





点击蓝字关注我们
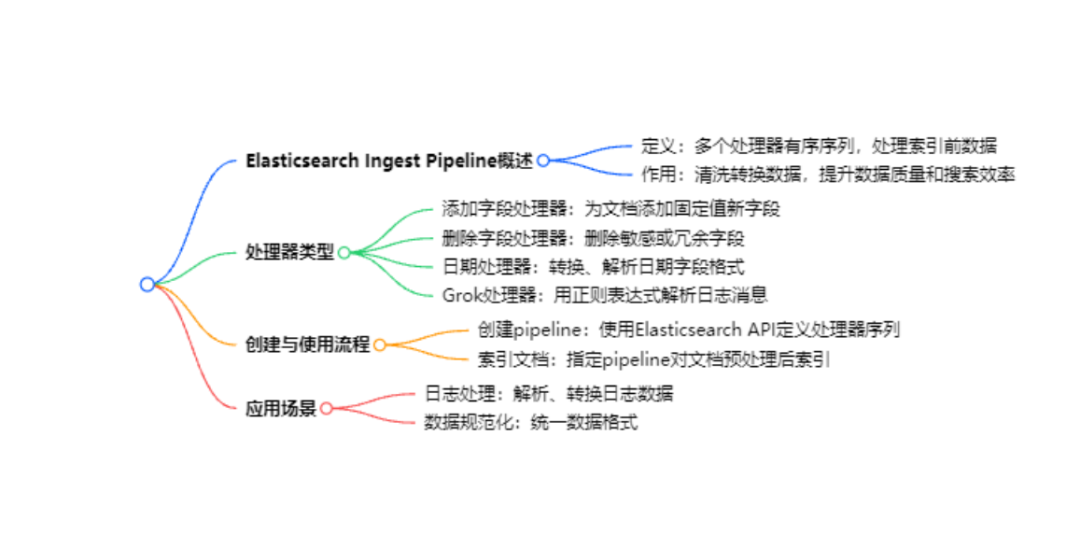
在当今数据驱动的时代,高效的数据处理与分析对于企业决策和业务发展至关重要。Elasticsearch作为一款强大的开源搜索引擎,为我们提供了众多功能来应对各种数据挑战。其中,Ingest Pipelines在数据预处理环节发挥着关键作用,它就像是数据进入Elasticsearch索引前的“智能加工厂”。接下来,让我们深入探究Ingest Pipelines的基础概念,开启这一强大功能的探索之旅。
为什么需要 Ingest Pipelines
在实际的数据处理场景中,我们从各种数据源获取到的数据往往是杂乱无章的,格式不一致、字段缺失或错误等问题屡见不鲜。例如,从不同系统收集的日志数据,可能包含多种时间格式、日志级别表达方式各异。如果将这些未经处理的数据直接索引到Elasticsearch中,后续的搜索和分析工作将变得异常困难,甚至可能得出不准确的结果。
Ingest Pipelines正是为了解决这些问题而生。它允许我们在数据被索引之前,对其进行一系列的转换和处理操作,确保进入索引的数据是干净、规范且易于分析的。这不仅提高了数据的质量,还极大地提升了Elasticsearch搜索和分析的效率。
什么是 Ingest Pipelines
从本质上讲,Ingest Pipelines是一个由多个处理器(processor)组成的有序序列。每个处理器都承担着特定的数据处理任务,当文档进入Elasticsearch的索引流程时,它会依次通过Ingest Pipeline中的各个处理器,每个处理器按照预设的规则对文档进行处理,最终输出经过处理后的文档并存储到索引中。
例如,假设我们有一个包含用户信息的文档,其中出生日期字段的格式为“YYYY/MM/DD”,但我们希望在索引中统一为“YYYY - MM - DD”的格式。我们可以在Ingest Pipeline中添加一个日期转换处理器,对这个字段进行格式转换。这样,所有进入索引的文档,其出生日期字段都会以我们期望的格式存储,方便后续的查询和分析。
Ingest Pipelines 中的处理器
处理器是Ingest Pipelines的核心组件,Elasticsearch提供了丰富多样的处理器,以满足不同的数据处理需求。以下是一些常见的处理器类型:
添加字段处理器(Add Field Processor):可以为文档添加新的字段,并设置固定的值。比如,为所有文档添加一个“数据来源”字段,并设置其值为“公司内部系统”。
删除字段处理器(Remove Field Processor):用于删除文档中不需要的字段。如果我们的文档包含一些敏感信息或冗余字段,在索引之前可以使用这个处理器将其删除。
日期处理器(Date Processor):正如前面提到的,它可以对日期字段进行格式转换、解析等操作,确保日期的一致性和准确性。
Grok处理器(Grok Processor):这是一个非常强大的文本解析处理器,特别适用于解析日志消息。通过定义正则表达式模式,它可以将复杂的文本内容提取到不同的字段中。例如,将“2023 - 01 - 01 12:00:00 INFO [main] Starting application”这样的日志消息,解析出时间戳、日志级别、线程名和消息内容等多个字段。
简单示例:创建一个基础的 Ingest Pipeline
为了更直观地理解 Ingest Pipelines 的工作原理,我们来看一个简单的示例。假设我们有一个索引,用于存储用户的登录信息,其中包含“login_time”字段,格式为“MM/dd/yyyy HH:mm:ss”,我们希望将其转换为Elasticsearch默认的日期格式“YYYY - MM - DD HH:MM:SS”。
首先,我们使用 Elasticsearch 的 API 创建一个 Ingest Pipeline:
PUT _ingest/pipeline/login_time_convert{"processors": [{"date": {"field": "login_time","formats": ["MM/dd/yyyy HH:mm:ss"],"target_field": "login_time","timezone": "UTC"}}]}
在这个 Pipeline 中,我们使用了日期处理器(date),指定要处理的字段为“login_time”,输入格式为“MM/dd/yyyy HH:mm:ss”,并将处理后的结果覆盖原字段,同时设置时区为UTC。
然后,在索引文档时,指定使用这个Pipeline:
PUT login_index/_doc/1?pipeline=login_time_convert{"user_id": "user1","login_time": "01/05/2023 10:30:00"}
这样,当文档被索引时,它会先经过“login_time_convert”这个Pipeline,“login_time”字段的格式会被转换为“YYYY - MM - DD HH:MM:SS”,然后再被存储到“login_index”索引中。
通过这一期的内容,我们对 Elasticsearch 的 Ingest Pipelines 有了初步的认识,了解了它的作用、基本概念以及常见的处理器类型。在后续的文章中,我们将深入探讨更多复杂的应用场景、高级处理器的使用以及如何优化 Ingest Pipelines 的性能。敬请期待!
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
