





大家好,我是一安~
讲真的NULL
貌似在哪里都是个头疼的问题,比如 Java
里让人头疼的 NullPointerException
,为了避免猝不及防的空指针异常,千百年来程序猿们不得不在代码里小心翼翼的各种 if
判断,麻烦而又臃肿,为此 Java8
引入了 Optional
来避免这一问题。
下面咱们要聊的是 MySQL
里的 NULL
,在大量的 MySQL
优化文章和书籍里都提到了字段尽可能用NOT NULL
,而不是 NULL
,除非特殊情况。
案例数据
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`age` tinyint(4) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
INSERT INTO `user` (`name`, `age`) VALUES ('kaka', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('niuniu', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yangyang', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('dandan', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('liuliu', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yanyan', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('leilie', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yao', 26);
INSERT INTO `user` (`name`, `age`) VALUES (NULL, 26);
INSERT INTO `user` (`name`, `age`) VALUES (NULL, 26);
测试
count统计丢失
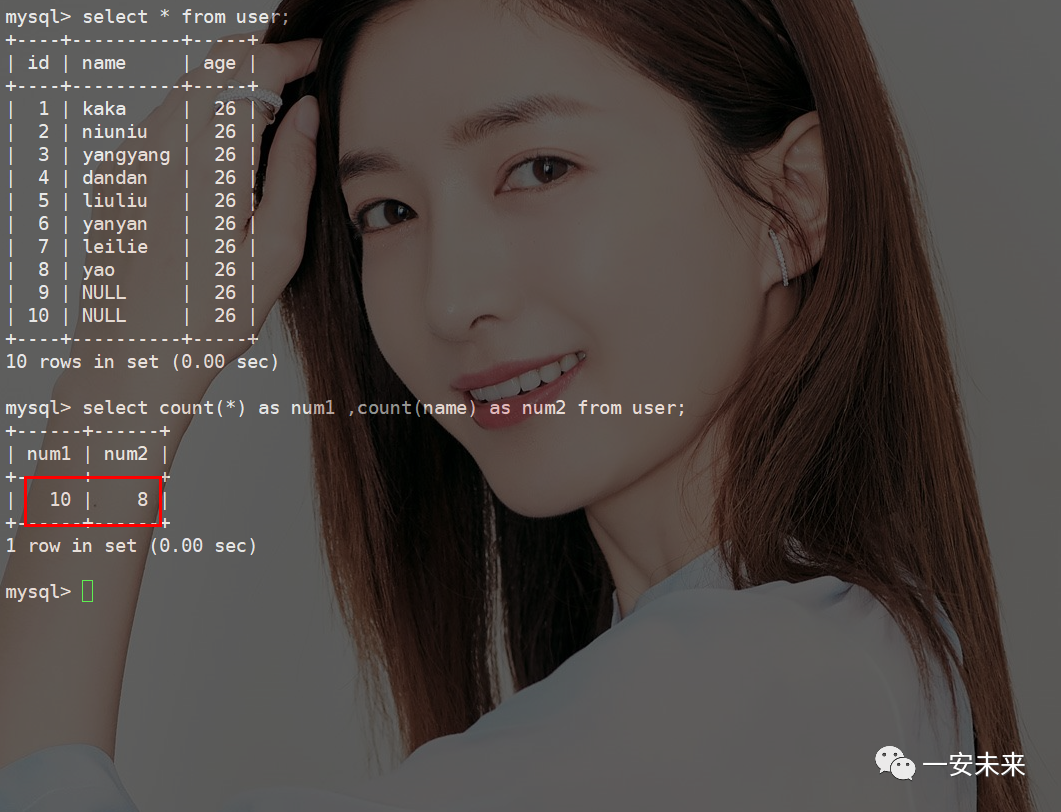
当
count
除了主键字段外,会有两种情况:
字段为 NULL
,执行时,判断到有可能是NULL
,但还要把值取出来再判断下,不是NULL
的进行累加字段为 NOT NULL
,执行时,逐行从记录里边读出这个字段,判断不是NULL
,才进行累加说明:
MySQL
对于count
做了专门的优化,跟字段不同的是并不是把所有带了*
的值取出来,而是指定了count(*)
肯定不是NULL
,只需要按行累加即可
使用表达式数据丢失
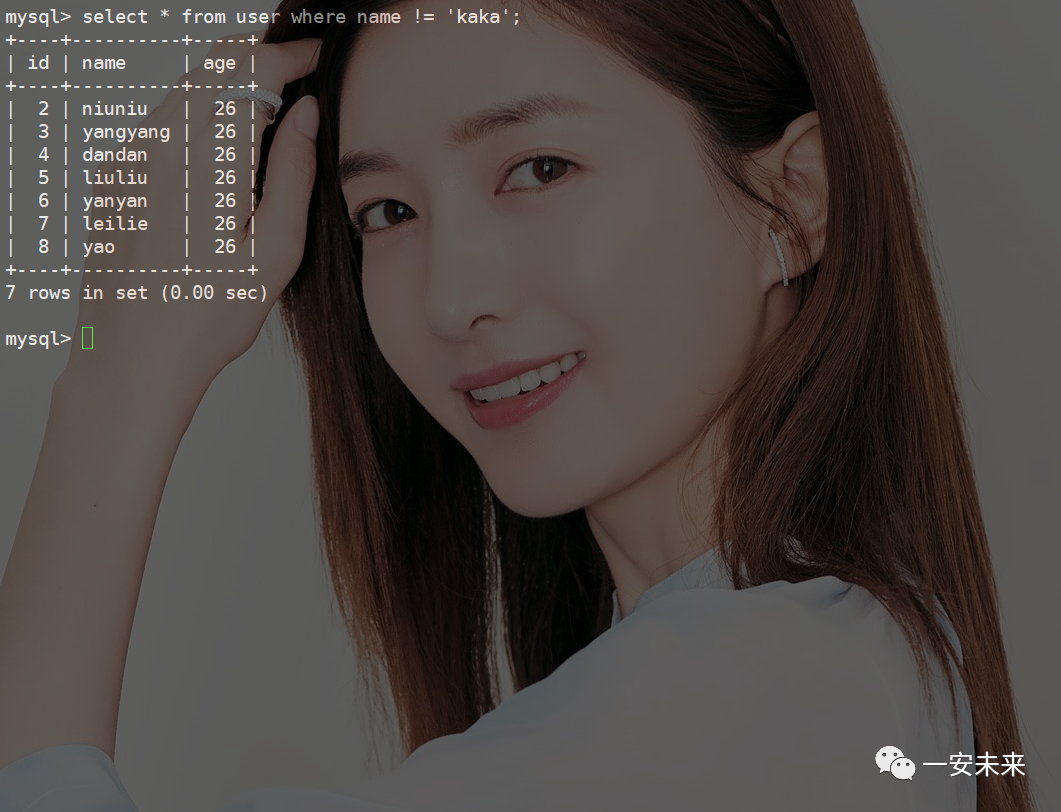
在
MySQL
中,NULL
是一个特殊的值,表示缺少值或未知值。NULL
不等于任何值,包括自身。因此,当你使用不等于操作符进行比较时,NULL
值将不会与'kaka'
相等,它们也不会被包含在查询结果中要解决这个问题,只能再加一个条件就是把字段值为
NULL
的条件(or isnull(name)
)再单独处理一下
空指针
CREATE TABLE user_order (
id INT PRIMARY KEY auto_increment,
num int
) ENGINE='innodb';
insert into user_order(num) values(3),(6),(6),(NULL);
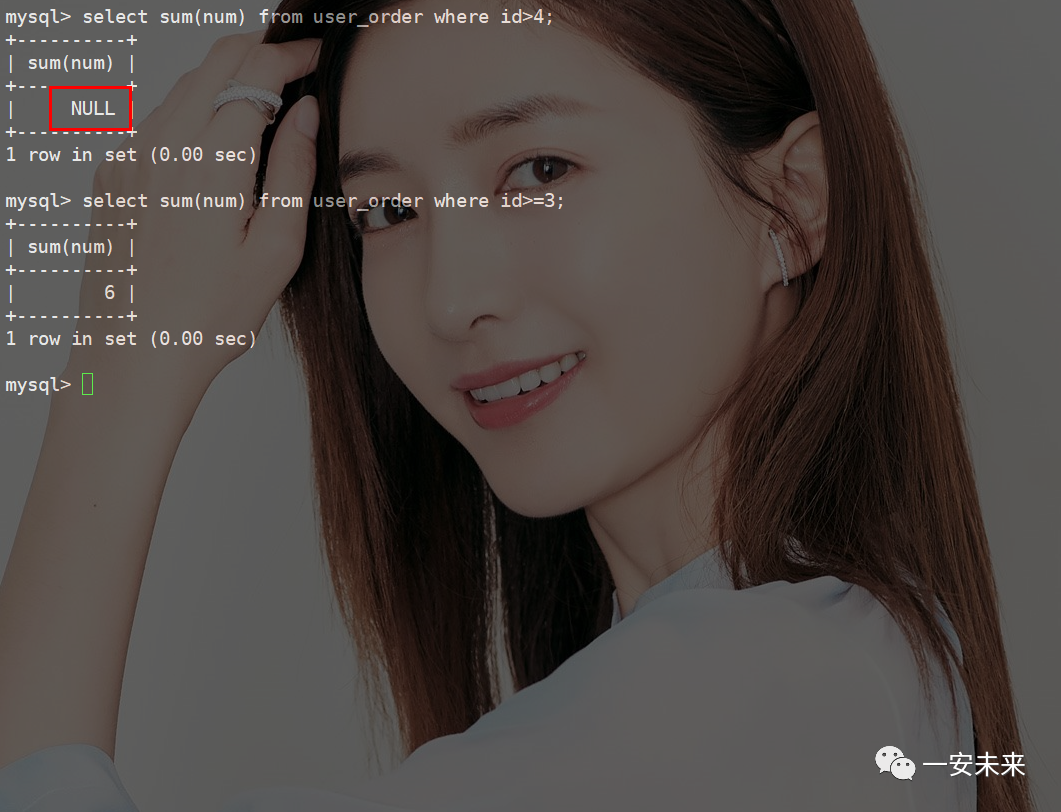
NULL
表示缺少值或未知值,它在计算中被视为未定义的值。当使用SUM()
函数时,MySQL
将无法确定NULL
值的具体数值,因此结果被设置为NULL如果希望在计算总和时将
NULL
值视为 0,可以使用COALESCE()
函数来将NULL
值转换为 0(SUM(COALESCE(num, 0))
),然后再进行求和计算
NULL值过滤
对存在NULL
值的字段使用表达式进行过滤,正确用法应该是is null
或者 is not null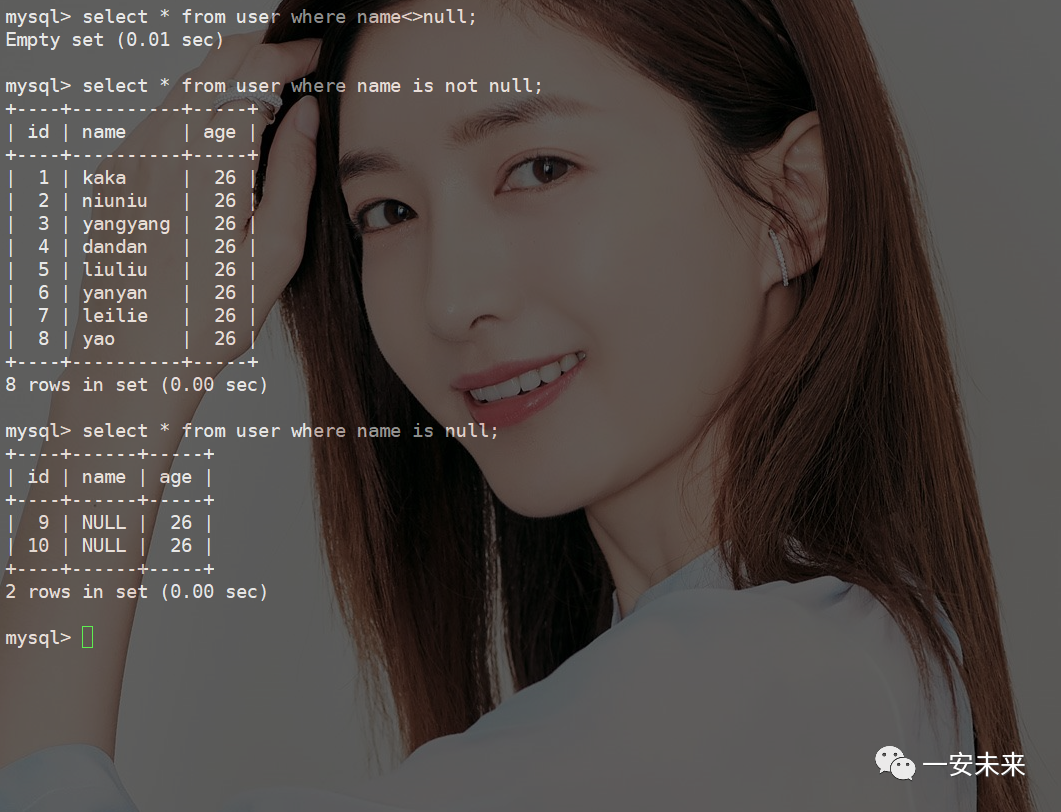
补充说明
当可为NULL
的列被索引时,每个索引记录需要一个额外的字节,在MyISAM
里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
对于索引字段,如果它们不是NOT NULL,则每个字段加1个字节。 对于定长字段: tinyint占1个字节 int占4个字节 bitint占8个字节 date占3个字节 datetime占5个字节 char(n)占n个字符 对于变长字段: varchar(n)占n个字符+2个字节 根据不同的字符集,一个字符占用的字节数不同: latin1编码,每个字符占用1个字节 gbk编码,每个字符占用2个字节 utf8编码,每个字符占用3个字节 utf8mb4编码,每个字符占用4个字节
如我们计算一下在utf8mb4编码下,通过EXPLAIN
命令查看key_len
的值:
字段:phone varchar(20) DEFAULT NULL COMMENT '手机号'
条件:where phone='xxx'
在utf8mb4编码下,每个字符占用4个字节。因此,对于字段phone
,我们需要计算20 * 4 + 2 + 1
。
首先,计算20 * 4
,即20个字符乘以每个字符占用的字节数4,得到80个字节。
接下来,加上2个字节,这是变长字段(varchar)的额外开销。
最后,加上1个字节,这是因为在查询中使用了该字段作为索引字段。
将这些值相加,得到83个字节,即key_len=83
。
请注意,这是在utf8mb4编码下的计算结果。如果使用其他编码(如utf8或gbk),计算方法会有所不同。
如果这篇文章对你有所帮助,或者有所启发的话,帮忙 分享、收藏、点赞、在看,你的支持就是我坚持下去的最大动力!

SpringBoot 这样做参数校验才足够优雅,彻底告别 if-else
面试官:在 Java 中 new 一个对象的流程是怎样的?彻底被问懵了。。

