




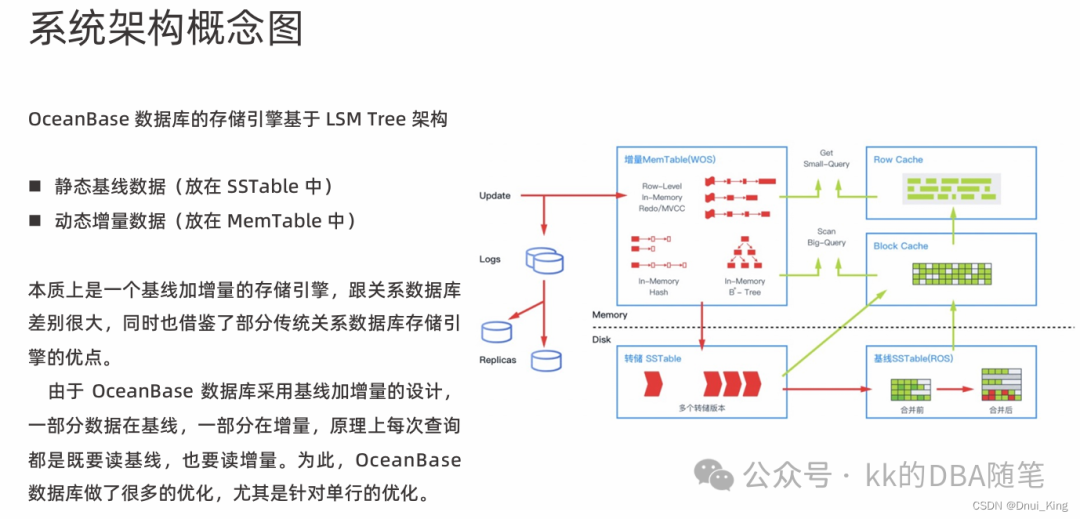
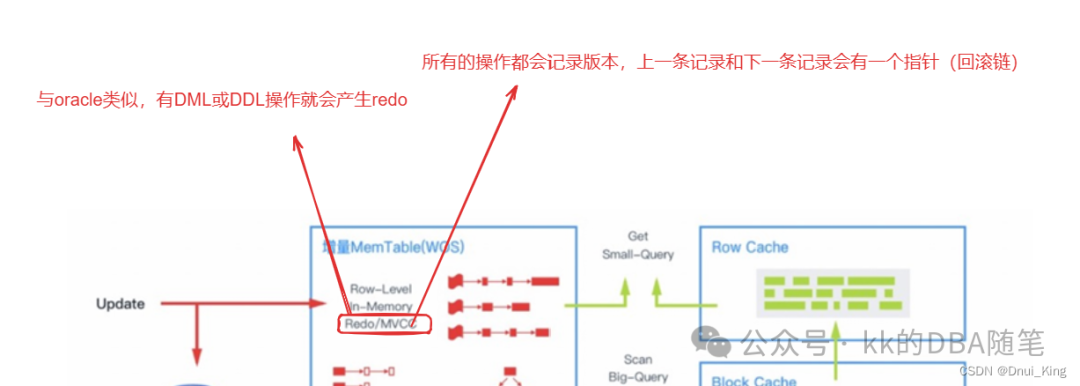
如图,Oceanbase 数据库的存储引擎基于 LSM Tree(结构日志合并) 架构。
从名字上来看,说明它是基于日志,有序存放的。
动态增量数据(放在 MemTable 中),还有个名词时 memstore,在租户中,包括 memstore 和 KVcache。
memtable 可以理解为存放的时候是基于表的存放,是一种增量的数据
如:DML 操作,在 OB 中 update 有自己的特点与 PG 有相同点。
在 PG 中做 update 操作会先删除再插入,但数据不会真正删除,会标记为 delete 状态。
OB 中做 update 操作与 PG 类似,直接插入一条新的数据,然后带上一条时间戳。不会像 oracle 一样直接在原来的行进行修改。
如上图,数据不会一直放在内存中,会放在静态基线数据,放在 SSTable(SortedString)中,看名字就知道它在底层是以排序好的字符串的形式。
为了持久化考虑,OB 的默认事务级别和 oracle 一样,也是 RC,提交后会把日志写到 redo log 中,在 ob 中也叫 clog(commit log)。
日志如何同步?
- 如果本机是 leader,它会把日志落到本地,同时把日志同步到另外两个副本。
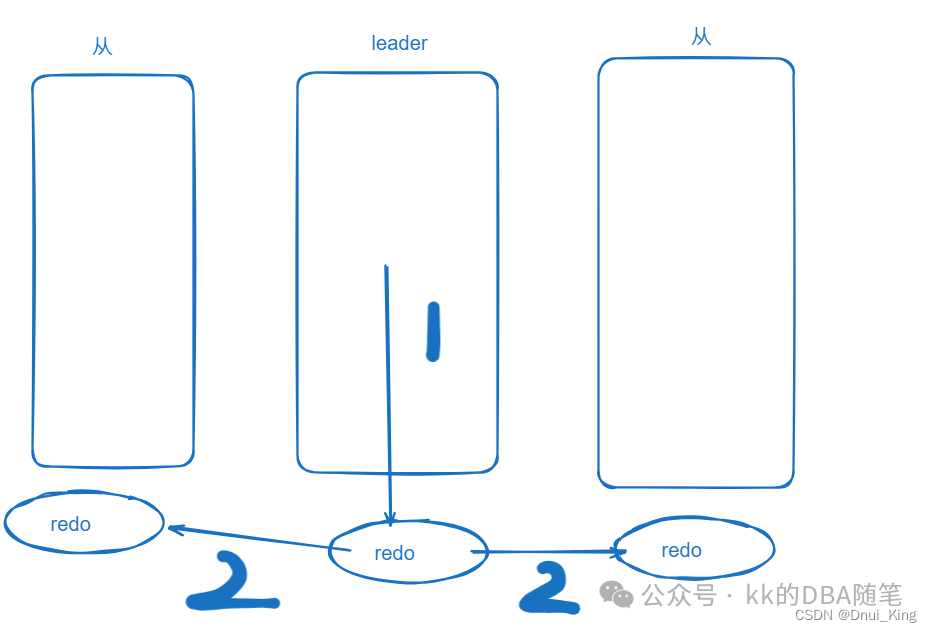
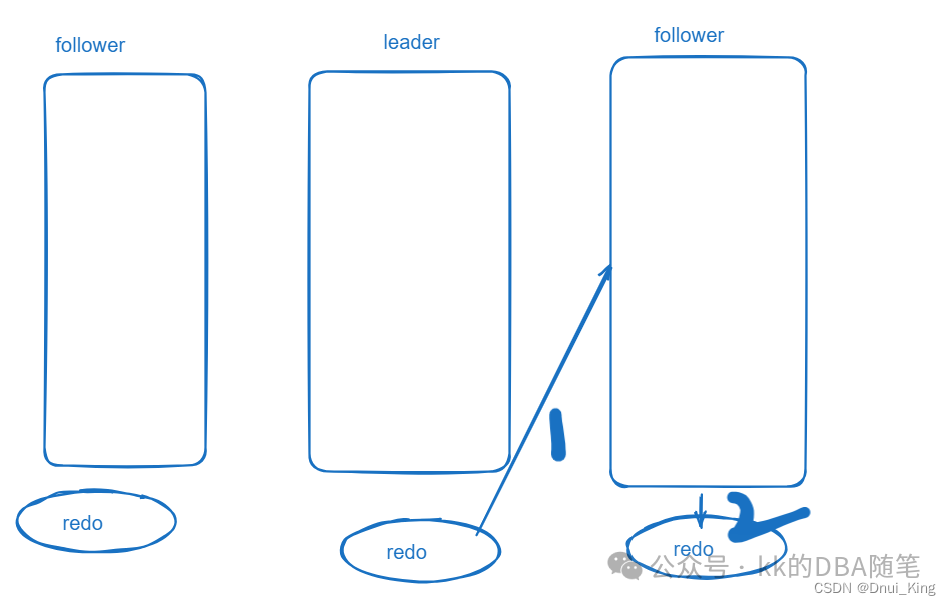
- 如果本机不是 leader,会接受 leader 产生的 redo,然后落盘。
memtable 结构:
1.Row-Level:
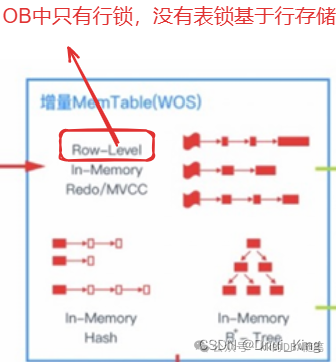
2.Redo/MVCC
3. 内存存储引擎
OB 是一个准内存数据库,内存会很大,要操作这么大的内存,如何快速找到我们想要的数据?
OB 中有两种方式:
1.hash 2.B 树
如果 DML 语句是一个范围操作,就会使用 B 树,如果是一个单行查询,就会使用 hash。
4. 数据读取内存区域
select 操作会怎么读取?
- 由于写内存区域(memtable)的数据是最新的,所以会先读 memtable
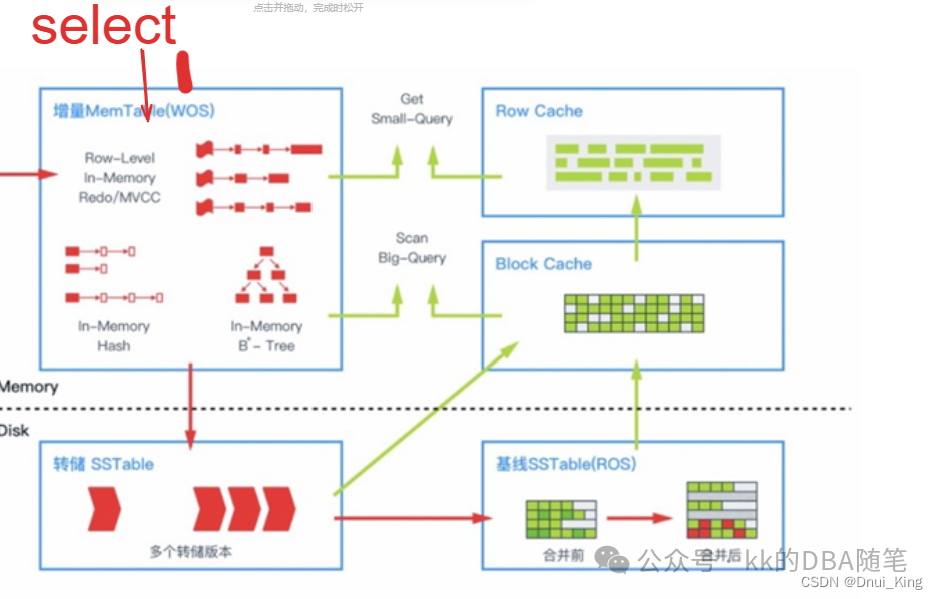
- 如果 memtable 里面没有,就需要去读转储 SSTable,再把数据写到 Block Cache。
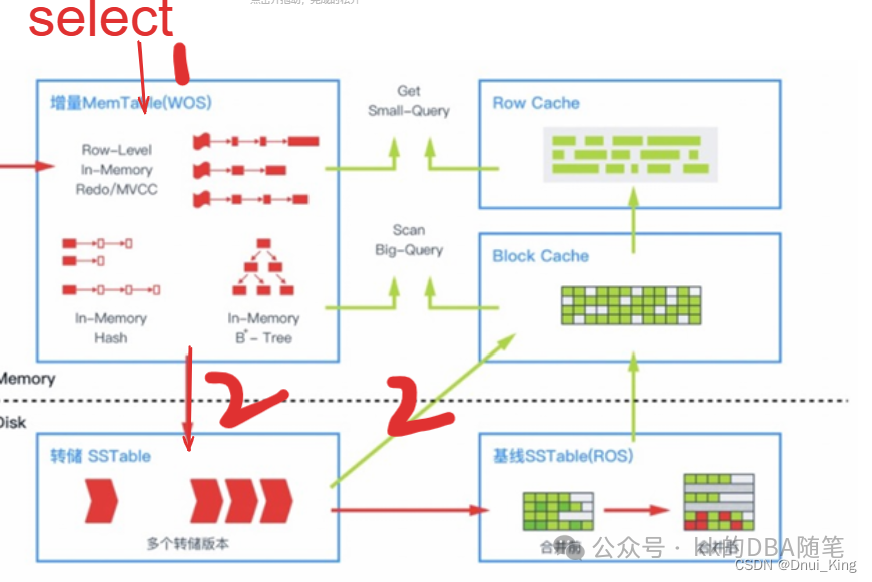
- 如果转储 SSTable 也没有,就会去找基线 SSTable
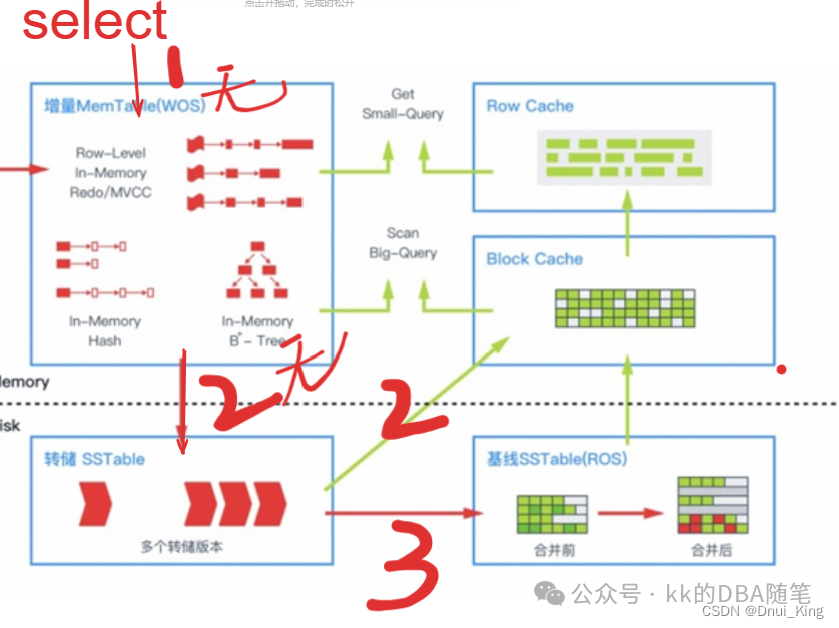
Block Cache 和 Row Cache 有什么区别?
在 OB 中磁盘中存放的单位是宏块——2M,类似于 oracle 中的 extent。
在宏块底层是微块——16k。
需要做全表扫描的时候,读 Block Cache 即可,Block Cache 适合 OLAP。
ROW 我理解为像一个缓冲池,适合 OLTP 系统,把热点行数据缓存在 ROW Cache,下次 select 直接访问 row cache 即可。
在 OB 中只有一个基线文件,随着合并,这个基线文件会很大。
如果 SSTable 所在的磁盘有 2T,那么会默认分配 2T*90=1.8T 给到这个文件。
所以要做 RAID 5 不做 RAID 0 并且使用 lvm 逻辑卷管理。
