






1994年,美国明尼苏达大学的实验室里,一群工程师在测试一个名为“Group Lens”的系统。当它第一次通过协同过滤算法,从浩如烟海的新闻组帖子中挑出用户可能感兴趣的内容时,一扇名为推荐算法的大门,自此彻底打开,
没人想到这项技术会在三十年后的移动互联网时代,成为支配全球50亿人注意力流向的“隐形之手”。
字节跳动用推荐引擎将人均单日内容消费时长从15分钟拉升至140分钟,
Instagram用算法推荐取代时间流后,用户活跃度暴增。
各大电商平台之中,基于高效、个性化算法,为用户生成量身定制的购物推荐,成为每个电商平台终极目标。
但你是否有想过,推荐算法究竟是如何工作的?
在常见的基于推荐逻辑和数据依赖性的分类之外,推荐算法,还可以被粗略的分为动态与静态两类,静态推荐算法的推荐结果相对固定,通常基于用户的历史数据和物品的固有属性进行推荐,推荐结果具有一定的稳定性和可解释性;但近两年动态推荐算法逐渐占据主流,他们可以根据用户的实时行为、环境变化以及物品的动态信息进行实时推荐,更好地满足用户的需求。
而在众多动态推荐算法之中,Transformers4Rec无疑是近些年来最具代表性的一个。
在不久前由 Zilliz 主办的非结构化数据 Meetup 上,美国知名百货公司Nordstrom 的数据科学家 Kunal Sonalkar,分享了他们是如何使用 Transformers4Rec 实现序列化和会话相关的推荐,来更好地满足用户不断变化的需求。
01
选型思路:什么是 Transformers4Rec ,适合什么场景?
相比传统的动态推荐算法,Transformers4Rec 集成了 Transformers 架构,可以更好的理解系统中的用户交互行为如浏览、添加购物车等,并将其与推荐系统很好的融合,进而做出更精准的实时推荐。
例如,假设一位顾客正在浏览一家在线书店。他首先查看了几本科幻小说,并将其中一本加入购物车,随后又浏览了几位相关作者的页面。Transformers4Rec 就会分析这一系列行为,并预测这个顾客可能对另一本热门科幻小说或相关奇幻小说感兴趣。
(要注意的是,在这个过程中,我们除了要精准理解用户的兴趣之外,还需判断他们是否对价格敏感等信息,从而制定相应的推荐内容。比如,同样是搜索“鞋子”的顾客,系统会根据用户之前的互动和偏好(如预算或品牌),给他们推荐不同的结果。)
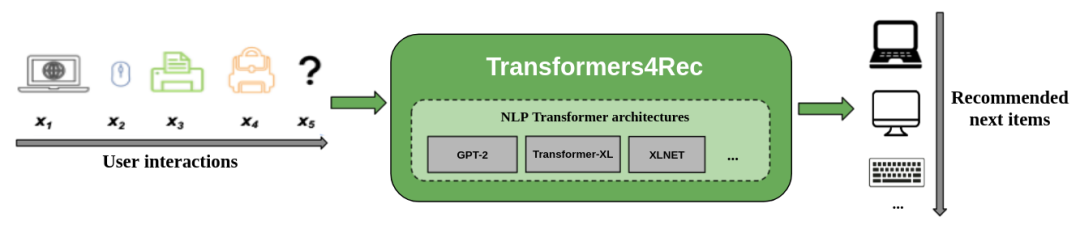
图:Transformers4Rec 在一个推荐系统中的工作流程
当然,电商之外,在短视频或者内容社区场景中,我们通常还需要为用户推荐一些“相似但不同”的候选内容,那么我们就可以将用户观看序列等数据,存入向量数据库(如Milvus),在检索时通过主检索:相似度>0.8的视频(核心兴趣区),副检索:相似度0.4-0.6的视频(探索兴趣区)这种方式来提升推荐的灵活性与索引召回效率。
整体来说,在落地中,Transformers4Rec 最大的优势有三:
(1)灵活性:Transformers4Rec提供了模块化的构建模块,这些模块既可配置又可与标准PyTorch模块兼容,允许创造自定义的架构。
(2)支持多输入特征:由于与HF Transformers的集成,可处理NLP领域的序列标签,这也允许Transformers4Rec处理RecSys数据集中的丰富特征。
(3)顺滑的预处理和特征工程:Transformers4Rec集成了NVTabular和Triton Inference Server,可构建一个完全GPU加速的管道以支持顺序和会话推荐。
更智能、更实时,也更灵活,但Transformers4Rec 并非万能。相较传统推荐算法,基于 Transformers4Rec 的推荐系统,会带来显著的计算成本,尤其是在大规模部署 GPU 资源时。
通常来说,构建和维护这种系统需要非常多的基础设施,包括从数据收集和存储,再到模型部署和实时推理。
在这一过程中,选择合适的基础设施,对于创建快速检索的推荐系统至关重要。例如,使用像 Milvus 这样的向量数据库,可以实现快速的相似性搜索和高效的向量Embedding 存储,并将结果很好地集成到推荐流程中。
与此同时,我们需要关注,电商场景中,我们通常需要处理新增或频繁变化的商品目录。如何在历史数据有限的情况下做精准推荐?这要求模型和数据基础设施具备适应性,以便根据最新上下文更新推荐。
02
Transformers4Rec是如何工作的?
Transformers4Rec的架构包括四个主要组件:特征聚合(Feature Aggregation)、序列掩码(Sequence Masking)、序列处理(Sequence Processing)和预测模块(Prediction Head)。
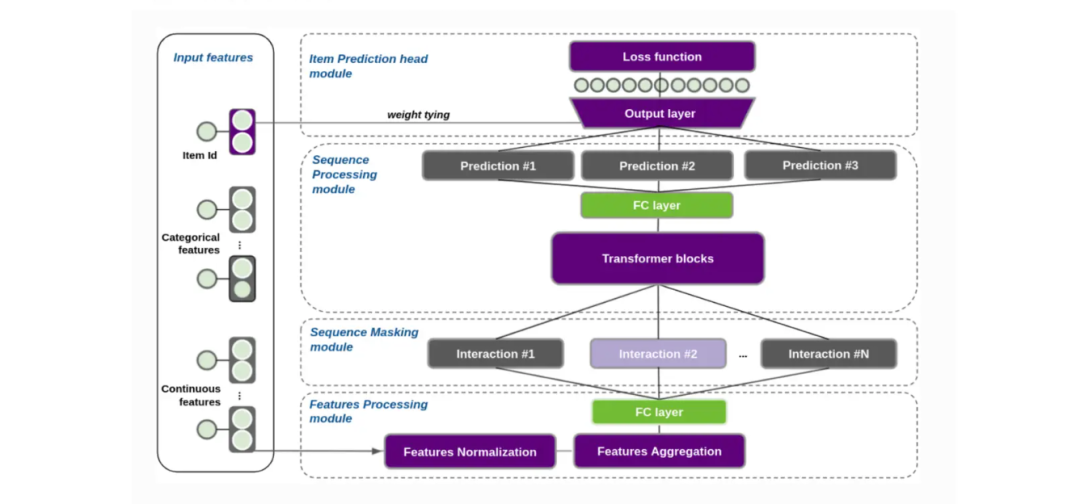
图:Transformers4Rec 架构
组件一:特征聚合(Feature Aggregation)
特征聚合组件,主要会收集有关用户交互的数据(包括连续变量和分类变量),用来构建全面的推荐画像。例如,在一个电子商务推荐系统中,分类特征可能包括品牌和产品类型等属性,而连续特征可能涵盖价格、折扣率或最近的交互行为(例如,过去24小时内对某商品的点击次数)。
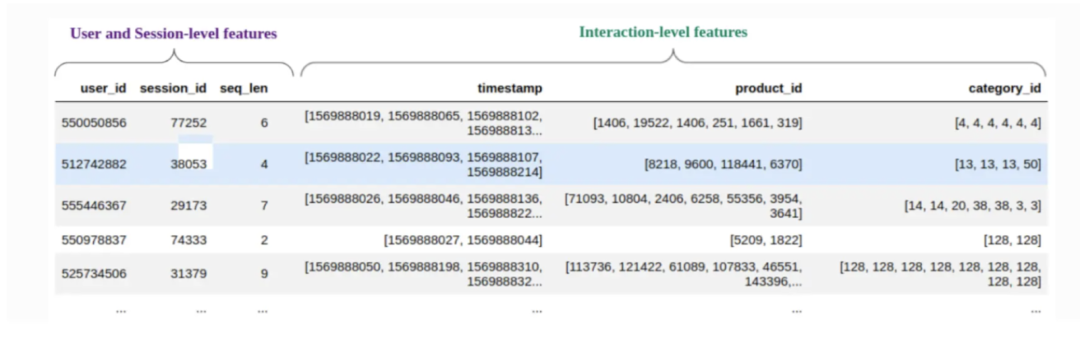
图:Transformers4Rec 里的特征聚合
在将这些序列输入到 Transformer 模块之前,交互数据需要被预处理成一种标准化的格式,称为向量 Embedding(即高维空间中交互数据的数值表示)。输入的信息,可以按用户 ID 或会话 ID 进行分类,将交互序列聚合成单一的向量表示,这个过程被称为“交互 Embedding”。
这种 Embedding包含了用户交互的上下文信息,例如用户操作的类型、涉及的商品以及交互的顺序,它们可以存储在向量数据库中,从而实现高效的检索和语义搜索。像 Milvus 或其托管的 Zilliz Cloud 这样强大的向量数据库,通过集成 PyTorch,可以简化这一过程。
此外,Transformers4Rec 还包含一个 NVTabular 模块,它可以轻松地将原始数据转换为所需的格式,就可以更容易地管理数据了。
组件二:序列掩码(Sequence Masking)
Transformers4Rec 中的序列掩码组件,会对用户交互进行掩码处理,从而防止数据泄露的同时保持序列顺序,确保了模型遵循事件的时间线。例如,在预测用户的下一个商品时,该模块会隐藏任何之后的操作,从而使模型能够以因果关系、逐步地进行学习。
Transformers4Rec 中不同类型的序列掩码,可以控制模型在训练或推理期间“看到”的内容,这有助于系统捕捉用户行为中有价值的模式,并且提高系统预测下一次交互的准确度。Transformers4Rec 提供了多种序列掩码选项:
因果语言建模(Causal Language Modeling, CLM):该技术对序列中的未来商品进行掩码,训练模型仅仅依靠先前的商品进行预测。对于交互顺序非常敏感的序列化推荐场景,CLM 方法非常有用。
掩码语言建模(Masked Language Modeling, MLM):在 MLM 中,序列中的某些位置会被随机掩码,模型通过学习周围的上下文,来预测被隐藏的商品。这种技术可以帮助模型理解商品之间的关系,不用依赖严格的顺序。
随机标记检测(Random Token Detection, RTD):RTD 将序列中的一个随机商品,替换为不相关的商品,模型通过学习来识别这个错误的商品。这种方法教会模型从随机噪声或异常中区分真实模式。
排列语言建模(Permutation Language Modeling, PLM):在这种方法中,通过打乱序列中商品的顺序,来训练模型预测新顺序中的商品。PLM 通过提高模型识别任何顺序的能力,来提高灵活性。
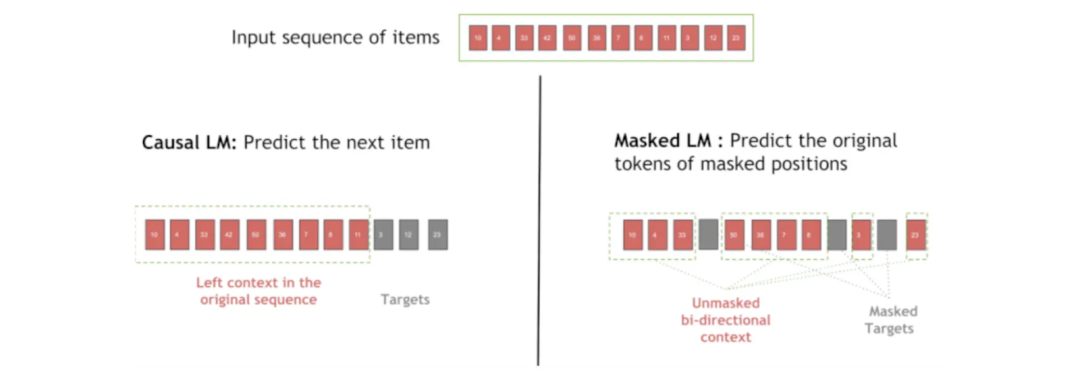
图:序列掩码过程中,因果语言建模和掩码语言建模的区别
备注:通常,在训练之前,20-30%的位置 embedding 会被掩码。
组件三:序列处理(Sequence Processing)
序列处理组件将输入特征提供给 Transformer 模型,来预测用户交互序列中被掩码的商品或位置。Transformers4Rec 支持多种序列处理架构,包括XLNet、GPT-2 和 LSTM,用户可以为推荐系统选择最合适的模型。
交互向量 Embedding 会被传递到 Transformer 模块中,例如下面的代码片段。用户可以通过设置层数和序列长度等参数,来配置 Transformer 架构。
通过传递聚合的输入、应用掩码,并启用所需的模型配置,我们可以在 PyTorch 中创建一个序列块,从而为定制推荐任务提供灵活的设置。
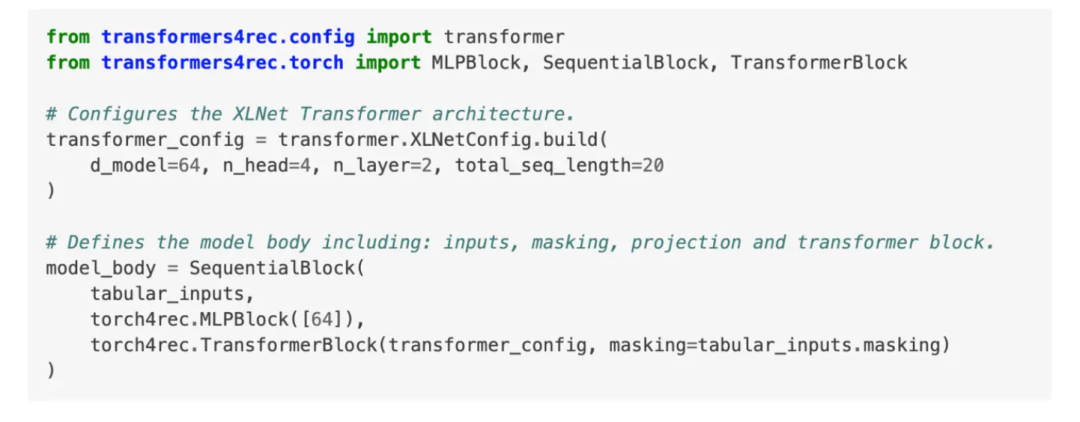
图:PyTorch 中的序列处理
Fig) Sequence processing in Pytorch
组件四:预测模块(Prediction Head)
预测模块是 Transformers4Rec 框架中的最后一个模块,它利用 Transformer 模型的输出,来生成可以使用的推荐结果。
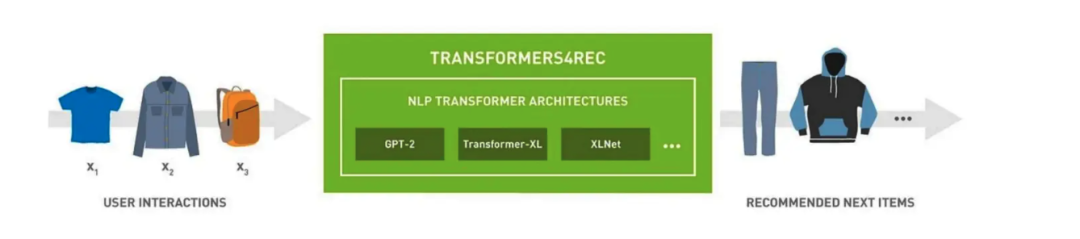
图:Transformer 模型的输出,用于生成可以使用的推荐结果
该模块支持根据业务需求定制的多种推荐方式,包括:
下一项预测(Next Item Prediction):根据用户之前的操作,预测用户可能想了解的下一个商品,从而提供及时且相关的推荐。
二元分类(Binary Classification):在这个模式下,模型计算用户点击特定商品的概率。这对于点击率(CTR)预测非常有价值,因为它可以帮助确定哪些商品最有吸引力,以此优化布局和内容。
回归(Regression):回归任务可以对连续值进行预测,例如用户在某个商品上花费的时间、预期的交互次数,甚至是预估的购买数量。
下图展示了端到端的生产流程,包括所有四个组件:特征聚合、序列掩码、序列处理和预测模块,它们协同工作,提供准确且符合上下文的推荐。
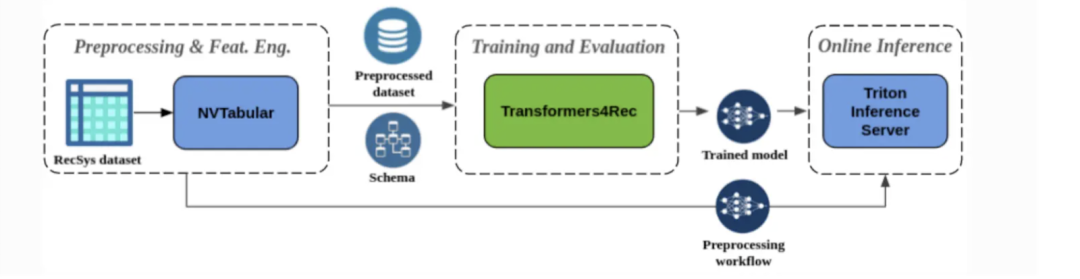
图:使用 Transformers4Rec 构建的推荐系统中的端到端流程
03
如何评估Transformers4Rec 的效果?
推荐系统的有效性,很大程度上取决于它满足用户需求的准确性。对于 Transformers4Rec,常见的评估指标包括精确率(precision)和召回率(recall),用于评估系统前“N”个推荐与用户偏好的匹配程度。
此外,排序指标,如平均精度均值(Mean Average Precision, MAP)和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG),也可以用来评估推荐商品的相关性和顺序。
04
总结
在本文中,我们讨论了 Transformers4Rec 如何利用 NLP 衍生的技术,来创建动态、个性化的推荐系统。通过特征聚合、序列掩码、序列处理和预测模块等组件,这个框架能够捕捉复杂的用户模式,从而提供实时且相关的推荐。精确率、召回率、MAP 和 NDCG 等关键指标,则可以用来评估系统的有效性,确保提供满足用户需求的推荐。
而在此过程中,Transformers4Rec 会对企业的基础设施成本和存储需求带来不小的挑战。我们可以通过使用像 Milvus 这种向量数据库工具,来支持高效的向量存储和检索,或者微调参数(如向量维度和序列长度),来解决实际落地中的这些困难。
如对以上案例感兴趣,或想对Milvus做进一步了解,欢迎扫描文末二维码交流进步。



