




leader 是集群中领导者,所有的读写都是走 leader,follower 副本不参加读写,leader 会周期性的向 follower 发出心跳,同时也会把自己的日志同步给 follower。
follower 不参与读写,只会对其它服务做出相应,并同步 leader 的日志。如果长时间收不到 leader 的心跳信息,这时候 follower 会把自己的角色变为 condidate(候选者),并发起投票。
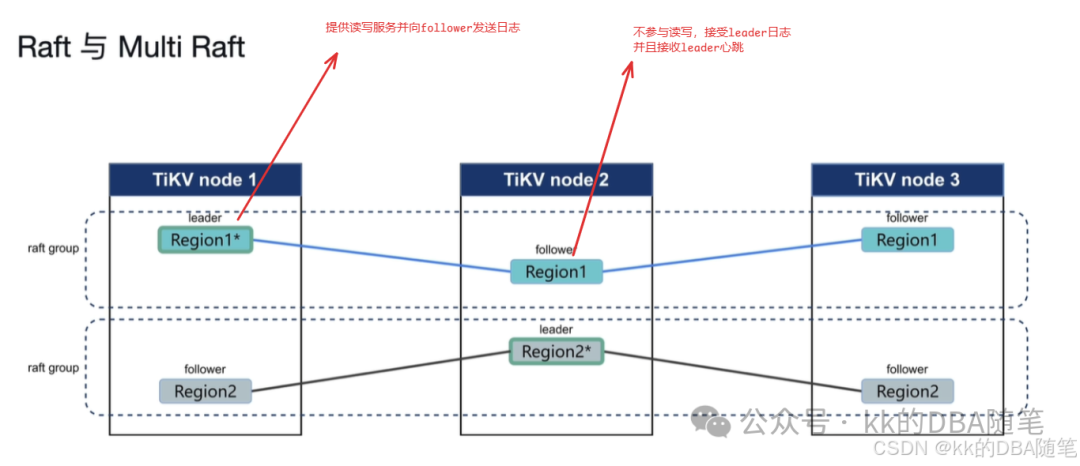
其中一个 region 及其两个副本 构成一个 raft group ,多个 raft group 构成了 multi raft。
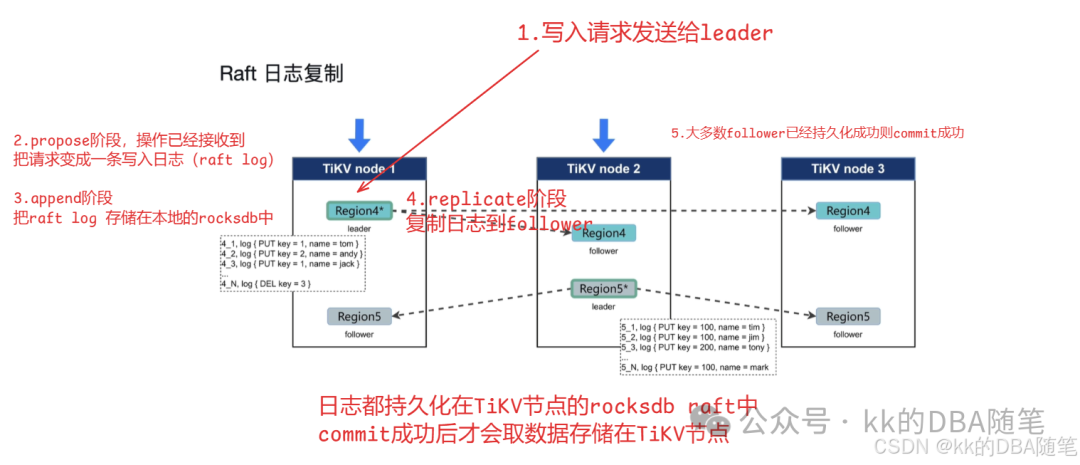
Raft 日志复制
- propose 阶段客户端接收到请求操作
- append 阶段:raft log 已经持久化到 rocksdb raft 中 (只在 leader 节点)
- replicate 阶段:把 leader 节点的 raft log 发到其它 TiKV 节点,同时持久化到自己的 rocksdb raft 中
- commit 阶段:其它节点将 raft log 持久化成功后 返回 leader 一个响应值,根据 raft 协议,超过一半返回响应成功,则 commit 成功
- Apply 阶段:将 raft log 写入到 rockdb KV 中(这一步是实际的数据落盘,也就是用户层面的 commit 阶段)
Raft Leader 选举
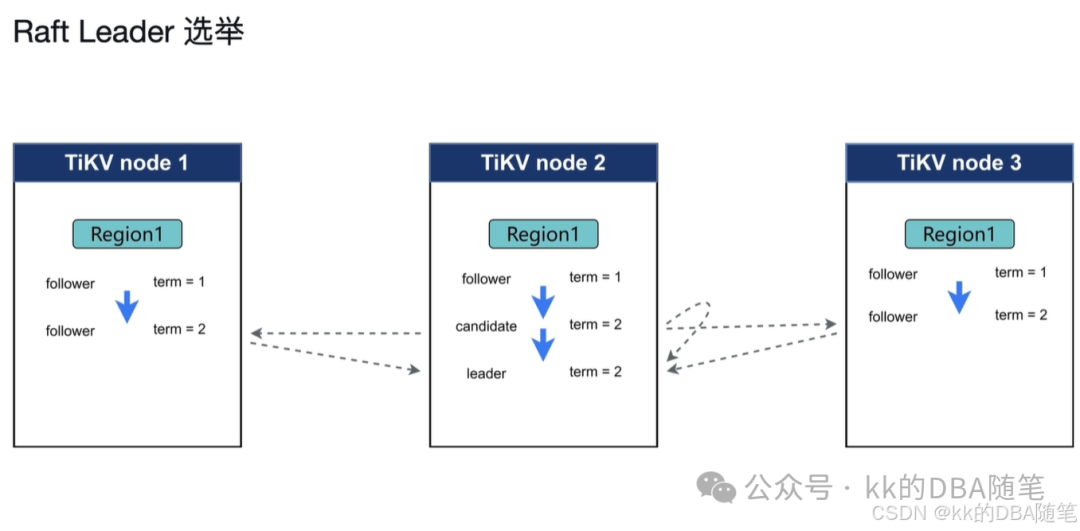
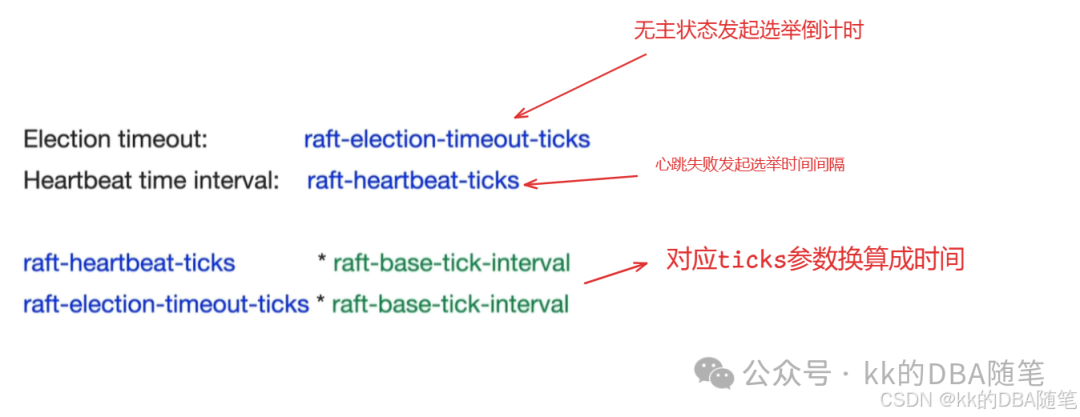
在集群刚开始创建时,大家都是 follower,这时候每个 region 都有一个计时器(election timeout),谁先到了 election timeout 则进入 candidate 阶段并发起选举,当选 leader。如果同时有多个 candidate ,这时候每个 region 都会投票给自己,则选举失败,重新开启新一轮投票,直到选出 leader。
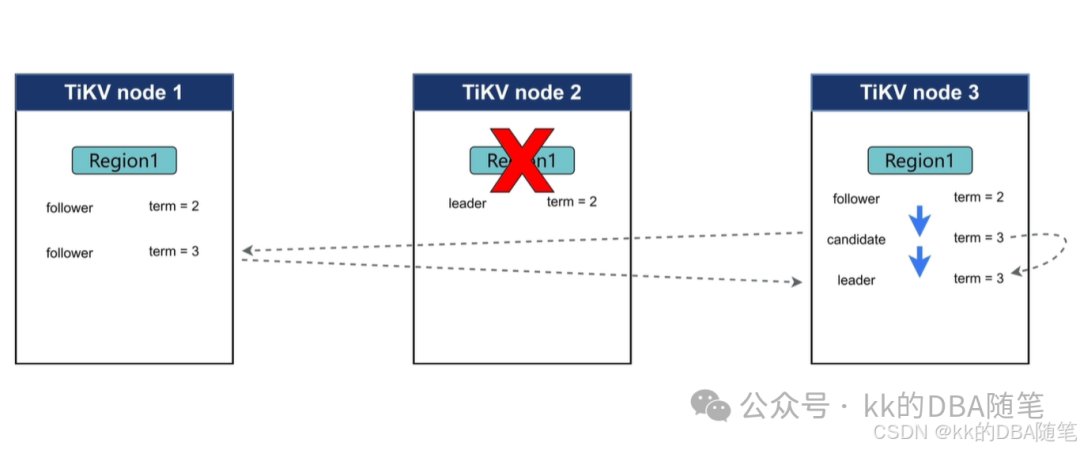
如果此时 leader 宕机,followrer 节点接收不到 leader 节点的心跳,则会倒计时(heart beat interval ),如果到了 heart beat interval followrer 节点将会进入 candidate 阶段,并发起选举,当选 leader。
相关参数:
文章转载自kk的DBA随笔,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
