




DeepSeek的迅速蹿红,也导致了目前收费的提升和服务质量的下降,同时随着DeepSeek的爆火和出圈、以及社区的完善和上手门槛的降低,大模型与普通人的距离也越来越近,对于IT人士而言可以不用钻研太多,但必须主动会用。
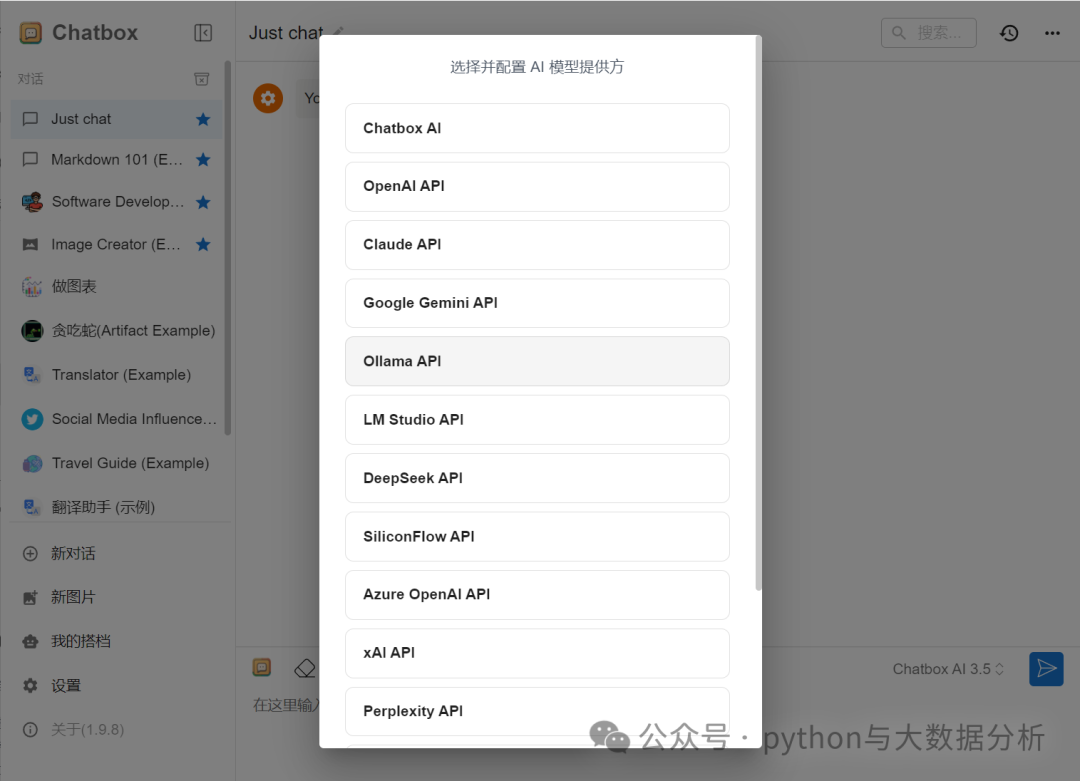
对我们而言,构建本地交互应用无非两种形式,工具或代码,主流的工具如Open WebUI和Chatbox AI;代码则包括以下几种方式(来自于deepseek的回答):方式 1,使用 Hugging Face Transformers 加载本地模型;方式 2,通过自定义 API 调用;方式 3,直接加载本地模型文件;方式 4,使用 ONNX 或 TensorRT 加速。关于自定义API调用又分为很多种方式,有基于flaskapi的,有基于flask、streamlit、gradio等。当然我们不可能每种都尝试,笔者也在慢慢摸索过程中,今天先简单介绍其中两种方式,api调用的只能等到下次了。




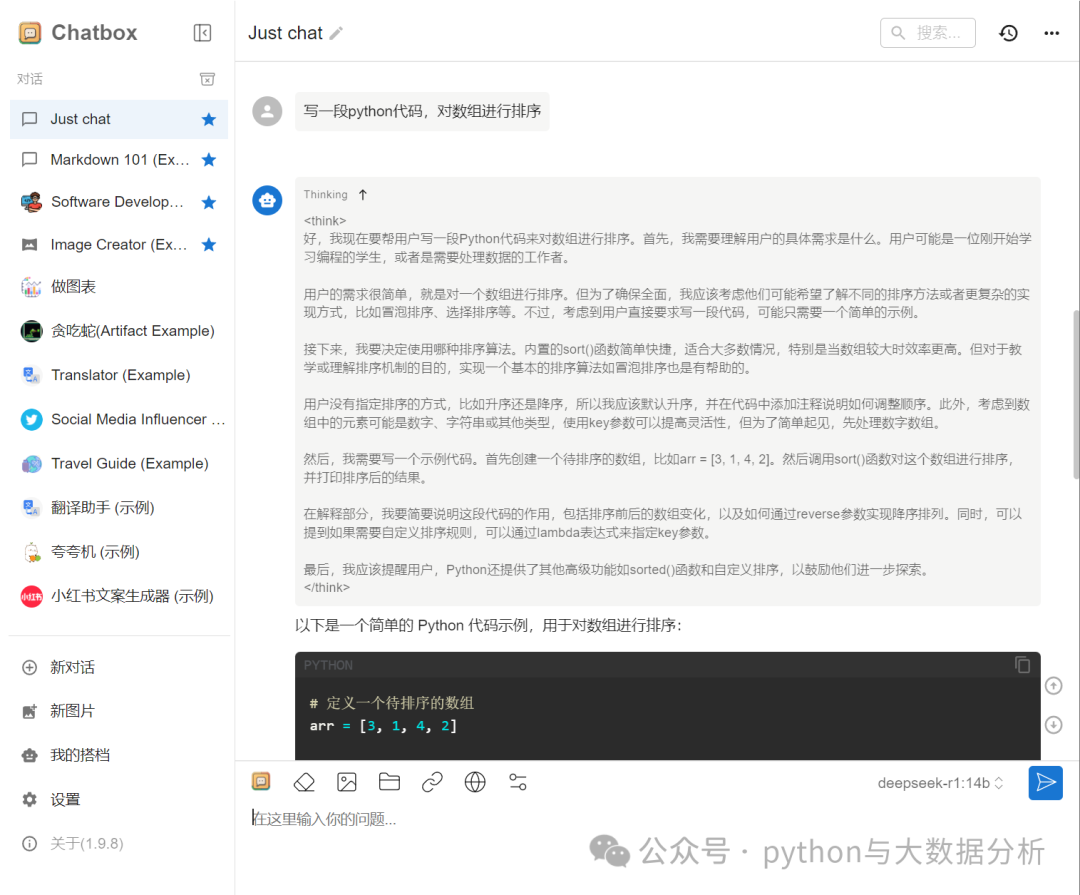
此处的代码是基础代码,后续无论是通过flask还是streamlit还是gradio,无非是前端呈现问题,对接口的调用、输入、输出是大同小异的。
import requestsimport json# Ollama API 的地址url = "http://localhost:12345/api/generate"# 定义请求的数据# model:指定要使用的模型名称,这里是 deepseek-r1:14b。# prompt:输入给模型的提示信息,即你想要询问的问题。# stream:设置是否使用流式响应。# 如果设置为 True,模型会逐步返回结果;# 如果设置为 False,则会等待模型生成完整的结果后一次性返回。# 请求头:设置 Content-Type 为 application/json,表示请求数据是 JSON 格式。# 发送请求:使用 requests.post 方法发送 POST 请求,并将响应结果解析为 JSON 格式。# 处理响应:打印模型的回复,如果请求或解析过程中出现错误,会捕获相应的异常并输出错误信息。# 定义请求的数据content = {"model": "deepseek-r1:14b", # 模型名称"prompt": "您好,写一篇3000字的射雕英雄后传小说", # 输入的提示信息"stream": True # 是否使用流式响应}# 将数据转换为 JSON 格式contentjson = json.dumps(content)# 设置请求头headers = {"Content-Type": "application/json"}# 非流式输出if content["stream"] == False:# 发送 POST 请求try:response = requests.post(url, headers=headers, data=contentjson)# 检查响应状态码response.raise_for_status()result = response.json()print(result["response"]) # 打印模型的回复except requests.exceptions.RequestException as e:print(f"请求出错: {e}")except (KeyError, json.JSONDecodeError):print("解析响应数据出错")# 流式输出else:try:response = requests.post(url, headers=headers, data=contentjson, stream=True)response.raise_for_status()for line in response.iter_lines():if line:result = json.loads(line)if 'response' in result:print(result["response"], end='', flush=True)except requests.exceptions.RequestException as e:print(f"请求出错: {e}")except (KeyError, json.JSONDecodeError):print("解析响应数据出错")
最后输出如下,只要不涉及严谨的知识领域,看起来回答都还是不错的

最后欢迎关注公众号:python与大数据分析

文章转载自追梦IT人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
