




开头还是介绍一下群,如果感兴趣PolarDB -MySQL ,Polardb-PostgreSQL,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2720人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6群均已爆满,7群430+,开8群9群)

终于PolarDB在完成了PolarDB-M 完全在云上可以取代MySQL的工作后,马上有开始针对云上的PostgreSQL开始了蓄谋已久的工作。
之前的文章也写过一些PolarDB for PostgreSQL的东西,但都是在研究和学习,2025年了,PolarDB for PostgreSQL的研发团队已经开始准备替代云上的POSTGRESQL RDS产品的之路,基于RDS产品的缺陷,后期会在我的云数据库专栏里面来说说,云数据库之间打架的事情,虽然没有 哪吒魔童闹海那么惊心动魄,但后续对云上的数据库产品重新排兵布阵是具有深远的影响。
为什么我会热衷云原生数据库的研究和学习,以及使用,因为年代不同了,无论是RDS ,还是ECS自建的开源数据库在云上进行部署,一句话换汤不换药,老牛车走老辙,云上的数据库最终都是要往云原生数据库上集中的,这里包含了成本,技术,厂商的倾向性等等,在这些知识普及后,如CTO这样的工作者势必会转向云原生数据库,而放弃RDS,或ECS自建的产品,在明白上层的领导的一些理念和后续的技术发展特性,势必走在前面有助于自我提升和延长工作位置的长度,终究他会,你不会,你会,他比你强,这就是卷的核心,无论是人,还是技术。
首先PolarDB for PostgreSQL 云原生数据库是基于PostgreSQL原版的基础上,贴近新型硬件,改进PostgreSQL缺陷,增加客户需要的新功能,完全真实的进行serverless提升数据库使用便利性的专属技术序列。
有想了解年前PolarDB FOR POSTGRESQL的产品经理到我这里说了什么的可以看如下的文章。今天主打开始使用PolarDB FOR PostgreSQL的感受之旅。在被厂商围剿的DBA 求生之路 --我是老油条
1 PolarDB FOR PostgreSQL 有什么特点:
1.1 上线就是两节点,读写自动分离,事务可以拆分也可以不拆分,同时可以通过代理来自动选择主库是否接受读请求,从库与主库将可以强一致。PG被攻击的连接数的问题,就不存在了,数据库本身带有一个强大的代理,连接数的问题不存在了,同时主从节点可以完全强一致,或者在你选择的时间内一致。
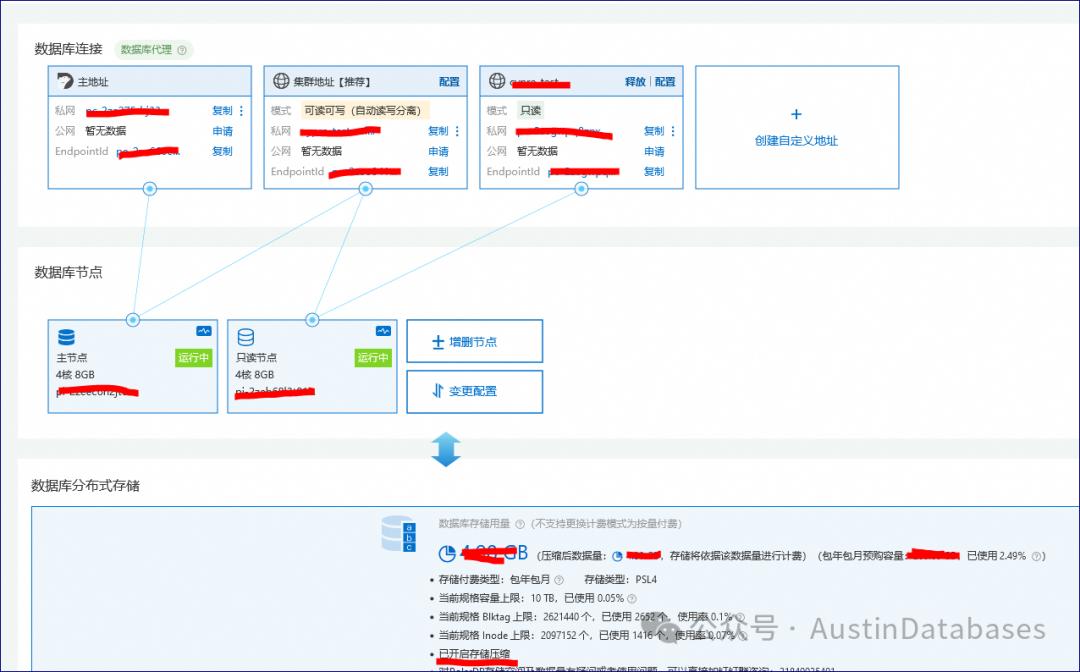
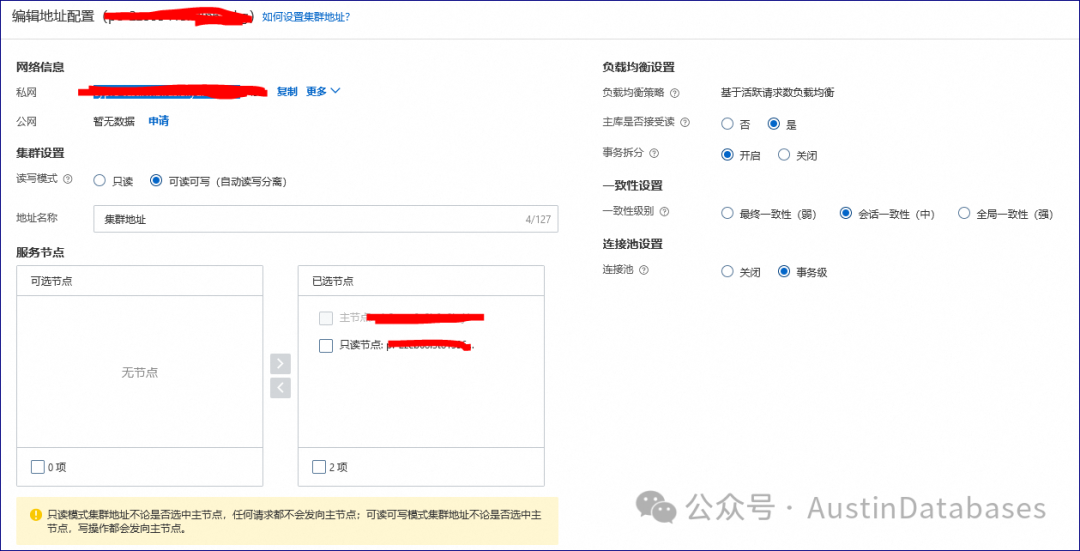
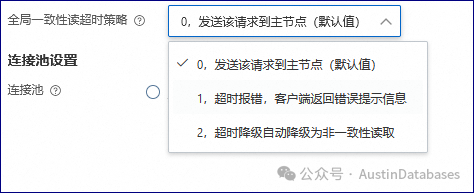
当然你可以选择主从节点不强一致,运行之间有多长时间的差距,比如100ms,如果读请求发现数据在从库比主库差距在100ms以上,则自动可以选择去主库读取数据或其他的方案。
1.2 上线可以开启数据压缩
与PostgreSQL的半遮半掩的toast部分压缩相比,PolarDB for PostgreSQL 是真压缩,纯硬件的数据直接压缩,同时支持TDE数据加密的功能。
当然这不是关键,今天的关键是要学习 PolarDB FOR POSTGRESQL 的独特技能,冷热分离数据库自持能力。
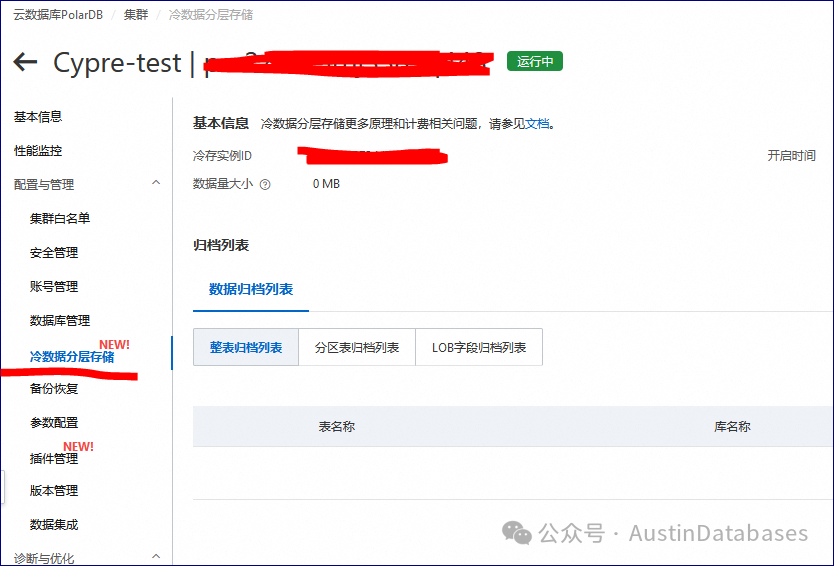
其核心的原理是POLARDB FOR POSTGRESQL 直接在数据库操作层面介入OSS存储介质,在SQL命令层面,直接将数据表下方到归档存储层的功能。这个功能我一直想试用。
易用性好
SQL透明:数据库的SQL操作完全透明,无需进行任何改写,支持OSS表联合查询;存储到OSS上的数据也支持进行增、删、改、查操作。
索引透明:支持针对索引、物化视图等设置归档策略,操作透明。
灵活度高
支持多种分层存储策略,包括按照表维度进行归档(同时支持索引、物化视图)、按分区维度进行归档、按指定LOB字段进行归档。并且支持不同策略的组合,可以根据业务使用情况进行灵活配置。
性能良好
查询性能良好,采用了三层缓存设计:UDF内逻辑对象缓存+页面共享缓存+文件持久化缓存,有效减少了对OSS的访问次数,从而将OSS的读写延迟影响降到最低。
安全可靠
OSS冷存数据同样支持备份恢复功能,在降低备份成本的同时还保障了高可用能力。
技术原理图
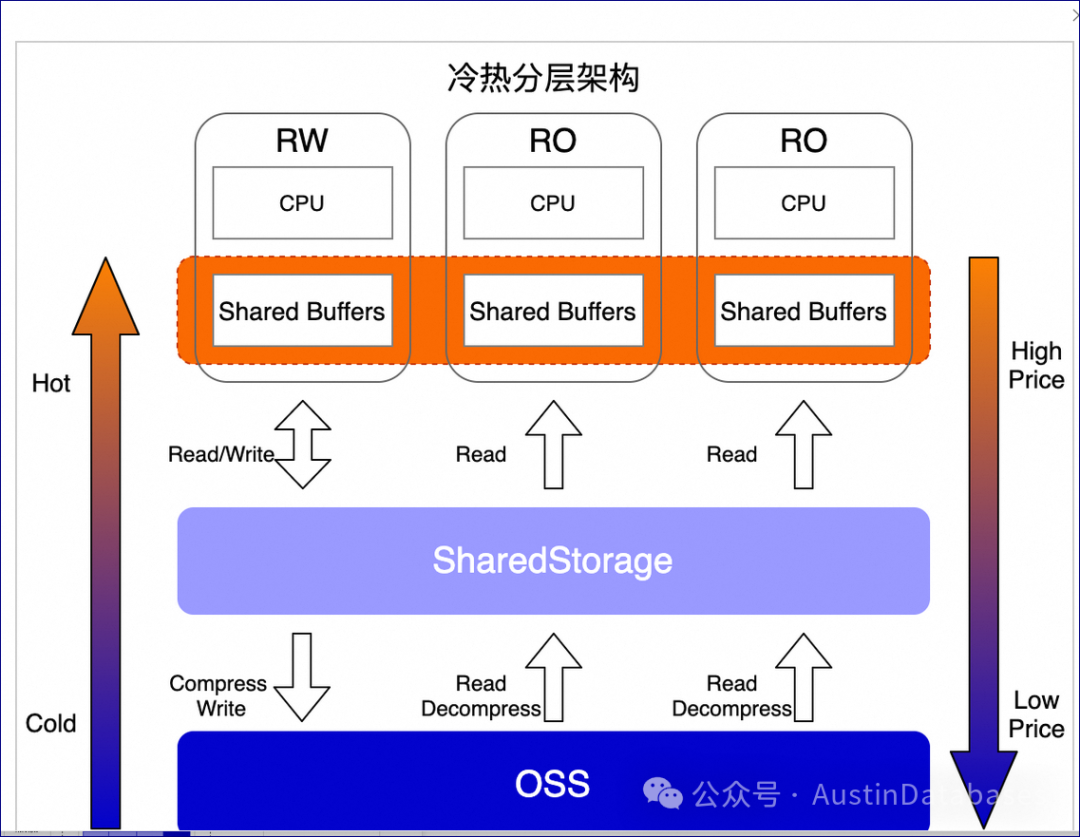
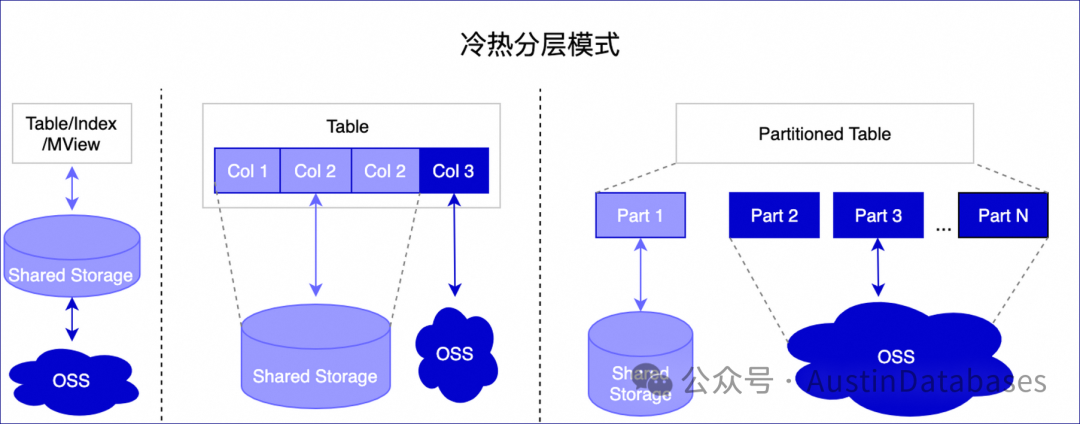
当然这里还有一些其他的功能,因为我是初学者,所以先不研究那么多,先尝试使用一下这个功能。
postgres=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
---------------+---------------+----------+---------+-------+---------------------------------
polardb_admin | polardb_admin | UTF8 | C | C | =T/polardb_admin +
| | | | | polardb_admin=CTc/polardb_admin
postgres | polardb_admin | UTF8 | C | C |
template0 | polardb_admin | UTF8 | C | C | =c/polardb_admin +
| | | | | polardb_admin=CTc/polardb_admin
template1 | polardb_admin | UTF8 | C | C | =c/polardb_admin +
| | | | | polardb_admin=CTc/polardb_admin
(4 rows)
postgres=> create database test;
CREATE DATABASE
postgres=>
postgres=> \c test
psql (13.15 (Debian 13.15-0+deb11u1), server 14.13)
WARNING: psql major version 13, server major version 14.
Some psql features might not work.
You are now connected to database "test" as user "postgres_admin".
test=> CREATE TABLE example_table (
test(> id SERIAL PRIMARY KEY,
test(> name VARCHAR(50),
test(> age INT,
test(> birthdate DATE
test(> );
CREATE TABLE
test=> INSERT INTO example_table (name, age, birthdate)
test-> SELECT
test-> 'Name ' || generate_series,
test-> floor(random()*100),
test-> CURRENT_DATE - (cast(random()*365*80 as int) || ' days')::interval
test-> FROM generate_series(1, 10000000);
INSERT 0 10000000
test=>
test=> -- 提交事务
test=> COMMIT;
WARNING: there is no transaction in progress
COMMIT
test=> select * from example_table limit 1;
id | name | age | birthdate
----+--------+-----+------------
1 | Name 1 | 75 | 2000-09-08
(1 row)
test=> select count(*) from example_table;
count
----------
10000000
(1 row)
test=> SELECT pg_size_pretty(pg_total_relation_size('example_table')) AS total_size;
total_size
------------
783 MB
(1 row)
test=> create index idx_name on example_table(name);
CREATE INDEX
test=> SELECT
test-> pg_class.relname AS indexname,
test-> pg_size_pretty(pg_relation_size(indexrelid)) AS index_size
test-> FROM pg_index
test-> JOIN pg_class ON pg_index.indexrelid = pg_class.oid
test-> WHERE pg_class.relname = 'idx_name';
indexname | index_size
-----------+------------
idx_name | 301 MB
(1 row)复制
下面我们简单的做一个测试,我们把表塞入OSS中,然后在从OSS中弄回到正式的PLS4磁盘中,我们比对一下不同存储中的查询的变化。
下方的具体的数据库的查询中我们看到在OSS中查询1000万的数据有索引的情况下,查询的时间是1.6ms,在PLS4上查询的时间是0.160ms,速度相差的还是比较大的,10倍的速度,但由于在PLS4中查询的速度太快,对于人的感觉来说,没有感觉二者的差异。
test=> alter table example_table set tablespace oss;
ALTER TABLE
test=> alter table example_table set tablespace pg_default;
ERROR: cannot move relation "example_table"which store on "oss", please make sure there is enough storage space and set"polar_osfs_allow_alter_oss_tablespace" to true
test=> select * from example_table limit 1;
id | name | age | birthdate
----+--------+-----+------------
1 | Name 1 | 75 | 2000-09-08
(1 row)
test=> select * from example_table where name = 'Name 293843';
id | name | age | birthdate
--------+-------------+-----+------------
293843 | Name 293843 | 84 | 1997-04-05
(1 row)
test=> explain analyze select * from example_table where name = 'Name 293843';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_name on example_table (cost=0.43..2.65 rows=1 width=24) (actual time=0.487..0.488 rows=1 loops=1)
Index Cond: ((name)::text = 'Name 293843'::text)
Planning Time: 1.622 ms
Execution Time: 0.524 ms
(4 rows)
test=> set polar_osfs_allow_alter_oss_tablespace=true;
SET
test=> alter table example_table set tablespace pg_default;
ALTER TABLE
test=> explain analyze select * from example_table where name = 'Name 293843';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_name on example_table (cost=0.43..2.65 rows=1 width=24) (actual time=0.012..0.012 rows=1 loops=1)
Index Cond: ((name)::text = 'Name 293843'::text)
Planning Time: 0.160 ms
Execution Time: 0.052 ms
(4 rows)复制
下面我们测试另一个功能,针对单独的字段存储在OSS中,和存储在PLS4中的性能对比。下面可以看到,OSS 比PLS4上存储同样的数据库,慢了一倍,我个人觉得还好,主要是数据存储在更低成本的存储介质上了。
test=> CREATE TABLE test_large_object(id serial, val text);
CREATE TABLE
Time: 12.575 ms
test=> INSERT INTO test_large_object(val) VALUES((SELECT string_agg(random()::text, ':') FROM generate_series(1, 10000)));
INSERT 0 1
Time: 24.904 ms
test=> drop table test_large_object ;
DROP TABLE
Time: 21.054 ms
test=> CREATE TABLE test_large_object(id serial, val text);
CREATE TABLE
Time: 10.290 ms
test=> ALTER TABLE test_large_object alter column val set (storage_type='oss');
ALTER TABLE
Time: 8.060 ms
test=> INSERT INTO test_large_object(val) VALUES((SELECT string_agg(random()::text, ':') FROM generate_series(1, 10000)));
INSERT 0 1
Time: 45.827 ms
test=> drop table test_large_object ;
DROP TABLE
Time: 51.076 ms
test=>复制
在使用中,我和产品的研发人员进行了沟通,为什么使用了成本极低的OSS数据存储,PostgreSQL在操作中还能这么的快,原因在于PolarDB for PostgreSQL使用了二级缓存,最大可以调节到1T,默认为1G。
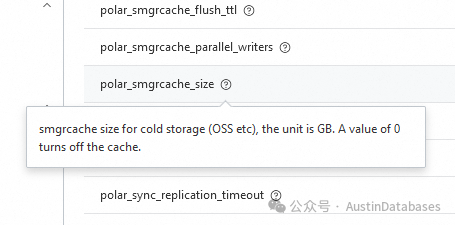
同时还支持强制缓存刷入到OSS中,也就是说我即使使用了OSS低成本的磁盘,但我还可以享受PLS5 PLS4的速度,主要经常使用的数据会在缓存中(实际上是高速磁盘且是一写三的分布式,不用考虑系统崩溃丢失数据,丢不了)缓存部分也可以进行监控和进行强制刷新到OSS磁盘中。
试用总结:在简单的试用中,将数据存储到OSS是一个开创性的云原生数据库的创意,ECS自建,PG RDS产品是没有这个功能的,对于PostgreSQL经常存储 4 5 6 7 8 9 10 T的我们,一些数据的确不应该占用昂贵的磁盘,对于一些不经常查询的表,或者归档的表的数据,直接可以一条命令让其存储到OSS上,并通过简单的方式还可以在恢复到高速的PLS4 PLS5上,让客户在存储成本上可以凭自己的实力来降低对应的成本,相对的速度还不慢,可谓是一个好的功能。
置顶
ORACLE 最终会把 MySQL 弄死对吗?原因是什么! (译)
2025数据库“新闻”,第四条坐实了开源PG属于谁? 开源MySQL低迷原因在哪?
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
PolarDB 相关文章
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火星人
PolarDB-MySQL 并行技巧与内幕--(怎么薅羊毛)
PolarDB 并行黑科技--从百套MySQL撤下说起 (感谢8018个粉丝的支持)
PolarDB 杀疯了,Everywhere Everytime Everydatabase on Serverless
POLARDB 从一个使用者的角度来说说,POALRDB 怎么打败 MYSQL RDS
PolarDB 最近遇到加字段加不上的问题 与 使用PolarDB 三年感受与恳谈
PolarDB 从节点Down机后,引起的主从节点强一致的争论
PolarDB serverless 真敢搞,你出圈了你知道吗!!!!
PolarDB VS PostgreSQL "云上"性能与成本评测 -- PolarDB 比PostgreSQL 好?
临时工访谈:PolarDB Serverless 发现“大”问题了 之 灭妖记 续集
临时工访谈:庙小妖风大-PolarDB 组团镇妖 之 他们是第一
POLARDB -- Ausitndatabases 历年的文章集合
PolarDB for PostgreSQL 有意思吗?有意思呀
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
MySQL相关文章
ORACLE 最终会把 MySQL 弄死对吗?原因是什么! (译)
MongoDB 相关文章
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
数据库 《三体》“二向箔” 思维限制 !8个公众号联合抽奖送书 建立数据库设计新思维
MongoDB 是外星人,水瓶座,怎么和不按套路出牌的他沟通?
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
阿里云系列
阿里云数据库产品权限设计缺陷 ,六个场景诠释问题,你可以做的更好?
阿里云数据库--市场营销聊胜于无--3年的使用感受与反馈系列
阿里云数据库产品 对内对外一样的卷 --3年阿里云数据库的使用感受与反馈系列
阿里云数据库使用感受--客户服务问题深入剖析与什么是廉价客户 --3年的使用感受与反馈系列
阿里云数据库使用感受--操作界面有点眼花缭乱 --3年的使用感受与反馈系列

