




在数据库系统中,Join算法是处理表间连接操作的重要算法。在MySQL中,通过选择合理的Join算法,快速查找匹配数据。下面介绍MySQL中,常见的Join算法。
Join算法
Join算法用于根据指定的连接条件,将两个或多个表中的记录组合起来。它是关系型数据库查询优化中的关键部分,直接影响查询的性能和效率。在MySQL8.0版本前,主要依赖于嵌套循环连接(Nested-Loop Join, NLJ)。是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。在MySQL中嵌套变体3种连接算法:简单嵌套循环连接、索引嵌套循环连接、块嵌套循环连接。
1.简单嵌套循环连接(Simple Nested-Loop Join ,SNL)
会读取驱动表中的一条记录,然后根据连接条件扫描内部表,反复循环,直到遍历完驱动表所有满足谓词条件的记录。常用的方式就是两张表之间的全表扫描。
for each row in t1 {
for each row in t2 {
if (row satisfies join conditions){
send to client
}
}
}
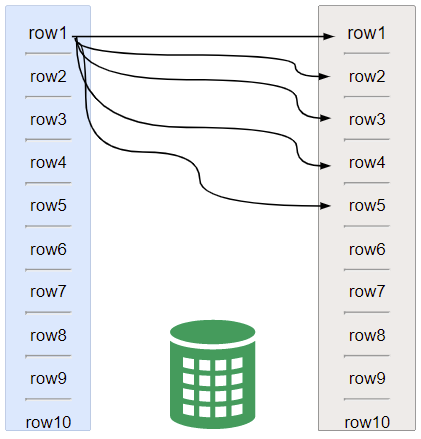
2.索引嵌套循环连接(Index Nested_Loop Join ,INL)
简单嵌套循环的版本版本,搜索过程使用索引来完成,效率更高。

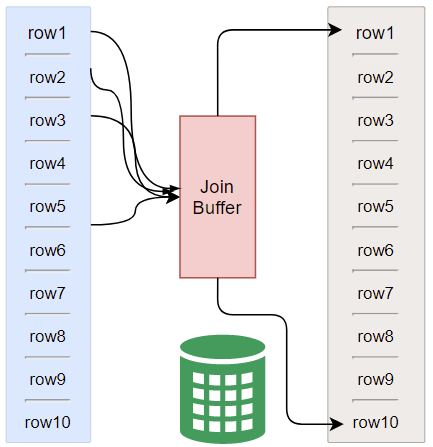
3.块嵌套循环连接(Block Nested-Loop Join,BNL)
在驱动表的结果存入Join Buffer, 被驱动表的每一行与整个Join buffer中的记录做比较,从而减少内层循环的次数。
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;
mysql>CREATE TABLE `t1` (
`id` bigint(20) NOT NULL,
`name` varchar(10)
)ENGINE=InnoDB ;
mysql>CREATE TABLE `t2` (
`id` bigint(20) NOT NULL,
`name` varchar(10)
) ENGINE=InnoDB ;
mysql>INSERT INTO t1(id,name) VALUES(1,'A'),(2,'B'),(3,'C');
mysql>INSERT INTO t1(id,name) VALUES(3,'C'),(4,'D'),(5,'E');
mysql> EXPLAIN SELECT a.* FROM t1 as a, t2 as b WHERE a.id=b.id;

在Explain中显示Using join buffer (Block Nested Loop)
4.批量键访问联接(Batched Key Access Join,BKA)
BNL算法使用一个类似于缓存的机制,将表数据分成多个块,然后逐个处理这些块,以减少内存和CPU的消耗。就是一次性缓存多条驱动表的记录到Join Buffer里,然后通过Join Buffer中的记录批量与内层索引循环读取的记录进行匹配。BKA算法支持内部连接、外部连接和半连接操作,包括嵌套的外部连接。(inner join, outer join, and semijoin 和nested outer joins)。必须在驱动表上建索引,这时就可以直接转成BKA算法。
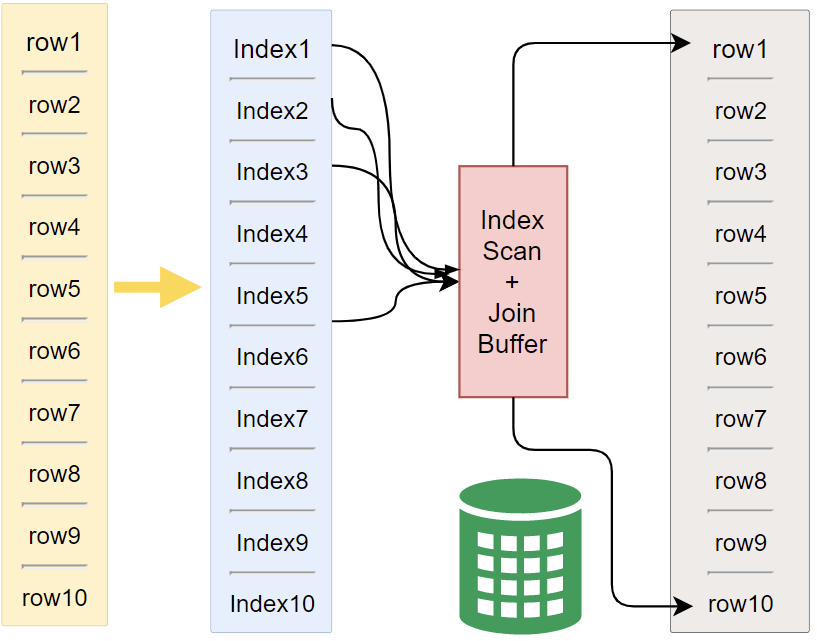
为了让Join使用 BKA 算法,给驱动表t1字段id加上索引。
mysql> CREATE INDEX idx_id ON t1(id);
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
mysql> EXPLAIN SELECT a.* FROM t1 as a, t2 as b WHERE a.id=b.id;

备注:MRR方式是,扫描二级索引,把收集到的主键值会被放入read_rnd_buffer内存中,之后主键值进行排序(排序的目的是为了将随机访问转换为顺序访问)。由于主键值是有序的,因此访问基表时产生的磁盘I/O也变为顺序I/O,从而提高了读取效率。
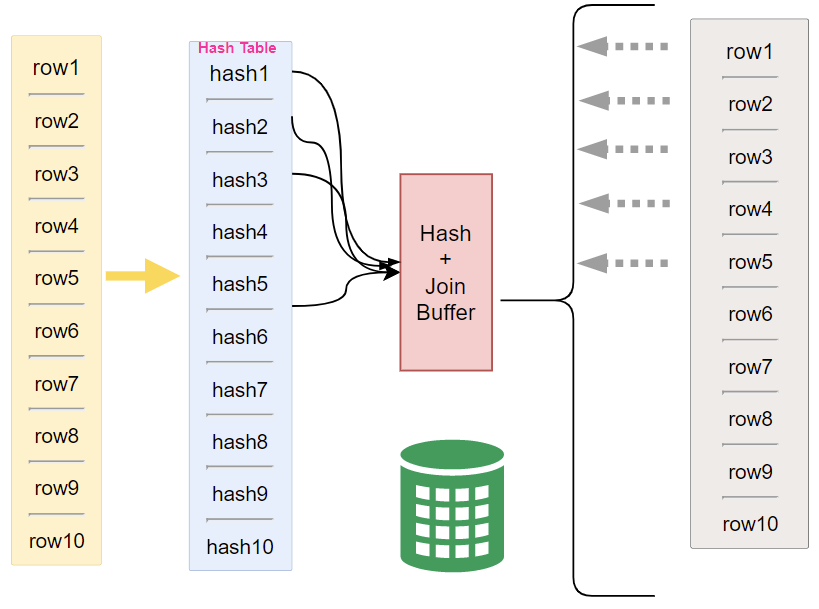
5.哈希连接(Hash Join)
在MySQL8.0.18及更高版本高版本,Nested-Loop方式基本已经被弃用。选择使用Hash Join方式处理。哈希连接是将表数据先构建哈希表,之后扫描哈希表。
- MySQL将连接操作的第一个表插入到哈希表中,其中哈希表的Key键是连接操作的连接column列。
- MySQL将连接操作的第二个表的每一行与哈希表中的相应行进行equi比较,如果它们的连接列匹配,则将它们作为连接操作的结果返回。
在Explain执行计划中,通过Extra信息可以看到使用了哈希连接,如:Using where; Using join buffer (hash join)

总结
MySQL8.0之后高版本中Hash Join的引入对SQL执行路径的优化产生了显著影响,使得MySQL在处理等值Join等场景时性能更优,同时优化器在选择执行路径时也有了更多的灵活性。
| 时间复杂度 | 说明 | |
|---|---|---|
| Nested Loop Join | O(M*N) | 适合小数据集,大数据集很慢 |
| Hash Join | O(M+N) | 适用于大数据集 |
