





点击蓝字关注我们
组件介绍
1.1 Filebeat 简介
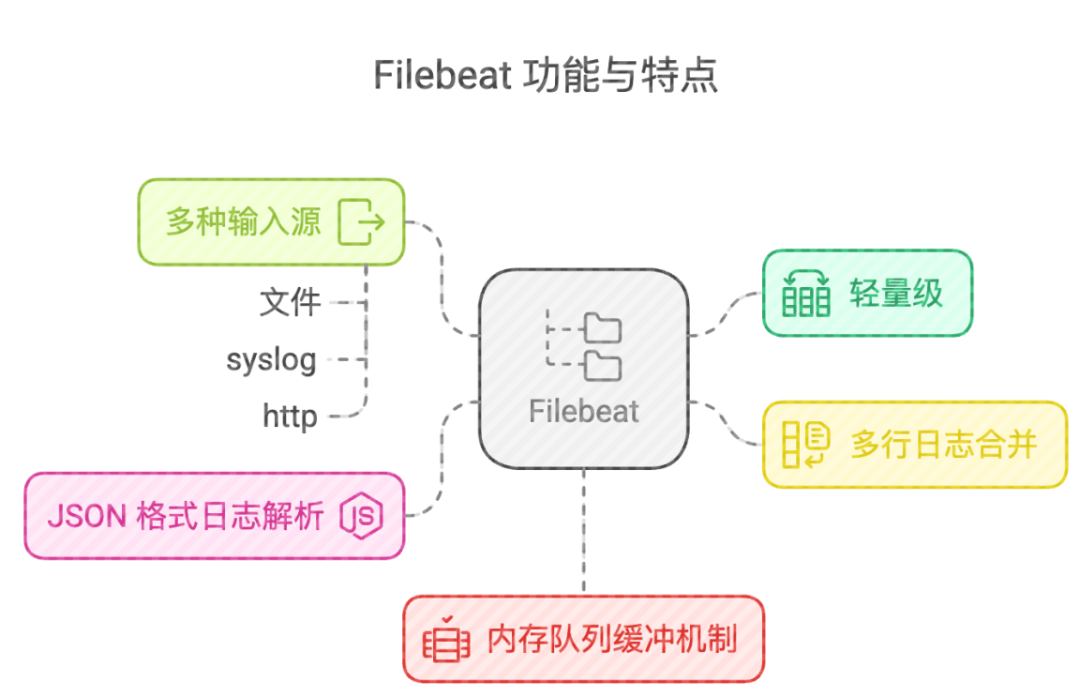
Filebeat 是一个轻量级的日志采集器,主要用于从文件系统收集日志数据并转发到 Elasticsearch 或 Logstash 进行处理。
主要特点:
• 轻量级,占用系统资源少
• 支持多种输入源(文件、syslog、http等)
• 内置多行日志合并功能
• 支持 JSON 格式日志解析
• 具备内存队列缓冲机制
1.2 Logstash 简介
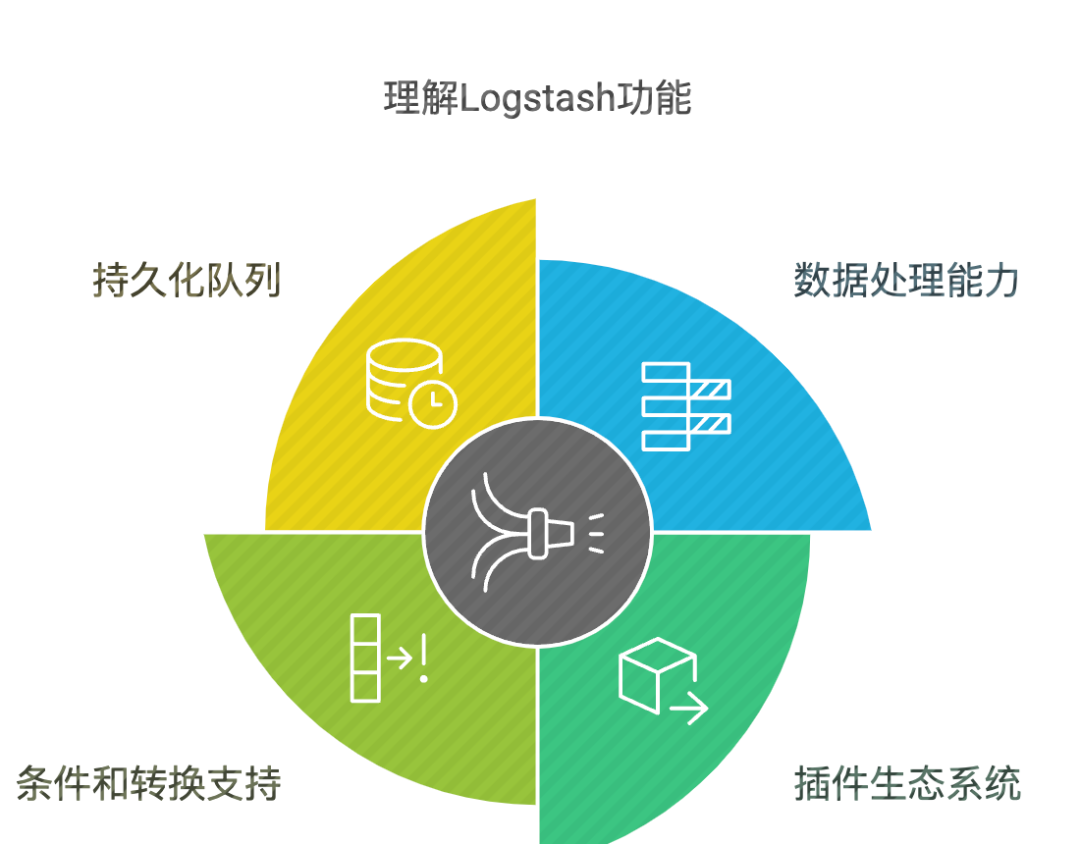
Logstash 是一个数据处理管道,可以同时从多个来源采集数据,转换数据,然后将数据发送到指定的存储库中。
主要特点:
• 强大的数据处理能力
• 丰富的插件生态
• 支持条件判断和复杂的数据转换
• 具备持久化队列功能
最佳实践配置
2.1 Filebeat 关键配置
1) 多行日志处理配置示例:
multiline.pattern: '^\['multiline.negate: truemultiline.match: aftermultiline.max_lines: 10000复制
2) JSON 日志处理配置示例:
json.keys_under_root: truejson.overwrite_keys: truejson.message_key: logjson.add_error_key: true复制
3) 内存队列优化配置:
queue.type: persistedqueue.max_bytes: 1024mbflush.min_events: 2048flush.timeout: 1s复制
2.2 Logstash 关键配置
1) 持久化队列配置:
queue.type: persistedpath.queue: /usr/share/logstash/dataqueue.max_bytes: 1024mbqueue.checkpoint.writes: 1024复制
2) 条件判断示例:
if [loglevel] == "ERROR" and [deployment] == "production" {pagerduty {# 告警配置}}复制
常见问题排查
3.1 Filebeat 内存溢出
可能原因:
• 采集文件数过多
• 多行日志配置不当
• 内存队列设置过小
解决方案:
• 调整 close_inactive 参数关闭不活跃文件
• 优化 multiline 配置
• 增大 queue.max_bytes 值
3.2 Filebeat 数据发送缓慢
可能原因:
• 网络带宽限制
• ES 写入速度慢
• 队列积压
解决方案:
• 检查网络状况
• 调整 ES 写入参数
• 增加 worker 数量
• 优化 batch size
性能优化建议
4.1 Filebeat 优化
• 合理设置 harvester_limit 限制采集器数量
• 使用 ignore_older 忽略旧文件
• 调整 scan_frequency 降低扫描频率
• 启用 compression 压缩传输数据
4.2 Logstash 优化
• 使用持久化队列保证数据可靠性
• 调整 pipeline.workers 数量
• 优化 pipeline.batch.size
• 合理设置 filter 插件的缓存
监控指标
5.1 Filebeat 关键监控指标
• harvester 运行状态
• 发送队列长度
• 事件处理延迟
• CPU/内存使用率
5.2 Logstash 关键监控指标
• pipeline 事件吞吐量
• 队列使用情况
• filter 处理时延
• JVM 堆内存使用率
总结
ELK Stack 中的 Filebeat 和 Logstash 是构建日志采集系统的重要组件。合理的配置和优化可以显著提升系统的性能和可靠性。
建议在生产环境中:
• 根据实际场景选择合适的配置参数
• 建立完善的监控体系
• 制定清晰的问题排查流程
• 定期进行性能优化
希望本文能帮助你更好地使用和维护 ELK Stack 日志系统。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
