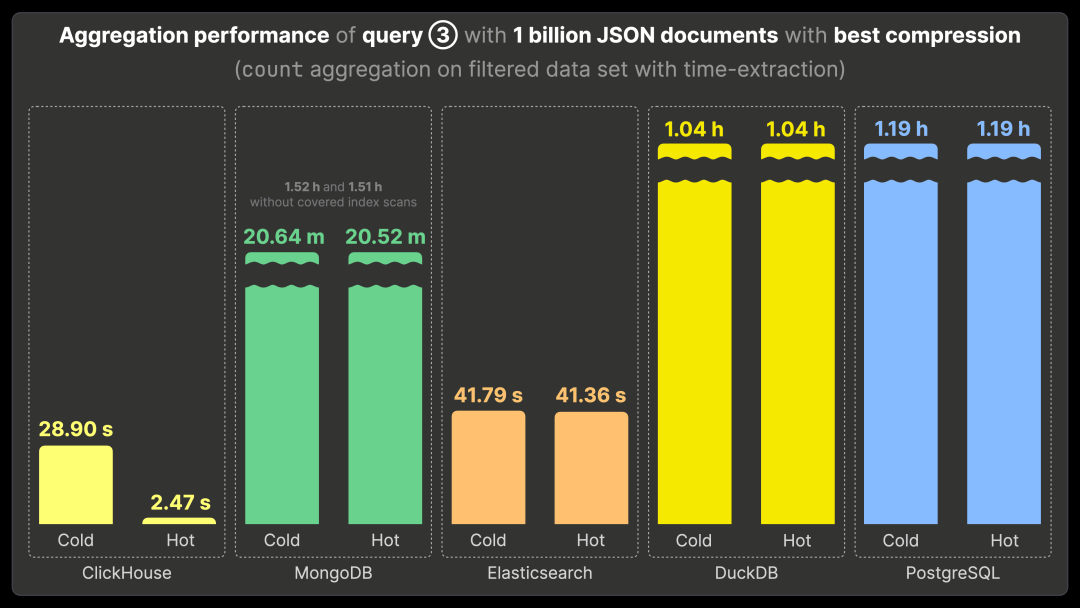
ClickHouse 运行查询 ③ 需要 28.90 秒(首次运行)和 2.47 秒(重复运行)。性能对比如下:
比 MongoDB 快 480 倍(运行时间约 20 分钟)。
比未启用覆盖索引扫描的 MongoDB 快 2100 倍(运行时间约 1.5 小时)。
比 Elasticsearch 快 16 倍(运行时间约 41 秒)。
比 DuckDB 和 PostgreSQL 快 1400 倍(运行时间均约 1 小时)。
查询 ④ 的聚合性能
查询 ④ 通过 min 聚合,找出发布最早帖子(资历最老)的 3 位 Bluesky 用户。
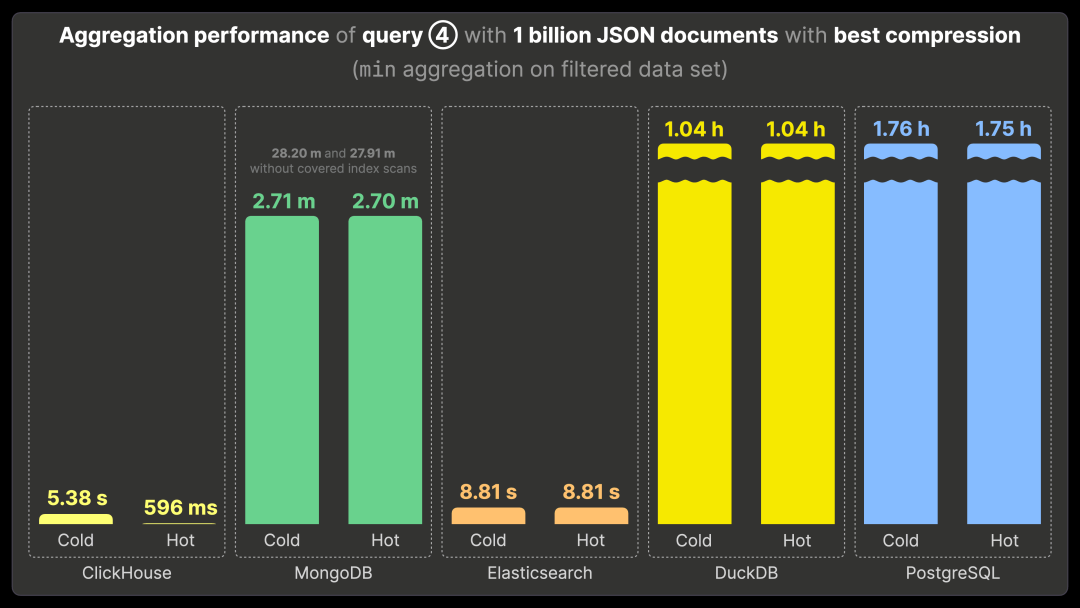
ClickHouse 运行查询 ④ 需要 5.38 秒(首次运行)和 596 毫秒(重复运行)。性能对比如下:
比 MongoDB 快 270 倍(运行时间约 2.7 分钟)。
比未启用覆盖索引扫描的 MongoDB 快 2800 倍(运行时间约 28 分钟)。
比 Elasticsearch 快 14 倍(运行时间约 8.81 秒)。
比 DuckDB 快 6000 倍(运行时间约 1 小时)。
比 PostgreSQL 快 10000 倍(运行时间约 1.75 小时)。
查询 ⑤ 的聚合性能
查询 ⑤ 通过 date_diff 聚合,找出在 Bluesky 平台上活动时间跨度最长的 3 位用户。
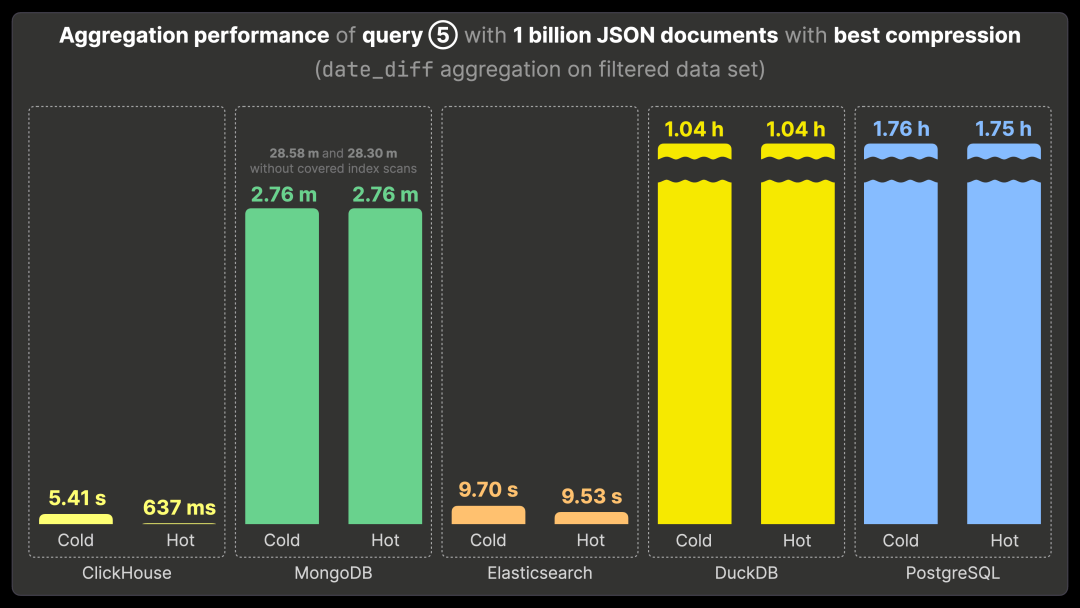
ClickHouse 运行查询 ⑤ 需要 5.41 秒(首次运行)和 637 毫秒(重复运行)。性能对比如下:
比 MongoDB 快 260 倍(运行时间约 2.76 分钟)。
比未启用覆盖索引扫描的 MongoDB 快 2600 倍(运行时间约 28 分钟)。
比 Elasticsearch 快 15 倍(运行时间约 9.5 秒)。
比 DuckDB 快 5600 倍(运行时间约 1 小时)。
比 PostgreSQL 快 9900 倍(运行时间约 1.75 小时)。
在我们的基准测试中,ClickHouse 在存储效率和查询性能方面全面超越了所有测试过的 JSON 数据存储系统。
在分析型查询方面,ClickHouse 不仅更快——相比领先的 JSON 数据存储(如 MongoDB),它的速度快数千倍,相比 DuckDB 和 PostgreSQL 也是如此,并且比 Elasticsearch 快十倍以上。更重要的是,ClickHouse 在提供卓越性能的同时,也保持了极高的存储效率——其 JSON 文档存储占用的空间甚至比磁盘上的压缩文件更小,大幅降低了大规模分析场景的总拥有成本。
ClickHouse 原生支持 JSON 数据类型,让您无需事先设计或优化数据模式,即可兼具高效的分析查询与极致的存储效率。这使得 ClickHouse 成为高性能通用型 JSON 数据存储的最佳选择,特别适用于事件数据通常以 JSON 格式存储,并且对成本控制和查询性能有严格要求的场景,例如基于 SQL 的可观测性平台。
希望本文能为您提供关于主流 JSON 数据存储系统的深入见解。如果您有兴趣参与,我们诚邀您为开源 JSON 基准测试项目 JSONBench 贡献力量——无论是优化现有测试,还是加入新的候选系统,甚至挑战“十亿文档 JSON 挑战”!🥊

我们正为上海活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


